





GraphQL has been gaining wide adoption as a way of building and consuming Web APIs. GraphQL is a specification that defines a type system, query language, and schema language for your Web API, and an execution algorithm for how a GraphQL service (or engine) should validate and execute queries against the GraphQL schema. It's upon this specification that the tools and libraries for building GraphQL applications are built.
In this article, I'll introduce you to some GraphQL concepts with a focus on GraphQL schema, resolver, and the query language. If you'd like to follow along, you need some basic understanding of C# and ASP.NET Core.
Why Use GraphQL?
GraphQL was developed to make reusing the same API into a flexible and efficient process. GraphQL works for API clients with varying requirements without the server needing to change implementation as new clients get added or without the client needing to change how they use the API when new things get added. It solves many of the inefficiencies that you may experience when working with a REST API.
Some of the reasons you should use GraphQL when building APIs are:
- GraphQL APIs have a strongly typed schema
- No more over- or under-fetching
- Analytics on API use and affected data
Let's take a look.
A Strongly Typed Schema as a Contract Between the Server and Client
The GraphQL schema, which can be written using the GraphQL Schema Definition Language (SDL), clearly defines what operations can be performed by the API and the types available. It's this schema that the server's validation engine uses to validate requests from clients to determine if they can be executed.
No More Over-or Under-Fetching
GraphQL has a declarative way of requesting data using the GraphQL query language syntax. This way, the client can request any shape of data they want, as long as those types and its fields are defined in the schema. This is analogous to REST APIs where the endpoints return predefined and fixed data structures.
This declarative way of requesting data solves two commonly encountered problems in RESTful APIs:
Over-fetching and Under-fetching
Over-fetching happens when a client calls an endpoint to request data, and the API returns the data the client needs as well as extra fields that are irrelevant to the client. An example to consider is an endpoint /users/id which returns a user's data. It returns basic information, such as (in this example, an online school's database will be used) name and department, as well as extra information, such as address, billing information, or other pertinent information, such as courses they're enrolled in, purchasing history, etc. For some clients or specific pages, this extra information can be irrelevant. A client may only need the name and some identifying information, like social security number or the courses they're enrolled in, making the extra data such as address and billing information irrelevant. This is where over-fetching happens, affecting performance. It can also consume more of users' Internet data plan.
Under-fetching happens when an API call doesn't return enough data, forcing the client to make additional calls to the server to retrieve the information it needs. If the API endpoint /users/id only returns data that includes the user's name and one other bit of identifying data, clients needing all of the user's information (billing details, address, courses completed, purchasing history, etc.) will have to request each piece of that data with separate API calls. This affects performance for these types of clients, especially if they're on a slow connection.
This problem isn't encountered in GraphQL applications because the client can request exactly the bits of data they need from the server. If the client requirement changes, the server need not change its implementation but rather the client is updated to reflect the new data requirement by adding the extra field(s) it needs when querying the server. You will learn more about this and the declarative query language in GraphQL in the upcoming sections.
Analytics on clients' usage
GraphQL uses resolver functions (which I'll talk about later) to determine the data that the fields and types in the schema returns. Because clients can choose which fields the server should return with the response, it's possible to track how those fields are used and evolve the API to deprecate fields that are no longer requested by clients.
Setting Up the Project
You'll be building a basic GraphQL API that returns data from an in-memory collection. Although GraphQL is independent of the transport layer, you want this API to be accessed over HTTP, so you'll create an ASP.NET Core project.
Create a new ASP.NET Core project and install the dependencies shown in Figure 1.

The first package you installed is the GraphQL package for .NET. It provides classes that allow you to define a GraphQL schema and also a GraphQL engine to execute GraphQL queries. The second package provides an ASP.NET Core middleware that exposes the GraphQL API over HTTP. The third package is referred to as the GraphQL Playground, which works in a similar way to Postman for REST APIs. It gives you an editor in the browser where you can write GraphQL queries against your server and see how it responds. It gives you IntelliSense and you can view the GraphQL schema from it.
The GraphQL Schema
The GraphQL schema is at the center of every GraphQL server. It defines the server's API, allowing clients to know which operations can be performed by the server. The schema is written using the GraphQL schema language (also called schema definition language, SDL). With it, you can define object types and fields to represent data that can be retrieved from the API as well as root types that define the group of operations that the API allows. The root types are the Query type, Mutation type, and Subscription type, which are the three types of operations that you can run on a GraphQL server. The query type is compulsory for any GraphQL schema, and the other two are optional. Although you can define custom types in the schema, the GraphQL specification also defines a set of built-in scalar types. They are Int, Float, Boolean, String, and ID.
There are two ways of building GraphQL server applications. There's the schema-first approach where the GraphQL schema is designed up front. The other approach is the code-first approach where the GraphQL is constructed programmatically. The code-first approach is common when building a GraphQL server using a typed language like C#. You're going to use the code-first approach here and later look at the generated schema.
Let's get started with the schema. Create a new folder called GraphQL and add a new file Book.cs with the content in the following snippet:
public class Book
{
public int Id { get; set; }
public string Title { get; set; }
public int? Pages { get; set; }
public int? Chapters { get; set; }
}
Add another class BookType.cs and paste the content from the next snippet into it.
using GraphQL.Types;
public class BookType : ObjectGraphType<Book>
{
public BookType()
{
Field(x => x.Id);
Field(x => x.Title);
Field(x => x.Pages, nullable: true);
Field(x => x.Chapters, nullable: true);
}
}
The code in the last snippet represents a GraphQL object type in the schema. It'll have fields that will match the properties in the Book class. You set the Pages and Chapters fields to be nullable in the schema. If not set, by default, the GraphQL .NET library sets them as non-nullable.
The application you're building only allows querying for all the books and querying for a book based on its ID. The book type is defined so go ahead and define the root query type. Add a new file RootQuery.cs in the GraphQL folder, then copy and paste the code from Listing 1 into it.
Listing 1: The type for the root query operation
using GraphQL.Types;
using System.Collections.Generic;
using System.Linq;
public class RootQuery : ObjectGraphType
{
public RootQuery()
{
Field<ListGraphType<BookType >>("books", resolve: context => GetBooks());
Field<BookType>("book",
arguments : new QueryArguments(new QueryArgument<IdGraphType> { Name = "id" }),
resolve: context =>
{
var id = context.GetArgument<int>("id");
return GetBooks().FirstOrDefault(x => x.Id == id);
});
}
static List<Book>GetBooks()
{
var books = new List <Book>
{
new Book
{
Id = 1,
Title = "Fullstack tutorial for GraphQL",
Pages = 356
},
new Book
{
Id = 2,
Title = "Introductory tutorial to GraphQL",
Chapters = 10
},
new Book
{
Id = 3,
Title = "GraphQL Schema Design for the Enterprise",
Pages = 550,
Chapters = 25
}
};
return books;
}
}
The RootQuery class will be used to generate the root operation query type in the schema. It has two fields, book and books. The books field returns a list of Book objects, and the book field returns a Book type based on the ID passed as an argument to the book query. The type for this argument is defined using the IdGraphType, which translates to the built in ID scalar type in GraphQL. Every field in a GraphQL type can have zero or more arguments.
You'll also notice that you're passing in a function to the Resolve parameter when declaring the fields. This function is called a Resolver function, and every field in GraphQL has a corresponding Resolver function used to determine the data for that field. Remember that I mentioned that GraphQL has an execution algorithm? The implementation of this execution algorithm is what transforms the query from the client into actual results by moving through every field in the schema and executing their Resolver function to determine its result.
The books resolver calls the GetBooks() static function to return a list of Book objects. You'll notice that it's returning a list of Book objects and not BookType, which is the type tied to the schema. GraphQL for .NET library takes care of this conversion for you.
The Book resolver calls context.GetArgument with id as the name of the argument to retrieve. This argument is then used to filter the list of books and return a matching record.
The last step needed to finish the schema is to create a class that represents the schema and defines the operation allowed by the API. Add a new file GraphSchema.cs with the content in the following snippet:
using GraphQL;
using GraphQL.Types;
public class GraphSchema : Schema
{
public GraphSchema(IDependencyResolver resolver) : base(resolver)
{
Query = resolver.Resolve<RootQuery>();
}
}
In that bit of code, you created the schema that has the Query property mapped to the RootQuery defined in Listing 1. It uses dependency injection to resolve this type. The IDependencyResolver is an abstraction over whichever dependency injection container you use, which, in this case, is the one provided by ASP.NET.
Configuring the GraphQL Middleware
Now that you have the GraphQL schema defined, you need to configure the GraphQL middleware so it can respond to GraphQL queries. You'll do this inside the Startup.cs file. Open that file and add the following using statements:
using GraphQL;
using GraphQL.Server;
using GraphQL.Server.Ui.Playground;
Go to the ConfigureServices method and add the code snippet you see below to it.
services.AddScoped<IDependencyResolver>(s => new FuncDependencyResolver (s.GetRequiredService));
services.AddScoped<GraphSchema>();
services.AddGraphQL().AddGraphTypes(ServiceLifetime.Scoped);
The code in that snippet configures the dependency injection container so that when something requests a particular type of FuncDependencyResolver from IDependencyResolver that it should return. In the lambda, you call GetRequiredServices to hook it up with the internal dependency injection in ASP.NET. Then you added the GraphQL schema to the dependency injection container and used the code services.AddGraphQL extension method to register all of the types that GraphQL.net uses, and also call AddGraphTypes to scan the assembly and register all graph types such as the RootQuery and BookType types.
Let's move on to the Configure method to add code that sets up the GraphQL server and also the GraphQL playground that is used to test the GraphQL API. Add the code snippet below to the Configure method in Startup.cs.
app.UseGraphQL<GraphSchema>();
app.UseGraphQLPlayground(new GraphQLPlaygroundOptions());
The GraphQL Query Language
So far, you've defined the GraphQL schema and resolvers and have also set up the GraphQL middleware for ASP.NET, which runs the GraphQL server. You now need to start the server and test the API.
Start your ASP.NET application by pressing F5 or running the command dotnet run*. This opens your browser with the URL pointing to your application. Edit the URL and add /ui/playground at the end of the URL in order to open the GraphQL playground, as you see in Figure 2.
The GraphQL playground allows you to test the server operations. If you've built REST APIs, think of it as a Postman alternative for GraphQL.
Now let's ask the server to list all the books it has. You do this using the GraphQL query language, another concept of GraphQL that makes it easy for different devices to query for data how they want, served from the same GraphQL API.
Go to the GraphQL playground. Copy and run the query you see on the left side of the editor in Figure 3, then click the play button to send the query. The result should match what you see on the right-hand side of the playground, as shown in Figure 3.
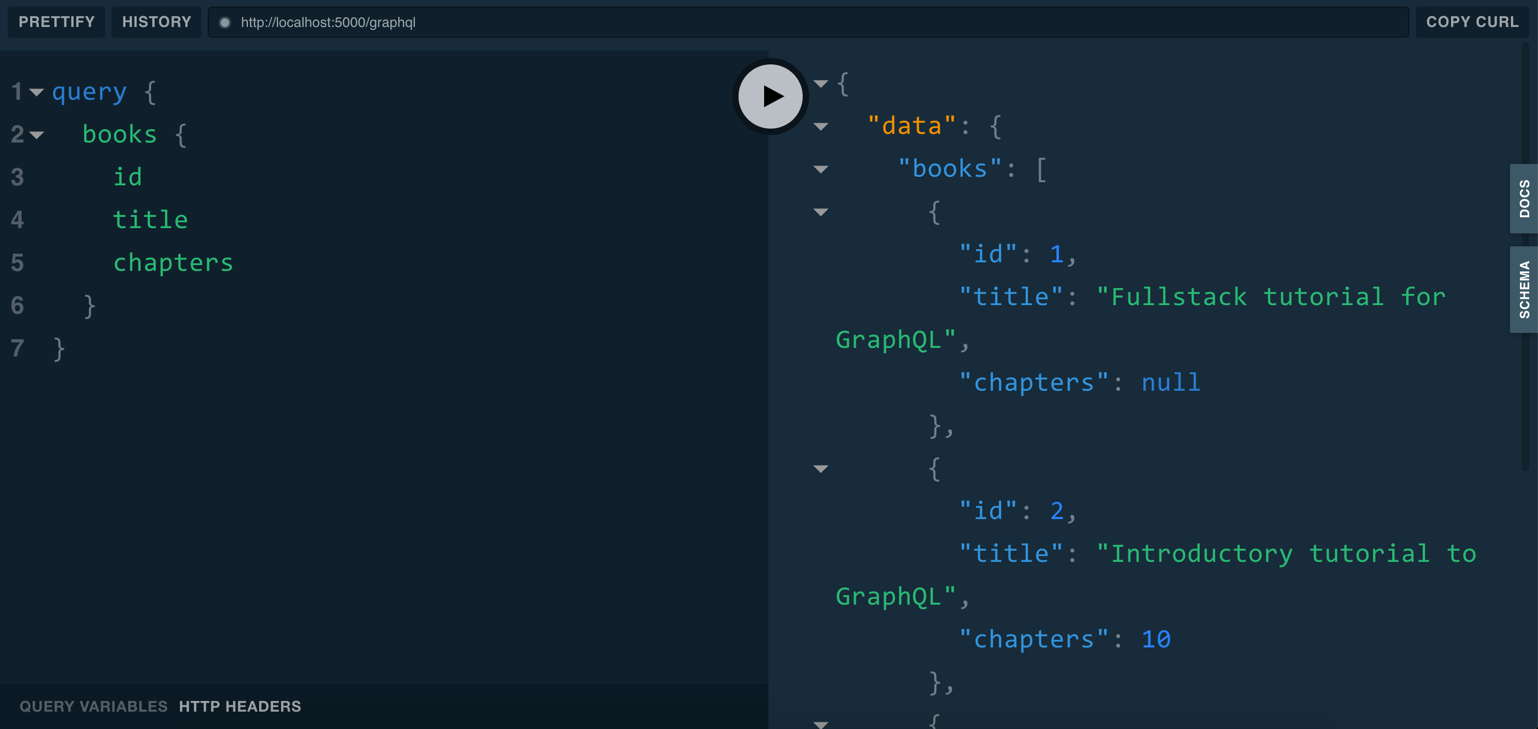
You'll notice that the query is structured similarly to the schema language. The books field is one of the root fields defined in the query type. Inside the curly braces, you have the selection set on the books field. Because this field returns a list of Book type, you specify the fields of the Book type that you want to retrieve. You omitted the pages field; therefore it isn't returned by the query.
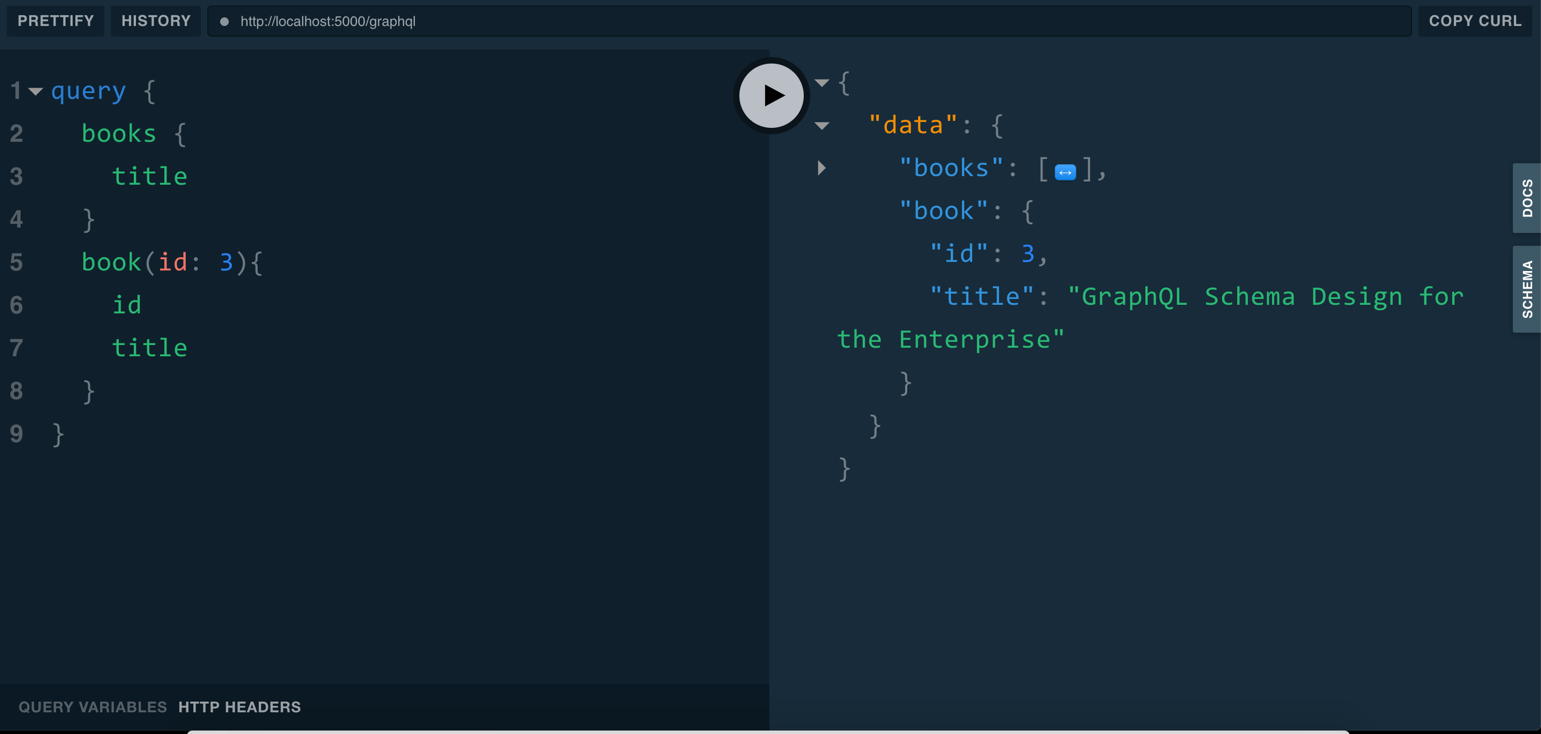
You can test the book(id) query to retrieve a book by its ID. Look at Figure 4 and run the query you see there to retrieve a book. In that query, you set the id argument to a value of 3, and it returned exactly what you need. You'll notice that I have two queries, books and book(id: 3). This is a valid query. The GraphQL engine knows how to handle it.
What's Next?
So far, I've covered some basics of GraphQL. You looked at defining a schema using the code-first approach, writing resolver functions, and querying the GraphQL API. You created a server using the GraphQL package for .NET, the NuGet package GraphQL.Server.Transports.AspNetCore, which is the ASP.NET Core middleware for the GraphQL API, and GraphQL.Server.Ui.Playground package that contains the GraphQL playground. You used the GraphQL playground to test your API. I explained that in GraphQL, there are three operation types. In this article, you worked with the query operation; in the next article, you'll look at mutations and accessing a database to store and retrieve data. You'll update your schema so you can query for related data, e.g., authors with their books, or books from a particular publisher. Stay tuned!!
