


There's a line in the movie “Lord of the Rings” about “the ties that bind us”. One thing that binds many application developers is the need to write T-SQL code. In this latest installment of The Baker's Dozen, I'll present 13 T-SQL programming tips. Although many of these are rather introductory topics that many SQL developers already know, there should hopefully be a few items in here that are new to intermediate SQL programmers.
What's on the Menu?
True to the traditional Baker's Dozen 13-item format, here are the 13 topics I'll cover in this issue:
- Cumulative aggregations before SQL Server 2012
- Cumulative aggregations using SQL 2012
- Moving Averages in SQL 2012
- Baker's Dozen Spotlight: calculating elapsed time across rows
- UNPIVOT versus UNION
- The multiple aggregation pattern (and anti-pattern)
- Differences between
INandEXISTS - A use for
RANKfunctions - Cursors versus table types for performance
- Calculating aggregations across rows
- Parameter sniffing and stored procedure execution plans
- Stored procedures that try to query for one parameter value or ALL
- The difference between
WHEREandHAVING
1: Cumulative Aggregations before SQL Server 2012
Programming challenge: As shown in Figure 1, based on Orders in AdventureWorks in 2006, write a query to retrieve the first order (by vendor) that gave the vendor a cumulative order total of at least $10,000.
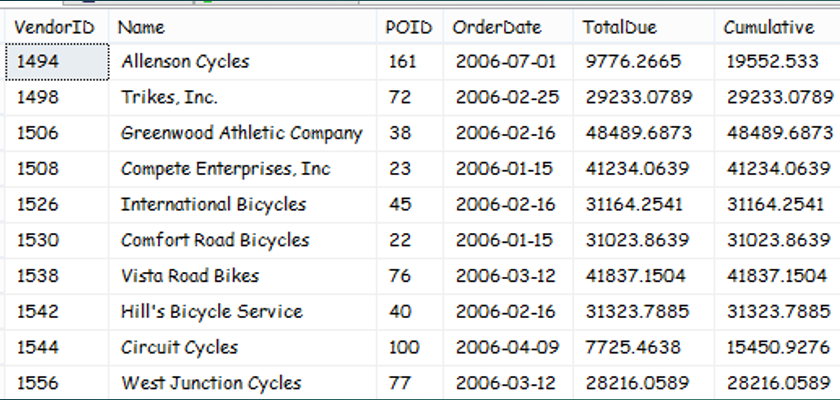
T-SQL developers often struggled with calculating cumulative aggregations (“running totals”) prior to SQL Server 2012. This was a scenario where developers often looked for a row-by-row approach instead of a set-based approach. Even the CROSS APPLY feature in SQL Server 2005 only partly helped with this issue, as developers still needed to write moderately complicated subqueries to conditionally aggregate from the first row of a scope to the most current row.
Listing 1 shows one solution for anything between SQL Server 2005 and SQL Server 2008R2, inclusive. The solution involves a CROSS APPLY to query the Order table in the outside and then on the inside as a subquery (similar to a SELF JOIN), and to sum the order amounts in 2006 for all orders for that vendor with a Purchase Order ID on the “inside” less than or equal to the Purchase Order ID on the “outside.” Yes, this approach assumes that the purchase order IDs are assigned in pure sequential/chronological order. You could also use an Order Date if the Order Date is down to split-second granularity where no two orders for the same vendor could have the exact same time.
Listing 1: Cumulative Aggregation (Running SUM) prior to SQL 2012
;with CumulativeCTE as
(
select POH.VendorID, POH.PurchaseOrderID ,
cast(POH.OrderDate as date) as OrderDate,
POH.TotalDue, RunningTotal.Cumulative
from Purchasing.PurchaseOrderHeader POH
cross apply ( select sum(TotalDue) as Cumulative
from Purchasing.PurchaseOrderHeader Inside
where Inside.VendorID =poh.VendorID and
Inside.PurchaseOrderID <= POH.PurchaseOrderID
and year(OrderDate) = 2006
) RunningTotal
where year(OrderDate) = 2006
and Cumulative > 10000 )
select VendorID, Name, CumulativeCTE.PurchaseOrderID as POID,
cast(CumulativeCTE.OrderDate as date) as OrderDate,
CumulativeCTE.TotalDue, CumulativeCTE.Cumulative
from Purchasing.Vendor
join CumulativeCTE on Vendor.BusinessEntityID =
CumulativeCTE.VendorID
where CumulativeCTE.PurchaseOrderID =
(select top 1 PurchaseOrderID from CumulativeCTE Inside
where VendorID = Vendor.BusinessEntityID
order by PurchaseOrderID )
order by VendorID, OrderDate
This pattern simulates a “perform varying” operation to sum up the order amounts for all orders prior to the current order. Once you've established a cumulative amount as a common table expression (and filter on the rows where the cumulative value exceeds $10,000), you can query into that common table expression and retrieve the first row (with a TOP 1 or a RANK() value of 1) for each vendor. This has never been an attractive or elegant solution, but it certainly works.
Fortunately, Microsoft added functionality to the T-SQL language in SQL Server 2012 to make cumulative aggregations a little easier, and that leads to the next tip.
2: Cumulative Aggregations using SQL 2012
Listing 2 shows a basic example of how to aggregate cumulatively, using the new SQL Server 2012 keywords ROWS UNBOUNDED PRECEDING, as shown below. This feature allows developers to sum/aggregate rows from the first row in a group to the “current” row based on a specific order.
select PurchaseOrderID, OrderDate, TotalDue,
SUM(TotalDue) OVER (PARTITION BY VendorID
ORDER BY PurchaseOrderID
ROWS UNBOUNDED PRECEDING ) AS
CumulativeAmount FROM.....
Listing 2: Cumulative SUM using UNBOUNDED PRECEDING in SQL 2012
select PurchaseOrderID, OrderDate, TotalDue,
SUM(TotalDue) OVER (PARTITION BY VendorID
ORDER BY PurchaseOrderID
ROWS UNBOUNDED PRECEDING ) AS CumulativeAmount
from Purchasing.PurchaseOrderHeader
where VendorID = 1494 and year(OrderDate) = 2006
order by PurchaseOrderID
This gives you a cumulative sum of TotalDue for each row, based on all prior orders for the Vendor. But how? There are two related answers. First, the SUM(TotalDue) OVER tells SQL Server that you want to aggregate over a set (or window) of rows. Second, the PARTITION BY VendorID tells SQL Server that aggregated sum based on the “group” of VendorID. Third, the ROWS UNBOUNCED PRECEDING tells SQL Server to start at the first row (based on the PARTITION and in order by PurchaseOrderID) and sum up to the current row. This is how you tell SQL Server, “for the current row in the result set, sum all the prior rows for that vendor, starting with the first row and ending with the current row.” This is powerful stuff!
Listing 3 shows the full-solution counterpart to Listing 1. You still need to do some type of SELF JOIN to dive back into this table to grab the first row where the cumulative amount exceeds 10,000. It's very difficult to do all of this in one simple query, but at least the new language statements in SQL 2012 make this simpler than prior versions.
Listing 3: Full example of ROWS UNBOUNDED PRECEDING in SQL 2012
; with CumulativeCTE AS
(select VendorID, PurchaseOrderID, OrderDate, TotalDue,
SUM(TotalDue) OVER (PARTITION BY VendorID ORDER BY
PurchaseOrderID
ROWS UNBOUNDED PRECEDING ) AS CumulativeAmount
from Purchasing.PurchaseOrderHeader
WHERE OrderDate BETWEEN '1-1-2006' AND '12-31-2006' )
SELECT Vendor.Name, Outside.*
FROM Purchasing.Vendor
JOIN CumulativeCTE Outside
ON Vendor.BusinessEntityID = Outside.VendorID
WHERE Outside.PurchaseOrderID = (SELECT TOP 1 PurchaseOrderID
FROM CumulativeCTE Inside
WHERE Inside.VendorID = Outside.VendorID AND
Inside.CumulativeAmount > 10000
ORDER BY Inside.PurchaseOrderID)
3: Moving Averages in SQL 2012
Programming challenge: As shown in Figure 2, based on Orders in AdventureWorks in 2006, write a query to retrieve the weekly orders and four-week moving average of weekly orders for a specific vendor. The “current week” should be included in the four-week range. If a week has no sales (null), you include it (as if the sales were zero).

Fortunately, you can use the same windowing functions and features in SQL Server 2012 that you saw in the last tip. In this instance, for each summarized row (by week), you can average “over” the four prior rows using the syntax in the snippet below. Note that instead of using ROWS UNBOUNDED PRECEDING as you did before, you use ROWS 3 PRECEDING to include the three prior rows based on the order of the Week Ending Date. Because the AVG OVER includes the current row, retrieving the three prior rows gives us the four-week moving average effect. Also note that you use ISNULL to transform any NULL values to zero. Otherwise, aggregation functions like AVG would ignore the NULL week (unless that's the intention).
select DateList.WeekEnding, SumTotalDue,
AVG( ISNULL(SumTotalDue,0)) OVER
(ORDER BY DateList.WeekEnding
ROWS 3 preceding)
as MovingAvg
FROM ...
Listing 4 shows the entire solution, which also includes a simple table-valued function to explode a date range between two dates, and also a scalar function to express a date in terms of a week-ending Saturday date.
Listing 4: Moving average in SQL 2012 with AVG OVER
CREATE FUNCTION [dbo].[CreateDateRange]
(@StartDate Date, @EndDate Date)
RETURNS
@WeekList TABLE (WeekEnding Date)
AS
BEGIN
; WITH DateCTE(WeekEnding) AS
(SELECT @StartDate AS WeekEnding
UNION ALL
SELECT DateAdd(d,7,WeekEnding) AS WeekEnding
FROM DateCTE WHERE WeekEnding < @EndDate
)
insert into @WeekList select * from DateCTE
OPTION (MAXRECURSION 1000)
RETURN
END
GO
CREATE FUNCTION [dbo].[WeekEndingDate]
( @InputDate date )
RETURNS Date
AS
BEGIN
DECLARE @ReturnDate DATE
-- @@DateFirst defaults to 7 (Sunday),
SET @ReturnDate =
dateadd(day,
(@@DateFirst -
datepart(weekday, @InputDate)), @InputDate)
RETURN @ReturnDate
END
GO
DECLARE @StartDate DATE, @EndDate DATE
SET @StartDate = '12-8-2007'
SET @EndDate = '3-29-2008'
;With summarizedCTE as
(select VendorID, dbo.WeekEndingDate(OrderDate) as WeekEndDate,
SUM(TotalDue) AS SumTotalDue
FROM Purchasing.PurchaseOrderHeader POH
WHERE OrderDate BETWEEN @StartDate AND @EndDate
AND VendorID = 1496
GROUP BY VendorID, dbo.WeekEndingDate(OrderDate))
select DateList.WeekEnding, SumTotalDue,
AVG(ISNULL(SumTotalDue,0)) OVER
(ORDER BY DateList.WeekEnding ROWS 3 preceding) as MovingAvg
FROM dbo.CreateDateRange ( @StartDate, @EndDate ) DateList
left outer join SummarizedCTE on DateList.WeekEnding =
summarizedCTE.WeekEndDate
order by WeekEnding
4: Baker's Dozen Spotlight: Calculating Elapsed Time across Rows
Programming challenge: As shown in Figure 3, where you have the names of individuals who've moved from phase to phase (for any business process, the specific process doesn't matter) with a specific start and end time, you want to produce a result set that shows the elapsed time from all possible name/starting phases to name/ending phases. For Kevin, you want to know the elapsed time from Phase 1 through Phase 4 (1, 2, 3, 4), and then from Phase 2 to 4 (2, 3, 4), etc. The desired result set is shown in Figure 4. Ultimately, you might want to produce average time statistics on how long it takes to move from Phase 2 to Phase 4, etc.
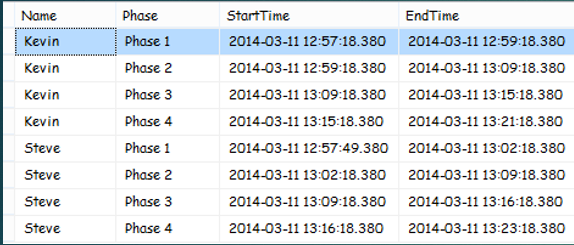
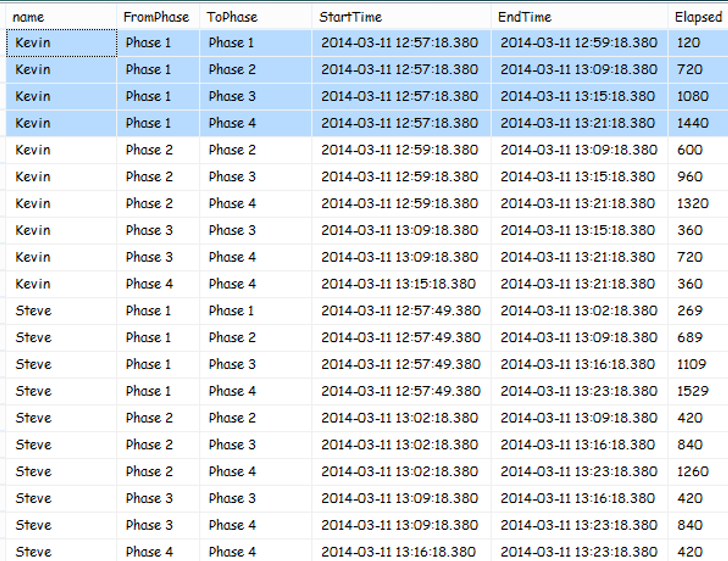
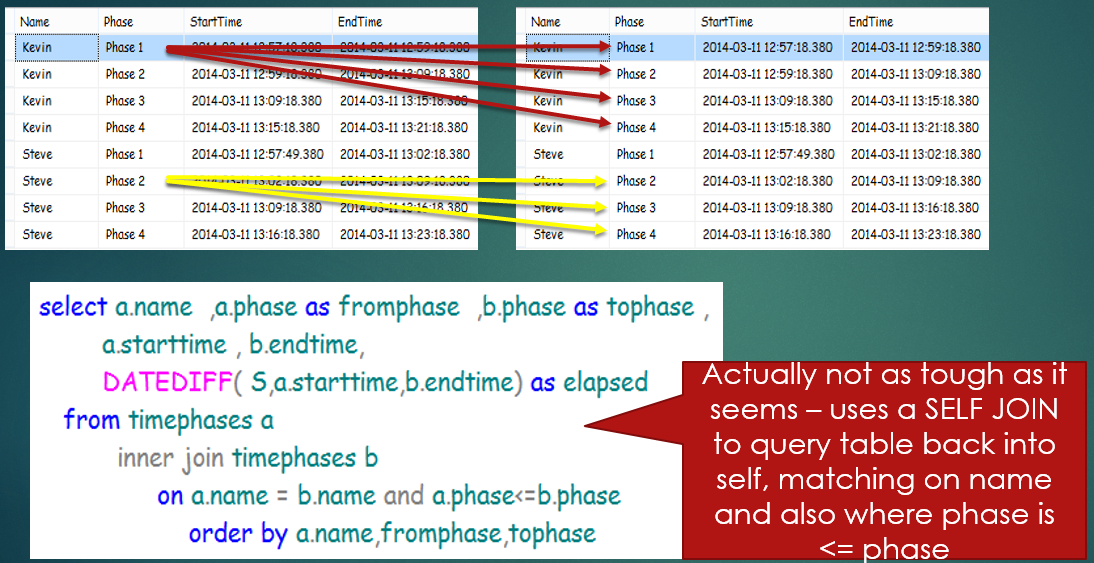
Not too long ago, I had to generate a result set like this for a client. I'll admit freely that I initially made the problem (and the query) too complicated. After some discussions with other developers, I realized all that was needed was a SELF-JOIN into the original table, matching up on the name and where the phase was one less. Once I joined up the outer table on a name/phase with an inner table on the name and “next” phase, I could use the DATEDIFF function to determine the difference between the time for the next phase and the time for the current phase. Listing 5 shows the entire solution.
Listing 5: Elapsed time across rows (Baker's Dozen Spotlight)
CREATE TABLE TimePhases ( Name varchar(50), Phase varchar(10),
StartTime datetime, EndTime datetime)
INSERT INTO TimePhases values ('Kevin', 'Phase 1',
'2014-03-11 12:57:18.380', '2014-03-11 12:59:18.380')
INSERT INTO TimePhases values ('Kevin', 'Phase 2',
'2014-03-11 12:59:18.380', '2014-03-11 13:09:18.380')
INSERT INTO TimePhases values ('Kevin', 'Phase 3',
'2014-03-11 13:09:18.380', '2014-03-11 13:15:18.380')
INSERT INTO TimePhases values ('Kevin', 'Phase 4',
'2014-03-11 13:15:18.380', '2014-03-11 13:21:18.380')
INSERT INTO TimePhases values ('Steve', 'Phase 1',
'2014-03-11 12:57:49.380', '2014-03-11 13:02:18.380')
INSERT INTO TimePhases values ('Steve', 'Phase 2',
'2014-03-11 13:02:18.380', '2014-03-11 13:09:18.380')
INSERT INTO TimePhases values ('Steve', 'Phase 3',
'2014-03-11 13:09:18.380', '2014-03-11 13:16:18.380')
INSERT INTO TimePhases values ('Steve', 'Phase 4',
'2014-03-11 13:16:18.380', '2014-03-11 13:23:18.380')
select a.name ,a.phase as fromphase ,b.phase as tophase ,
a.starttime , b.endtime,
DATEDIFF( S,a.starttime,b.endtime) as elapsed
from timephases a
inner join timephases b
on a.name = b.name and a.phase<=b.phase
order by a.name,fromphase,tophase
I've also included an illustration of this solution in Figure 5.
5: UNPIVOT versus UNION
Programming challenge: As shown in Figure 6, convert the flat, denormalized rows of monthly sales by SalesManID to a normalized set of rows.
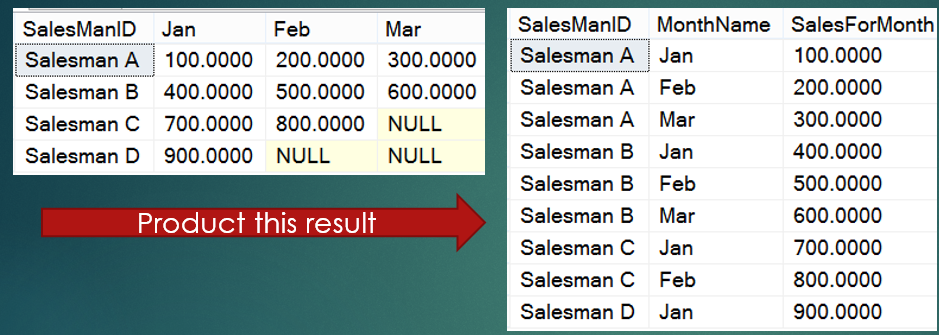
Most developers would likely write this solution as a UNION ALL statement, with one SELECT statement for each column. Although this works, developers are likely to include a performance penalty with all the SELECT and UNION ALL statements. UNION ALL won't perform a duplicate check, but an alternate solution might be to use the UNPIVOT feature that Microsoft added in SQL Server 2005. Admittedly, when Microsoft added PIVOT and UNPIVOT in SQL 2005, I first expected that I'd use PIVOT frequently. As it turns out, I've used UNPIVOT more often, especially in the last few years.
UNPIVOT isn't necessarily intuitive and I'll also admit that I need to keep an example close by for when I need it again. But it can give you better performance and a less-costly execution plans, especially when dealing with a high number of rows and columns. Listing 6 shows a basic example of UNPIVOT to convert the columns to rows. Note that just like with the PIVOT statement, the column list is static - you'd need to use dynamic SQL if you don't know the column names until runtime.
Listing 6: UNPIVOT as an alternative to UNION ALL
create table dbo.SalesTemp
(SalesManID varchar(10), Jan decimal(14,4), Feb decimal(14,4),
Mar decimal(14,4))
GO
insert into SalesTemp values ('Salesman A', 100, 200, 300),
('Salesman B', 400, 500, 600),
('Salesman C', 700, 800, null),
('Salesman D', 900, null, null)
SELECT SalesManID, MonthName, SalesForMonth
FROM dbo.SalesTemp AA
UNPIVOT (SalesForMonth FOR MonthName IN (Jan, Feb, Mar)
) TempData
6: The Multiple Aggregation Pattern (and Anti-pattern)
Programming challenge: As shown in Figure 7, you have three tables, a Job Master and then two child tables (Job Hours and Job Materials). The relationship between Job Master and the two child tables is one-to-many. You want to produce a result set with one row per job, summarizing the hours and materials.
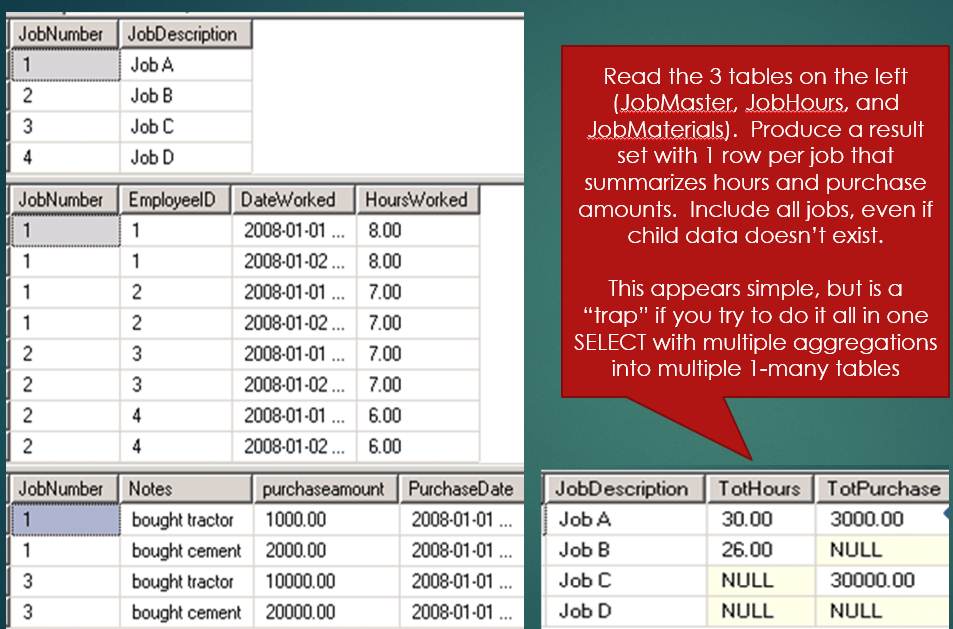
I've used this example for years (close to a decade) as an example of the dangers of multiple aggregations, and where subqueries are necessary. Although I've tried to not use examples from prior Baker's Dozen articles, in this article, I admit that I've used this before. However, as a consultant, I continue to see developers who (understandably) fall victim to the anti-pattern I'm about to describe. And admittedly, a few weeks ago, I almost caught myself falling into the trap myself!
Listing 7 first shows a standard SELECT with two LEFT OUTER JOINSs into the two child tables, with aggregations on both the Hours Worked and the Purchase Amounts.
Listing 7: Danger of multiple aggregations
CREATE TABLE JobMaster (JobNumber int, JobDescription varchar(50))
CREATE TABLE JobHours (JobNumber int, EmployeeID int,
DateWorked DateTime,
HoursWorked decimal(10,2))
CREATE TABLE JobMaterials (JobNumber int, Notes varchar(50),
purchaseamount decimal(14,2),
PurchaseDate DateTime)
insert into JobMaster values (1, 'Job A'), (2, 'Job B'),
(3, 'Job C'), (4, 'Job D')
INSERT INTO JobHours values (1, 1, '01-01-08',8)
INSERT INTO JobHours values (1, 1, '01-02-08',8)
INSERT INTO JobHours values (1, 2, '01-01-08',7)
INSERT INTO JobHours values (1, 2, '01-02-08',7)
INSERT INTO JobHours values (2, 3, '01-01-08',7)
INSERT INTO JobHours values (2, 3, '01-02-08',7)
INSERT INTO JobHours values (2, 4, '01-01-08',6)
INSERT INTO JobHours values (2, 4, '01-02-08',6)
insert into JobMaterials values (1, 'got tractor',1000,'1-1-08')
insert into JobMaterials values (1, 'got cement',2000,'1-1-08')
insert into JobMaterials values (3, 'got tractor',10000,'1-1-08')
insert into JobMaterials values (3, 'got cement',20000,'1-1-08')
-- this produces incorrect results for Job A
select jobmaster.JobDescription, SUM(HoursWorked) as SumHours,
SUM(purchaseamount) as SumMaterials
from JobMaster
left outer join JobHours
on JobMaster.JobNumber = JobHours.JobNumber
left outer join JobMaterials
on JobMaster.JobNumber = JobMaterials.JobNumber
Group by JobMaster.JobDescription
order by JobDescription
-- By aggregating as separate definitions, we get the right results
; with HoursCTE AS
(SELECT JobNumber, SUM(HoursWorked) as TotHours
from JobHours group by JobNumber) ,
MaterialsCTE AS
(SELECT JOBNUMBER, SUM(PurchaseAmount) as TotPurchase
from JobMaterials GROUP BY JobNumber)
SELECT JobMaster.JobNumber, JobMaster.JobDescription,
TotHours, TotPurchase
FROM JobMaster
LEFT join HoursCTE
ON JobMaster.JobNumber = HoursCTE.JobNumber
LEFT JOIN MaterialsCTE
ON JobMaster.JobNumber = MaterialsCTE.JobNumber
If you weren't aware of the problem, you might think the first query would be acceptable. Unfortunately, it generates the results shown in Figure 8.
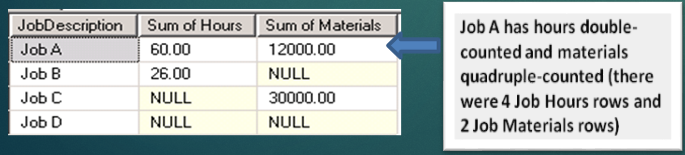
You should have had values of 30 hours and $3,000 for Job A, but instead, the results show 60 hours and $12,000. Is this bug in SQL Server? Absolutely not. This is a case of the database engine doing precisely what you TOLD IT to do, as opposed to what you WANTED IT to do. So why are the numbers so inflated for Job A? Before I get to that, here are some hints:
- You should have had 30 hours and we got 60 hours. That's a factor of two.
- You should have had $3,000 for materials and you got $12,000. That's a factor of four.
- There were two rows in Job Hours for Job A.
- There were four rows in Job Materials for Job A.
Basically, the factor by which you were off in the one child table happens to be the number of rows in the other child table. Is this a coincidence? No, it's not! Here's the issue: although unintentional, you've produced an internal Cartesian product (cross join) between the four instances of Job A in hours with the two instances of Job A in job materials. Basically, Job A was “exploded” into eight rows in the internal result set!
This is a perfect example where you can't do all of this in one SELECT statement and where subqueries are necessary. The second query in Listing 7 uses two common table expressions (derived table subqueries) to pre-aggregate the two child tables. You can then join the master table to the two common table expressions in a one-to-one fashion and generate the correct results.
I came across the “multiple aggregations” anti-pattern a little over 15 years ago. I wrote a query similar to the first query in Listing 7. Fortunately, I noticed the problem with the results before I implemented the code to production. But I've known developers who weren't so fortunate. Some didn't notice and verify the results, and got bit in production. Rarely does someone discover and realize an anti-pattern in one shot. The realization starts with identifying some undesirable result - anything from wrong numbers on a report to an inelegant process. My first inkling on the “multiple aggregations” anti-pattern was noticing inflated numbers in one of my test cases. It took me a while to fully understand the problem, but at least I was fortunate that I caught the problem before the users did!
Rarely does someone discover and realize an anti-pattern in one shot. The realization starts with identifying some undesirable result - anything from wrong numbers on a report to an inelegant process.
7: Differences between IN and EXISTS
Programming challenge: Describe the differences between IN and EXISTS.
IN and EXISTS might initially look similar, but in reality they're very far apart. Listing 8 shows an example for both.
Listing 8: IN vs EXISTS
-- using IN, must match up a single column. Inside query
-- can run on its own
SELECT Vendor.Name
from Purchasing.Vendor
WHERE (BusinessEntityID) in
(SELECT VendorID from Purchasing.PurchaseOrderHeader
WHERE YEAR(OrderDate) = 2006 AND ShipMethodID = 1)
-- Correlated subquery
SELECT VendorOutside.Name
from Purchasing.Vendor VendorOutside
WHERE EXISTS (SELECT * from Purchasing.PurchaseOrderHeader
WHERE YEAR(OrderDate) = 2006 AND ShipMethodID = 1
AND VendorID = VendorOutside.BusinessEntityID )
Here are the fundamental differences.
- With the
INfeature, you use a derived table subquery that could execute independently. You specify a single column on the outside and match to the single column returned on the inside. It's good for general testing but many recommend against it (or caution against it) in production. - With
EXISTS, you use a correlated subquery. The subquery cannot execute independently, as it refers to (correlates with) values from the outer parent query. Unlike theINstatement, you don't specify a specific column on the outside to match with the values returned from theSELECTon the inside. Instead, you match up columns as aWHEREclause on the inside. This is arguably a bit more complicated, but ultimately provides more flexibility.
Listing 8 shows the difference between IN and EXISTS. Listing 9 also shows another issue with IN; or more specifically, with NOT IN. A developer might want to know how many keys are “not in” the results from a derived table subquery. The problem is that if the derived table subquery contains any NULL values for the column being used in the match, the outer result will always be empty! As a result, you need to make sure that you include a WHERE <column> IS NOT NULL in the derived table subquery (or just use the recommended EXISTS instead).
Listing 9: Danger of NOT IN with NULL values
DECLARE @ColorMaster TABLE (ColorID int identity,
Color varchar(100))
DECLARE @SalesTable TABLE (SalesID int identity,
SalesAmount money, ColorID int)
insert into @ColorMaster (Color) values ('Red'), ('Blue'), ('Yellow')
insert into @SalesTable (SalesAmount, ColorID) values ( 100, 1),
(200, 2), (300, null)
select * from @ColorMaster Colors where ColorID in (select ColorID
from @SalesTable ) -- 2 rows....Red and Blue
select * from @ColorMaster Colors where ColorID not in (select
ColorID from @SalesTable ) -- 0 rows - WHAT???
select * from @ColorMaster Colors where ColorID not in
(select ColorID from @SalesTable WHERE ColorID is not null)
-- This works, must filter out the NULLs on the inside
-- or SQL Server generates zero rows in outer result set
Recently I asked a group of SQL developers to describe the difference between IN and EXISTS. I knew they'd written code for those features before, but was curious how they'd respond. It might seem like an academic exercise, but try to take some feature you frequently use and define it with a limited number of references to specific code. You'd be amazed at how much you can take aspects of a feature for granted until you really start breaking down definitions. (I'm the king of taking things for granted if I don't stop to think about them!)
You'd be amazed at how much you can take aspects of a feature for granted until you really start breaking down definitions.
8: A Use for RANK Functions
Programming challenge: Using AdventureWorks purchase orders in 2006 summarized by Vendor and Ship Method, show each Ship Method and the top two Vendor IDs (in terms of total order dollars).
Although some developers might use the SELECT TOP 2 VendorID order by DollarAmount approach, you'd need to use it for each Ship Method. You can do that, but another approach is to use the RANK functions that Microsoft introduced in SQL Server 2005. Listing 10 contains a query that generates a rank number (within each Ship Method, ordered by the sum of order dollars).
Listing 10: RANKing and PARTITIONING
SELECT * FROM
(SELECT ShipMethodID, VendorID, SUM(TotalDue) as TotalDollars,
RANK () OVER (PARTITION BY ShipMethodID
ORDER BY SUM(TotalDue) DESC) as VendorRank
FROM Purchasing.PurchaseOrderHeader
WHERE OrderDate BETWEEN '1-1-2006' AND '12-31-2006'
GROUP BY ShipMethodID, VendorID ) Temp
-- can't filter on RANK, must use subquery and then refer
-- to the ALIAS column
WHERE VendorRank <= 2
Here's the core code that uses the RANK function and PARTITION BY/ORDER BY statements:
SELECT ShipMethodID, VendorID,
SUM (TotalDue) as TotalDollars,
RANK () OVER (PARTITION BY ShipMethodID
ORDER BY SUM(TotalDue) DESC) as VendorRank
FROM Purchasing.PurchaseOrderHeader
Of course, that code snippet returns all ShipMethodID/VendorID combinations with orders. You want the first two vendors for each Ship Method. Can you use the VendorRank alias in the WHERE clause? No, because you can only use table column names in the WHERE clause. Can you be a bit verbose and repeat the RANK function in the WHERE clause, much in the same way that you might do with a scalar function? No, because the RANK functions read across a set (window) of rows, and the WHERE clause operates row-by-row. So you'd need to wrap that SELECT statement (in the snippet above) as a derived table/common table expression and then refer to the materialized VendorRank column on the outside.
9: Cursors versus Table Types for Performance
Listing 11 and Listing 12 represent a challenge that developers face when attempting to execute a stored procedure for a set of rows. I'll whittle it down to a very simple example, but one where the pattern applies to many situations. The two listings contain code for two different approaches to solve the problem. Listing 11 uses SQL Server cursors, an older approach that can sometimes yield serious performance issues. Listing 12 uses table types, a feature that Microsoft added in SQL Server 2008. I'll cover the approaches in reverse order. First, I'll talk about Table Types as I break down the code in Listing 12.
Listing 12: Cursors versus Table Types: (Second, Table Types, GOOD!!!)
CREATE TYPE IntKeysTT AS TABLE
( [IntKey] [int] NOT NULL )
GO
create procedure dbo.UpdateVendorOrdersFromTT
@IntKeysTT IntKeysTT READONLY
As
Begin
update Purchasing.PurchaseOrderHeader set Freight = Freight + 1
FROM Purchasing.PurchaseOrderHeader
JOIN @IntKeysTT TempVendorList
ON PurchaseOrderHeader.VendorID = TempVendorList.IntKey
End
go
create procedure dbo.RunUpdateVendorsUsingTTs
as
begin
DECLARE @VendorList IntKeysTT
INSERT INTO @VendorList
SELECT BusinessEntityID from Purchasing.Vendor
WHERE CreditRating = 1
exec dbo.UpdateVendorOrdersFromTT @VendorList
end
go
exec dbo.RunUpdateVendorsUsingTTs -- runs in roughly 1 second
Suppose you have a stored procedure that receives a single vendor ID and updates the freight for all orders with that vendor ID. Now, suppose you need to run this procedure for a set of vendor IDs. Today you might run the procedure for three vendors, tomorrow for five vendors, the next day for 100 vendors. Each time, you want to pass in the vendor IDs. If you've worked with SQL Server, you can probably guess where I'm going with this. The big question is: How do you pass a variable number of Vendor IDs? Or, stated more generally, how do you pass an array, or a table of keys, to a procedure? Something along the lines of:
exec dbo.UpdateVendorOrders @SomeListOfVendors
Prior to SQL Server 2008, developers needed to pass XML strings or comma-separated lists of keys to a procedure, and the procedure converted the XML/CSV strings into table variables for eventual joins with other data. Although this worked, developers wanted a more direct path. In SQL Server 2008, Microsoft implemented the table type. This FINALLY allowed developers to pass an actual table of rows to a stored procedure.
Passing a table of rows to a stored procedure requires a few steps. You can't just pass any old table to a procedure. It has to be a pre-defined type (a template). Let's suppose that you always want to pass a set of integer keys to different procedures. One day it might be a list of vendor keys. The next day it might be a list of customer keys. You can create a generic table type of keys, one that can be instantiated for customer keys, vendor keys, etc.
CREATE TYPE IntKeysTT AS TABLE
( [IntKey] [int] NOT NULL )
GO
I've created a table TType called IntKeysTT. It's defined to have one column: an IntKey. Now, suppose I want to load it with Vendors who have a Credit Rating of 1 and then take that list of Vendor keys and pass it to a procedure:
DECLARE @VendorList IntKeysTT
INSERT INTO @VendorList
SELECT BusinessEntityID
from Purchasing.Vendor
WHERE CreditRating = 1
Now I have a table type variable, and not just any table variable, but a table type variable (that I populated the same way I would populate a normal table variable). It's in server memory (unless it needs to spill to tempDB) and is therefore private to the connection/process.
Can you pass it to the stored procedure now? Not yet. You need to modify the procedure to receive a table type. The full code is in Listing 12, but here's the part of the stored procedure that you need to modify:
create procedure dbo.UpdateVendorOrdersFromTT
@IntKeysTT IntKeysTT READONLY
As
Begin
Notice how the procedure receives the parameter IntKeysTT table type as a table Type (again, not just a regular table, but a Table Type). It also receives the parameter as a READONLY parameter. You CANNOT modify the contents of this table type inside the procedure. Usually you won't want to; you simply want to read from it. Now you can reference the table type as a parameter and then use it in the JOIN statement, just as you would any other table variable.
There you have it. It's a bit of work to set up the table type, but in my view, definitely worth it.
Additionally, if you pass values from .NET, you're in luck. You can pass an ADO.NET data table (with the same tablename property as the name of the Table Type) to the procedure. For .NET developers who've had to pass CSV lists, XML strings, and so forth to a procedure in the past, this is a huge benefit!
Now I'd like to talk about Listing 11 and an approach people have used over the years: SQL Server cursors. At the risk of sounding dogmatic, I strongly advise against cursors unless there's just no other way. Cursors are expensive operations in the server. For instance, someone might use a cursor approach and implement the solution in the way I'll describe in a moment.
Listing 11: Cursors versus Table Types (First, Cursors – BAD!!!)
create procedure dbo.UpdateVendorOrders
@VendorID int
As
Begin
update Purchasing.PurchaseOrderHeader set Freight = Freight + 1
where VendorID = @VendorID
end
go
create procedure dbo.RunUpdateVendorsUsingCursor
as
begin
set nocount on
DECLARE @VendorID int
DECLARE db_cursor CURSOR FAST_FORWARD FOR
SELECT BusinessEntityID from Purchasing.Vendor
where CreditRating = 1
OPEN db_cursor
FETCH NEXT FROM db_cursor INTO @VendorID
WHILE @@FETCH_STATUS = 0
BEGIN
EXEC dbo.UpdateVendorOrders @VendorID
FETCH NEXT FROM db_cursor INTO @VendorID
END
CLOSE db_cursor
DEALLOCATE db_cursor
end
go
exec dbo.RunUpdateVendorsUsingCursor -- takes 48-52 seconds
The best thing I'll say about SQL Server cursors is that it “works”. And yes, getting something to work at all is a milestone. But getting something to work and getting something to work well are two different things. Even if this process only takes 5-10 seconds to run, in those 5-10 seconds, the cursor uses SQL Server resources quite heavily, which isn't a good idea in a large production environment. Additionally, the greater the number of rows in the cursor to fetch and the greater the number of executions of the procedure, the slower it will be.
When I ran both processes (the cursor approach in Listing 11 and then the table type approach in Listing 12) against a small sampling of vendors (five vendors), the processing times where 260ms and 60ms, respectively. The table type approach was roughly four times faster. Then when I ran the two scenarios against a much larger number of vendors (84 vendors), the difference was staggering: 6701ms versus 207ms, respectively. The table type approach was roughly 32 times faster.
Again, the CURSOR approach is definitely the least attractive approach. Even in SQL Server 2005, it would have been better to create a CSV list or an XML string (if the number of keys can be stored in a scalar variable). But now that there's a table type feature in SQL Server 2008, you can achieve the objective with a feature that's more closely modeled to the way developers think. Specifically: “How do I pass a table to a procedure?” Now you have an answer!
Now that there's a table type feature in SQL Server 2008, you can achieve the objective with a feature that's more closely modeled to the way developers think.
10: Calculating Aggregations across Rows
Programming challenge: Using AdventureWorks, by Vendor, list the average amount of time between orders. Although this could be done by taking the specific time between each individual order, I'll keep this simple. For each vendor, get the earliest order date and the most recent order date, calculate the difference in days, and then divide by the number of orders (minus 1, since a vendor with two orders would only have one segment of time between them).
I'll start by profiling the orders for a small vendor, Vendor ID 1636 (Figure 9). Because the rules state that you need to take the oldest and newest dates and divide by the number of orders, you can use MIN and MAX, subtract one from the other to determine the total number of days between, and then divide by the count of rows in order to come up with a basic average.
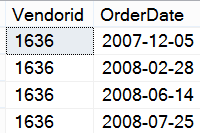
The total number of days elapsed for this vendor (between the first and last orders) is 233 days. If you divide that by four, you get 58.25 days. You know that number can't be right, as the difference between two of the date ranges far exceeds 58.25 days. You need to divide by three (or the COUNT(*) minus 1), as you actually have three periods in between the four orders (from 1 to 2, from 2 to 3, and from 3 to 4). The final result in Listing 13 needs to divide the total elapsed days by the count, less 1. That gives you the correct results (as seen in Figure 10).
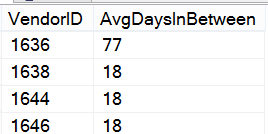
Also note that in Listing 13, you need to use a HAVING clause to only include those vendors with a total order count greater than 1. If a vendor has only one order, there's no elapsed time and therefore nothing to calculate.
Listing 13: Simple (but not so simple) Aggregation
select VendorID,
DATEDIFF(D,MIN(OrderDate), MAX(OrderDate) )
/ ( COUNT(*)-1) -- subract 1 for # of intervals
AS AvgDaysInBetween
from Purchasing.PurchaseOrderHeader
GROUP BY VendorID
HAVING COUNT(*) > 1 -- only for vendors with more than 1 order
ORDER BY VendorID
Finally, suppose that you wanted to change this exercise and produce a result set that showed the current order and “last order date” on the same line. You can use the LAG function to “hop back” one row, based on the order sequence of the order date, and within the VendorID group/partition.
select *,
datediff (d,LastOrderDate, OrderDate)
as DaysInBetween
FROM
(select Vendorid,
cast(orderdate as date) as OrderDate,
lag(cast( orderdate as date),1,null) over
(Partition by VendorID
Order by OrderDate) as LastOrderDate
from Purchasing.PurchaseOrderHeader) Temp
order by orderdate
That produces a result set like the one in Figure 11.
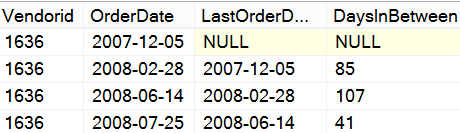
You can use the
LAGfunction to “hop back” one row, based on the order sequence of the order date, and within the VendorID group/partition.
11: Parameter Sniffing and Stored Procedure Execution Plans
Listing 14 shows the basics of parameter sniffing. Suppose that you have a table with an index on Product ID. The three stand-alone queries at the beginning of Listing 14 yield at least two different execution plans. For one value, the query generates an execution plan with an Index Seek execution operator plus a Key Lookup execution operator (to retrieve the non-key columns) and the other values generate an execution plan with an Index Scan. In the latter case, it's because SQL Server examined the distribution of values of the product ID within the clustered (physical order) index and determined that an Index Scan would be more efficient than an Index Seek and a subsequent Key Lookup.
Listing 14: Parameter Sniffing, the basics
select PurchaseOrderID, PurchaseOrderDetailID, OrderQty,
UnitPrice, LineTotal
from Purchasing.PurchaseOrderDetail
where ProductID = 394 -- 19 rows - Index seek + key lookup
-- where ProductID = 492 -- 63 rows - Index scan
-- where ProductID = 319 -- 130 rows - Index scan
create procedure dbo.GetOrdersForSingleProduct
@ProductID int
as
begin
select PurchaseOrderID, PurchaseOrderDetailID,
OrderQty, UnitPrice, LineTotal
from Purchasing.PurchaseOrderDetail
where ProductID = @ProductID
-- option (recompile)
end
go
exec dbo.GetOrdersForSingleProduct @ProductID = 394 with recompile
exec dbo.GetOrdersForSingleProduct @ProductID = 492 with recompile
exec dbo.GetOrdersForSingleProduct @ProductID = 319 with recompile
This is standard (and expected) SQL Server behavior. However, if you take the query and define it as a parameterized stored procedure, the behavior changes. If you try to execute the stored procedure for each of the three key product ID values, you'll get an Index Scan every time, which otherwise was NOT the optimal plan when you ran the queries independently (i.e., not as stored procedures).
This is the fundamental issue of parameter sniffing. SQL Server “sniffs out” an execution plan upon the first execution and uses that plan. It doesn't generate a plan dynamically every time. EXCEPT if you use a statement level WITH (RECOMPILE) in the query (or by using a WITH RECOMPILE when you execute the procedure). This generates a new execution plan dynamically every time (and usually gives you the desired plan). However, it means that SQL Server needs to rebuild the execution plan every time, which might be highly undesirable if the database must rebuild the plan many times during the day (or hour, or even minute). The developers and DBAs will need to determine the proverbial “pain point” level.
12: Stored Procedures that Try to Query for One Parameter Value or ALL
Listing 15 demonstrates a problem that isn't unlike the issue in the previous tip.
Listing 15: Stored Procedures that try to run for one value or ALL
create procedure GetOrdersForVendor
@VendorID int
as
select PurchaseOrderID, OrderDate, ShipMethodID, TotalDue
FROM Purchasing.PurchaseOrderHeader
where @VendorID is null or VendorID = @VendorID
--We get an index scan for both???? even for one vendor???
exec GetOrdersForVendor @VendorID = 1492
exec GetOrdersForVendor @VendorID = null
alter procedure GetOrdersForVendor
@VendorID int
as
select PurchaseOrderID, OrderDate, ShipMethodID, TotalDue FROM
TempPurchaseOrderHeader
WHERE VendorID = @VendorID or @VendorID is null
option (recompile) -- statement level recompile
go
Suppose you have a stored procedure that returns orders for a vendor but sometimes you want to pass a NULL value and retrieve all the orders?
You might use something like this in the query:
where @VendorID is null or VendorID = @VendorID
I've known developers who thought that SQL Server would be smart enough to execute an Index Seek if they passed in a value into the stored procedure, and only used an Index Scan if they passed in a NULL. I've also known a few developers who believed that if they changed the logic in the WHERE (re-arranged the operators), SQL Server would generate the best execution plan, given the condition and the least amount of runtime evaluation that SQL Server could do. Unfortunately, both of those beliefs are incorrect. SQL Server generates one execution plan to cover both conditions and does so conservatively. As was the case in the prior tip, you'd need to use a statement-level RECOMPILE.
13: The Difference between WHERE and HAVING
I'll close with a fairly easy one. You use WHERE when operating on single rows from the tables/views you're querying, and you use HAVING in conjunction with aggregations. Listing 16 shows a query that retrieves all vendor orders in 2006 and only shows the vendor if the sum total of orders in 2006 exceeds $200,000 in sales.
Listing 16: The difference between WHERE and HAVING
SELECT VendorID, SUM(TotalDue) as AnnualTotal
FROM Purchasing.PurchaseOrderHeader
-- WHERE works on individual rows from the table(s)
WHERE OrderDate BETWEEN '1-1-2006' AND '12-31-2006'
GROUP BY VendorID
-- HAVING works on the aggregated amounts
HAVING SUM(TotalDue) > 200000
You use the WHERE clause to filter out the individual orders that weren't in 2006, and the HAVING statement to filter on just those vendors who aggregate total sales (given the parameters of the query) exceeded $200.000. Note that you can't use the AnnualTotal alias in the HAVING because you need to repeat the expression.
You use HAVING in conjunction with aggregations, which leads to a small and subtle point: Might the following query work?
SELECT SUM(TotalDue) as AnnualTotal
FROM Purchasing.PurchaseOrderHeader
WHERE OrderDate BETWEEN '1-1-2006' AND '1-2-2006'
HAVING SUM(TotalDue) > 4000
Because the query doesn't have a GROUP BY, some might be tempted to say that the query won't work. Actually, it does. In this instance, the query either returns one row (the grand total of sales for the first two days of 2006), or an empty result set (if the grand total in the first two days didn't exceed 4,000). Those who say that HAVING works when you have a GROUP BY aren't 100% correct. It's true that most aggregation queries use a GROUP BY, but it's not always true. A HAVING still works as long as there's an aggregation.
Final Thoughts:
I hope you're able to gain some benefit from the T-SQL tips here. As I said at the beginning, experienced developers are probably aware of much of the content I've written here. But I hope that new- and intermediate-level developers will pick up some worthwhile knowledge. Whether you're a .NET developer, an ETL developer, an SSRS developer, or a data warehouse specialist, everyone has to write T-SQL code at some point. This is truly one of the “ties that bind us.”
Some Anniversaries
My world changed forever in May 1987. I started my career 28 years ago, at the same time I watched my younger brother graduate from basic training in the U.S. Marine Corps. The events of that month shaped our lives forever. EDS paid me about a thousand dollars to write a database application. At night, I read every word in trade publications like Dr. Dobbs Journal, PC Tech Journal, and I witnessed the power of the Compaq DeskPro 386 and software tools like dBase and Microsoft/Turbo C. As someone whose initial field of study was liberal arts, I knew the power of words and ideas and the value of practical education. So much of what I've done since then, and especially over the last decade as a SQL Server MVP, as an instructor and a technical mentor, is rooted in those early days when I saw the explosion of the PC industry and how much I wanted to be a part of it. And like the good marine my brother has always been, I've always been a fanatic about it.
Additionally, in May 2005, I started putting together ideas for what became my first article in CODE Magazine. The great writer and DDJ columnist Al Stevens had always been a huge inspiration for me. Fast forward 11 years and nearly 50 Baker's Dozen articles later, I've been able to carve out the path I envisioned, thanks to CODE Magazine and (in particular) Rod Paddock for supporting the method to my madness.
I thought it would be the coolest thing in the universe to be part of both the software and the magazine industries all those years ago. I hadn't yet experienced the waywardness of business and the cynicism it sometimes breeds. But that's what good memory is for, to remind myself of all the things that helped shape me. I try to remember where I came from, and always keep my eyes on where I want to go.
