


What does this “Modern Authentication” phrase mean to you? This is the challenge. Something so critical to our applications doesn't even have a good definition. I'm confident that now, many of you are wondering what this article is all about. This article is about the absolute basics of authentication.
When was the last time you wrote an application that didn't need any information about the user using the application? Almost never, right? Authentication is as essential as it gets. And yet the challenge is mixed with the jargon of keywords and chasing ever-changing standards of security and identity. The field of authentication can appear overwhelming.
The result is poorly written applications. Think about it, poorly written applications that concern user identity. Ouch!
The goal of this article is to simplify all of this, so you're better equipped to talk back smartly when someone throws all that technical identity jargon at you. The goal is to share the absolute basics of identity that I wish everyone was on the same page about.
What Is Modern Authentication?
Let's start with the first challenge. There's no clear definition of this term “Modern Authentication” and yet everyone throws the term around. So let's attempt to define it first, at least for the purposes of this article.
The challenge is that we've had pretty good solutions for authenticating and managing users for a while now. In the Microsoft world, we've used Active Directory. But the concepts aren't unique to active directory. There are protocols such as NTLMv2 and Kerberos that have been in use for some time now. The problem is that neither of these protocols are perfect for an Internet world.
NTLMv2 relies on point-to-point exchange; to simplify, without sending my password over the wire, using some sort of shared understanding between me and the recipient (server), the server is able to ascertain that I'm providing the correct credential. This has a serious downside in that my credentials can't be forwarded by the server to another server.
To alleviate that issue, a protocol called Kerberos was created. In Kerberos the domain controller hands out tickets for creating sessions between the client and the server or the domain controller itself. Kerberos is great and has served us very well in corporate environments. Where it breaks down, of course, is when you try to take things to Internet scale. For instance, Kerberos is extremely chatty and requires a lot of network ports to be opened for it to work. Now, organizations have really stretched the boundaries of what Kerberos can do. There are concepts such as trusts, VPNs, and so much more that have enabled us to stretch the boundaries of what was intended to be a single-organization solution.
The modern workplace is different. As I write this article, the world is hunkering down due to the COVID-19 pandemic, and a lot of businesses are getting really hurt. Restaurants, airlines, cruise ships—I can't imagine the damage they're experiencing right now. But compared to similar previous crises, I'm simply amazed at how unfazed the information worker has been. They're just working from home. They just fire up Microsoft Teams or similar, and it's business as usual. In fact, I'd argue that working remotely, done right, is more productive than sitting in an office, dealing with a commute for two hours a day, paying for, and maintaining all that real estate, etc.
All of this is made possible because companies today have the confidence that they can fire up Microsoft Teams or their browsers, or other applications, authenticate to the corporate network securely, and work. Although this act of joining an online meeting or opening a document on SharePoint may appear banal, there are two very important tenets at play here:
- The organization is confident that this data is going to be secure.
- The employee or contractor finds this experience easy and convenient to use.
Although enabling such seamless productivity wherever you are, or whoever you are, and whatever device you are using, is the work of many technologies and many disciplines, a key enabler here is modern authentication.
With that long-drawn out background, let me attempt to define what I mean by modern authentication.
Legacy Authentication
Legacy authentication is what we used for our dinosaur applications—protocols such as NTLMv2, Kerberos, or similar, that you've typically used on-premises, are legacy authentication.
No, I'm not calling them extinct, they're still our bread and butter. And those dinosaurs are being brought into the modern authentication world kicking and screaming, whether they like it or not.
The reality is that organizations have a lot of investment in these classic/legacy identities. And as much as we'd like to, many critical products, including those that run in Azure or AWS, don't yet support modern identities properly. There's a lot of investment in bridging this gap. For instance, there are things such as Azure AD connect that let you bridge on-premises Active Directory identities to Azure AD identities, or products such as SQL in Azure or Azure Storage, that are making progress in working with modern identities.
A lot of work still needs to be done here. I don't have rose-colored glasses on, and I must assert that these legacy identities will be with us for quite a while.
Modern Authentication
Modern authentication refers to authentication established by protocols that are better designed for Internet scale and management. Although I realize that this is a very amorphous definition, there are some common tenets among all of these authentication protocols.
- They allow you to separate the identity provider (IdP for short) from the service provider (SP for short). The IdP is the entity who accepts your credentials and validates who you are. The SP, also sometimes referred to as the relying party (or RP), is the one providing a service. For instance, an IdP could be Azure AD, who authenticates you. And an RP or SP can be a SharePoint website that accepts such identities.
- They don't require any direct communication between the IdP and SP. No need to open firewall ports, etc. Authentication is built on the backbone of trusts, pre-established ahead of time using mechanisms such as certificates. SharePoint trusts the Azure AD identity, and homework has been done ahead of time to ensure that the identity has not been tampered with.
- The process is almost always asynchronous and stateless. If there's need for state, it's the responsibility of the client. There are some borderline scenarios where this isn't possible, such as when you need instant sign out. But in a vast majority of cases, the entire protocol is stateless. And it's asynchronous, which means that the SP may not even know if the user will complete the authentication process, and the IdP has no idea if the user will ever go back to the SP with the provided identity.
These general characteristics are exhibited by numerous protocols, all of which are modern authentication. Some of these protocols are WS-Fed, SAML, OAuth, and OpenID Connect. Azure AD supports these protocols, and the various endpoints can be seen by clicking the “endpoints” button on any app page in the Azure Portal, as can be seen in Figure 1.
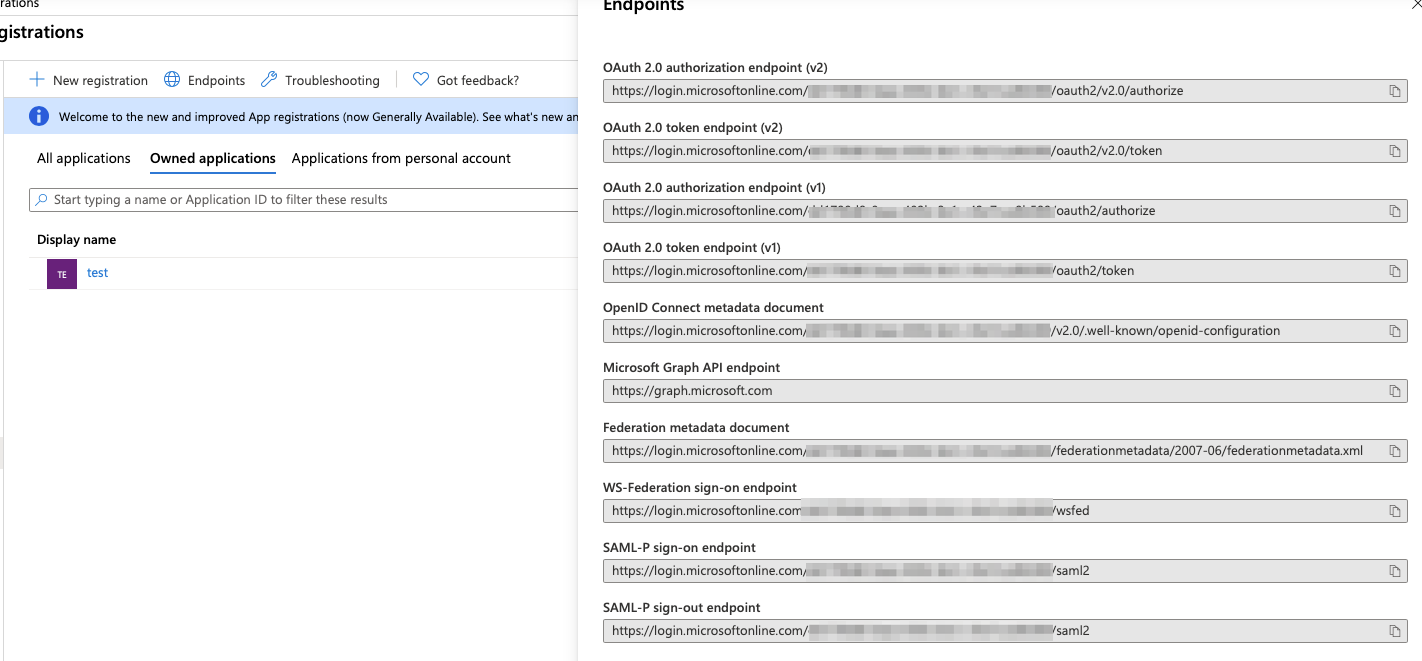
Let's understand them one by one.
WS-Fed
WS-Federation, or WS-Fed for short, was an early entrant into this space. The problem it was trying to solve was a website, such as SharePoint, that needed authentication services from an identity provider, such as Azure AD. Here's how it works at a high level.
The user opens a browser and visits the RP. Are you getting used to these acronyms yet? RP is the relying party, the application that relies on the IdP for authentication services. RP, SP, same thing.
The user sends an anonymous request through their browser.
The SP says, hey, you're not authenticated, but here are the kinds of identities I accept.
The user picks one of those choices; this process is called Home Real Discovery or HRD. This can be automatic, or manual, or any combination thereof.
The user is then redirected to the IdP. The user then provides their credentials, and they're issued an SAML token. Wait, SAML? Yes, keep reading!
This token is then presented to the SP, which is able to validate it and extract the user's identity and necessary claims out of it.
At the end of this entire dance, a Web browser session is established between the SP and the user. At no point did the SP have to make a direct call to the IdP. And to continue the session, well it's just a browser session, so your usual concepts apply.
SAML
SAML, well if I described the flow step by step, you'd say, hey this is just like WS-Fed. And indeed, in many ways it is. But there are a few additional points involved.
First, SAML works with SAML 2.0 tokens. Wait, isn't this confusing? Is SAML a protocol or a token? It's both. WS Fed uses SAML 1x tokens, and SAML protocol uses SAML 2x tokens.
Secondly, SAML gives you a lot more flexibility around who starts the whole flow, what claims are needed for the application to work, and how they are encrypted.
Finally, SAML is newer, so it was back-fitted into scenarios it was never intended for, such as SAML to JWT token transformations or vice versa, or making SAML work on mobile platforms.
As of today, SAML continues to be a very important protocol and will remain so for many years to come.
OAuth
OAuth, isn't an authentication protocol. It's a delegation protocol.
Have you ever landed on a site where someone published an article so absurd that you were compelled to comment? Around the comment box, it says that you need to log-in first. And some of the options include logging in using your Facebook, Twitter, or Google accounts.
Here's how that works. Let's say that you pick Facebook. The site then redirects you to Facebook, where you provide your credentials. And then you're redirected back to the site (the SP), which now knows who you are and lets you log in.
Here's what's really going on. You're redirected to Facebook, not to authenticate yourself, but for the application to do certain things on your behalf. But who are “you” in that “your behalf” part? Well, that's where you need to authenticate yourself. And what are those “certain” things? It's things like accessing your name and email address. This allows the application to know who you are, so it sort of works like an authentication protocol, even though it was never intended to be one.
In that sense, OAuth is a pseudo-authentication protocol.
In a sense, OAuth is a pseudo-authentication protocol.
The problem with OAuth is, of course, first that it's such a loose standard that everyone has chosen to implement it however it fits them. This has caused a real confusion and interoperability issue.
The second problem is that it was promoted heavily by social media companies. Their intent wasn't to provide a social service, but to force you to overshare. So, those “certain things” that you're allowing the application to do on your behalf frequently go way beyond “access my name and email address.”
If you pay close attention, just to leave a comment on an absurd incendiary article on the Internet, you are required to:
- Give your name and email address
- Give your “friends” list
- Let them access your information at any time
- Allow them to post on your behalf
- Draw your blood (just kidding!)
Clearly, there has been abuse. And this has forced the hand of many of these companies to limit the abuse.
OpenID Connect
OpenID Connect is a more formalized version of OAuth, where the world agreed to agree on certain minimum standards that protocols must follow for each major platform. They agreed on a certain basic set of tokens, and some basic claims that must be present in those tokens that the world can rely on to know the user's identity.
As of today, OpenID Connect is perhaps the main protocol that all new development is being done under. Standards are powerful and it makes a lot of sense to get behind the standards. Azure AD v2 flows, for instance, are OpenID Connect compliant. The main thrust of this article will be OpenID Connect.
There are three main things you need to know about OpenID Connect:
- Tokens
- Public client vs. confidential client
- Grant types or flows
Tokens
In OpenID Connect, you perform token exchange. There are three kinds of tokens you should know of. Before I mention what kinds of tokens, I should mention that the most common format you'll see for these tokens is the JWT format. Although JWT isn't a hard and fast requirement, it's the most common format you'll run across. JWT is simply three JSON strings encoded in base64 format with the “.” character between them. The first part is the header, the second is the body, and the third is the signature. When an IdP issues a JWT token, it signs it with its private key, and using its public key, the consumer of that token can ensure that the token hasn't been tampered with. It's as simple as that. Oh yes, one other very important thing, these tokens are sent over various protocols and must not be leaked. The world has agreed that end-to-end encryption, such as HTTPS/TLS, is a 100% hard-and-fast requirement for these tokens to remain secure, so please keep that in mind.
Given that, there are three different tokens to know of: ID tokens, access tokens, and refresh tokens.
An ID token is the user's identity. An ID token must not contain any authorization information—it's merely an identifier for the user. When you sign into a website, you're given an ID token. That's how the website is able to ascertain who you are.
The second token you must know of is an access token. This token lets you authenticate yourself to a Web API. You put this token in the Authorization header of your request, which usually looks like Bearer goobledoogook, that the API you're calling can verify and then grant you access. Because losing an access token pretty much means losing the keys to whatever that access token is good for, access tokens are usually short-lived (30 minutes to one hour, etc.). It's difficult, although not impossible, to centrally revoke access tokens. There's a specific claim in an access token called the jti claim, which is a unique identifier for the jwt token. Using this claim, you can effectively block compromised access tokens also. Now, you may be wondering, if you have authored a Web api, how do you validate an access token?
Finally, a refresh token is a long-lived token that you use to get new access tokens. You usually get an access token for a certain resource—also known as an audience. Only clients that can safely secure refresh tokens should use refresh tokens. This is why a refresh token isn't included by default. You have to ask for it using a specific scope called “offline_access.” I haven't talked about scopes yet, so keep this in the back of your mind for now.
Validating Tokens
Validating a token is an important part of this puzzle. A refresh token is something you just store and use as a key to unlock future access tokens. You do need to validate ID tokens and access tokens. How can you trust that a token presented by a user or application is something you can trust?
Well, there are two kinds of tokens: opaque and not opaque. Opaque tokens are, by reference, tokens, i.e., you're given a random string and you're required to call the IdP every time you wish to validate a token. The advantage here is instant central sign-out and revocation, and possibly smaller token size. The disadvantage is much higher network traffic. But, because you're submitting the token to the IdP at every step, the validation of the token isn't something you need to worry about.
On the other hand, a non-opaque token requires you to put in some work to validate it. Note that most SDKs have implemented this for you, but it still helps to know how it works. As I mentioned, the incoming token has three parts. The first step is to decode the token and validate its signature. To validate the signature, you grab the jwks_uri from the well-known configuration of the OpenID Connect provider. What? Did I just speak out a bunch of jargon? Sorry! In reality it's quite simple. Every IdP exposes a well-known configuration endpoint. For instance, for Azure AD, the endpoint looks like this:
https://login.microsoftonline.com/{tenant}/v2.0/.well-known/openid-configuration.
Or sometimes you may have app-specific configuration URIs, like this:
https://login.microsoftonline.com/{tenant}/v2.0/.well-known/openid-configuration?appId=<appId>.
This URL is anonymous and it returns a simple JSON object. There will be a property called jwks_uri, which contains the public keys for signature validation.
Lesson learned. For your SP to validate tokens, it needs outbound connectivity to the well-known configuration endpoint URI and the jwks_uri. You can't validate AAD tokens in an air-gapped environment.
Once you've validated the signature, you can now unpack the token. This simply means deserializing the token. But remember, as a client application, you must never unpack the tokens. You must treat tokens as opaque. This is because at any point, the IdP can choose to change their implementation to encrypt the tokens. This will make it effectively impossible to unpack the token on the client side. If you build your application around unpacking access tokens, you're setting yourself up with a time bomb.
If you build your application around unpacking access tokens, you're setting yourself up with a time bomb.
On the server, you validate the token by verifying the value of the various claims. For instance, is the token still valid from a time perspective, which is a combination of three claims: nbf (not before), iat (issued at), and exp (expiration). Whether you are the valid audience for this claim is in the “aud” claim. Who issued this claim is in the “iss” claim. And so on.
Public Client vs. Confidential Clients
Many OpenID Connect flows require you to present a secret. The secret may be a password, or it may be a certificate. A public client is simply an application that runs on a platform that you can't trust. For instance, a browser, or a mobile app deployed on a phone that you have no control of, or a Windows desktop app, etc. These applications can't be trusted to hold a secret.
The contrast to this is a Web application, which can store a secret securely on the disk (or elsewhere) on the server. Because this secret never leaves the server, you can trust that it's never compromised. Such an application is called a confidential client.
This is an important distinction because in Azure AD, public clients are disabled by default. You have to explicitly enable them for you to request access tokens without a secret. This can be seen in Figure 2.

Flows or Grant Types
Finally, you need to understand the concept of grant types. OpenID Connect isn't a single protocol. It's a family of ever-growing protocols. Depending upon the kind of application you're authoring, you may want to pick the appropriate grant type. Here are some common grant types you need to know about.
Client Credential Flow is when you care about a headless process authenticating, where you have no opportunity to present a user interface. This is a simple POST request, where you specify what you're requesting a token for, also known as the audience URI. You specify who you are, which is the client ID, also known as App ID, and you provide a client secret. The caller of the client credential flow has no opportunity to provide an inline consent, so all consents must already be in place. Also, the caller of the client credential flow in Azure AD can be either an application or a service principal. When acting as a service principal, you simply provide the service principal username and password, which then also allows you to do interesting things, such as roles on headless processes. An important note about client credential flow: the access token returned is valid for an hour, which is the default, but has configurable duration in Azure AD. However, there's no refresh token. To get a new access token, you simply repeat the request. The request to get an access token using client credential flow can be seen in Listing 1. For the eagle-eyed among you, the scope I've requested here is: https://graph.microsoft.com/.default. This will give me a token for all scopes that have been consented to. You're required to use the ./default shortcut in CC flow.
Listing 1: Client Credential Flow
POST /{tenant}/oauth2/v2.0/token HTTP/1.1
Host: login.microsoftonline.com
Content-Type: application/x-www-form-urlencoded
client_id=<guid>
&scope=https://2Fgraph.microsoft.com/.default
&client_secret=<secret>
&grant_type=client_credentials
Resource Owner Password Credentials grant flow, or ROPC, is where you play a username/password to an endpoint. Long story short, try not to use it. You have to use it when you must have 100% control on the UX for sign in, but the downsides far outweigh the upsides. Here are some reasons why you should avoid using ROPC:
- ROPC is very hacker-friendly, and you're taking on a big responsibility for securing a much larger attack surface now. For instance, it's now your responsibility to protect against brute force, password spray, dictionary attacks, etc.
- You're between a rock and a hard place—the rock being taking responsibility to secure the user's credentials on a public client and the hard place being prompting the user for frequent sign ins. Guess what most people do then? Store credentials in public client, which is a bad idea!!!
- And what if the application is cloned? With ROPC, you're opening your users to be phishable. You have no idea if the application is closed or not.
- Performance will be bad because you'll have hashing encryption of credentials.
- Your server can't distinguish the user from the app.
- Credentials are exposed to the client app. Credentials should never be anywhere else except the user and the server. Frankly, when you can help it, not even the user. Passwordless is what you should strive for.
- The client can now request any scope without an Okay from the user. So, imagine that you can now access the calendar app without the user knowing you're accessing the calendar.
- There's no support for federation.
- There's no support for MFA.
- Advanced threat protection and conditional access become less useful.
- There's no SSO.
- It's against the OAuth best practice guidelines (RFC8252)
Long story short, if someone asks you to use ROPC, run like hell. Don't do it.
Here's an interesting side note. Did you know that the PowerShell commandlet Connect-MSOLservice, when logging in using saved credentials, uses ROPC behind the scenes? It's a good thing they deprecated the MSOnline module.
Authorization Code Grant Flow is a pretty good protocol. It's perfect for signing into a website and requesting access tokens for secure Web APIs. It works in two steps. First, you redirect the user to the authorization endpoint, where the user provides their credentials and authenticates themselves. Hold on! I thought authorization and authentication were separate concepts? Yes, they are, and this nomenclature can be off putting. But remember, an authorization step is when you have a chance of showing a user interface, and there is where the user authorizes that such and such application is allowed to do such and such actions. This process is called consent. So the name, authorization endpoint, makes sense. The request to the authorization endpoint looks like Listing 2. It's worth mentioning that requesting the auth-code is just one possible mechanism here.
There are some interesting things going on in Listing 2. Let's try to understand them. First of all, it's a simple GET request. The request must include things like who are you (client ID), what you're asking for access to (scope), and, optionally, a state. State is simply passed back to you at the end of a success or failure so you can remember the state at the origination of the authentication request. This means that if the user landed on a deep link in your application, the state is a perfect place to store that deep link.
Listing 2: Request for an auth-code
https://login.microsoftonline.com/{tenant}/oauth2/v2.0/authorize?
client_id=<clientid>
&response_type=code
&redirect_uri=http://Flocalhost/myapp/
&scope=openid offline_access https://2Fgraph.microsoft.com/mail.read
&state=12345
Of special interest is the redirect URI. The redirect URI is where the IdP, in this case Azure AD, returns the auth code. This URI must be something you control and trust. It must be HTTPS. A common mistake is to leave straggling redirect URIs in your app, such as something.azurewebsites.net. Remember, when you deprovision that azurewebsites.net URL, someone else can claim it, and hijack your application, because you forgot to remove that redirect URI. So keep that redirect URI list clean and at the bare minimum of what you absolutely need.
This request, if successful, returns an auth code, which is simply in the query string in the “code” parameter. Now you can use this one-time-use-auth-code to request an access token. The request to get an access token can be seen in Listing 3.
Listing 3: Asking for an access token
POST /{tenant}/oauth2/v2.0/token HTTP/1.1
Host: https://login.microsoftonline.com
Content-Type: application/x-www-form-urlencoded
client_id=<appid>
&scope=https://2Fgraph.microsoft.com%2Fmail.read
&code=<authcode>
&redirect_uri=http://Flocalhost/myapp.
&grant_type=authorization_code
&client_secret=<secret>
The request for an access token, if successful, returns an access token to all the scopes you have previously consented to. There are some important things to know about the request you see in Listing 3.
First, that it's a POST request played to the token endpoint. If you asked for a refresh token in scopes, you can also play that refresh token to this endpoint to get new access tokens without asking the user to sign in again. You request a refresh token using the scope offline_access. Effectively, this means that the user allows you to access functionality on their behalf, when offline. That is, the user doesn't need to sign in every time you ask for an access token. A common poor architecture is to store access tokens on durable storage, or to reuse refresh tokens across multiple nodes via durable storage, such as databases. This is a terrible idea and breaks the concept of non-repudiation.
The second thing you should note in Listing 3 is that the auth code is a one-time-use code. This is for security reasons. In this code, the redirect URI must match, down to the trailing slash, the same redirect URI you used to request the auth code.
The final thing to note about Listing 3 is that the client_secret you need to provide is only for confidential client applications. You can toggle the application to be a public client and not require the client secret to be passed.
Next up is the Implicit Grant, which is suitable for JavaScript SPAs. Implicit grant isn't recommended anymore, but where you can't control the back-end, such as on a SharePoint online site, and you must make Web service calls to a CORS endpoint from a JavaScript SPA, implicit grant is your only choice.
PKCE, or proof key for code exchange is where you supply a code at the beginning of your auth flow. When requesting access tokens, you must supply the same code. This mitigates many of the downsides of implicit grant and is commonly used on mobile applications. Work is underway on numerous identity providers to support PKCE on JavaScript SPAs as well.
Device code flow is where the device that's authenticating has a very limited UI. It simply shows you a code and you're required to open your browser on a laptop, visit a specific URL, enter that code, and finish the authentication process. In the meantime, that device with the limited UI polls an endpoint on the IdP, waiting for you to finish the authentication process, at the end of which it gets the access token and optionally a refresh token.
There are, of course, additional details and flows to talk about, but like any other topic, identity is a universe that you can keep diving deeper into. I'll stop here for now.
Scopes and Consents
I couldn't finish without briefly mentioning this important concept. Scopes is how you shape an API, or how a client requests certain claims. When I request the OpenID scope, I'm asking for the bare minimum claims that OpenID supports. But when I request the profile scope, I'm asking for the user's name, email address, etc. Similarly, when I ask for the offline_access scope, I'm asking for a refresh token.
Scopes also allow me to request access tokens, where the scp claim of the scope includes the audience against which my access token must work. For instance, a valid scope is https://graph.microsoft.com/user.read. When I ask for this scope, I'm asking for an access token that has the ability to read the currently logged-in user's profile on an API called Microsoft Graph.
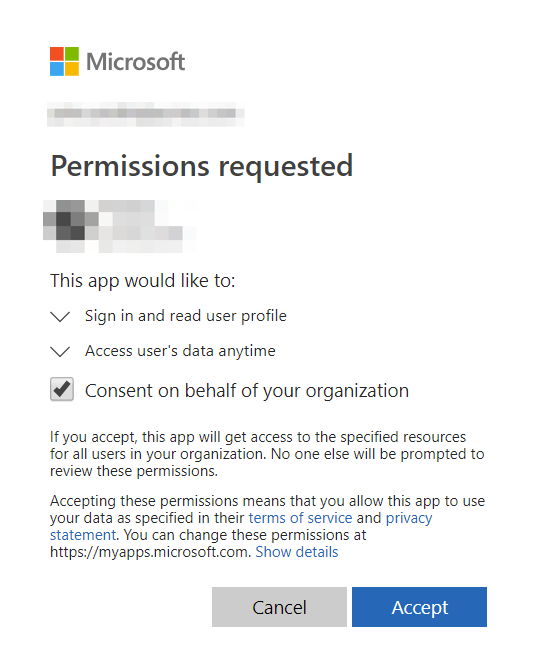
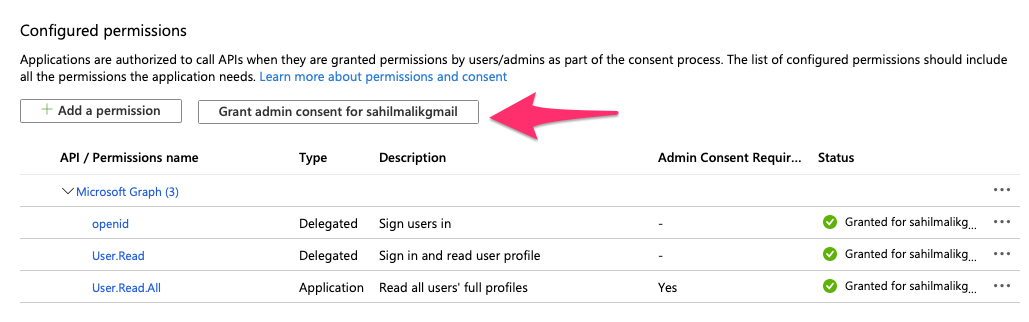
This means that the user must allow the act of reading the user's profile being read. This allowing act is called granting consent. Consent can be granted either during log in, by the user, as can be seen in Figure 3, or by an administrator during log in, ahead of time via an API, or via the Azure Portal, as can be seen in Figure 4.
Some specific scopes require an administrator consent. For instance, you wouldn't want some random user in your organization to grant the permission to register new apps, right?
Summary
This article is loaded with information, so if you read this far, congratulations. I don't pat myself on the back often, but the information in this article is very hard to find in a succinct, accurate, and easy to understand manner. I wish this basic information about identity was common knowledge to everyone. It would really make many tasks so much simpler.
Authenticating a user to your application is about as basic a requirement as it gets. Hardly any application doesn't have to deal with it. It's appalling how confusing it can be, given the complexities of the protocols and myriad platforms that make it so much more complex. There are some companies that have done a stellar job at making this dev story easier, but you still need to know the concepts.
I hope the concepts in this article help you get further ahead in solving identity challenges properly. And when articles talk about IdP, SP, RP, SAML, redirect URI, and auth code, you'll be well equipped to know what they are talking about.
Until next time, code securely.
