


Why do we write software? Occasionally, I think that we developers just write software for the pleasure of putting a few cool technologies through their paces. Most likely, instead, we write software to address specific requests from customers or in an attempt to provide a service for others to consume, whether companies, organizations, or individuals. The trend today is that consumer applications - namely, those applications we write trying to fill or find a market - are, for the most part, either mobile apps or cloud-based multi-tenant services. Enterprise, line-of-business applications are, instead, those applications we write because a customer makes an explicit request and allocates a budget on it. When it comes to this, the bottom line is that we are called to write software that implements real business processes and manipulates entities living in some real business domain. In a nutshell, our software is called to mirror a piece of real life - the notorious real world.
In general, software exists (and thrives) because of its inherent capability of reproducing the reality of some business experience while speeding up existing processes, enabling new and more effective processes, and allowing in-depth analysis of data and results. That kind of software is invaluable, as long as it meets true requirements and streamlines real processes.
The point is of this article, however, is not commenting on a list of known facts and how technology is sold to help. The purpose is recalling the core reasons why customers ask developers to write software and matching them to what we actually do nowadays. It's more like a “duty vs. action” kind of thing.
Useful software is invaluable, as long as it meets true requirements and helps streamlining real processes.
Modeling vs. Mirroring the Business Domain
The segment of the real-world that we target with any software is generically referred to as the “business domain.” It is commonly abstracted to a collection of entities, relationships, and processes. Entities are things like the “order,” the “product,” and the “invoice,” but also the “work-item,” the “tennis match,” the “score,” the “booking,” and so forth. Each entity is characterized by attributes and behavior. Relationships are connections required between two or more entities. Processes are workflows that transform entities performing even fairly sophisticated operations. Let's stop here for a moment and think over the term “required.”
It's usually easy to figure out the entities that populate a specific business domain - they're the things that domain experts, stakeholders, and end users mention in the interviews we do to gather requirements. It's much less easy to figure out the relationships between those entities. Many of the relationships are referred to during interviews, but some may be omitted, stay latent, or are missed. This creates a sort of a gray area for the development team to step in and make assumptions. Making assumptions is always a good thing as long as any assumption is then validated against the domain experts and then removed or reworked as appropriate.
If I look back at consolidated habits of planning and building software, I can see that too often developers end up designing an ideal model of the domain rather than mirroring what they can actually see. Reasons for this are probably varied. One reason is certainly that an “ideal” model is easier to build and explain. I like to call this the “God-mode anti-pattern.” Developers feel the power of shaping the reality they can see and build a virtual reality as they would like to have it. The result is that software built based on these ideal rules sometimes doesn't match real functional requirements or it doesn't match some key nonfunctional requirements, such as performance or scalability.
The literature of software practices is full of patterns, methodologies, and recommendations about these issues. YAGNI is one of these and stands for You Aren't Going to Need It. The purpose of YAGNI is so you just don't code things you don't strictly need. However, I think that YAGNI and other valuable recommendations operate at the wrong abstraction level. YAGNI is a vector for developers building the software. YAGNI is pure tautology at the architecture level: you don't want to have more than you should. The goal of software architecture is mirroring real life and streamlining processes rather than modeling it the best you can.
I find that “mirroring” is a strong term that puts a lot more emphasis on the role of domain analysis. First, we understand the real world and make sense of how it works; next, we reason about the best way to model software entities to reproduce that. The top-level architecture must mirror the real world; the actual implementation models the real-world with the inevitable approximation that software may face.
Why Is Behavior So Crucial?
At first, insisting on mirroring versus modeling may just seem an architect's hobbyhorse. If you think and dig further, though, you'll see that the whole point of what I called “mirroring” here is just better analysis of the domain, better understanding of the internal mechanics of the processes to be implemented. When a customer describes a process, she uses her own (business) lingo. Such lingo includes terms that match domain entities, verbs that indicate the actions performed on entities and adverbs that change or simplify the meaning of the action verb. You may learn for example that a customer is registered, an account is approved, an order is canceled, or maybe that a sporting match is started. Admittedly, in this context, anything like customers, accounts, orders, and sports matches are all entities. Each entity is coupled with a set of verbs that indicate the behavior of the entity. Furthermore, a business process orchestrates known entities and their known behavior in more sophisticated workflows. Figure 1 shows the diagram of a typical process for a sport match.
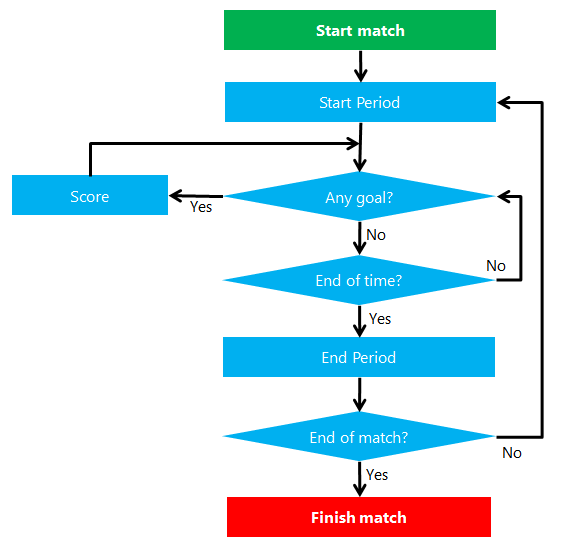
A quick look at the flowchart of Figure 1 reveals that the depicted run-match process involves an entity that in business lingo is called “the match.” The match can start, finish, have a goal scored, and start and end intermediate periods. This is the business language that you should focus on if you really want to mirror the real-world. Too often, instead, as architects we focus on how we would actually code the process over a familiar technology. When we think of a match, we also think of persistence and how we would like to save the content of the match entity.
Most of today's architects grew up with the relational model in mind. It's not our fault; that's what we studied at college and used for at least two decades. There's nothing wrong with the relational model and, more importantly, with modeling done following the practices learned out of relational theory. Relational theory is still great at analysis, but you should just take it one level of abstraction higher and focus on behavior and data rather than just data.
Let's say that your customer is a sport organization interested in automating refereeing practices and scorecards. You're called to plan a system that can be used by referees or their assistants during the performance of the match. The sport here isn't relevant; but it that helps if you can think of anything like basketball, football, or maybe water polo.
Guided by instinct, many of us today would approach the building of such a system starting from a Match entity with properties like:
- Team names
- Team goals
- Current period
- State of the match
In plain C# code we wouldn't go too far from the source below:
public class Match
{
public string Team1 { get; set; }
public string Team2 { get; set; }
public bool IsBallInPlay { get; set; }
public int TotalGoals1 { get; set; }
public int TotalGoals2 { get; set; }
public int MatchState { get; set; }
public int CurrentPeriod { get; set; }
public TimeSpan Matchtime { get; set; }
}
Mapped to the above Match class, the entity Match is easy to persist and manage. And, more importantly, it has all the properties you need to implement the process in Figure 1. In a realistic scenario, you'll make the source code prettier with constructors, enumerated types, and some basic validation just to ensure that team names are not null and possibly that period and goal properties hold sensible values. You don't want any instance of the Match class to hold a score of -1 to 5 million.
Imagine now that at some point, the customer calls back complaining of some misbehavior in the system. The customer will use his own lingo to explain what's wrong. He may say something like “when a goal is scored, the clock should be stopped until the referee puts the ball in play again.” In your source code, you have nothing like “scoring a goal” or “stopping the clock.” You can surely understand these concepts and manage them in code, but it requires a translation from the customer's lingo to the developer's lingo. At the end of the day, instead of mirroring the real-world, you just create a mostly database-oriented model for it.
A key paradigm shift for software architects and developers is thinking more of the entities and how they behave and are used in the business domain rather than how they should be persisted.
A key paradigm shift for software architects and developers is thinking more of the entities and how they behave and are used in the business domain rather than how they should be persisted. It goes without saying that entities have a state that must be persisted at some point. However, the model for the business doesn't have to be the model for persistence. Put another way, you should target your analysis at discovering and understanding behavior. In doing so, it may be that in simple, or just lucky, scenarios there's nearly no behavior to take into account. In this case, domain and persistence model nearly coincide. Domain and persistence model are distinct things even though we didn't notice or mind the difference for years. As I see things, it's the role of software that's changing. Every aspect of real life is subjected to software these days. Subsequently, software must be designed to mirror real life rather than just model it. To get back to the flowchart in Figure 1, Listing 1 shows a better way to rewrite the Match class so that it more effectively mirrors the Match entity as it exists in the business domain.
Listing 1: A behavior-oriented implementation of the Match entity
public class Match
{
public Match(string team1, string team2) { ... }
// Properties
public string Team1 { get; private set; }
public string Team2 { get; private set; }
public bool IsBallInPlay { get; private set; }
public Score CurrentScore { get; private set; }
public int MatchState { get; private set; }
public int CurrentPeriod { get; private set; }
public TimeSpan Matchtime { get; private set; }
// Methods
public void Start() { ... }
public void Finish() { ... }
public void StartPeriod() { ... }
public void EndPeriod() { ... }
public void GoalForTeam1() { ... }
public void GoalForTeam2() { ... }
}
There are a few significant changes in the code of Listing 1. First and foremost, all properties now have private setters. This means that the state of the class changes only through methods, including the constructor(s). No longer can you set the number of goals for a given team. You achieve the same now only by calling the appropriate method. A method like GoalForTeam1 doesn't do fancy or overly complex things. All it does is use a step 1 increment on a privately managed integer property.
Wrapping this piece of logic in a method named GoalForTeam1 brings three benefits. First, it keeps naming conventions in software aligned with the language of the business. In sports, a team scores a goal even if in software it actually means incrementing an integer property. Second, you drastically reduce the risk that inconsistent code might be written by someone else on the team. Third, when the customer calls you back to report a bug, the language the customer uses to describe the issue is far closer to the naming conventions used in code, which greatly simplifies the mental effort of getting to the core of the problem, if any. The second point is worth some more thought.
A software model that mirrors a segment of real business is commonly referred to as a “domain model.” Taken literally, the expression “domain model” indicates a generic model that effectively represents the mechanics of a business domain. More often than not, though, the term “domain model” recalls object-oriented models sometimes crafted by developers, sometimes automatically inferred from the DDL of an existing database. I'm using here the expression “domain model” to mean a model that effectively represents the mechanics of a business domain.
When you write such a domain model, you're actually writing the core logic of the domain that's invariant to use cases. Without emphasis, you're writing the API of that business domain. When you write an API, you should limit access to users of the API to only access code actions that are consistent with the business. If you have an entity that represents a sport match with a score, nothing in the API should enable a coding path that results in an instance of the Match class with negative numbers in the score. Having, say, a public setter for an integer property that holds the score just makes this unwanted scenario dramatically closer. By focusing on behavior, you implement and expose actions and let actions manipulate properties internally. There's still no guarantee that the implementation will be correct, but at least the public interface of the domain is consistent with the business and the implementation is the (important) detail it should be.
In modern software, you can't go anywhere without a serious analysis of the business domain.
Tools for Effective Domain Analysis
In modern software, you can't do anything without serious analysis of the business domain. You need to know which tools are available to perform domain analysis. Domain analysis usually starts with the gathering of requirements through interviews. This is the first step; what happens next largely depends on the experience and expertise of the software architect. There's a phase in which the architect attempts to make sense of collected requirements. The output of this phase is a set of possibly high-level specifications for developers.
An international standard exists to help with the processing of requirements. The ISO/IEC 25010 standard defines a set of quality characteristics that software products are expected to have. The standard identifies eight families of quality characteristics: functionality, reliability, usability, efficiency, maintainability, compatibility, security, and portability. A simple but effective practice to process functional requirements is grouping them by categories. What you can do is create, say, an Excel document with one tab for each of the eight categories of the standard. Next, you go through the list of raw requirements and map each to an existing category.
When done, you read it back and stop on all those tabs that are either empty or with just one or two requirements. If no requirements are found, say, under portability, you should stop and wonder if you know enough about the attribute and if you asked enough questions to customers for issues to emerge. As things are, when you put nearly no requirements under portability, it could likely be that the application has no portability requirements. However, it could also mean that users forgot to mention that or took it for granted or just used misleading words. Making assumptions, or deferring the time of clarification, may have an important cost. To take the example to its logical end, portability relates to the software ability of being used from within different environments. Assuming that after the first pass, no portability requirements are in place, the team may be led to make decisions that make it impossible to support, say, iOS or Android clients at a later time.
Acknowledgment of requirements has the purpose of determining the functions to be implemented in the final system. The next step is transforming basic knowledge into a more technical set of specifications. Here's where a methodology called Domain-Driven Design (DDD) can prove quite helpful. For some reason, DDD is too often associated with the idea of coding based on a rich and object-oriented domain model. “Rich domain model” is a common expression to indicate a graph of classes written according to a bunch of guidelines, such as factories instead of constructors, no private setters, no dependency on databases, 100% consistency, value types, aggregate model, and more. The adjective “rich” typically indicates that entity classes are not limited to properties but also expose public methods. The nature of such public methods, though, is not always clear and ranges from rather useless “SetXXX” methods to replace public setters to more domain-specific methods, such as in Listing 1.
DDD is primarily about domain analysis and aims at revealing the top-level architecture of the system being designed. The power of DDD is not in using objects to wrap SQL command and access to databases. The power of DDD is in the tools it provides to explore the domain and find out the ideal top-level architecture. When approaching the design of an enterprise system, it may not be a good idea to look for a single architecture that addresses any concerns and functional aspects. Understanding the boundaries of logical subsystems is key to a successful architecture as much as it is vital to understand the mechanics of the system by simply learning the native lingo.
In DDD, there are two distinct parts: analytical and strategic. The analytical part is what provides concrete tools and guidelines for effective domain analysis. The strategic part recommends a supporting architecture for the various subsystems identified during the analysis. If you don't split the domain into subdomains and go with the recommended supporting architecture, then you end up with the canonical big picture of DDD: just implement a rich object-oriented domain model and you're done. Except that years of DDD experience in the trenches painfully suggests the picture of Figure 2.
Conducting a domain analysis using DDD requires two patterns: ubiquitous language and bounded contexts. The ubiquitous language (UL) is a plain glossary of terms that form the unique vocabulary shared by all parties involved with the project and thoroughly used in all forms of spoken and written communication (in an ideal world). Bounded contexts (BC) are areas of the domain that are treated differently from the point of view of design and implementation.
The main goal of UL is mitigating the risks of misunderstandings and wrong assumptions that may happen when people with different skills and expertise work together. People may speak different languages and translation between respective jargons is the norm. It should be the exception, instead. To a software expert, using the natural language of the business may sometimes be too restrictive. It means, for example, that you “cancel the order” rather than “delete the record.” In the business, in fact, orders are canceled and there's no notion of records. Even though when an “order is canceled,” probably a record is deleted. However, using the proper business wording may also cause you to reflect on whether it's really necessary to delete a record. Further thinking may also cause you to wonder whether in the business, the canceled order is wiped out or merely tracked as deleted. More often than not, a canceled order is still tracked and never removed from the system. By not focusing on the UL, you might have missed a good point and have one more changing requirement to face. And sometimes, requirements change simply because we get them wrong the first time.
The UL contains nothing that's created artificially; it emerges out of interviews and goes through several iterations before it starts making sense and looking unambiguous and fluent to both software and domain experts. All involved in the UL must faithfully reflect the business and the names used to describe entities and processes. The development team has two main responsibilities with respect to the UL. First, the team must evolve the UL as new insights are gained about the system. Second, the team must keep the UL and the domain model in sync.
In the beginning, you typically assume one indivisible business domain and start processing requirements to build the UL. As you proceed, you learn more and more how the organization works, which processes are performed, how data is used and how things are referred to. Sometimes, the same term has different meanings when used by different people, especially in a large organization. When this happens, you've probably crossed the invisible boundaries of a subdomain. As a result, the business domain you assumed indivisible needs splitting. Figure 3 shows the relationships between domains, subdomains, and BCs.
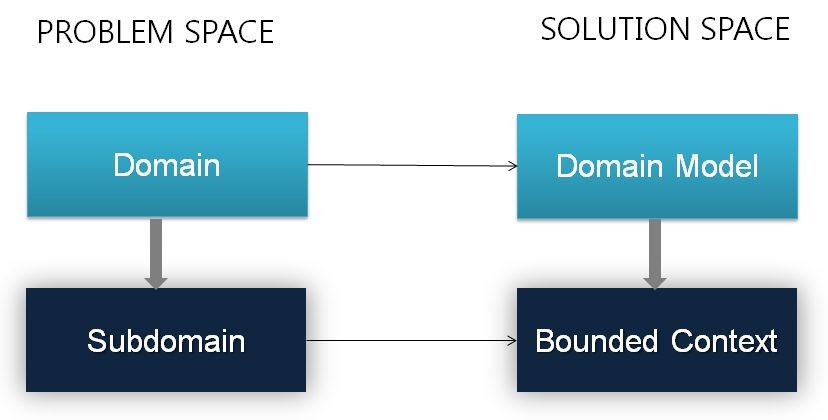
In the problem space, you have a domain and can sometimes break it up into multiple subdomains. In the space of solutions, the domain model instead addresses the concerns of a unique domain and BCs are domain models for smaller pieces of the original domain. A BC is an area of your final application that has its own UL, its own independent implementation (e.g., Domain Model) as well as a well-known interface to talk to other BCs. In DDD, the diagram where all BCs are laid out with connections to one another is called a context map.
For years, we faced a mass of forgiving and passive users humbly accepting any user interface enforcements. This is no longer the case today or in the foreseeable future.
UX is Way More Complicated than User Interface
So far in this article, I tried to emphasize the importance of domain analysis. As I see things, this is the #1 challenge today for software development. For decades, we wrote software caring about the back-end much more than the front-end. Today is different. Today, it's quite hard to sell a product, whether a website, an internal application, or a mobile app, that isn't carefully designed both in terms of look-and-feel and, more than ever, usability.
The user interface is the means through which users accomplish their tasks and interact with the system we create. Any user interface that allows users to accomplish a given task is good; but not all interfaces are good in the same way. Let's admit it: As developers, for years we faced a mass of forgiving and passive users humbly accepting any user interface enforcements. This is no longer the case today or in the foreseeable future. One of the painful aspects of modern software is that the development team has a hard time catching up with constantly changing requirements. In some very specific scenarios (e.g., startups), requirements may really be changing frequently even though probably not on a daily basis. In some other scenarios, the extreme complexity of the business rules may lead to misunderstanding and wrong assumptions even when the UL pattern is diligently applied. (The UL pattern is not a lifesaver; it simply helps making your life simpler.) Finally, in yet another bunch of situations, requirements change because of the interaction offered to users, or the way in which information is aggregated and presented is misleading, less than optimal, or doesn't let users work with the expected fluidity and speed.
Today, the agile approach is the mainstream methodology to develop software. The term “agile” was introduced in contraposition to a way too rigid methodology - the waterfall - that was in use earlier. Inspired by practices in use in civil engineering and architecture, the waterfall methodology introduced barriers between the various phases of development. In waterfall, you don't start on phase N+1 until phase N is fully completed - or sort of. The agile philosophy pushed the opposite approach; proceed through small steps and check every time you complete a step whether all is right. The agile approach worked beautifully for years and still works. But it doesn't always help with the same effectiveness today.
An approach that I like to call UX-first suggests that you use a slightly different methodology that is neither fully waterfall nor fully agile. What about something along the lines of “responsive (or just responsible) waterfall?” At the end of the day, the UX-first approach isn't rocket science and can be summarized by in Figure 4.
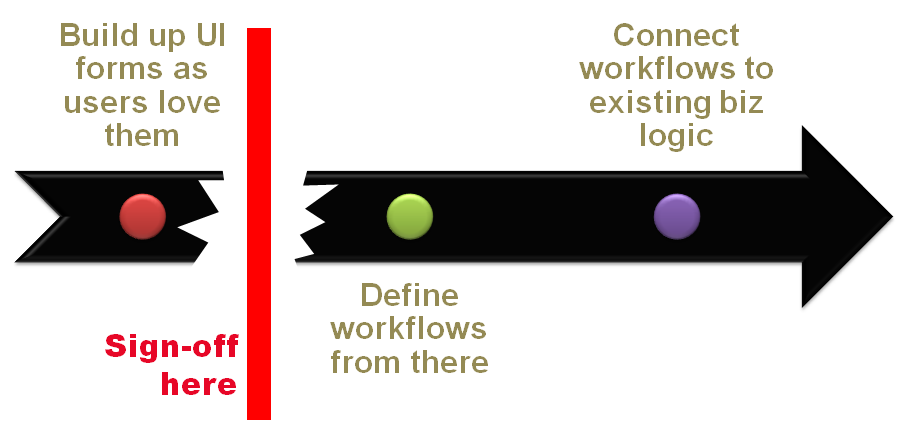
UX-first is articulated in three steps. First, you build user interface forms because users love them. You take a task-first approach and focus on the ideal interface that users need for the task they need to perform. You do this UI analysis for each view the system will have. You start from the user interface to finalize the ideal user experience, avoiding usability bottlenecks. It's an iterative process that requires nothing more than sketches and wireframes of the views. You don't do any work on the domain model at this time other than perhaps outlining the UL and BCs. You proceed with the back-end only when you've got approval for the forms. You then proceed with workflows and the application layer and then connect the application layer to pieces of the domain model and domain services. Finally, you turn to the infrastructure and databases and documents and cache and whatever else you may need. It's a top-down approach, which is nothing new in the history of software. Especially in the beginning of software, top-down was fairly common and later on, it was pushed aside to favor a more solid back-end centered on a powerful database and a good set of stored procedures. Both data containers and presentation have been neglected since. Now things seem to go differently. The UX-first approach has a key benefit: You start focusing on actual code only when the artifacts to produce are well tested and signed off. You know exactly what your back-end has to produce and what it receives. For each view, you know exactly what comes in and out. At least, users can't easily catch you on saying “hey, this is not what we wanted.”
An effective implementation of the UX-first approach may require an additional professional role: the UX architect. The UX architect interviews customers in order to collect usability requirements and plan the ideal UX for the presentation layer. The four pillars of a user experience are information architecture, interaction, visual design, and usability reviews.
The order is not coincidental. The first point is to look at the hierarchy of the information and determine the ideal way for the information to be displayed through the application. Next comes the way in which users interact with that information and the graphical tools you provide for that to happen. All this work, however, is nothing without usability reviews. A high rate of UX satisfaction is achieved only when the interface and interaction form a smooth mechanism so that neither has usability bottlenecks or introduces roadblocks in the process. For a UX architect, talking to users is fundamental, but it's even more important observing users in action, listening to their feedback and, if possible, even filming them in action.
A usability review is an iterative process that starts with interviews and mockups and continues even once the application or a prototype has been put in production.
The focus of a UX architect isn't merely the user interface, although UI is certainly important. UX is about catching design and process bottlenecks as soon as possible. The focus of the UX architect is the data flow, not the graphics. This is also the key argument to set UX and UI apart. The software architect and UX architect are two distinct roles. But the same individual can take both. Or, more likely situation is that the role of the UX architect is played by the leader of the designer team, whether an internal group of people or an external company.
Aspects of Development
A saying in software development that has been made quite popular by Twitter and Facebook reminds us that if you're concerned about the costs of good code, wait and see how much bad code costs. When bad code is mentioned, many just think of software full of bugs. That's bad, but not bad enough. Software packed with bad coding practices is even worse. A plain bug affects functionality and once it's been tracked down and fixed, it's no longer a problem. Bad coding practices, instead, are not easily detectable as the code works. However, coding practices in the long run affect large shares of the application, preventing it from scaling or performing as expected or preventing the application from being properly extended. There are three aspects of software development that revolve around the global theme of software quality: testability, readability, and use of patterns.
For years, .NET developers only relied on the debugging tools available in Visual Studio to ensure the quality of their code. In the past decade, however, development teams became more attentive to automated tests as a better way to find out quickly what could be wrong in code and whether given features were still working after some changes. Bruce Eckel brilliantly summarized testing in the popular sentence “If it ain't tested, it's broken.” Frankly, I've always found such a statement a bit provoking in the mere wording. I recognize, though, that it serves well the purpose of calling out people's attention on the ability to determine automatically and repeatedly whether some code works as expected. Testable code is loosely coupled code that uses SOLID principles extensively and avoids common pitfalls of object-orientation.
Testability is often mistaken for just having tests, but testability is much more important than the actual step of testing. Testability is an attribute of software that represents a (great) statement about its quality. Testing is merely a process aimed at verifying whether the code meets expectations. The ROI of testability is all in the improved quality of the code you get. Writing classes with the goal of making them testable causes you to favor simplicity and proceeding one small step a time. In this way, you quickly catch when a given class becomes bloated and where monolithic code should be broken up into dependencies. You can even get testability without writing a single test for specific classes. However, writing tests and classes together help make sense of the ROI. The final goal, at any rate, is having good code, not good tests.
The final goal of writing software is having good code, not good tests.
Most of the attention today is captured by unit tests. Unit tests are written by developers for themselves for two main reasons: to serve as a regression tool and to improve confidence about the quality of the software. Unit tests are focused on a single unit of code, mostly a class. Leaving an entire class uncovered by tests is potentially dangerous, as bugs may slip in and pass acceptance unnoticed. However, if you look at the system as a whole, missing integration tests is much more critical than missing unit tests. Integration tests involve different parts of the system and test how they can work together in a scenario that's really close to reality. Often, integration tests cross layers and tiers of the whole system and involve databases and services. For this reason, integration tests take much longer than unit tests to set up and run. As a result, in order to save time during the always hectic end of the project, sometimes teams take the shortcut of the notorious “Big Bang” pattern instead of going through canonical integration tests.
The Big Bang pattern is quite a simple thing: You configure the system in a production-ready environment and push a typical workload on it to see how it goes. That's it. You do it once and all components are tested together only the first time. If all goes well, chances are that the system really works. If something goes wrong, you may be left clueless investigating the issue and the time you saved because of the Big Bang pattern may be spent investigating compatibility problems armed only with empirical data.
Test-driven design (TDD) is a methodology for software development that puts a lot of emphasis on unit tests. TDD is one of those things that divide the public in two opposite and strongly opinionated camps. TDD brings a few facts to the table and you should look at these facts before you join either camp. Tests are not the primary goal of TDD. The ultimate goal of tests in TDD, in fact, is not high code-coverage but getting to better design. Instead, continuous refactoring is the foundation of TDD much more than tests.
When it comes to better software design, readability is another fundamental milestone to reach. If any code that gets checked into the system is working as expected and won't be touched anymore, the quality of that code is not so relevant. In any other case, other developers, and often the same developer who originally wrote it, may find it hard to understand any code not written with some good practices in mind. No matter that this has been said for decades, readability is often neglected. Maybe readability is not entirely neglected, but it's neglected just enough to require some extra waste of time (and money) when existing code needs be reworked or new people need to be trained on the internals of the system being built.
Readability is an attribute of code that developers should learn right at the beginning of their careers and develop and improve over time. Readability shouldn't be postponed as it too often happens that you need to rethink something just when you don't have enough time for it.
As a seasoned developer, you know very well that you're never going to have enough time for anything but just writing the code. That's why good developers manage to write readable code “by default.” Readability is also an argument strictly related to domain analysis and the UL. Building a glossary of business terms is a complete waste of time if those terms aren't used in spoken and written communication between involved parties and aren't reflected in the source code. When you write a domain entity or a domain service as a C# class, all methods and properties should strictly reflect names and actions existing in the glossary. If at some point the glossary changes, the source code should be updated too. Synchronization between the code and UL should be invariant - otherwise you lose most of the benefits of both domain analysis and readability.
It's a known fact that bad coding practices represent a cost; but what are good coding practices all about? Use of design patterns is somehow related to good coding. A design pattern is a well-established solution applicable to a family of concrete implementation problems. Being a core solution, a design pattern might need adaptation to a specific context. Design patterns originate from the direct experience of developers and represent a valid solution to a class of problems. Beyond this point, there's no real value in pursuing design patterns. Like the Force, design patterns might be with you, but they won't provide you with any special extra power. Design patterns must be known but applied regardless. Knowledge of design patterns emerges as you code and guides you to finding an appropriate solution to a common problem.
Approaching development as if it's only going to be good if you apply tons of patterns is reductive both for the role of patterns and for the entire solution. The wrong way to deal with patterns is cherry-picking patterns from a list and finding a match to the problem. A better way consists in generalizing the problem until a natural match with something you know emerges. In math, a common way to solve theoretical problems consists of mapping the problem to another problem for which a solution is known. It's the same with design patterns.
Like the Force, design patterns might be with you, but they won't provide you with any special extra power.
The Bottom Line
Why do we write software? There's an answer to this question in the same ISO/IEC 25010 standard paper I mentioned earlier. A software system exists to solve a problem and achieve its mission in full respect of the stakeholders' concerns. Furthermore, a software system lives in a context and the context drives developmental decisions.
The major challenge I personally see in software development today is understanding and managing the “context” of the system. This context is a segment of the real world full of real business processes and naming conventions. Altogether, the context expresses mechanics that must be understood. Understanding the mechanics is commonly referred to as domain expertise.
For many years, we just played a catch-me-if-you-can game with technology. That was enough for a long time. Today, it's no longer enough. As obvious as it may sound, it's more critical than ever to call things with their true names and bring software back to where it belongs: mirroring instead of modeling the real world.
