


A rewarding experience of writing and speaking is taking a seemingly complex topic and making it more understandable and accessible. In this article, I’ll show how to create and use OLAP databases and cubes using SQL Server Analysis Services 2008 (SSAS 2008). The benefits of OLAP are significant, even monumental - but like most technologies, reaping the benefits means considerable research and effort into leveraging the tools. In the case of OLAP databases, developers need to learn the differences between OLAP databases and relational databases, and how to use the tools that SSAS provides. In this article, I’ll walk through how to create an OLAP database and how to use the tools in Analysis Services to enhance the OLAP database. By the end, you’ll see why businesses and other organizations see the value of OLAP databases. I’ll also briefly cover some of the plans Microsoft has announced for the next generation of OLAP tools.
OLAP and Analysis Services
One of my primary objectives in this article is to “demystify” SSAS and OLAP database technology. I teach SSAS, OLAP, and MDX technologies to hundreds of students, and I understand the complexities of the learning curve with these tools.
In learning all the tools of the Microsoft Business Intelligence platform (also called the “BI stack”), I make the following analogy: that if learning the BI stack were like medical school, SSIS is like learning the bones of the human body and learning SSAS is like learning the brain and central nervous system. SSAS is like the central nervous system of business intelligence applications that use Microsoft OLAP.
Every year, I run into developers at Code Camp and other events who tell me that their employer is just now moving to OLAP. OLAP is a major paradigm shift for those who have worked for years with OLTP relational databases. So the need for walkthroughs that provide the right balance of theory and practice is essential. Too much theory and I’ll sound like a boring college professor - too much “click here, do this, do that” and it’s merely learning by rote.
What’s on the Menu?
In Sergeant Joe Friday-style (i.e., “the facts, just the facts”), here are the 13 items on the menu for this article:
- Defining a data source for an OLAP database
- Identifying fact table and dimension relationships (direct, referenced, many-to-many)
- Using the Cube Wizard to create an OLAP cube
- Using the dimension editor to create a clear presentation of business entities for end users
- Modifying fact table/dimension relationships
- Creating OLAP partitions to physically segregate active data that users query most frequently
- Creating OLAP aggregations to optimize data retrieval
- Creating OLAP calculated members with MDX
- Building graphical KPIs (Key Performance Indicators) using OLAP data, for view in different output tools that read OLAP information
- Using XMLA script to perform certain processing actions against OLAP databases
- Understanding the differences between MOLAP and ROLAP
- Implementing SSAS report actions to access reports against underlying transactional data.
- Implementing data security using SSAS roles
Some Basic OLAP Definitions
I’d like to provide some basic definitions for OLAP technology with Analysis Services. OLAP is a big culture shift for relational database experts. Those who know the old joke about two guys struggling to change a tire and acknowledge, “this stuff isn’t rocket science” will appreciate what I tell my student in my OLAP classes: that there are rocket scientists walking around saying, “you know, this rocket science stuff isn’t exactly OLAP technology.” So I’ll provide some definitions, in a narrative-format that follows this flow of the examples in this article.
I can use Visual Studio to create an SSAS project, which I’ll ultimately deploy to an Analysis Services OLAP database. I can deploy the OLAP database to a particular SSAS Server (localhost, production server, etc.). The source of the OLAP database is usually some type of SQL Server relational database, which could be normalized or de-normalized. In Tip 1, I’ll cover the process of defining the data source for an OLAP project.
The OLAP database usually contains one or more OLAP cubes. Figure 2 shows an example of an OLAP cube. Generally speaking, a cube is a geometric object with many sides (dimensions). In the case of databases, an OLAP cube contains fact tables and business dimensions.

OK, so what are fact tables and dimensions? Fact tables contain facts (“measures”), such as revenue, costs, spending, quantity sold, etc. Dimensions are the business entities that provide context for the facts; loosely-speaking, they are the master files from an OLTP system, such as an account master, a product master, date master, cost center master, etc. Virtually every OLAP cube will have a date dimension - it is almost a universal dimension. (Imagine an OLAP cube where users DIDN’T want to slice numbers by year, quarter, week ending date, etc.)
The cube automatically ties (relates) the facts to the dimensions, regardless of whether the relationships are direct, referenced (indirect) or even many-to-many. In Tips 2 - 4, I’ll cover these issues.
Internally, the OLAP cubes contain bitmap indexes that (loosely speaking) “auto-join” facts and dimensions so that end users can “slice and dice” measures by business dimensions, without needing to write any code.
At this point, it’s VERY important to understand that each fact table has a statement of granularity - in other words, the dimension level at which the facts are stored. So an OLAP cube might have one fact table built at the reseller account/product/date level, and a budget fact table at the employee and quarter level. (To give you some historical appreciation - Analysis Services 2000 only permitted one fact table pure OLAP cube.)
Each fact table has a statement of granularity - in other words, the dimension level at which the facts are stored. So an OLAP cube might have one fact table built at the reseller account/product/date level, and a budget fact table at the employee and quarter level.
In Tips 2 - 5, I’ll also cover several dimension components and how they relate to fact tables. Each dimension contains attributes, which are the equivalent of relational table columns. Loosely speaking, attributes are the “by” in business user language (e.g. “I want to look at sales by product color, by geography market, etc.”).
Attributes can form parent-child relationships, such as markets rolling up to regions, regions rolling up to zones, products rolling up to categories, months rolling up to years, etc. These relationships are known as hierarchies, and help end users to traverse these parent-child relationships through rollup and drilldown activities. It should be noted that not all attributes form parent-child hierarchies - some attributes (product color, for instance) might not be related to any other dimension attribute.
When fact tables get very large, I can split each cube fact table into multiple OLAP partitions. I can build my own partitioning scheme, such as creating an active partition for the last full year of data and one or more archived partitions for prior years of data. In Tip 6, I’ll show how to create OLAP partitions.
Additionally, I can also build OLAP aggregations inside each OLAP fact table partition. OLAP aggregations are sometimes one of the more misunderstood features of Analysis Services. Because OLAP users are able to roll up data in OLAP cubes very quickly (e.g. roll up sales from day to year), many assume that OLAP cubes somehow store every possible combination of subtotals for each measure.
This assumption is false - by default, SSAS OLAP databases do not store calculated subtotals. Instead, the Analysis Services engine automatically performs “on-the-fly” aggregations when users want to roll up measures, such as sales by country, brand, and year. Even critics of Microsoft products acknowledge that Analysis Services performs on-the-fly aggregations very rapidly. However, at some point, a fact table partition will still grow in size to the point where pre-stored calculations at higher dimension levels will help with performance. So Analysis Services provides aggregation functionality that allows OLAP developers to see what queries have been run by users (and how long they took), and also to build aggregations based on specific dimension attributes. I’ll look at aggregations in Tip 7.
The programming language to query OLAP databases is MDX (Multidimensional Expressions). MDX initially appears similar to T-SQL - but is actually very different. Suppose I want to see sales summarized by month, along with sales for the same time period a year ago. I can write an MDX query, or I can use one of the OLAP query designers in an Excel OLAP PivotTable, SSRS report, or a PerformancePoint Services dashboard to generate the MDX code. One could write a book on MDX, but I’ll at least cover some MDX basics in Tip 8.
Another important topic in business intelligence applications is KPIs, which stands for Key Performance Indicators. KPIs are business performance metrics (% of sales goal, % damages, % returns, % shortages, % good customer reviews) that developers can render as graphic visualizations (a green light or smiley face or similar image for a “good” status, and a red light for a “bad” status). Some KPIs are “trend-based” - for instance, a company might have a sales goal to increase revenue by at least 5% every year. Developers often write KPIs in MDX. I’ll cover some KPI examples in Tip 9. Note that some executives view KPIs as one of the most important components of an OLAP/Business Intelligence solution.
When OLAP developers are ascending the SSAS curve (and sometimes believing along the way that rocket science is easier!), they often wonder how to programmatically update OLAP cubes. In the course of a week, the business may have ten new accounts, three new products, and a week’s worth of sales. While the easy approach might be to load the SSAS Project in Visual Studio and reprocess/redeploy the OLAP database from the source data, this approach will be very impractical on an on-going basis. And so in Tip 10, I’ll cover some SSAS processing tasks using XMLA script that developers can write in Integration Services, to programmatically (and incrementally) update OLAP fact/dimension contents.
Another topic in the world of OLAP is storage persistence modes. There are three: MOLAP, ROLAP and HOLAP. Tip 11 will cover MOLAP and ROLAP. This topic is very difficult to cover in a few sentences without delving deep into specifics, but for now, here are two pieces of information. First, in MOLAP, data from a relational data store is physically synthesized into an OLAP cube structure. By contrast, in ROLAP, the cube is basically a virtual definition, which means MDX queries to retrieve OLAP data are passed back to the relational source (as SQL queries). HOLAP is a hybrid approach. Second, the vast majority of OLAP implementations use MOLAP (which is the default storage mode). Conservative estimates are that 80% of OLAP installations use MOLAP, while other estimates place it at over 90%.
Database teams sometimes face a challenge on whether to store transaction level data into an OLAP cube. OLAP cubes are traditionally for analysis at higher business dimension levels, where the need to drill down to transaction details is only necessary when one sees some business anomaly. In this instance, SSAS developers can build drill-out report actions from the cube, to “hook” into SSRS reports that might exist in an OLTP or Data Warehouse situation. This allows OLAP developers to extend the analytic path from an OLAP cube to an external report, and provide the end-user with one-click access to an external SSRS report while browsing an OLAP cube in Excel. In Tip 12, I’ll cover an example of this outstanding (but sometimes underutilized) feature.
Finally, in many corporate environments, associating users with segments of the database is extremely critical. A brand manager should only see data for his/her brand, a region manager might only have access to specific accounts, etc. In SQL Server relational databases, developers need to build a variety of solutions such as creating authorization tables that link end users to specific data, creating database views, and/or adding logic to stored procedures. While the relational database engine never “stands in your way” of doing this, it also doesn’t provide anyone with out-of-the-box capabilities for associating users with specific dimension rows. Fortunately, in OLAP databases, we can build SSAS database roles into OLAP cubes. This feature allows developers to associate Windows users (or user groups) directly with specific dimension data - the role feature itself leverages how SSAS exposes dimension data in a way that might remind .NET developers of typed datasets. In Tip 13 I’ll show how SSAS roles work.
So that’s an overview of OLAP terminology and an overview of how I intend to cover these terms in this article. But there’s still one important question - why is OLAP so important? Can’t we simply provide OLAP-style functionality without going through the steps of creating OLAP databases using SSAS?
Why Is OLAP Important?
The title speaks for itself. Here are some reasons:
- Retrieving data from an OLAP database can be faster - in some cases, MANY times faster, than retrieving data from relational databases. As databases grow in size, the performance gains from OLAP increase, even significantly. It is not uncommon for OLAP retrieval to be at least 10 times faster (or more) than with relational databases.
- End users (“information workers”) can generally retrieve data from OLAP databases more easily than from relational databases. I’ll cover this in more detail throughout the article. While OLAP isn’t always a pure silver magic bullet, it still provides users with (comparatively) greater opportunities for analytic discoveries without needing a developer to write code.
- Related to the previous point, users can easily navigate dimensional hierarchies, either for drill-down or roll-up activities.
- A secondary benefit of OLAP is that developers can best leverage certain features from some analytic tools (like Microsoft PerformancePoint Services in SharePoint 2010) when using OLAP databases.
- Analysis Services allows you to define security roles to limit user access to data. For example, you can define that Windows Users A and B (or Windows Group XYZ) can only see data for Markets A and B and Product Brand XYZ - often without writing any code. By comparison, in a relational database environment, developers/DBAs must create authorization definition tables, views, logic in stored procedures, etc.
- Analysis Services provides hooks (known as Report Actions) for users who want to extend the analytic path of a cube back to the source transaction data.
- OLAP cubes are smaller than the original data source. Numbers will vary, but OLAP cubes are often just 20-25% of the size of the original relational source.
OLAP Scenarios
Frequently, those new to OLAP ask questions about updating OLAP cubes. Most people just assume (understandably) that the Analysis Services OLAP engine contains DML-like statements to add/update/delete OLAP data.
As it turns out, updating OLAP data is very different than updating relational data. Analysis Services contains what are called XMLA processing commands, and they operate at a higher level than row-based DML statements.
Figure 1 provides a high-level view of an OLAP environment. Typically, companies will build OLAP databases from some relational database staging area (or data warehouse) that contains a clean and validated version of data/transactions. The transactions in this staging/warehouse area are generally not likely to change. Developers use different XMLA commands (that I’ll cover in Tip 10) to populate OLAP tables in different update scenarios. But before I go any further, there are a few points that are important to mention:
- Figure 1 represents just one overall environment. Sometimes the staging area may be a transient area that holds data for a period of time, such as new sales information on a weekly basis.
- In less common situations, the source of an OLAP database could be a relational system, where end-users want OLAP functionality from real-time data. In this instance, developers might use a methodology known as ROLAP, which I’ll cover in Tip 11. The point to remember is that 50 different organizations could approach OLAP in a handful of ways.
- Contrary to popular belief, OLAP databases are NOT data warehouses. A data warehouse contains a clean version of historical transactions, while the level of granularity of an OLAP database might be more summarized.

So What Will We Have at the End?
This article will present a somewhat stripped down version of the larger AdventureWorks OLAP project that comes with SQL Server 2008 R2. It would take several articles to reproduce every single feature of the AdventureWorks OLAP database, so I’ve selectively taken portions of the AdventureWorks sample. In a few instances, I’ve also provided some enhancements to the database. Overall, I’ll create a cube with four fact tables and eight dimension tables and different relationship types. Not rocket science, but not child’s play either.
Figures 25-27 contain some Excel Pivot Tables we’ll be able to produce. To this day, Excel remains a popular tool for viewing OLAP data. I can’t emphasize this enough: the OLAP database that I’ll create will contain several dimension relationship types (regular, references, many-to-many). The very nature of OLAP cubes will allow end users to “slice and dice” data without needing to write a single JOIN statement. This is one of the signature themes of OLAP - empowering end users. Here are some of the things I’ll be able to do with the OLAP database:
- View Internet (Customer) sales and Reseller (Vendor) sales together by Geography, Product, and Date attributes.
- View Internet and Reseller Sales by different international currencies, using an exchange rate bridge table.
- View Reseller sales by Employee Sales Person and quarter, compare to Employee Sales Quota for the same quarter, and render a graphic KPI to show performance against the goal.
- View a transaction-related report from another server (in as little as two mouse-clicks), while browsing the OLAP cube in Excel.
- Define which end users can view which part of the OLAP cube.
Tip 1: Defining OLAP Data Sources
I’m going to write these tips in a step-by-step narrative so that anyone who wants to reproduce this project can do so. I’m assuming you’ll have SQL Server 2008 R2 developer (or Enterprise Edition) installed. If you have the original SQL Server 2008 Edition that should suffice - you’ll just use the AdventureWorks2008DW database instead of the R2 version. Note: I make no promises that this will work with the standard edition of SQL Server 2008/2008R2.
First, you need to open Visual Studio (or Business Intelligence Development Studio) and create a new Analysis Services project. (Figure 3 contains a copy of what Solution Explorer will look like for the SSAS project, once we’re finished.) I’ve called the project MiniADW2008R2.
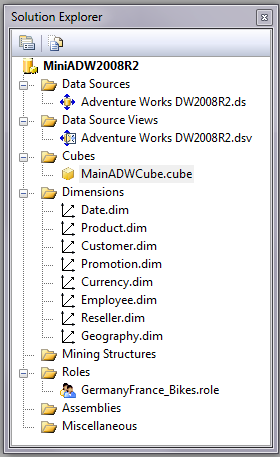
Second, in Solution Explorer, you need to right-click on Data Sources and create a new Data Source. Why? Because in just about every case, an OLAP cube needs an original source of data. While a Data Source is just a glorified connection string, it still tells SSAS where to read for the underlying data. What type of database will constitute the source? Here are some options:
- In many cases, it will be a data warehouse or a staging area that represents new data for the week/fortnight/month that will ultimately go into a data warehouse. Often, this source will be a SQL Server relational database, and very likely de-normalized.
- Less common, the source will be a relational/OLTP database. In Tip 9, when I discuss ROLAP, I’ll explain why.
Third (well, really an extension of the second step), BIDS will prompt you to create a connection string to the underlying data source. You can specify the server where AdventureWorksDW2008R2 resides (whether it’s your localhost server or another database server), and then the AdventureWorksDW2008R2 database itself.
So that’s it for creating a data source. There are two more items I’ll mention. First, there’s an additional option in the data source for the Impersonation method. This is the account that the Analysis Services engine will use when connecting back to the relational source. Remember that it might not be “you” - Analysis Services might run a job at the proverbial “two o’clock in the morning” to update the OLAP data from the relational source. So the impersonation account might be some type of system/service account, or a specified account/password that an I.T. manager provides. For this example, I’m using the standard Analysis Services service account.
Second, by default, the Analysis Services engine reads the relational source using the Read Committed Transaction Isolation Level. In most instances, this default is fine and doesn’t need to change. However, in situations where users want OLAP functionality with real-time access to the underlying relational data (see Tip 11 on ROLAP) using Read Committed might lead to locking timeouts. In this situation, you may need to change the isolation level to Snapshot. You’ll also need to change the connection string to turn on MARS (Multiple Active Result Sets).
Tip 2: Fact Table and Dimension Relationships in the Data Source View
OK, so I’ve created a Data Source - what next? The next step is to create a Data Source View (DSV). Here’s the reason for the DSV: You need to tell the Analysis Services project what specific Data Source tables to use in the OLAP database.
Additionally, we need to tell the Data Source view how the tables are related - SSAS will take those table relationships (either direct, indirect, or many-to-many) and build those relationships into the OLAP cube. So the DSV is more a definition than anything else - an abstract representation that the SSAS engine will use to create the OLAP cube.
In most instances, you won’t select all of them - even if you intend to use a specific database exclusively for an OLAP database, there might be control tables and other miscellaneous tables for managing the database. So you can right-click in the Solution Explorer project on the Data Source View folder, and create a new Data Source View.
Here’s where I’ve deviated from the built-in AdventureWorks OLAP project example. So, SET DEVIATION ON. Instead of using all the fact tables and dimension tables from AdventureWorksDW2008R2, I’ve selectively chosen four fact tables and seven dimension tables - smaller than the full-scale ADW project, but enough variety to see some of the major SSAS/OLAP concepts.
Additionally, I’ve deviated in a second way. The AdventureWorks tables contain more columns than I need to demonstrate the necessary points of this article - so I’ve built views on top of the tables to grab only the columns I need. Table 1 contains the 11 tables I’ve used for this example, and the names of the views. The download project for this article contains all the T-SQL listings for the views. (Purely for space purposes, the code listings don’t appear in this article.) However, I’d like to talk about one piece of code from the view that creates vDimDates:
DATEADD(d,
7 - DATEPART(dw, FullDateAlternateKey),
FullDateAlternateKey) AS WeekEndDate
DATEADD(d,
4 - DATEPART(dw, FullDateAlternateKey),
FullDateAlternateKey) AS BaseDateForMonth
The core version of ADW DimDates doesn’t contain a date attribute that I’ve had to build for clients for years - a week ending date. So I’ve created one, simply by taking the Day of Week of the core date, subtracting it from 7 (the # of days in a week) and then adding the result to the core date. Note that this code assumes a Sunday to Saturday week - if your company uses a different definition for a fiscal week (e.g. Wednesday to Tuesday), you’d need to use the @@DATEFIRST and SETDATEFIRST statements.
Additionally, to try to showcase as much date functionality as possible, I’ve added something else to vDimDates. The default DimDates sets the Month and Quarter and Year attribute based on the actual calendar date. So 12/30/2007 is part of the month of December and the year of 2007. However, as I illustrate in Figure 4, 12/30/2007 belongs to a week that ends in 2008, on 1/5/2008. Since the week contains more days in January of 2008 than December of 2007, I’ve placed the entire week into January 2008. (Many people ask how to do this: in my example code snippet above, I’ve taken the “middle” day of the week, Wednesday, to determine which month/quarter/year to use).

OK, SET DEVIATION OFF - it’s time to build the Data Source View. You right-click on the Data Source View option in Solution Explorer, and create a new DSV. BIDS will prompt you to select the tables from the data source you created in Step 1. Figure 5 shows the dialog box where you select the tables. Note that in Figure 5, you’re selecting the views that I mentioned in Table 1.
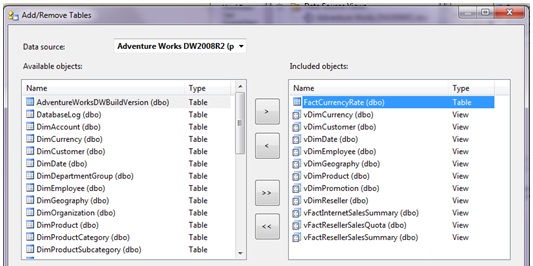
After you select the tables in Figure 5, BIDS will display the tables in a table diagram format (Figure 6). Another critical point: had the tables contained primary key/foreign key relationships, the BIDS DSV designer in Figure 6 would have drawn relationship arrows. But because I specified views (from Table 1), I need to build the relationships between the fact tables and dimension tables manually. Again, the SSAS engine will build these relationships into the OLAP cube.
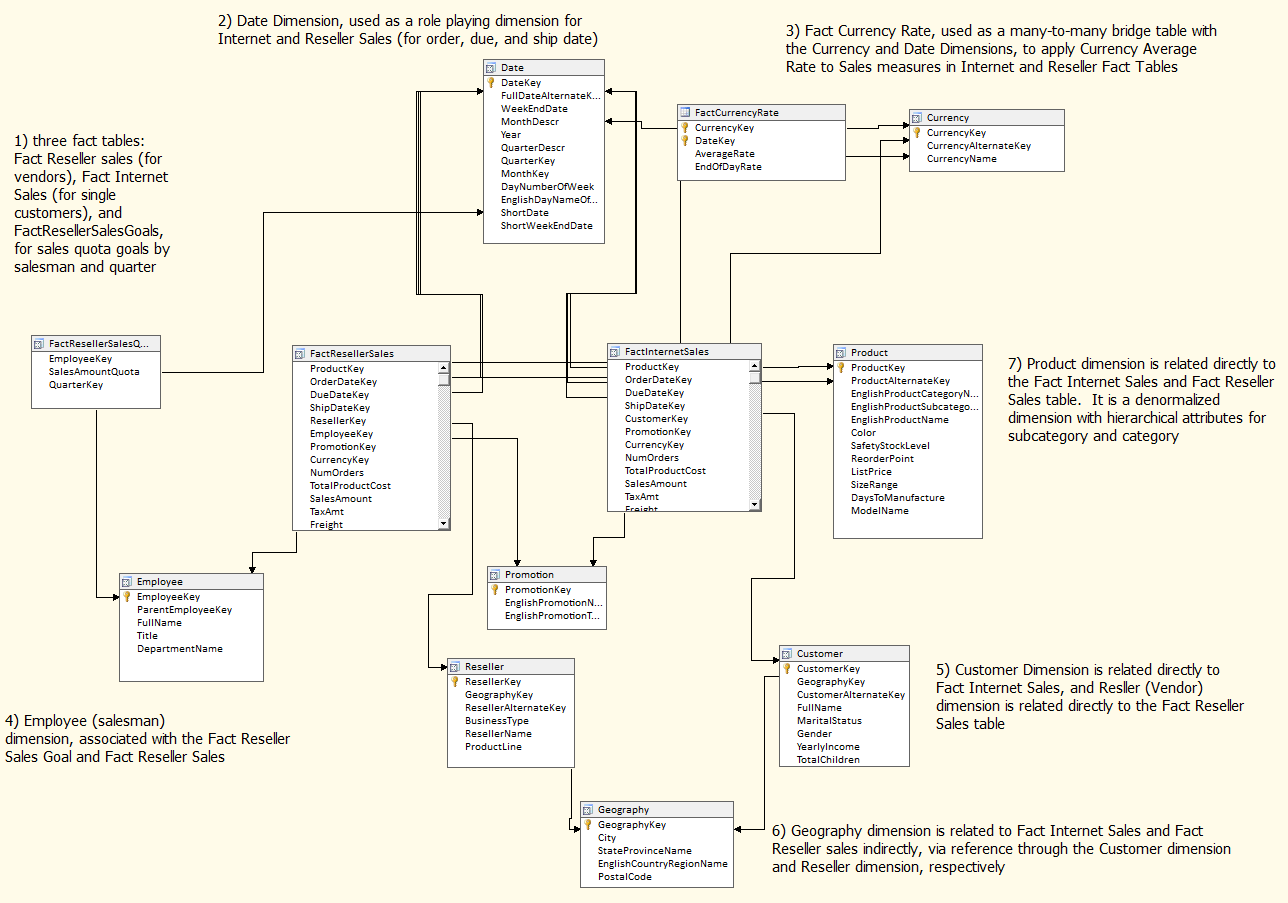
The relationships I need to create (by dragging the key column from the dimension table to the fact table) fall into three categories. First, here are the direction relationships:
- Product dimension is related to FactInternetSales and FactResellerSales (on ProductKey)
- Customer dimension is related to FactInternetSales (on CustomerKey)
- Date dimension is related to all fact tables on DateKey
- Reseller dimension is related to FactResellerSales (on ResellerKey)
- Employee dimension is related to FactResellerSales FactResellerSalesQuota (on EmployeeKey)
- Promotion dimension is related directly to FactInternetSales and FactResellerSales
- Currency dimension is related directly to FactCurrencyRate
Second, the following relationships are considered referenced/indirect, or “snowflake” relationships:
- Geography dimension is related to FactResellerSales and FactInternetSales through the direct relationships between those tables and DimReseller and DimCustomer, respectively. This will allow us to view reseller sales and Internet sales side-by-side, by geography, even though the two fact tables do not carry a geography key directly.
The following relationships are considered many-many bridge table relationships:
- Currency is related to the two many fact tables, using the FactCurrencyRate as a bridge. This bridge functions correctly because both fact tables also slice by the date dimension, which is also found in the FactCurrencyRate bridge table. In the end, this will allow us to view sales by any other currency by applying the exchange rate for that day and that currency.
If you want to take a “sneak peak” ahead to Figures 8 and 15, you’ll see what BIDS and SSAS does to create the OLAP fact table/dimension relationships from this DSV. (Many call the dimension usage diagram in Figures 8 and 15 a “dimension bus matrix”). Figure 8 contains the initial dimension usage that SSAS builds from the DSV (using the Cube Wizard that I’ll cover in the next tip.) Figure 15 contains a modified version of the dimension usage, after I perform some “post-wizard surgery.”
Tip 3: Using the Cube Wizard to Create a Cube and Dimension Usage
Now that we’ve defined the dimension and fact table “players” for the OLAP database, I can take the next major step towards creating the OLAP cube. The SSAS project in BIDS contains a Cube Wizard that allows me to point to the DSV (from the previous step). You can access the Cube Wizard by right-clicking on CUBE in Solution Explorer to create a new cube using the Cube Wizard.
The Cube Wizard will prompt you for the Data Source View to use, and then will display a screen similar to the one in Figure 7. The Cube Wizard screen displays all the tables from the DSV, and asks which tables are the fact tables. There is a Suggest button you can click, which will determine which tables are the fact tables (by reading the relationships from the DSV).
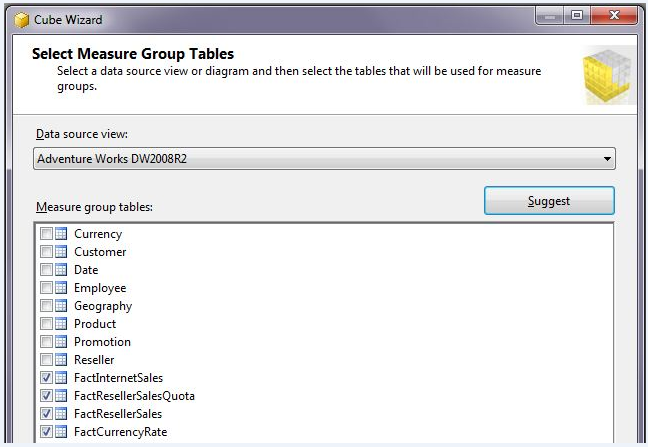
In most instances, the Suggest button accurately detects the fact tables. However, sometimes the Suggest button will misreport a dimension table as a fact table - this usually happens when the dimension table is part of a snowflake schema and also contains a column that SSAS believes it can aggregate. In this situation, it is very important to uncheck the checkbox, as this will prevent you from using the dimension for the intended purpose.
After taking the default options for the remaining Cube Wizard screens, BIDS will add a cube definition and dimension definitions to Solution Explorer. At this point, I DON’T yet have an OLAP database, but rather, a project structure definition for one. I’d need to deploy/process the project, but I’m not yet ready to do that.
After running the Cube Wizard, the most important thing I can do is double-click on the new cube definition in Solution Explorer. This loads the SSAS cube editor, where I can add many enhancements to the cube definition, such as calculations, KPIs, partitions, aggregations, etc. But I want to go to the Dimension Usage tab (Figure 8), and see the relationships that SSAS identified between the fact tables and dimension tables. In Figure 8, the SSAS Cube Wizard established many relationships between the fact tables and dimension tables. The wizard even detected the “role playing” relationship between the InternetSales and ResellerSales fact tables and the Date dimension table (where a single DateKey could play the “role” of an Order Date, Due Date, or Ship Date).
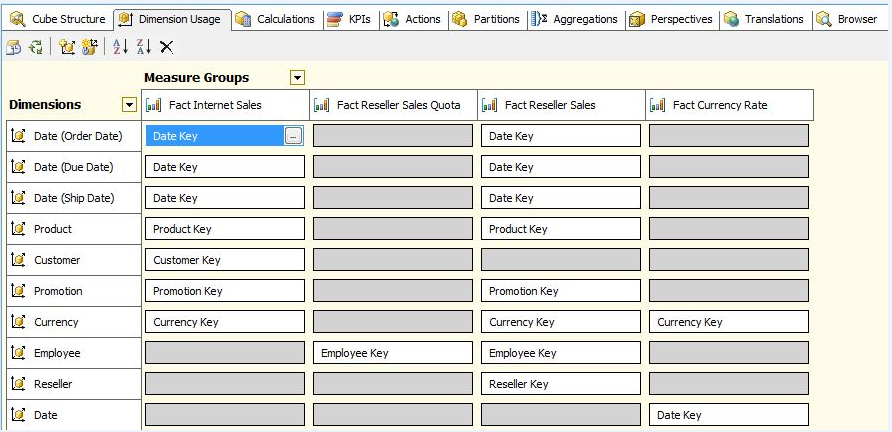
Is this complete? - No, not exactly. The Cube Wizard detected many relationships, but not all of them. I’ll need to perform a little surgery. Fair or unfair, one of the important distinctions between a casual SSAS user and a professional OLAP developer is knowing when and how to tweak dimension usage. At this point, the following items need to be addressed:
- Fact Reseller Sales Quota is related to the Employee dimension, but not by any of the Date Roles. Quotas are set at the Employee and Date (Quarter) Level.
- The Fact Internet Sales table is related to the Currency dimension, but has no visibility to the Fact Currency Rate bridge table. Thus, there is no way to express Sales Revenue for any specific day by another currency (in terms of the exchange rate for that day). So the Cube Wizard did not detect the many-to-many relationship between Fact Internet Sales and Fact Currency Rate.
- Perhaps most subtle of all, currently there is no way to view FactInternetSales and FactResellerSales by a common Geography dimension. FactInternetSales is related to the Customer dimension, and FactResellerSales is related to the Reseller dimension. Both Customer and Reseller are (in turn) related to geography, in what is termed a “dimension outrigger.” However, the Cube Wizard did not see that far down. I’ll show how to adjust that later.
I’ll leave the dimension usage table alone - for now. I need to review each of the individual OLAP dimension definitions in Tip 4, and then I’ll come back and tweak the dimension usage.
Tip 4: Using the Dimension Editor
Modifying and enhancing dimensions can be one of the more difficult tasks in SSAS. It’s also very critical for the following reasons:
- We are establishing the presentation of the business contexts to end users
- We are defining parent-child relationships that not only benefit end-users for rollup and drilldown operations, but also help OLAP developers in writing hierarchical logic (calculating % of parent share)
- In many instances, SSAS needs to know what uniquely defines an attribute - and SSAS 2008 implemented some additional controls (over 2005) that developers must be aware of
So in this tip, I’ll cover the modifications that I’ll make to the dimension definitions that the Cube Wizard created. In a nutshell, I’ll do the following:
- For the date dimension, I’ll create three hierarchies (Figure 9). The primary hierarchy will cover all the date levels (Year, Quarter, Month, Weekend Date, and Date) and the other two will only go from the Year level down to either quarter or month.
- For date columns where I want to display one value but sort on another (quarter), I need to set some key and sort definitions (Figure 10).
- Finally, I need to tell the SSAS engine that dates roll up into week-ending dates and week-ending dates roll up into months - in other words, which dimension attributes contain relationships (Figure 11).

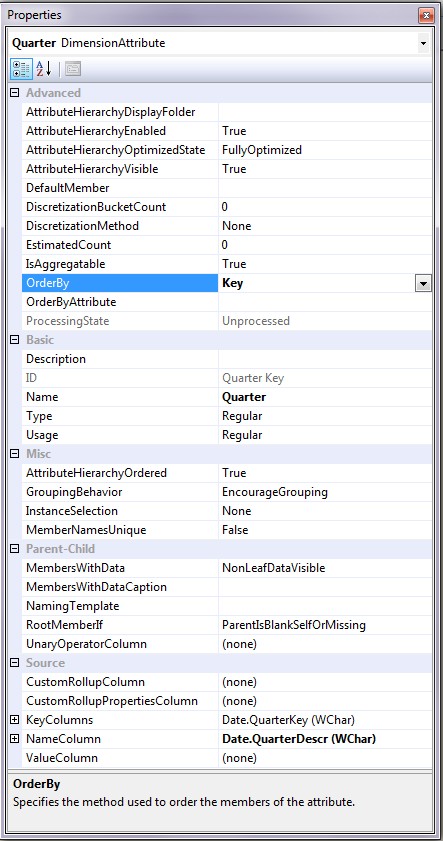

Important note: When I create attribute relationships, I can define them as rigid or flexible (by right-clicking on the relationship arrow and selecting Relationship Type). If I create a rigid relationship, Analysis Services will store information in the OLAP dimension that will optimize any rollups from attribute to a parent attribute. The downside to rigid relationships is that I’ll need to reprocess the entire dimension if parent-child attribute relationships change. (I’ll cover this more in detail in Tip 10.) For relationships that change very infrequently (or never), I should always create rigid attribute relationships: for relationships that can change often enough over time that I don’t want to re-process the dimension every time, I should create flexible attribute relationships.
Notice that the Geography dimension doesn’t even appear in the dimension usage (in Figure 8). Here’s why - because the Cube Wizard only spotted a direct relationship between FactInternetSales / FactResellerSales and the Customer / Reseller dimensions. Fortunately, in Solution Explorer, I can right-click on Dimensions and add a cube dimension manually and select the Geography table. Later I’ll set the dimension usage.
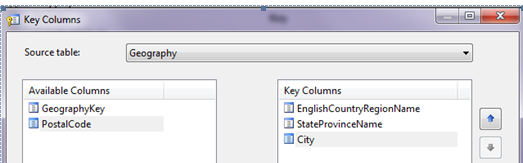
Next, I’ll create a geography hierarchy (Figure 12) that goes from Country to Postal Code. I’ll also define attribute relationships for the levels that make up the geography hierarchy (Figure 13). Finally, since some city names can appear twice in the database (either in the same country or different countries), I’ll qualify the key definition for a city (Figure 14).
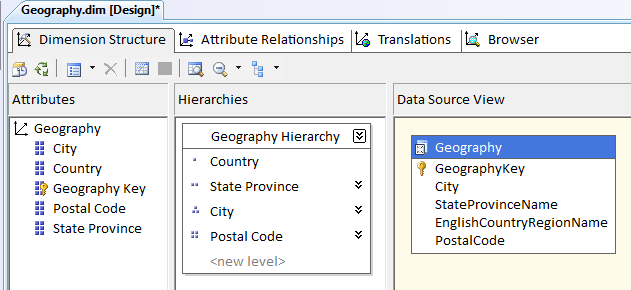

While I haven’t included any screen shots/figures, I’ve done the same thing for the product dimension. I dragged the products attributes for category, subcategory, and product into the hierarchy area, and I created a set of attribute relationships for product to roll up into subcategory, and subcategory to roll up into category.
Tip 5: Cube Dimension Usage, Revisited
Finally, I mentioned in the previous tip that after finishing the dimension editing, I’d come back and revisit the dimension usage (from Figure 8), to make it look like Figure 15. Here’s what I did:
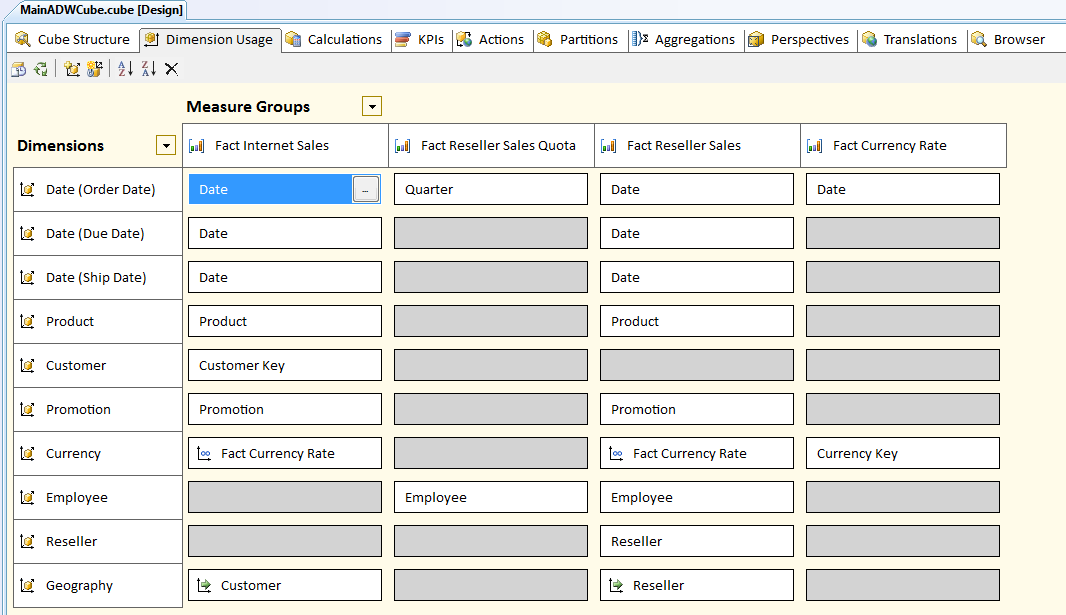
First, I can right-click at the bottom of the dimension usage area and add a new cube dimension reference and then select the Geography dimension. Then in the relationship intersection between Geography and FactInternetSales, I can click the ellipsis button and add a referenced relationship between the two tables that uses the Customer dimension as an intermediate dimension (Figure 16). I also need to add a referenced relationship between FactResellerSales and Geography that uses the Reseller dimension as an intermediate dimension.
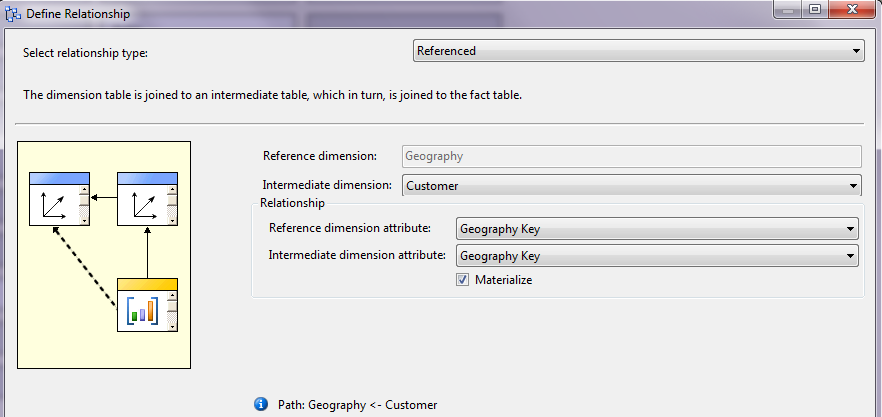
Second, so that I can express Internet Sales and Reseller Sales by any foreign currency, where the SSAS engine will automatically determine the current conversion rate for that currency/date, I need to define a bridge table (many-to-many) relationship table between FactInternetSales and Currency, using the FactCurrencyRate table as a bridge table (Figure 17). I also need to do the same thing for the relationship between FactResellerSales and Currency.

If you’re really paying attention, you may be asking, “Wait, what date dimension relates to the FactCurrencyRate table?” Well, back in Figure 8, the Cube Wizard created an artificial date role at the bottom. I’ll get rid of that last date role at the bottom in Figure 8, and I’ll decide that the Order Date role should be linked to the Fact Currency Rate Bridge table.
OK, so how can I actually express sales revenue (either Internet sales or reseller sales) by the corresponding conversion rate? Well, because of the bridge table and date relationships, I can take the raw measure for Internet Sales and express it in terms of the Conversion Rate. So in the cube structure table of the cube editor, I can take the Sales Amount measure, go to the properties window, and enter [Sales Amount] / [Average Rate] for the Measure Expression. (I can do the same thing for the Sales Amount measure in Fact Reseller Sales.)
Now, if you’re REALLY paying attention, you might say, “Wait, that means we have to ALWAYS be slicing data by one of the currency dimension members - where can we set a default?” A very good question - I can go back to the Currency dimension, find the Currency Name attribute, and set the DefaultMember property to [Currency].[Currency Name].&[US Dollar].
Additionally, I need to disable some default SSAS dimension behavior. By default, SSAS will aggregate any retrievals by a dimension member; for instance, showing revenue by city will not only generate $$$ for every city, but also will generate a grand total. In this situation, I DON’T want currency dimension members to aggregate. When you think about it, adding the number for U.S. dollars to the number for Mexican pesos would make zero analytic sense - so I need to set the IsAggregatable property for the Currency Name to FALSE
All told, this will allow me to slice data by the different currencies in the Currency dimension (U.S. dollar, Japanese Yen, Mexican Peso, etc.). There’s just one tiny element remaining (isn’t there always “one last thing?”) In the cube, I can define the default currency symbol. If you look all the way ahead at Figure 25, you’ll see Internet and Reseller sales in terms of different currency symbols. I can accomplish this by placing some default code into the cube calculations area (Listing 1) that maps language codes for each currency conversion name that the cube uses.
Finally - the end of this long and arduous journey through the dimension editor and dimension usage areas. I can now right-click in the solution and take the option to deploy, which will physically create an OLAP database. By default, SSAS will create an OLAP database with the same name as the project (in my case, MiniAdventureWorks2008R2). SSAS will also deploy the OLAP database on my localhost server. Since I use a named instance for my OLAP server (localhost\SQL2008R2), I need to right-click on the project in Solution Explorer and change the project property settings. Visual Studio allows me to set the OLAP server and name of the OLAP database.
At this point, can deploy and test in cube browser or Excel.
Tip 6: Creating OLAP Partitions
Depending on the company database size, a single fact table could be millions of rows, or billions, or even beyond. The OLAP data might go back 2 years, or 5 years, or even further. End users may often query on the proverbial 20% of the data (e.g. data for the last two years) 80% of the time. Additionally, a company may only incrementally update a small percent of data at any one time, leaving most of the remaining historical data as static.
Analysis Services allows developers to create physical partitions on fact tables. By defining rules for what data appears in what OLAP partition, developers can greatly increase query performance and processing performance. Developers can even define partitions on different servers for load balancing. If end users query data that spans partitions, the Analysis Services engine can transparently query the data in parallel executions.
So one of the primary tasks is to define a logical partition approach: whether to create a new partition for each year, or create an active one for the most recent two years and an archived one for prior years, or something more aggressive (a partition per quarter or even month). Ironically, you write T-SQL code, not MDX code, to create OLAP partitions. It’s important to note that the onus is on the developer to verify that the T-SQL code neither drops source data, nor “double-counts” data across partitions. The SSAS engine will not validate the logic of a partitioning scheme.
The Analysis Services cube editor in Solution Explorer contains a tab for partitions. By default, the Cube Wizard created a full partition for each fact table. Figure 17 shows the “end result” for the Internet Sales fact table - an active partition for everything greater than or equal to 2008, and an archived partition for else. A first-time developer might conclude that the first step to creating a new partition is to click the New Partition link - actually, before that, the developer must click the ellipsis button to the right of the partition source and modify the definition of the partition to use a SQL query to only read a subset of the data. (In other words, before creating a new partition, you must first tell the default partition to “share” the data source!) After doing so, the developer can then click the New Partition button to enter the correct T-SQL query for the definition of the archive partition. (I’m simply using the Year of OrderDateKey either being before or after 2008.)
In my example (active partition for everything 2008 or greater), I’ve taken a very simple approach on the partitioning logic. Some developers might maintain a separate table in the data warehouse that dynamically defines the current/active period. Others may create jobs in SSIS using XMLA script (which I’ll cover in Tip 9) when partitions are built more frequently. Whatever the requirements, partitioning can have a dramatic impact on day-to-day performance.
Tip 7: Creating OLAP Aggregations
Partitions are not the only way to increase the performance of OLAP cubes. I can build in aggregations as well. As I stated at the beginning, by default, Analysis Services does not construct any “built-in” subtotals in an OLAP cube. This surprises many who are impressed with how rapidly the SSAS engine will roll up (aggregate) measures from the lowest dimension level to a high dimension level.
However, at some point, the amount of data in a fact table (or partition) will grow to the point where the SSAS “on-the-fly” aggregation process will slow down. Users may note that queries at the year and zone and product brand level have slowed from seconds to minutes - maybe gradually over time, or immediately upon the data team loading a new source of data. SSAS 2008 provides an aggregation editor that allows SSAS administrators to define levels for “built-in” aggregations (subtotals).
Even before I cover the tools to create built-in aggregations, I want to mention a feature in Analysis Services that allows SSAS administrators to view past queries by user (to get a handle on which users are waiting the longest for results). You can turn on SSAS “query logging” by opening up Management Studio, connecting to the Analysis Services server, and setting the following properties in the SSAS server properties window: CreateQueryLogTable, CreateQueryLogConnectionString, and QueryLogSampling. After you set those, you can later access the query log by going to the Aggregation tab in the Visual Studio cube editor, right-clicking on the partition in question, and taking the option for “Usage based optimization.” This will allow you to view queries and execution times by user and date range. You can use the results from this output towards building an aggregation strategy.
An OLAP aggregation strategy (“aggregation design” in SSAS) might include building subtotals by quarter, by quarter and zone, and/or maybe by month and market and product group. A strategy can include one or two aggregations, or even dozens. A common recommendation is to build the fewest aggregations that will positively impact the greatest number of end users. While it might be tempting to add an aggregation at the date year level and geography country level, such an aggregation will not help those who query at the quarter and state level. So this process requires careful analysis to yield any positive outcome. It’s important to note that since aggregations are based on dimension attributes, the aggregations will work in conjunction with dimension attribute relationships (especially rigid attribution relationships) to create these “stored subtotals” as quickly as possible.
An OLAP aggregation strategy (“aggregation design” in SSAS) might include building subtotals by quarter, by quarter and zone, and/or maybe by month and market and product group. A strategy can include one or two aggregations, or even dozens. A common recommendation is to build the fewest aggregations that will positively impact the greatest number of end users.
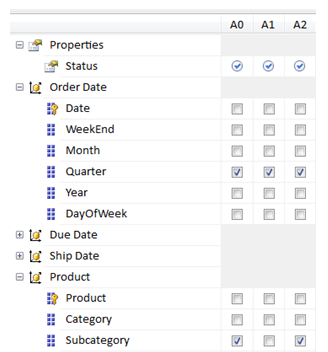
Figures 18 and 19 show the aggregation tab and aggregation advanced editor (the latter is a new feature in SSAS 2008) in the overall SSAS cube editor. The first screen (Figure 18) allows me to associate an aggregation strategy/design with one or more partitions. (So a database might have different sets of aggregations by partition.) The next screen (Figure 19) presents all the valid (related) dimensions and attributes for the partition(s), and I can check which attributes will comprise the aggregation. Note at the top of Figure 19 that individual aggregation definitions within the aggregation design do not have meaningful names; instead, they are simply called “A0”, “A1”, etc.

After re-deploying the OLAP database, the partition will contain the stored aggregations. So any queries where the specified dimension level is satisfied by any of the aggregation definitions will use that specific aggregation definition, and not roll up data on the fly - which can dramatically improve performance.
So what are downsides of aggregation? It will increase the size of the partition, though this may not be a serious issue. Additionally, processes that update the OLAP cube (either incrementally or full process) will take longer, because the SSAS engine must rebuild/build the aggregations. Once again, the use of attribute relationships may help with this process.
Tip 8: MDX Calculated Members
No matter how many meaningful measures exist in an OLAP database, there will still be a need for “on-the-fly” calculations that go beyond simple aggregation. End users might need to see weighted ratios or other weighted calculations, expressed in terms of the current year or the previous year. You can place predefined calculated members into the cube, using the MDX programming language.
In other instances, OLAP reports might need repeatable sets of data - such as top 10 products, top 10 customers, or a hierarchical list of geography elements from a country down to a city level. You can place predefined named sets into an OLAP cube, again using the MDX programming language.
Finally, there are countless instances when reporting against OLAP cubes in SSRS, or PerformancePoint Services, or even Excel, when the built-in visual designers aren’t enough for the required output. In these situations, custom MDX code is required.
First, Figure 20 shows an example of a calculated member in the BIDS cube editor. In this example, I eventually want to produce output that shows each employee salesman and their % of sales quota. I can create a calculated member called [Reseller Pct of Quota] that determines a reseller % of quota by taking two existing cube measures and performing a calculation.
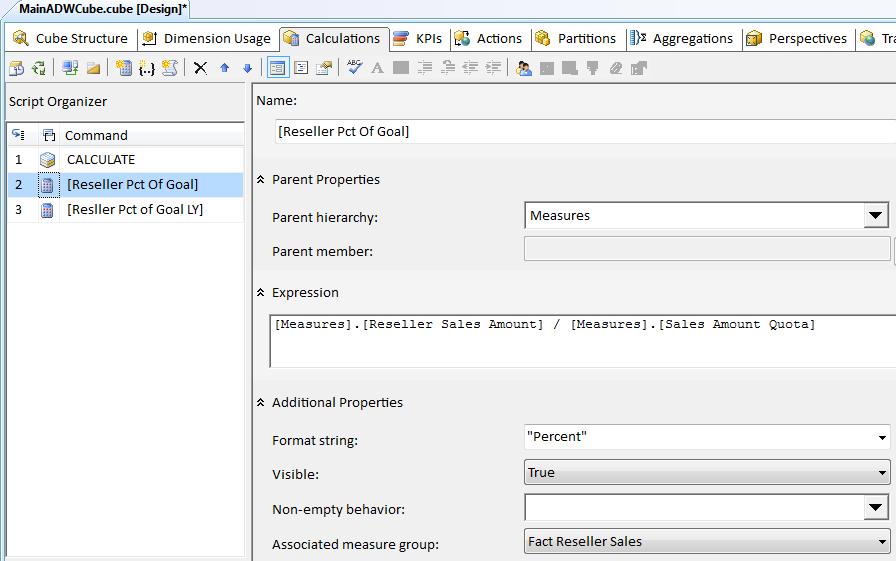
[Measures].[Reseller Sales Amount] /
[Measures].[Sales Amount Quota]
As the SSAS engine automatically aggregates these measures, I’m assumed to have a ratio/percent based on the aggregation (sum) of the measures.
Additionally, any time I’m looking at employee salesmen and % of quota for a specific quarter or year, and I also want to see the Reseller Pct of Quota for the same time period a year ago, I can express the Reseller Pct of Quota calculated member in terms of one year ago by using the MDX function PARALLELPERIOD. So the following is a second calculated member called [Reseller Pct of Goal LY].
CASE
WHEN PARALLELPERIOD(
[Order Date].[Full Date Tree].[Year] , 1,
[Order Date].[Full Date Tree].CurrentMember)
= NULL THEN 'N/A'
ELSE
( [Reseller Pct Of Goal] ,
PARALLELPERIOD(
[Order Date].[Full Date Tree].[Year] , 1,
[Order Date].[Full Date Tree].CurrentMember))
END
Note that the calculation checks to see if the ParallelPeriod for the current date context returns a NULL. If it does, that means that either the user hasn’t selected a “base date” at runtime, or the base date is one where no parallel period exists in the date dimension.
You may be wondering - OK, but where do I pass parameters into these calculations? Short answer: you don’t. Remember, the whole idea of OLAP is to automatically slice measures based on dimension usage and dimension relationships: MDX calculated members follow the same pattern. So we don’t define the time period or salesman for which to use these calculations: quite simply, the process is reversed. When we place these calculations in a report or simply an Excel OLAP Pivot Table, the SSAS engine will automatically slice the underlying data in the calculation by the related dimensions we specify at runtime. Awesome!!!
Tip 9: Building KPIs (Key Performance Indicators)
To the stakeholders of an application, KPIs are often the main reason for an OLAP database! Analysis Services allows developers to create simple visualizations of performance metrics. KPIs generally fall into four general categories/perspectives (according to the famous guidelines set by Norton and Kaplan for balanced KPI scorecards):
- Financial Perspective: Are we at our sales goal?
- Customer Relations Perspective: We send out customer surveys once per quarter - are the survey evaluation results above or below our goals?
- Internal Processes Perspective: We’re in a manufacturing environment…damages and shortages and irregulars are a fact of life - but are they above or below our thresholds?
- Education Perspective: Our developers are required to spend 10% of their time per quarter on learning nascent technologies.
Analysis Services contains a section to create KPIs from existing calculated members, in the KPI tab of the cube editor. Generally speaking, most basic KPIs return one of three values for the current runtime selections: a value of 1 means that we’re at or above our goal, which is generally a good thing. A value of -1 means we’re well below our goal, and that’s not a good thing. A value of 0 is a grey area: maybe it’s “OK”, or maybe it’s a warning. In the KPI, I can define the ranges and thresholds (either based on static numbers or data that comes from another fact table).
SSAS also allows us to render a value of 1, 0, and -1 using different indicators (green-red-yellow traffic lights, smiley faces, etc.). So at a minimum, a KPI must include a base calculation that we’re looking to analyze, a goal/threshold, a status of 1, 0, or -1, and a status indicator image.
Optionally, a KPI can have a trend definition. For instance, maybe for a specific metric, the company isn’t doing so well this current period, but it is still better than one year ago. By contrast, maybe the company is doing well this period, but was doing better last year. SSAS allows us to create a trend in the KPI, to show a positive or negative business trend over last year. Once again, we use a value of 1 to indicate a positive business trend, a -1 to indicate a negative business trend, and a 0 to indicate minimal or no trend.
Looking ahead, Figure 26 shows an example of rendering a KPI in Excel. The KPI is a Reseller % of Sales goal, which I can use at runtime for the entire sales force, or for individual salesmen.
Figure 21 shows how I can create a KPI with the following information:
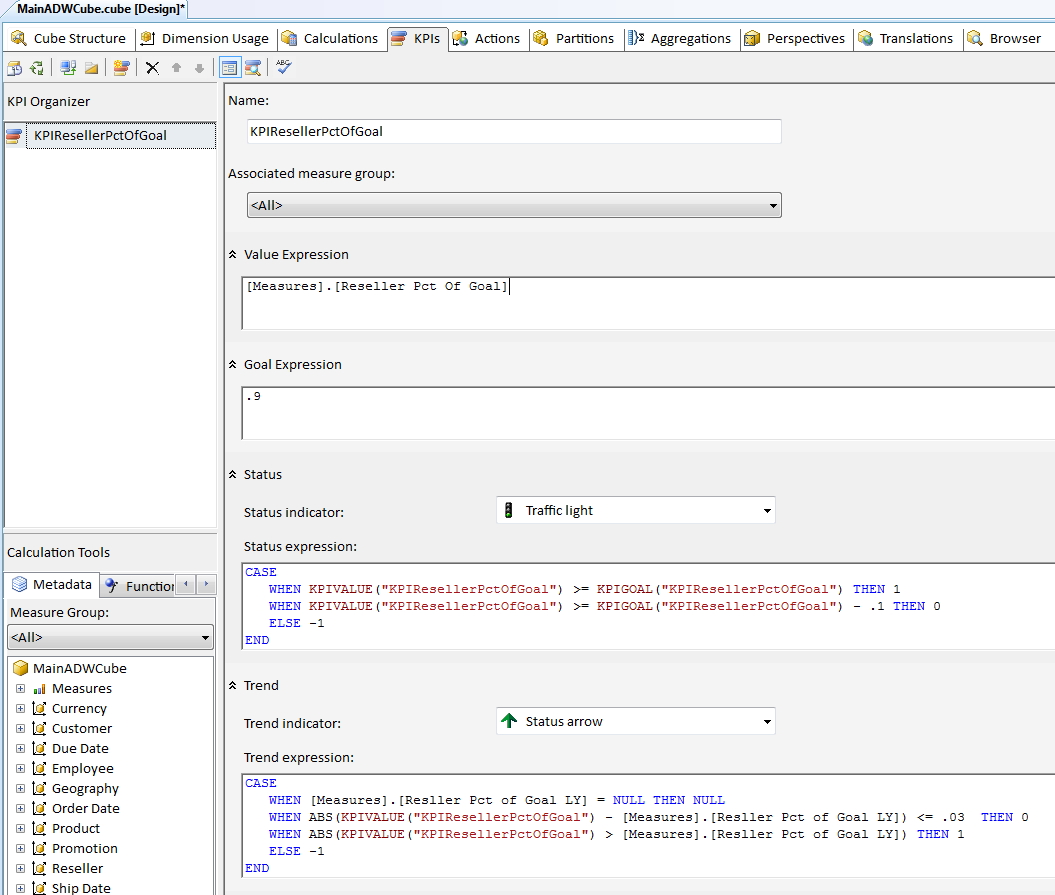
- The name for the KPI: KPIResellerPctOfGoal
- The underlying measure/metric: [Reseller Pct Of Goal]
- The goal: We want our saleman to be at least 90% of their goal, though this could have come from a fact table.
- The status indicator: Simple trafic light.
- An expression that compares the underlying measure/metric to the goal: Note the CASE statement that returns a 1 if the metric (% of quota) is above the KPI goal, a 0 if the metric is at least within a tenth of a point of the goal, and a value of -1 if the metric is below the goal (and by more than a tenth of point).
- An optional trend indicator and expression that checks the % of goal this year to last year, to see if there is a positive or negative business trend.
After I deploy the project, the KPI will be part of the OLAP database, and users/developers can access it in Excel or other OLAP reporting tools.
Tip 10: Processing an OLAP Cube with XMLA Script
When application developers learn SSAS, a common question is how to update OLAP databases (when new data is added to a transaction system) on a regular basis. Sure, it’s easy to fire up Visual Studio, open the SSAS project, and process the project again to rebuild the OLAP database; however, that’s hardly practical when new data needs to be loaded every day or even multiple times a day.
New SSAS developers wonder if they can write SQL-style DML statements to add/update/delete OLAP data. The short answer is no; however, Analysis Services provides XMLA scripting instead. XMLA stands for “XML for Analysis services,” and contains a series of processing commands that you can use.
There are several ways to implement XMLA scripts. One easy way is to create an SSIS package that uses the SSAS processing command tasks - these provides a GUI that generates XMLA script for the fact tables and dimensions to be updated. I covered this in Tip 8 of my Baker’s Dozen article in the July/August 2010 issue of CODE Magazine.
I’ll look at three common scenarios:
- Suppose my ETL process encounters four new accounts, three new products, and two modified products (corrections were made to the two products). I can use the XMLA command Process Update on the corresponding dimensions, followed by a Process Default on the OLAP database as a whole. Process Update will add any new OLAP dimension members that the engine encounters in the source data but not in the OLAP dimension. Process Default is a bit like a “refresh” - it brings the target object to a fully processed state.
- Suppose I want to completely rebuild one or more fact tables or partitions from scratch. I can use the Process Full command on the necessary OLAP object(s), followed by a Process Full on the OLAP database. Note: This process will delete the contents of the intended target OLAP objects. In this instance, make certain that the underlying source data has all the data you wish to bring forward. Sometimes people use Process Full where the data source only contains data for the last month/quarter - after the process, the OLAP database will only have data for the same time period as well!
- Suppose I have a new day’s worth of invoices and I want to incrementally update it in the OLAP cube. I don’t want to delete the contents of my OLAP fact table or partition - I simply want to add new fact rows. I can use Process Incremental on the fact table or partition. The Process Incremental option in SSIS also provides an interface where I can configure a T-SQL query to only extract the new invoices. Many companies might implement this many different ways, using either custom extracts that are read from T-SQL queries, or even from SQL 2008 Change Data Capture Logs. Once again, I’ll need to use a Process Default on the OLAP database when finished.
Those three scenarios are arguably the most common of all. I could write an entire article on this topic alone, but here are some additional notes on this topic:
- If a processing environment uses Process Update often on dimensions, the environment should also use Process Index on occasion. Process Index will rebuild dimension bitmap indexes.
- If you’re using Process Update on a dimension, and you’re changing a dimension attribute value for an attribute that’s defined in a rigid dimension relationship, the SSAS engine will generate a runtime error. Your options are either to make the attribute relationship flexible (instead of rigid), or use Process Full on the dimension.
- While Process Incremental might seem like an attractive option for trickle-feeding new OLAP fact table data, some view the process as slightly fragile. Certainly, if you’re not very careful, it’s easy to wind up with more data in the OLAP fact table/partition than you intended. Some installations will build many smaller OLAP partitions, and use a process full on just that specific partition.
- I’ve saved the biggest rule for last. In OLAP, just like in life, there are red rules (rules you always follow) and blue rules (rules you use as guidelines). Here’s a red rule - ALWAYS process new dimension members ahead of new fact table rows - no exceptions!
I can also use XMLA scripts to backup and restore OLAP databases. Listing 2 shows a short XMLA script to back up the OLAP database from this article. I can also perform a backup manually in SQL Server Management Studio by right-clicking on an OLAP database and selecting “Back Up…”.
Tip 11: MOLAP and ROLAP
So far, I’ve been talking about and demonstrating a specific storage methodology known as MOLAP. MOLAP (which stands for Multidimensional OLAP) is the default storage methodology in Analysis Services. Briefly stated, MOLAP means that the OLAP database has physical presence. In MOLAP, you need to physically deploy (or run the SSAS XMLA processing commands I described in Tip 10) for changes in the underlying relational data to appear in the OLAP cube.
Essentially, the SSAS engine “copies” the source data to an OLAP format. For many installations where users want to report on new data based on daily or weekly or monthly intervals, this isn’t a problem. You can set up SSIS jobs with SSAS processing commands (or run XMLA script other ways) and run them under SQL Server Agent on a scheduled basis.
However, suppose your users need INSTANT (real-time) access to information, once it appears in the underlying data source - but through an OLAP interface. They don’t want to wait for the next OLAP update cycle. Additionally, you may not want to schedule SSIS jobs to update OLAP cubes every fifteen minutes (though some people do!)
In this instance, an alternative option is to use ROLAP. ROLAP stands for Relational Online Analytic Processing. ROLAP is an interesting feature. You still create an SSAS solution. End users still get the “slice-and-dice” runtime OLAP features. However, the cube (or fact table) definition is really more of a “proxy,” a virtual definition. When users request data from what they believe is a physical cube/fact table, the SSAS engine turns around and sends T-SQL statements to the underlying data source, and synthesizes the data back to the end user, as if you were using MOLAP all along. As such, ROLAP has two benefits:
- End users get near-instant access to data. Almost the very second after the underlying relational source append new rows, end users can access the data from the OLAP interface.
- You don’t need to worry about XMLA processing commands, since you’re not trying to add new dimension members or fact rows. So by contrast to MOLAP, there is no copying of data from the underlying relational data source to the multidimensional OLAP database.
It almost sounds too good to be true - end users get the benefit of OLAP functionality, but without the management and maintenance issues of updating OLAP data. However, there can be one major drawback: performance. Each time an end user wants data from the OLAP definition, the SSAS engine fires a T-SQL query back to the relational source. (You can watch this yourself using SQL Profiler.) Additionally, you might need to define your OLAP data source connection string (in the SSAS project) to use the Snapshot isolation level, if read locks otherwise occur when the SSAS engine reads the underlying source (using the default isolation level of Read committed).
So ROLAP places a much higher demand on resources in the relational storage area. The general industry recommendation to avoid ROLAP if the underlying logical data model is complex (i.e., relationships beyond the standard de-normalized star schema methodology), and/or the data model contains a large number of dimension attributes.
In the summer of 2010, Microsoft produced an outstanding white paper on the pros and cons of ROLAP in a Data Warehousing environment: you can find the white paper by doing a web search on “Analysis Services ROLAP for SQL Server Data Warehouses - whitepapers. ”
OK, so where do you “set” an OLAP database to use ROLAP? There isn’t one specific setting. You can define the entire OLAP cube as ROLAP, or specific fact tables, or specific partitions, or specific dimensions. So you could use MOLAP for all of your fact tables, except for one where end users need instance access with ROLAP. To enable the ROLAP feature, you right-click and access the properties for the cube - fact table - partition - measure, and go to the property called Proactive Caching. In the dialog that pops up, there’s a horizontal slider bar where you can drag the option all the way to the left (for ROLAP).
If you were familiar with MOLAP and ROLAP to begin with, you may be wondering why I didn’t cover HOLAP. HOLAP is a hybrid approach that is essentially “ROLAP with aggregations.” The amount of time to process a HOLAP implementation can take almost as long as MOLAP. HOLAP is the rarest of the three storage methodologies.
Tip 12: Baker’s Dozen Spotlight: Implementing SSAS Report Actions
In my opinion, one of the more “unsung” hero features in SSAS is Report Actions (otherwise known as Actions). To best understand actions, I’ll present two scenarios:
- Suppose users are browsing an OLAP pivot table of product sales with Microsoft Excel, and want to quickly access a multimedia web page of product information for a specific product.
- Suppose users are browsing an OLAP pivot table (again in Excel), and drill down as far as they can in the cube, to see employee sales by day. The user would like to drill down further to see transactions for the day, but the OLAP cube is summarized at the date level.
In both instances, the user is trying to extend the analytic path beyond the OLAP database. SSAS actions provide developers with the ability to create “hooks” into some external link, such as a web page or an external SSRS report that reads a transaction system for sales for a specific date.
In the full blown AdventureWorks SSAS project, there is a good example of using an SSAS action to launch a city map, based on the current city that someone is browsing. That covers the first scenario above.
As for the second scenario, suppose the end user is browsing reseller sales (using our MiniADWOLAP cube) by employee and date. The user sees a number for an employee salesman and date that is very high (or very low) and wants to investigate. Now suppose there is an SSRS report that reads against reseller transactions for a specific employee and date parameter. Does the user have to go access that report (which might mean logging into another system? No - you can create a report action and set up a “hook” based on the current select employee and date in an OLAP Pivot Table, to allow the end user to launch the report (Figure 22).
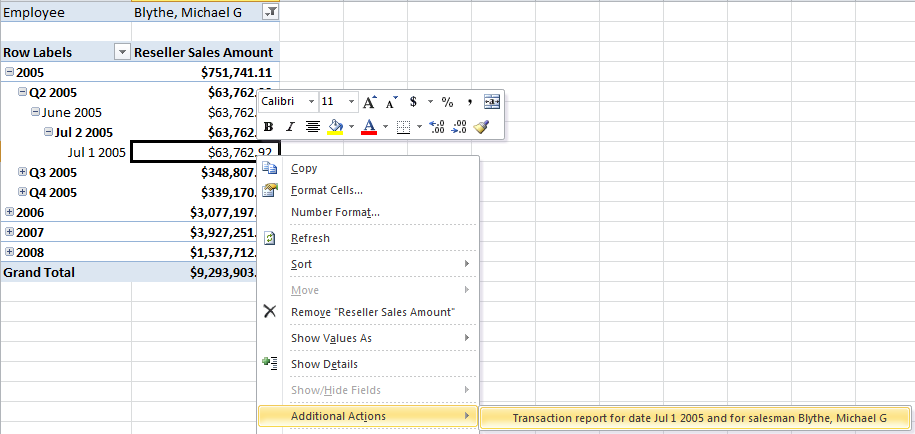
So how can I create this? In Figure 23, I’ve defined a report action (from the action tab in the BIDS cube editor). The report action calls an SSRS report that’s been previously deployed to an SSRS report server. You simply define the server name and report path. You also map the current employee and date in the pivot table to the two corresponding SSRS report parameters. Note the use of the MDX function urlescapefragment, which will deal with any escape code sequences when translating the current dimension member to URL syntax.

Actions can be a VERY important feature in a MOLAP environment, especially if you are battling against others who want to put transaction level data in an OLAP cube. If end users will only need to drill down to the transaction level if they see data anomalies at higher levels (like day), report actions can help “keep the transaction wolves at bay.”
Tip 13: Implementing Data Security Using SSAS Roles
Another “unsung” hero in SSAS is the security role capability. Suppose you have a group of end users who should only be able to see a certain set of product brands, or a set of markets or regions. In a SQL Server relational database, you’d likely need to build some combination of user authorization definition tables, database views, and (perhaps) logic in stored procedures.
By contrast, Analysis Services leverages the metadata approach of the dimensional model (which some refer to as the UDM) to provide a capability known as Roles. You can build roles into an SSAS project and define which users on the Windows domain should have access to what dimension member values. So in many instances, this process can be MUCH simpler than with SQL relational databases.
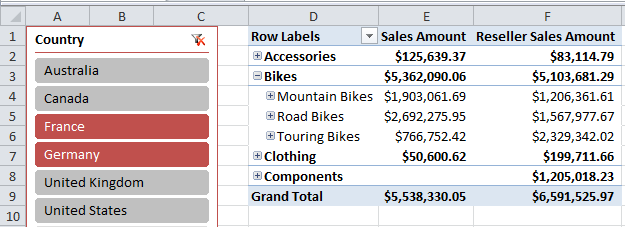
In Figure 24, I’ve provided an example of a user role with access to data for France and Germany. In the other tabs of the user role, I can define which users (or user groups) participate of this role. I can also specify other dimension members (such as Product Category of Bikes).
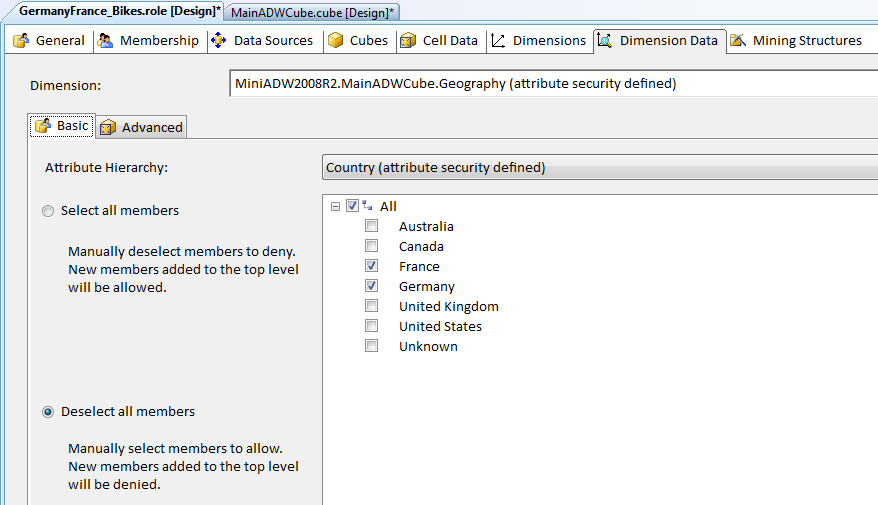
Here’s an interesting situation that can occur. In this example role (France and Germany) - remember that by default, dimension members will aggregate to an “all total.” In most cases, management will only want the users in this role to see a grand total that reflects France/Germany only. However, in a few situations, management may want users in this role to see the ALL country total, even though the only specific countries shown will be Germany and France. In the Advanced tab in Figure 24, there is a checkbox for Visual Totals. When checked on, the end user will only see totals for France/Germany - when checked off, the end user will see the all country total. So you can think of Visual Totals as a form of “filtered totals,” since any dimension aggregation will be only for the dimensions that are seen/visible.
After you deploy the project changes to the SSAS OLAP database, the Analysis Services engine will authenticate access to the OLAP database based on the Windows user (or user group). From there, the user will only see fact data based on those dimensions that I defined in the SSAS role screen in Figure 24.
If I want to test the role, do I need to log on to the Windows domain as one of the users? No. I can test the roles at least two ways. First, in the BIDS cube editor, there is a tab at the end for the cube browser. The cube browser contains an icon that allows me to access the cube under one of the SSAS OLAP database roles. After I select the role, I will only see those dimensions that I defined in the role. I can also test the role in Excel - after creating an OLAP pivot table against the database, I can go into connection properties and add a “Role=<Rolename>” entry to the connection string.
Does this mean you NEVER have to write custom code to deal with user authorization to specific member members? No. There can be instances where user access requirements are more complicated (for example: a user can set one set of products for Region A and a different set of products for Region B). In that situation, we’d need to incorporate some custom MDX into the Advanced tab of Figure 24.
So what will we have at the end? (Redux)
I mentioned (at the beginning) that when I was finished, I’d be able to easily create Pivot Tables in Excel against the OLAP cubes. Figures 25 through 27 show three different Pivot Tables that I created against the OLAP database. To create these, I did the following:
- I opened Excel (either Excel 2007 or Excel 2010).
- I selected the Data option from the main pull-down menu.
- In the context toolbar, I selected “From Other Sources” and then selected “From Analysis Services.”
- I provided the name of the OLAP server (localhost\SQL2008R2 in my case) and selected the specific OLAP database and OLAP cube.
At that point, Excel allows me to create Pivot Tables and/or Pivot Charts from the facts and dimensions in the cube. In Figure 25, I selected Internet Sales and Reseller Sales as my two measures, sliced them by the Currency Name from the Currency dimension, and then defined the Geography, Order Date, and Product hierarchies as dropdown filter lists.

In Figure 26, I retrieved several measures from the Reseller fact table, along with the Reseller KPI (called KPIResellerPctOfGoal) that I created back in Tip 9. I then sliced it by Employee Name, and used the subset YearToQuarter hierarchy from the Order Date dimension. This is one of many examples where a subset hierarchy is necessary, as I don’t want to look at employee sales and sales goals at any level lower than date quarter.
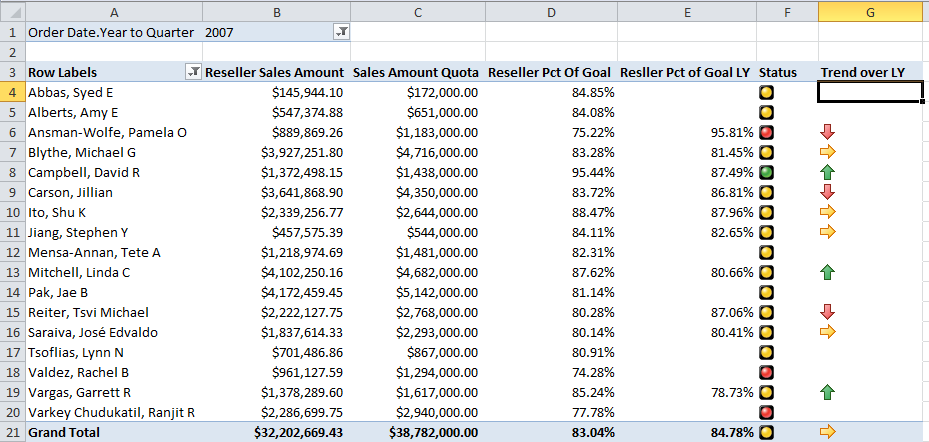
Finally, in Figure 27, I took a simple Pivot Table of sales by Product and Geography, and used the Geography as a Visual Slicer (a new feature in Excel 2010).
These three figures barely scratch the surface of ways that I can access OLAP data. I could devote an entire article to the different ways developers and end users can access information in an OLAP database. That’s a segue to my next topic.
Next Baker’s Dozen…
Now that I’ve covered how to create an OLAP database, the next logical step is to show the different ways users can access OLAP data. In the next Baker’s Dozen article, I’ll cover several output tools (SSRS, Excel, PerformancePoint Server) for rendering OLAP data in a browser/SharePoint. There will be several MDX code listings for incorporating MDX into these tools. I’ll also cover how .NET developers can access OLAP data to build custom web output.
Recommended SSAS Resources
There are some good SSAS books on the market, and one outstanding one. I highly recommend Expert Cube Development with Microsoft SQL Server 2008 Analysis Services, by Marco Russo, Alberto Ferrari, and Chris Webb. The book is worth far more than the price.
As stated earlier, I also recommend the blogs of Chris Webb (http://cwebbbi.wordpress.com/">http://cwebbbi.wordpress.com/) and Teo Lachev (http://www.prologika.com/">http://www.prologika.com/). I also recommend the website www.ssas-info.com. I’d also like to personally thank Chris Webb, who has fielded many OLAP/MDX questions from me over the last year. If you are serious about OLAP, I’m not being facetious when I say that you should read every word of these resources.
I also recommend this utility from CodePlex, which helps manage SSAS projects in Visual Studio.
http://bidshelper.codeplex.com/">http://bidshelper.codeplex.com/
New Directions for Analysis Services
At the PASS Conference in Seattle in November 2010, Microsoft announced some plans for the next release of SQL Server (“Denali”), including information on a second model for creating databases in Analysis Services. This new model is known as BISM, - Business Intelligence Semantic Model. Much has been written about this second new model - I recommend the blogs of Chris Webb and Teo Lachev for more information on BISM.
