


Like when watching a sleight-of-hand magician, Web developers have been distracted by the recent popularity wars between the various front-end frameworks, and we've missed a fundamental shift in the nature of these frameworks. Functional Reactive Programming (FRP) has been quietly and steadily showing up in many aspects of the main frameworks of today.
You see this same change happening elsewhere, but as frameworks are the center of the front-end Web world, this is where all these influences come together. Why is this? Before I can answer that, you need to understand a few things about FRP.
What is FRP?
The simple answer to this question is that there is no simple answer. To the more academic side of the industry, FRP is all about values that change over time, sometimes called signals. But to the rest of the industry, FRP is more of an umbrella term that refers less to this esoteric definition, and more to the ancillary constructs and ideas that are generally part of FRP. These ideas and technologies include:
- Immutable data
- Observables
- Pure functions
- Static typing
- One-way state transitions
Let's take a quick look at each one of these items.
Immutable Data
Immutable data is a data type that can't change any value once it is created. Imagine an array that's created with two integers, 2 and 5. After you create it, you can't remove or add any elements, or change the values of either of those two elements. At first, this may seem to be unnecessarily limiting. When you need to turn that array into an array with three elements, 2, 5, and 8, you create a new array with those three elements. This may sound extremely non-performant, but in practice, it's not nearly as expensive as you would think and when used in change detection algorithms that exist in just about every front-end framework, it can lead to amazing performance gains. The most popular library that implements this is immutable.js.
Here's a simple example of using immutable.js to create a data structure, and then make a modification.
var map1 = Immutable.Map({a:1, b:2, c:3});
var map2 = map1.set('b', 50);
map1.get('b'); // 2
map2.get('b'); // 50
Notice that in the preceding code example, a new object is created when you change just one value. First, a map is created and then one of the values in that map is changed to a new value. This creates an entirely new object. The old object, map1, still has 2 for the value of b, and map2 has 50 for the value of b.
Observables
Observables have existed in the JavaScript world for a long time, although the FRP version of observables usually comes with more than the simplest form of an observable. These observables often have many more features than a typical observable and you can see this in action with libraries such as RxJS and Bacon.js. Like immutable data, observables give significant performance gains in change detection strategies.
Here's an example from the RxJS library that shows how to subscribe to an async data source, filter and map it, and then print out the results as they become available. This works not only with one piece of return data, but with a stream of data arriving intermittently as stock data does.
var source = getAsyncStockData();
var subscription = source.filter(function (quote) {
return quote.price > 30;
})
.map(function (quote) {
return quote.price;
})
.subscribe(function (price) {
console.log('Prices higher than $30: $' + price);
},
function (err) {
console.log('Something went wrong');
});
subscription.dispose();
Pure Functions
Pure functions are perhaps the most vague of these items because “pure” is a very common word. In this case, a pure function has no side effects. You can run the function as many times as you want and the only effect is that it computes its return value. Pure functions are significantly easier to both test and maintain. Using them lowers maintenance costs in applications written in frameworks like React and Mithril.
Here's a classic example of a non-pure function with side effects:
function getCustomerPrice(customer, item) {
var price;
if(customer.isUnapproved) {
customer.unapprovedAttempts.push({itemId: item.id})
} else if(customer.isPreferred) {
price = price * .9;
}
return price;
}
Notice how the Customer element is modified if they're unapproved? This is an example of a side effect. It's like a byproduct of the main job of the function, which is to simply get the customer price, and is the source of many bugs in programming. That's why you want pure functions with no side effects. A pure function version of this same code would leave logging the unapproved attempt to another piece of the program and simply return the customer price, as in the following:
function getCustomerPrice(customer, item) {
var price;
if(!customer.isUnapproved && customer.isPreferred) {
price = price * .9;
}
return price;
}
In any realistic application, you'll need state, and you'll need to modify that state at certain points, like logging the unapproved attempt shown in the first example here. But by drawing a line between areas that modify state, which are non-pure, and the parts that don't, which are implemented with pure functions, you create a lot of code that's simpler to build, test, and maintain. Pure functions rely on their inputs and not on any context. That means that they can be moved around and refactored easily. And, as shown in this example, pure functions tend to help you follow the single responsibility principle and keep things simple.
Static Typing
Static typing is the system whereby types of variables are established at compile time. This allows a program to avoid a host of typical run time errors and simple bugs. Many statically typed languages require a fair amount of ceremony to document the types and many programmers find this onerous. Some statically typed languages can infer types based on context, which means that most types don't need to be declared. You see this in Flow and TypeScript.
Let's look at an example of using an instance of a class in vanilla JavaScript, and again with TypeScript
class TodoModel{
// class properties
complete() {
// implementation
}
}
// vanilla JS
var todoModel1 = new TodoModel();
todoModel1.finish(); // throws a runtime error
//TypeScript
var todoModel2:TodoModel = new TodoModel();
todoModel2.finish(); // compile time error
The only difference between these two is that you've told the compiler that todoModel2 is of type TodoModel, which is a class that you declared. This lets the compiler know that if, later on, someone tries to call the finish method as shown in the snippet, there's no finish method and the error can be thrown at compile time. This makes the bug much cheaper to fix than waiting until unit tests are written, or even worse, having the error thrown at run time.
Also, notice that an inferred type system can give the same benefits by inferring that the type is TodoModel. That means that you don't have to declare the type, and the “vanilla JS” version can still act as if typed. Errors like the one discussed can still be caught at compile time. Both Flow and TypeScript support this.
One-Way State Transitions
One-way state transitions are perhaps the most significant of these various technologies. One-way state transitions are an architecture whereby changes to the model all go through a common type of dispatcher, then, when changes to the model are made, these changes are rendered to the screen. Figure 1 illustrates this idea. This is a way of thinking about your program as a simple cycle. Your model passes through a rendering function and becomes viewable elements. Changes (usually represented by user events) update the model, which then triggers a re-rendering of the view. The rendering functionality is ideally implemented as a pure function.
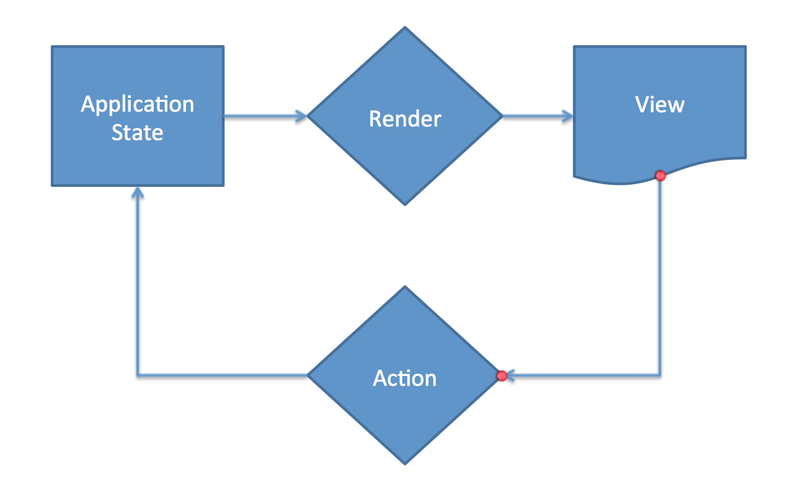
This concept deserves its own article to sufficiently explain these ideas, so I'll just touch on it. This architecture is significantly simpler and easier to learn than typical development because all actions that can change the state of a program are clearly and centrally defined. This makes it easier to look at a program and understand how it behaves. Imagine learning to operate a car without having first spent years in one, and having no guidance. As you explored it, you'd discover that you could lock and unlock the doors, open the hood and if you sat in it, you could turn the steering wheel (which doesn't seem to do anything useful), but that doesn't get you anywhere near to driving. You still need to learn that the key goes in the column to start the car, and how the radio and air conditioning work, and how turning the wheel really only matters when you're in motion, and how the pedals control the movement of the vehicle.
Now instead, imagine a manual that listed every action the car could take, and sent you to a page where you could read exactly what effect that action had. This is the difference between common programming architectures and one-way state transitions.
Using this methodology, it's cheaper to bring new developers onto a project because they can come up to speed quicker, with less direction, maintenance costs are down because problems are easier to track down, and brittleness is reduced overall. The largest payoff may be that as project sizes grow, velocity doesn't suffer the typical slow-down. Although the functional programming crowd (Haskell and Erlang programmers, among others) have been touting these very benefits for a long time, mainstream development as a whole hasn't been listening until now. And many people don't even realize where all of these ideas came from.
Deja Vu
It's important to note that most of these ideas are not particularly new, and many of them existed as early as the 80s or even earlier. Each of them can bring benefits to most development projects, but when used together, the total is greater than the sum of its parts. What's particularly interesting is the fact that these ideas aren't just suitable for a subset of application types. These same ideas have been used in games, animation, operating systems, and everything in between. For an interesting read on the parallels between React and Windows 1.0, check out this article: http://bitquabit.com/post/the-more-things-change/.
FRP Becomes Mainstream at Last
We are starting to see each of these previously mentioned ideas making their way into the mainstream of the Web development world. This is best recognized by their effect on the two dominant frameworks, React and Angular 2. Although it hasn't been released yet, due to the dominant market share of Angular 1, Angular 2 is definitely one of the frameworks occupying the attention of most front-end developers.
I'd be remiss if I didn't mention a third framework that you've probably never heard of: Elm. Elm is another front-end framework that makes the audacious move of being written in an entirely new language. Built by Evan Czaplicki while he attended Harvard, it's an attempt to make FRP more digestible to mainstream programmers. The reason that this is so remarkable is that it's had a heavy influence on both React and Angular 2.
The main reason that we're seeing these influences make their way into Web development now is centered on the never-ending quest for more maintainable code. Evan Czaplicki gave a great talk on this topic titled “Let's be Mainstream” ("https://www.youtube.com/watch?v=oYk8CKH7OhE"). As front-end applications grow ever larger, the need to make them easier to maintain has become more important. Because of this, we're seeing new techniques being introduced in an attempt to achieve this goal.
You can see this if you take a brief look at the overall history of front-end Web development. At each stage, the need for maintenance has driven a continual quest for methods to manage the complexity. The first attempt was simpler APIs through libraries like jQuery. Then frameworks came on the scene as a way to organize code into whole applications while still being modular and separating out various concerns. Automated testing quickly became a hot topic at this point. Then, increasingly fully featured frameworks appeared to help developers build bigger and bigger apps. All the while, everyone tried new methods to deal with constantly-expanding code bases.
Another reason we're seeing these influences now is that the high demand in front-end Web development continues to attract developers from other areas. These developers are bringing with them ideas that worked for them in other environments, and existing developers are looking to other areas for ideas that can help improve code built for the browser.
Changes are popping up all over. Both React and Angular 2 support using observable and immutable data. Both of them use one-way state transitions internally, and React even goes so far as to codify it for developers to follow with libraries such as Flux and the more recent Redux. Redux was directly inspired by Elm. Angular 2 supports using Redux or something similar, although they don't directly encourage it at this point. Both of them, meanwhile, encourage developers to use static typing with both Flow for React, and TypeScript in the Angular world.
What's Next
It's difficult to predict the future in any reasonable way, but there are a few places that you might see these ideas in action.
As FRP becomes mainstream, that could open up the door to widespread adoption of FRP languages like Elm. Combined with the features of Web Assembly, which makes JavaScript a more viable compile target, FRP languages such as Elm or Haskell - or new ones we haven't seen yet - could possibly make their way into popular Web development.
Another thing we'll likely see is a near-standardization on architectures using Flux-like one-way data state transitions. The React world seems to be standardizing on Redux, a simpler implementation than Flux, and adaptations of Redux for other frameworks are starting to appear.
Obviously, reading an article is useless unless it gives you actionable knowledge. So here's my advice to take advantage of the winds of change that are blowing in our industry:
- Be Aware. Just knowing what's going on will put you ahead of the curve.
- Learn. Go check out RxJs or Immutable.js or learn React and Angular 2.
- Open your mind. Even if these ideas sound strange to you, don't resist change. Open yourself up to new ideas and new paradigms. This is perhaps the best piece of advice I can give you.
