



JetBrains Rider is a cross-platform IDE that supports .NET, Mono, and .NET Core and technologies that use frameworks such as ASP.NET, ASP.NET Core, Xamarin, and WPF. Rider supports many languages, such as C#, VB.NET, F#, JavaScript, and TypeScript to build console apps, libraries, Unity games, Xamarin mobile apps, ASP.NET MVC, and other Web application types such as Angular, React, and Vue.js.
Find additional: .NET Core articles
Rider has many features to aid .NET developers in their daily work. It has support for supported languages through code completion, code generation, a large number of refactorings, navigation, over 2,300 code inspections, and much more. In addition to these coding features, Rider also has everything that .NET developers expect in their IDEs: a debugger, a unit test runner, a (fast!) NuGet client, database tooling, a WPF XAML preview window, version control, and integration with tools like Docker and Unity Editor is there as well. Even with all of these capabilities and features, Rider is fast, responsive, and memory efficient.
A Bit of History
Before we get into the technology and architecture of Rider, we must look at where this IDE came from. As far back as 2004, JetBrains was looking at a stand-alone application for the Visual Studio add-in ReSharper. It was never released, but a fully functional prototype was around at that time. As you can see in the snapshot of the ReSharper 2.0 UI in Figure 1, it provided a solution explorer, an editor, find usages, code completion, and refactorings. And although not a modern user interface, it's quite spectacular that the editor was able to provide adornments for displaying documentation in-line, given that it was built on .NET WinForms and Windows Presentation Foundation (WPF) wasn't around yet.
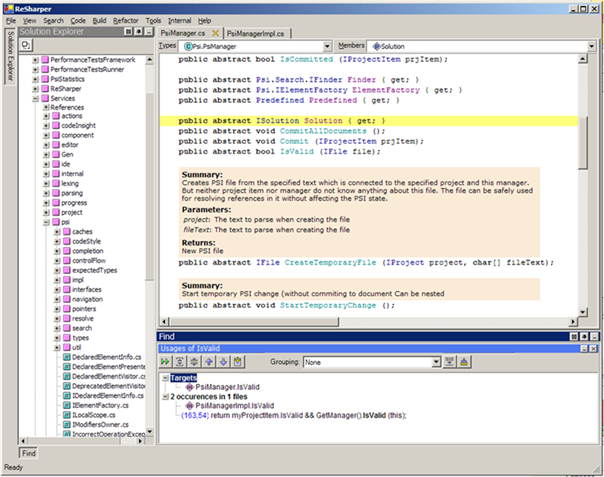
The project was halted, but the work didn't go to waste. A few valuable features for both future versions of ReSharper as well as what would become Rider were born, including the action system, text control implementation, several tool windows and toolbar controls, the unit test runner, and the ReSharper command line tools (CLI).
One of the design choices for the ReSharper 2.0 IDE was to keep functionality separate from the actual IDE. This approach helped future versions of ReSharper: It could support Visual Studio 2010, 2013, 2015, and 2017, all using the same core with an IDE interoperability layer on top. This design also proved key in being able to develop Rider. Roughly speaking, all that was needed was to plug another integration layer on top of ReSharper's core.
Much like with the ReSharper 2.0 IDE, JetBrains wanted to reuse as much of the existing technology and tools as possible (full disclosure: we both work for JetBrains). A logical step was to re-use the IDE platform that JetBrains had been building for years: IntelliJ IDEA. It supports many development scenarios and is the foundation of the other JetBrains IDEs, like WebStorm and IntelliJ IDEA Ultimate (https://www.jetbrains.com/webstorm/ and https://www.jetbrains.com/idea). And then there's ReSharper (https://www.jetbrains.com/resharper), which understands C# and VB.NET like no other IDE.
JetBrains set out on an adventure of marrying IntelliJ and ReSharper. One could provide a rich front-end and its existing tools, like version control and many more. The other could provide .NET tooling. Each is built on a different technology stack. IntelliJ is built on the Java Virtual Machine (JVM), and ReSharper is all .NET-based. We needed a way for both processes to be able to work together.
A Thin but Smart UI Layer
Rider runs IntelliJ as a thin layer on top of ReSharper. IntelliJ provides the user interface, displaying an editor and a text caret in a source file. Some languages, like JavaScript and TypeScript, have a full language implementation and Rider gets that, too. For other languages, like C#, VB.NET, and F#, the front-end has no knowledge about the language itself: This comes from the ReSharper back-end process.
When editing a source file, IntelliJ tracks what you're doing. For example, when you want to complete a statement, IntelliJ asks the current language service for completion items. C#, VB.NET, F#, and several other languages have no real implementation in Rider's front-end, and instead call into a facade language service that requests the information from the ReSharper back-end. This information then flows back into the front-end where a list of potential completions can be displayed.
Information flows in the opposite direction as well. Rider's IntelliJ front-end has the infrastructure to show code inspections (“squigglies”), but again has no notion of inspections for C#. When a file is opened, it notifies the ReSharper process and waits for it to analyze the file, run inspections, and gather highlights that should be displayed. ReSharper publishes a list of document ranges, inspection severity, and a tooltip text, and the front-end simply displays these.
In the end, Rider's IntelliJ front-end knows about some languages, providing several tool windows and things like version-control integration. For the .NET languages, it's really a thin UI layer that provides editing and other infrastructure, and it gets information from the back-end process when it's needed.
The Need for a Custom Protocol
Rider's IntelliJ front-end comes with a lot of infrastructure for editing, code completion, showing menu entries, code inspection results, and so on. The ReSharper back-end process has similar concepts of providing code completion, inspections and running refactorings.
Because of these similarities, JetBrains realized that we could work with a simplified model that's shared between the front-end and the back-end. When editing code, we could pass around small bits of text and deltas. Surfacing a code inspection meant providing a document range, a severity, and a description. If we can surface one code inspection from ReSharper in IntelliJ, we can surface all of them. If we can change chunks of code in the editor and make one refactoring work by passing around small chunks of data to update the model, we can make all refactorings work.
JetBrains experimented with various ways of passing around actions and small chunks of data between both front-end and back-end, such as:
- Re-using the Language Server Protocol (LSP), an idea we discarded. LSP is great and does many things, but it's also a lowest common denominator. Some refactorings in ReSharper are impossible to implement in LSP without bolting on many customizations. It's also unclear how LSP should handle languages like Razor, which typically mix C#/VB.NET and HTML, CSS, and JavaScript. There would have to be an LSP component for the separate languages, but also one for the combined languages. LSP would introduce many complexities and provide little benefit for our particular use case.
- Building a custom REST-like protocol where each process could call into the other. JetBrains experimented with various transport mechanisms and serializers, such as JSON and ProtoBuf. Unfortunately, this protocol proved slow, hard to customize, and hard to work with during development.
We realized that the main downside with both approaches was that they use a Remote Procedure Call (RPC) type of protocol. We would need to always think in a “request-action-response” flow, rather than having a more natural flow between front-end and back-end that are built on the same concepts. Instead of the front-end sending a “add file to solution message” to the back-end and then waiting for acknowledgement of updated state, we'd rather write a solution.Add(filename) in one place and have both processes in sync automatically, without having to think much about the conflict resolution or what would happen in case of an exception at that point.
Another realization came in the form of the type of data passed around. Coming back to inspections, this would be only a document range, a severity, and a description. Except in an RPC style, we need more details: Which solution is this inspection for? Which project in the solution? And which file? Every call would need such contextual information, making the RPC calls bulky and adding a lot of overhead for developers.
Our aha moment came when we tried modeling this protocol as a Model-View-ViewModel (MVVM) pattern. Its definition on Wikipedia states that MVVM “facilitates separation of development of the user interface (view) from development of the back-end (model) using a view model as a value converter.” IntelliJ is our view, ReSharper provides the model. And our protocol is the view model that shares lightweight data and data required for UI components.
Instead of having state in both processes and trying to keep them in sync, we have a shared model that both can contribute to. In essence, exactly what we wanted in the first place! When a developer adds a new file to a project in the front-end, the model is updated and both processes react on it. When a refactoring running in ReSharper adds a new file, that same model is updated and again, both processes can react on it. The model becomes our state, and both sides can subscribe and react to changes in the model.
Conflict Resolution
MVVM in inter-process communication doesn't solve conflicts. Changes can come from either the front- or back-end and may conflict. For example, the front-end may delete a file even as the back-end is running a refactoring and reports and updates to that deleted file in the model. When typing code while running a refactoring in the ReSharper back-end, how would you solve conflicting changes? Does the human who's writing code win? Does the back-end process that just rewrote code for our human developer win? How do you keep things synchronized?
One solution could be locking and preventing conflicts like this from happening. Except that nobody would like to see the IDE stop responding while a refactoring is running. Developers want to be able to delete that file, create a new one, and update the model even if some longer-running task hasn't completed yet. We want things snappy!
JetBrains decided on some basic concepts that prevent conflict resolution:
- There's a client and a server. For Rider, the client is IntelliJ and the server is ReSharper.
- Each value stored in the view model has a version.
- Every update of a value by the client increments the version.
- Server-side updates do not increment the version.
- Only accept changed values if the version is the same or newer.
When a value is changed by the client, the view model accepts it. If the server comes back with a change and the version number is lower, that change isn't accepted by the view model. This helps ensure that the client-side of the protocol always wins when there are conflicts.
Rider Protocol
JetBrains built and open-sourced the Rider Protocol using the MVVM approach and the rules for conflict resolution. But we didn't want to bother our developers with too many details of the protocol. Instead, we wanted the protocol to be more like Figure 2.

The lowest layer of the protocol provides the communication itself and works with sockets. Rider uses a binary wire protocol that sends across deltas. It provides batching, if needed, and supports logging to dump all data that goes over the wire. All of that is still too detailed to work with this protocol on a day-to-day basis! So JetBrains built a framework on top.
Having the IntelliJ front-end running on the JVM and the ReSharper back-end running on .NET, we created both a Kotlin (a JVM language) library and a C# library, both supporting several primitives. We also created a (Kotlin-based) code generator that allows us to define our view model in a domain-specific language using these primitives, and then generate code that can be used in the front-end and in the back-end.
JetBrains development teams only needed to know about these few primitives to work with the protocol, instead of having to learn all of the other magic that sits behind it. An added bonus here is that when using this framework, the protocol layer can be generated instead of having to work with reflection and introspection, helping in making it performant.
The protocol also supports the concept of lifetime, JetBrains' approach to managing object hierarchies. Instead of having to know when and where to dispose an object from memory, objects are attached to a lifetime and are disposed when the lifetime disappears. For example, a code inspection can be attached to the lifetime of an editor tab, so that when the editor tab is closed (and its lifetime ends), the inspection is also removed from memory. And that editor tab itself can be attached to the solution lifetime, so that when the solution closes (and the parent lifetime ends), all underlying objects are disposed of as well. Both IntelliJ and ReSharper make use of this approach, and the view model in the protocol should partake in this.
Next to lifetime, the protocol supports:
- Signals: events that are fired when something happens
- Properties: observable values
- Maps: observable collections
- Fields: immutable values
- Calls: RPC-style calls, something which is needed from time to time
All of these can pass around data types that are string, int, enum, classdef or aggregatedef (a node in the viewmodel), and structdef (object holding data).
This may all sound vague, so let's look at a simplified example. Rider's NuGet client supports working with various package sources. These all have a name and a URL.
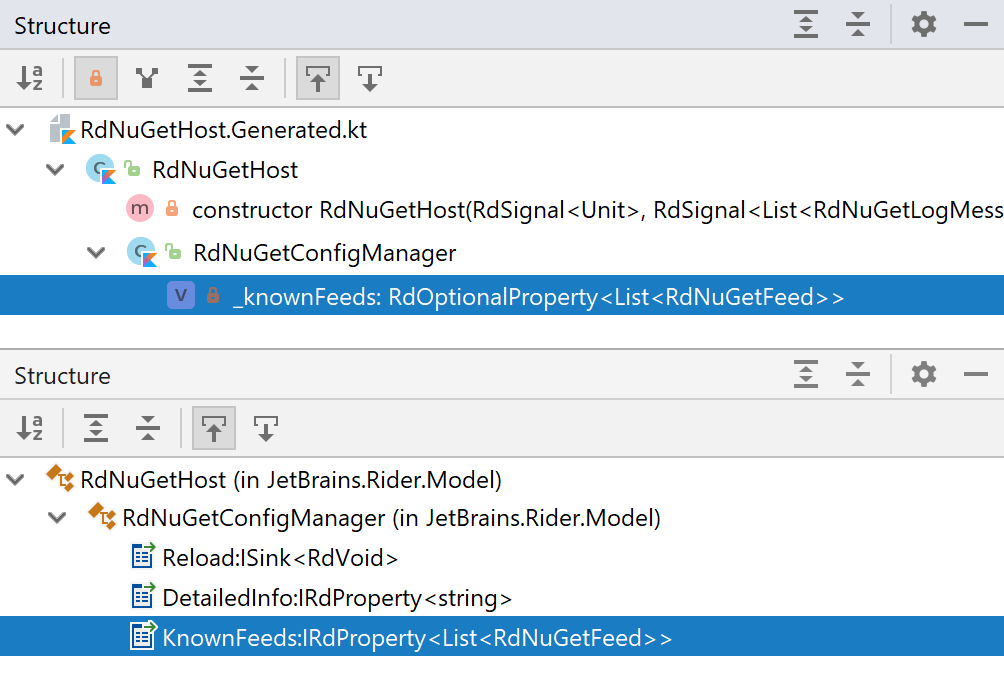
In the protocol, you define a view model node that holds NuGet client information (RdNuGetHost), which itself has a node that manages NuGet configuration (configManager) and has a property holding NuGet source names and URLs (knownFeeds).
object RdNuGetHost : Ext(SolutionModel.Solution, extName = "nuGetHost")
{
field("configManager",
("RdNuGetConfigManager")
{
property("knownFeeds",
immutableList(
structdef("RdNuGetFeed")
{
field("name", string)
field("url", string)
}))
})
}
After running code generation, you get a class definition in Kotlin, which the IntelliJ front-end can use, and a class definition in C#, which the ReSharper back-end can use, as seen in Figure 3.
You can then work against the generated protocol. For example, on the front-end side, you can set the list of feeds in the Kotlin programming language:
configManager.knownFeeds.set(arrayListOf(
RdNuGetFeed("NuGet.org", "https://api.nuget.org/v3/index.json")
))
You can subscribe to this list in the back-end .NET code and react to changes. Or you can enumerate the values in the list at a given point in time. You even get code completion, thanks to the protocol code being generated, as seen in Figure 4.
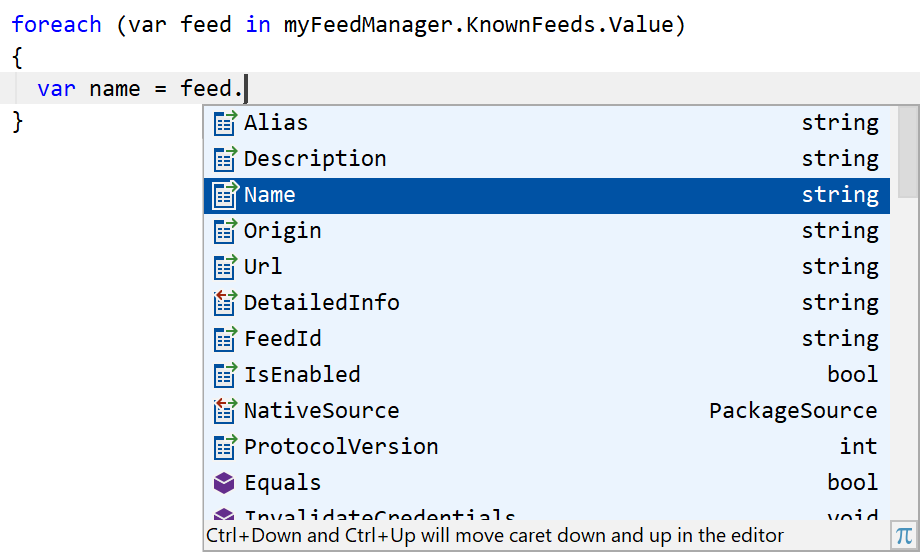
In essence, thanks to code generation for the protocol, you can work on the same model without having to worry about communication and state maintenance between the IntelliJ front-end and ReSharper back-end.
Microservices
We already discussed that Rider consists of two processes: the IntelliJ front-end and the ReSharper back-end. Because both are running on a different technology stack (JVM vs. .NET), Rider has to run multiple processes that communicate with each other using the Rider protocol. There are a few up sides to running multiple processes: each has its own 64-bit memory space, and on multi-core machines, there's a good chance that these processes may run on their own CPU cores, providing better performance.
There is another, equally interesting upside: isolation. Multiple processes run independently from each other (apart from communicating via the protocol), so they can run garbage collection independently, as well as start and stop independently. This last one is very interesting! Imagine you could start and stop processes as needed, with their own memory space, their own garbage collector, and potentially on their own CPU core?
Rider may run more than two processes, depending on the type of solution you're working with. When working on a Windows Presentation Foundation (WPF) project, there may be three processes running, as seen in Figure 5:
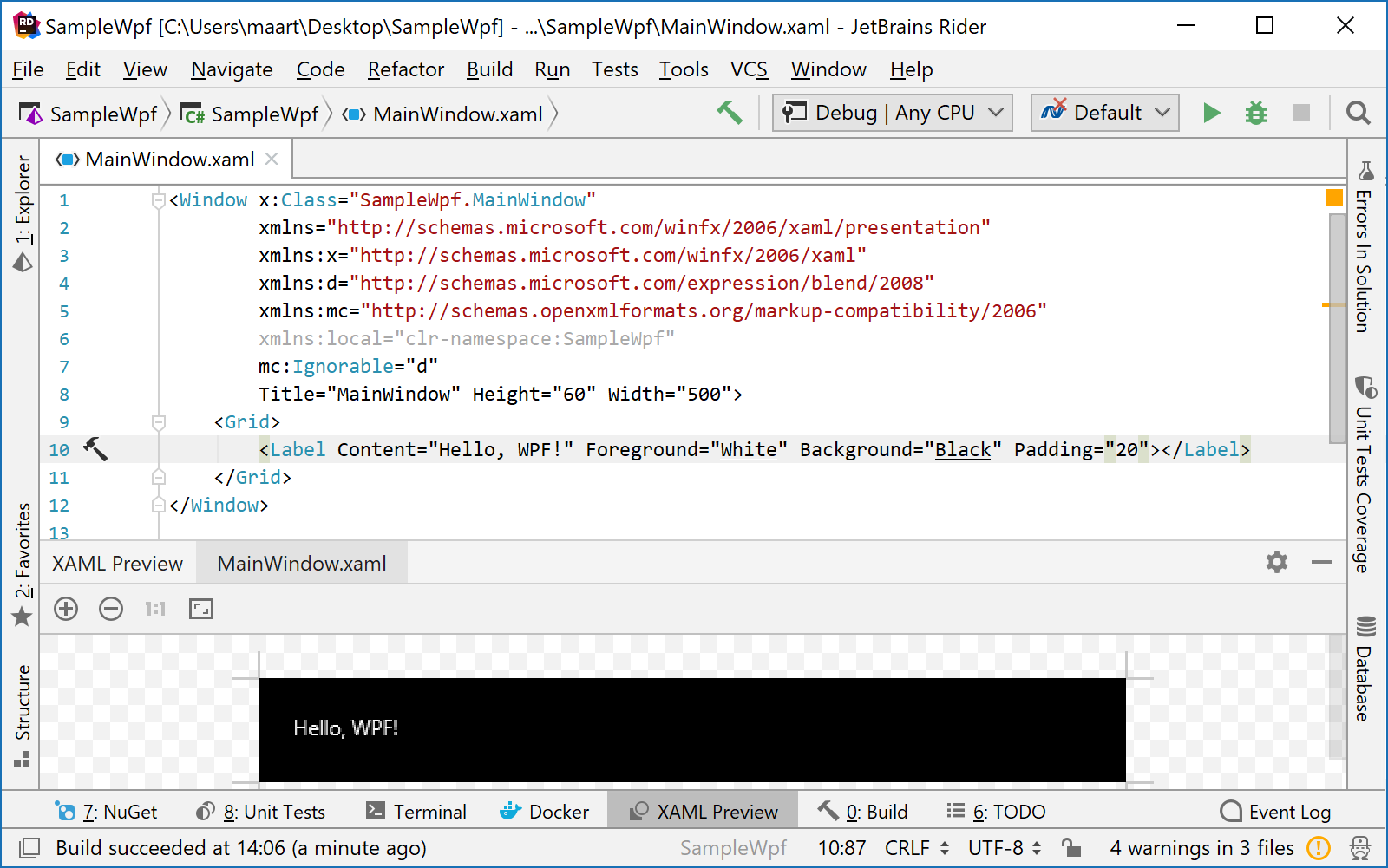
The editor itself is Rider's IntelliJ front-end, and code completion, code analysis, quick-fixes, and so on, are powered by Rider's ReSharper back-end. The XAML Preview window at the bottom is a third process: ReSharper's back-end will detect that you're working on a WPF application and spin up a rendering process that communicates a bitmap representation with ReSharper over another instance of the protocol (Figure 6).

Rider also supports running Roslyn analyzers. Many development teams write their own analyzers to provide additional tooling for the frameworks they build. The way this works in Rider is that the ReSharper back-end spins up a separate process analyzing code using Roslyn, and then communicates the results to the IntelliJ front-end (Figure 7).

The debugger also runs in a separate process, spawned by the ReSharper back-end and communicating using the Rider protocol. So when you have the XAML Preview tool window open in a project that uses Roslyn analyzers and you happen to be debugging that one, there will be even more processes running (Figure 8).
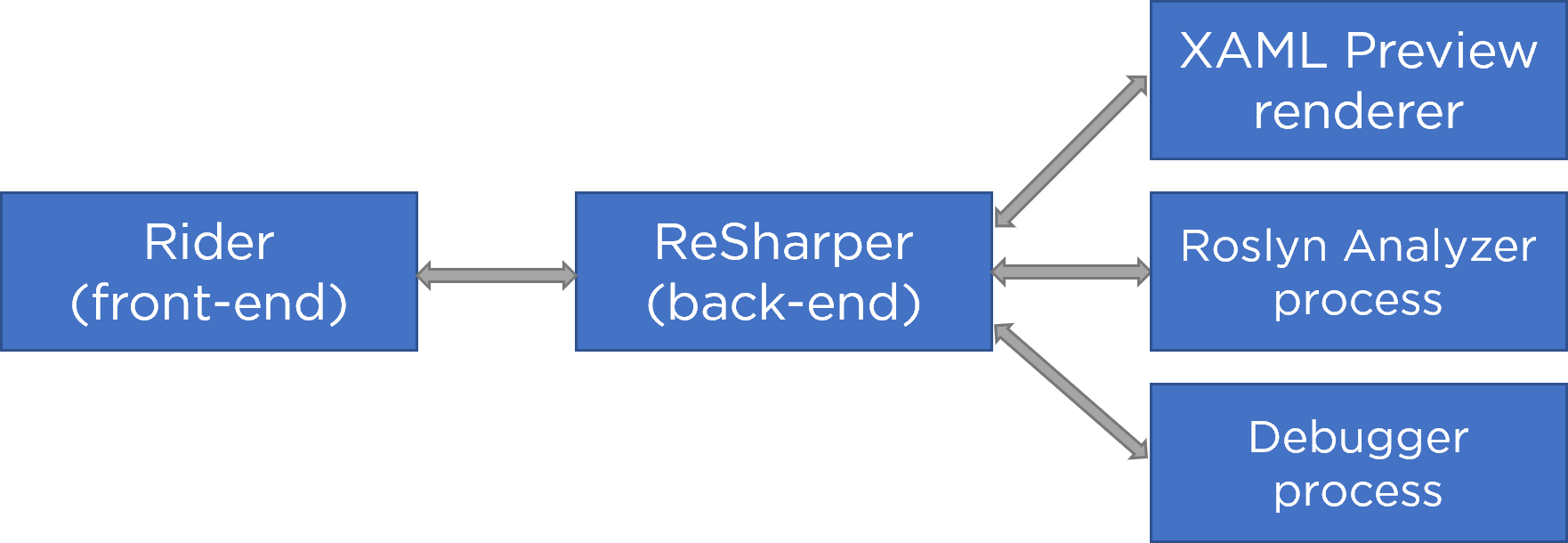
With an architecture where you can start and stop processes on demand, you can achieve a number of things:
- Separate memory space and independent garbage collection
- Start/stop functionality on demand, loading only the full feature set when needed by a solution
- Independent crashes. This becomes important in processes like the XAML Preview renderer, where you may have to render faulty user data. In those cases, you can fail gracefully and just stop one process instead of the entire IDE.
There is one additional benefit that we haven't discussed yet. Because the Rider protocol is socket-based, processes do not necessarily have to run on the same computer. For example, in the Docker debugging support, the debugger process runs in a Docker container (essentially a different computer), and communicates with the Rider's ReSharper back-end process. This opens the door to many possibilities, now and in the future.
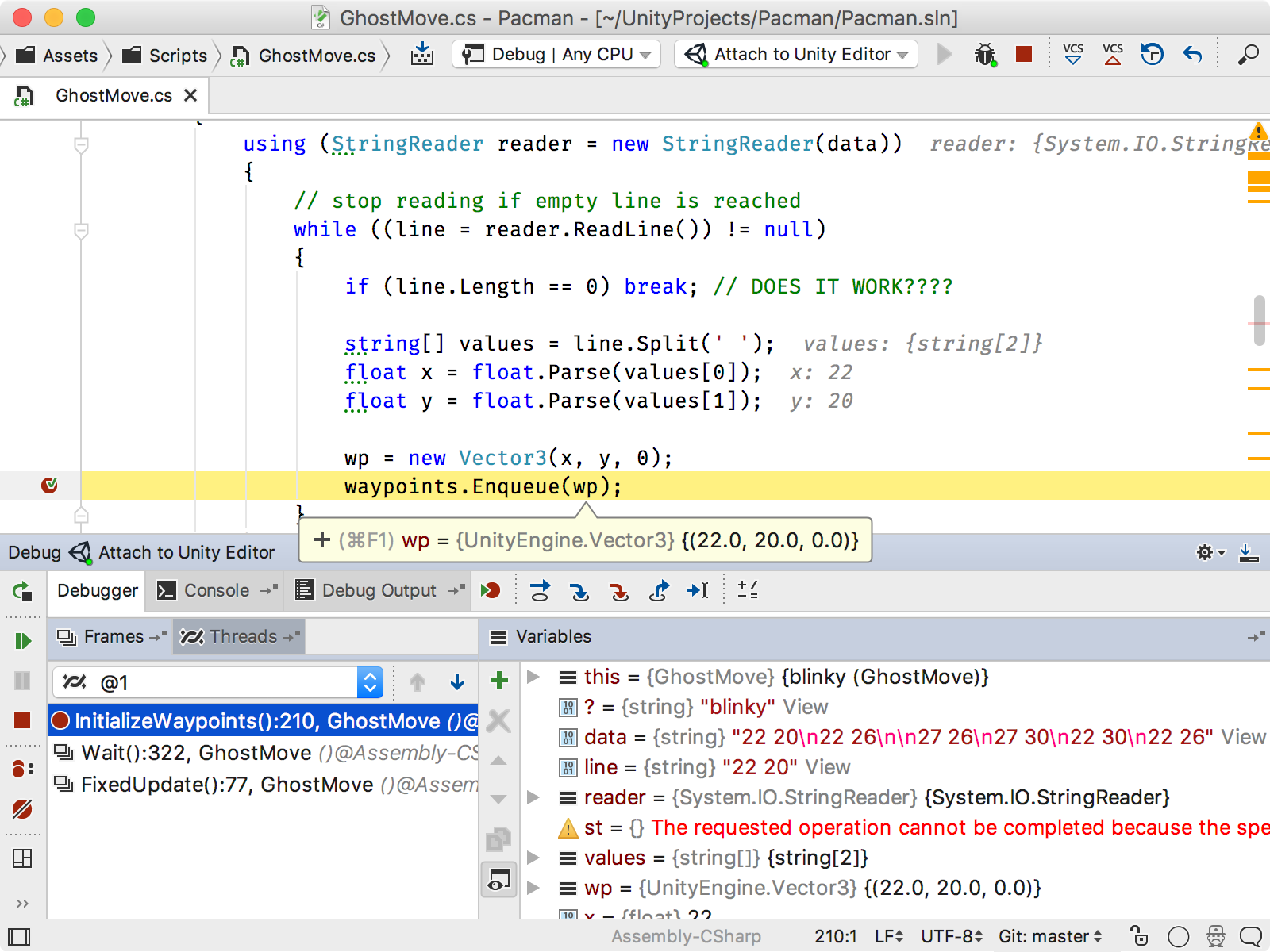
In almost all of the examples we've looked at so far, Rider owns the process that is started/stopped. For the integration with the Unity Editor, Rider doesn't own the process. Rider and Unity Editor can be started independently, but this doesn't prevent both processes from looking for each other's Rider Protocol connection. When both are launched and the connection is allowed, Rider can share its view model with Unity Editor and vice-versa. This lets Rider control play, pause, and stop buttons in Unity, and also provides the ability to debug code in Rider, even though it's running in the Unity Editor (Figure 9)!
In case you're interested in the internals of this plug-in, we have open sourced it (https://github.com/JetBrains/resharper-unity) so you can have a look at its IntelliJ front-end, its ReSharper back-end, and the Unity Editor plugin. Microservices!
What about the UI…
So far, we've focused on sharing the view model between Rider's IntelliJ front-end and the ReSharper back-end. What about the view itself? Surely, Rider must have a number of user interface elements and tool windows developed in the view side as well?
That's entirely correct. Surfacing code inspections and quick-fixes are really sharing a document range, severity, and description, and do not require any changes in the front-end as they re-use what is already in IntelliJ. In other places, for example, the NuGet tool window, you have to implement every feature on top of the protocol you've built.
While developing more recent versions of Rider, JetBrains did come to the realization that many user interfaces and user interface elements are similar in nature. For example, all inspection settings are roughly a list of inspections, their severity, and a Boolean that switches them on or off. The settings for these all share the same user control that binds that list to a grid view.
For many other settings, the user interface is often a header, followed by one or more pieces of text, followed by a checkbox, a textbox, or a dropdown. Instead of re-building those all the time, we've started building some standard views that you can populate using the protocol. For example, the C# Interactive settings in Rider are defined in the ReSharper back-end, using the following snippet of code:
AddHeader("Tool settings");
AddToolPathFileChooserOption(lifetime, commonFileDialogs);
AddEmptyLine();
AddStringOption((CSharpInteractiveOptions s) => s.ToolArguments,
"Tool arguments:")
AddHeader("Tool window behavior");
AddBoolOption((CSharpInteractiveOptions s) => s.FocusOnOpenToolWindow,
"Focus tool window on open");
AddBoolOption((CSharpInteractiveOptions s)=> s.FocusOnSendLineText,
"Focus tool window on Send Line");
AddBoolOption((CSharpInteractiveOptions s)=> s.MoveCaretOnSendLineText,
"Move caret down on Send Line");
The front-end can then render these, and in Rider's IntelliJ front-end, you'll see a proper settings pane (Figure 10):
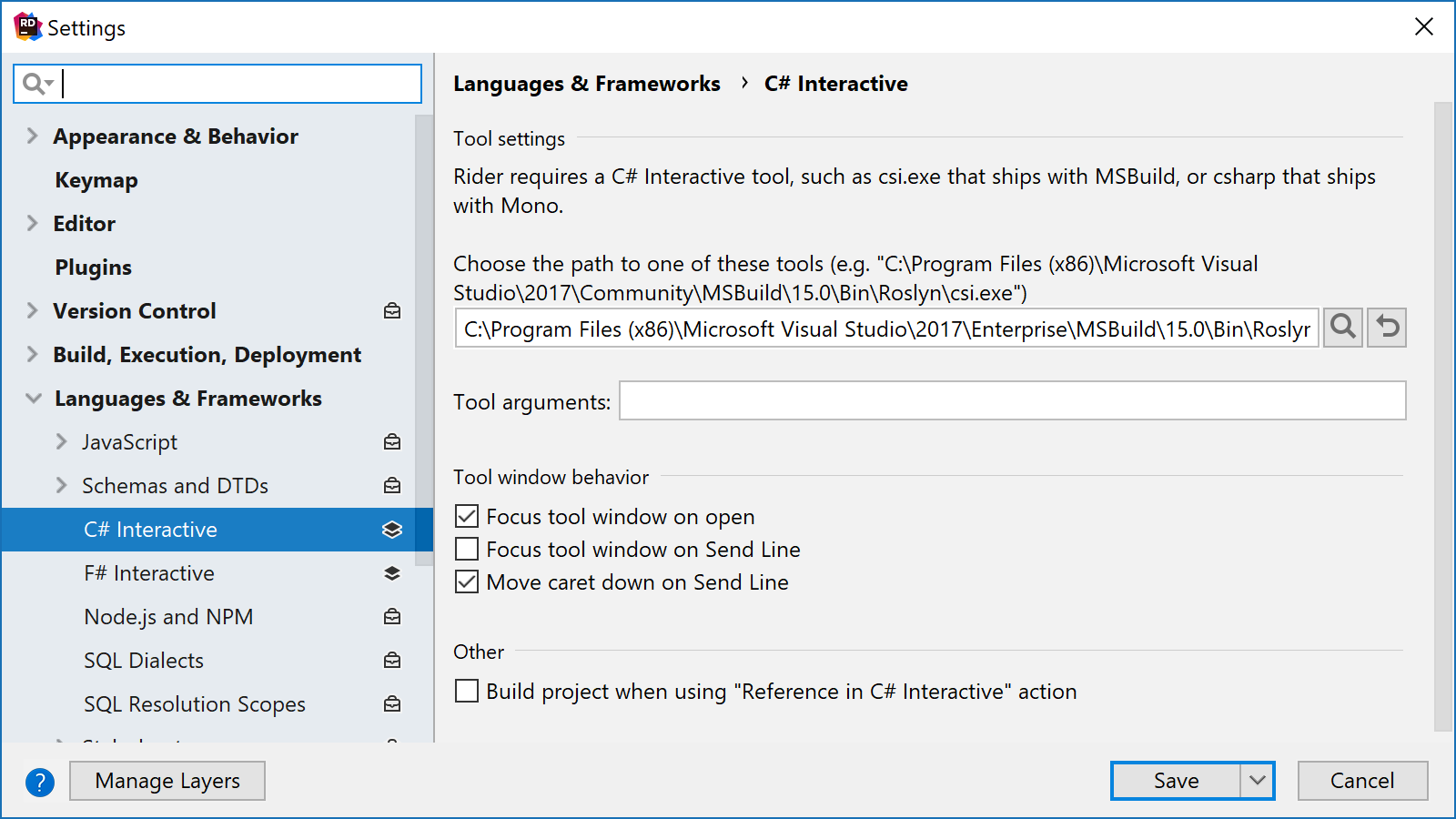
The benefit of defining user interfaces on the ReSharper side is two-fold. First, you no longer have to build the UI manually and can instead generate it from the protocol model. Second, because Rider and ReSharper are the same codebase, future versions of ReSharper can render these as well!
How Does Rider Make ReSharper Better?
We've touched on the fact that Rider re-uses as much as possible from ReSharper. The benefit of that is that features JetBrains adds to Rider are also available in ReSharper, and features JetBrains adds to ReSharper flow into Rider.
This also means that performance optimizations flow from one to the other. If JetBrains optimizes the speed of solution loading in ReSharper, Rider will benefit from that. If JetBrains optimizes loading of IDE components in Rider, ReSharper will benefit from that as well.
For Rider, JetBrains is focusing on getting the ReSharper back-end to run on top of the .NET Core CLR instead of requiring the full .NET Framework (on Windows) or Mono (on Mac O X and Linux). This effort will benefit Rider in that the runtime environment on all platforms will be .NET Core, instead of having two runtime environments today. Rider will also benefit from the many performance enhancements that were made in .NET Core, as will ReSharper.
Having Rider run ReSharper as a separate process also opens the door to running Visual Studio with ReSharper as a separate process. JetBrains is actively working on this, and this will provide the benefits outlined in this article: both Visual Studio and ReSharper will run in their own isolated processes and have their own memory space and, potentially, their own CPU cores. Together with the changes to support running ReSharper on the .NET Core CLR, this will greatly improve performance of ReSharper in Visual Studio!
Bringing in More Features: DataGrip, WebStorm, and dotTools
As you've learned from the history of Rider, the strength of the IDE comes from having the functionality from other IDEs in the IntelliJ family in the Rider IDE. For .NET and ASP.NET developers, JetBrains has integrated many of the features of the DataGrip and WebStorm IDEs into Rider, essentially by bundling existing plug-ins with Rider.
By bundling the database tools from DataGrip, Rider provides a rich experience for working with data and databases, supporting Oracle, MySQL, Microsoft SQL Server, Azure SQL Database, and many more. Rider users can write SQL code using the intelligence of the SQL text editor, execute SQL statements, view result sets, and navigate quickly through the database schema to look at the tables, views, and procedures with the database you're using.
JetBrains does want to go beyond simply bundling existing plug-ins and functionality. Because we feel that one and one should equal three, we're actively looking to extending functionality. How nice would it be if we could provide SQL code completion inside a string in a C# file? Or provide an Alt+Enter action to run that query? This is exactly what we're working on. Because we get the intelligence from both processes (and perhaps other contributing microservices), the IDE can become even smarter.
Other examples are in the bundled WebStorm features. With the rise of Web client-based development in the last decade, most ASP.NET and ASP.NET Core developers have seen the need to strengthen their use of JavaScript in their projects and solutions. Rider works and understands not only JavaScript in the editor but also the most popular Web frameworks today including Angular, React, and Vue.js. Rider lets you take advantage of checking your Web code using its own code analysis functionalities, combined with the most popular open-sourced linters available today. You also get to debug and test all of your JavaScript code independently from your .NET code using built-in debuggers and unit testing functionality from WebStorm. There's even a REST client to test your Web APIs built using ASP.NET and ASP.NET Core.
Right now, when working in a TypeScript file, all related functionality is provided by the WebStorm plug-in on the front-end. However, ReSharper also has many features related to JavaScript, TypeScript, HTML, and so on. We're working on combining the best of both worlds here by having both the front-end and the back-end contribute code analysis, completion, code generation, and all that.
In Rider 2018.2, code coverage and continuous testing is now integrated. This is powered by another back-end process: dotCover. Additional features will come from dotTrace (JetBrains' performance profiler) and dotMemory (JetBrains' memory profiler). Right now, these only run on Windows. The goal is to have these tools run on Mac OS X and Linux as well, bringing rich profiling features in Rider to those platforms, too.
Conclusion
The future of .NET and ASP.NET development is very exciting, and Rider wants to be a part of it. JetBrains has plans to add and improve support for many of the technologies that .NET developers use today such as Azure, WinForms, WPF, Xamarin, and .NET Core. JetBrains is also working to improve the performance of Rider by improving start-up time when opening .NET solutions, as well as adding zero-latency typing in the editors.
Some other things coming in the future include the ability to work with C++ code within solutions and projects, and opening up the plug-in ecosystem by providing an easier SDK that lets plug-in developers extend Rider's IntelliJ front-end, its ReSharper back-end, or both.
We hope this article provided some insights into the Rider IDE, as well as exposed the challenge faced when combining existing products that run on different technology stacks. Rider is a very rich and rewarding .NET IDE that you can use on Windows, Mac OS X, and Linux. Do try it out for yourself - there's a free trial available at https://www.jetbrains.com/rider.
