


Regardless of your .NET language of choice, managing data is a vital skill for most applications.
Developers frequently must work with data at different levels, with different tools, and in different forms. This article is the first in a two-part series on some of the more common data challenges that developers face. In Part 1 of this article, I’ll cover some capabilities in ADO.NET 2.0, ASP.NET 2.0, and T-SQL 2005. Part 2 will feature some additional T-SQL 2005 coverage, as well as ways to use .NET 2.0 generics.
Beginning with the End in Mind: An Entire Potpourri of Data Handling Tips
Recently I presented some CodeCamp sessions on different topics dealing with data. Some covered the new T-SQL enhancements of interest to developers, some covered new techniques in ADO.NET 2.0, and some even got into handling data in Web applications. One attendee approached me afterwards and told me he was pleasantly surprised that someone who’s listed as an MVP for C# would talk so much about data and what could be done today. I smiled and told him that my next article for CoDe Magazine was an article on data-handling techniques, and that the experiences of the day (including some questions I received from this gentleman) helped to further shape this article.
While T-SQL doesn’t lend itself to the level of program modularity that C# or Visual Basic developers enjoy, the APPLY operator improves the integration of reusable table-valued UDFs with the different stored procedures that call them.
Regardless of whether you work with C# or Visual Basic .NET or any other language, what you’re really working with throughout the day is DATA-whether you’re retrieving it, summarizing it, presenting it, etc. As an application developer your chief task is handling data. Don’t ever let anyone tell you differently.
Many developers don’t just handle data in one tool. You may work with the database, with a report writer, with third-party utilities, with the presentation layer, or other areas altogether. You have many tools and many choices! Someone could write a book on different ways to handle data in the .NET world.
So in this article I’ll present the first-ever Baker’s Dozen doubleheader. Game one will cover the following:
- Five different areas of ADO.NET (typed datasets, data math, data relations, filtering data, and summing data).
- Four different tips for handling data in an ASP.NET 2.0 application.
- Four different tips for retrieving data using the new capabilities in T-SQL 2005.
The nightcap of this twin-bill will cover practical uses of .NET generics for handling data along with coverage of the new ObjectDataSource, and some additional techniques for retrieving data in T-SQL 2005. So…let’s play ball!
Tip 1: Typed Datasets 101
A typed dataset is a strongly-typed container for collections of business entity data. It inherits from the System.Data.DataSet class. However, unlike the standard dataset that features late-binding and weak typing, typed datasets provide strongly-typed access to data. Typed datasets expose table, column, and relation objects as named properties, rather than generic collection elements.
Typed datasets give you the ability to use IntelliSense for statement completion, and type checking at compile time. In the context of reporting, typed datasets aid in data-driven report design and provide an excellent form of self-documentation of stored procedure result sets. Coding against typed datasets (as I’ll show you in different examples) adds a level of efficiency and structure.
You can create a typed dataset in one of two ways. If you have an existing schema (or can build one easily), you can use an approach similar to the following:
DataSet DsReturn =
this.RunStoredProc("GetAgingReceivables");
// Define a DataSet name and table names
// (we could use Table Mappings as well)
DsReturn.DataSetName = "dsAgingReport";
DsReturn.Tables[0].TableName = "dtAgingDetails";
DsReturn.Tables[1].TableName = "dtAgingSummary";
DsReturn.Tables[2].TableName = "dtAgingBrackets";
DsReturn.Tables[3].TableName = "dtClients";
// Write out the schema
DsReturn.WriteXml(@"c:\MyXml\DsAgingReport.xsd",
XmlWriteMode.WriteSchema);
After running this test code (which you could make into a schema generator utility), you can take the final schema and add it to Visual Studio 2005 as a typed dataset. In Solution Explorer, right-click, chose “Add” then “Existing Item…” and then navigate to the folder that contains the XSD file. Once Visual Studio builds the typed dataset, you have different options for viewing/editing it. If you want to use the standard XML schema editor, just right-click on the dataset in Solution Explorer and select “Open With…”.
If you’re building a typed dataset definition from scratch, where no schema yet exists, you can create the typed dataset manually using the DataSet Designer. However, if you find that you’re doing this more often than building a typed dataset from an existing schema, you may want to re-think your approach.
OK, so you’ve created a typed dataset. So what? Well, let’s take a look at what a typed dataset gives you.
First, a typed dataset gives you strong typing and statement completion in IntelliSense (Figure 1). Compare that to an untyped example, where you either must refer to columns by column number, or type it in as an expression. In addition, the example in Figure 1 does not need to cast any column to the corresponding data type. In my opinion, eliminating the need to cast a column object to the necessary type is one of the most attractive features of typed datasets.
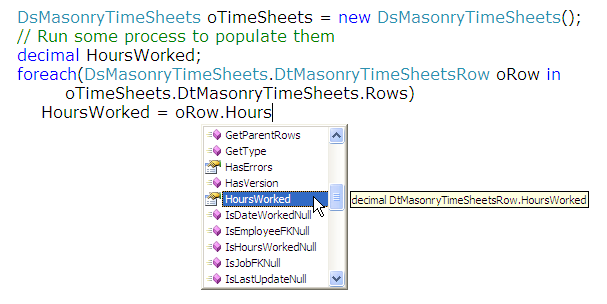
Second, you can easily define default column values in the Dataset Designer by setting the defaultvalue property.
Third, if you’ve defined a primary key for any strongly-typed DataTable in the Dataset Designer, the class exposes a Find method associated with the column name. As a result, you can perform a FIND against a table with a primary key of OrderID by using FindByOrderID. If the primary key is a concatenation of two columns (CustomerID and OrderID), the developer would use the pre-generated method FindByCustomerIDOrderID. I find this much more efficient than any of the alternatives.
Fourth, if a typed dataset contains table relations, the XML schema definition tool adds methods to the typed dataset class for traversing hierarchical data. For example, a developer can write parent/child code for the tables DtOrderHeader and DtOrderDetail by using GetDtOrderDetailRows that the .NET schema tool automatically generates. (I’ll cover this in Tip 3).
Fifth, you can more easily work with null values using typed datasets. Each strongly-typed DataRow contains a method to check if a column value is null, and to set a column value to null.
// Set value to NULL
oRow.SetHoursWorkedNull();
// Check for null value
if(oRow.IsHoursWorkedNull()==true)
Sixth, some critics of typed datasets in Visual Studio .NET 2003 will acknowledge that the new partial class capability in Visual Studio 2005 makes it easier to extend typed datasets. While partial classes are a great new feature, one could subclass a typed dataset even in VS2003 to add validation code or other capabilities. In the January/February 2006 issue of CoDe Magazine, I presented some code that subclassed a typed dataset to add XML import functionality.
Typed datasets aren’t perfect. They carry overhead. While certain specific aspects of typed datasets are faster than untyped datasets, instantiating a complex typed dataset can be costly. An application that frequently creates an instance of the same typed dataset may spend a measurable percentage of time on the creation process. Uri N. has developed a proxy class for typed datasets so that the actual creation only needs to occur once. You can find his .NET class on the CodeProject at http://www.codeproject.com/csharp/TypedDSProxy.asp.
Some developers complain about the default naming conventions in the typed dataset class for items like the DataTable/DataRow objects and methods/events. The generated names may not be consistent with the preferred naming conventions on your development projects. Fortunately, developers can use typed dataset annotations to solve some of the common naming issues, which allow developers to modify the names of elements in the typed dataset without modifying the actual schema.
Annotations also allow you to specify a nullValue annotation to instruct the typed dataset class how to react when a column is DbNull. You can optionally tell the typed dataset to return an empty string or a default replacement value. Shawn Wildermuth demonstrates typed dataset annotations in this excellent online article at http://www.ondotnet.com/pub/a/dotnet/2003/03/31/typeddatasetannotations.html. (If you are not familiar with Shawn, he has written numerous materials on ADO.NET and is an outstanding writer.)
Tip 2: Date Arithmetic
The .NET Framework classes offer many different capabilities for date arithmetic that you can use to calculate the difference between two dates, determine future dates, and more. Let’s take a look at some of them.
// Create two dates, Nov 1 2005 and Oct 1, 2005
DateTime dAgingDate = new DateTime(2005,11,1);
DateTime dInvDate = new DateTime(2005, 10, 1);
TimeSpan ts = dAgingDate.Subtract(dInvoiceDate);
int nDiffDays = ts.Days;
// Determine future dates
DateTime dNextDay = dtInvoiceDate.AddDays(1);
DateTime dNextMonth = dtInvoiceDate.AddMonths(1);
DateTime dNextYear = dtInvoiceDate.AddYears(1);
// Determine # of days in October 2002
int nDaysInMonth = DateTime.DaysInMonth(2002, 10);
// Is the year a leap year?
if(DateTime.IsLeapYear(2006)==true)
// Determine if a string represents a valid date
public bool IsValidDate(string cText)
{
bool lIsGoodDate = true;
// Convert in a try/catch
try
{
DateTime dt = Convert.ToDateTime(cText);
}
catch (Exception)
{
lIsGoodDate = false;
}
return lIsGoodDate;
}
// Gets today (time will be midnight)
DateTime dToday = DateTime.Today;
// Get the current date/time
DateTime dNow = DateTime.Now;
Look on the Web to find many other date math capabilities. I found an excellent one recently on the CodeProject: codeproject.com/csharp/CSDateTimeLibrary.asp.
Tip 3: Data Relations
As stated in Tip 1, you can more easily manage and work with related DataTables if you define typed datasets. By defining relationships in the DataSet Designer, Visual Studio automatically generates the relation and provides a default method for retrieving child rows in a parent/child relationship. In the following example, a strongly-typed Order Header row object exposes a method called GetdtOrderDtlRows.
dsOrders odsOrders = new dsOrders();
// Run some process to fill the DataSet
foreach(dsOrders.dtOrderHdrRow oHdrRow in
odsOrders.dtOrderHdr.Rows)
foreach(dsOrders.dtOrderDtlRow oDtlRow in
oHdrRow.GetdtOrderDtlRows())
nProductPK = oDetailRow.ProductPK;
Tip 4: Filtering Data
ADO.NET provides two different ways to filter data: Use a DataView and a RowFilter, or use a DataTable.Select**().** New .NET developers sometimes ask which technique to use. As you’re about to see, it depends on the situation.
ADO.NET provides two different ways to filter data: Use a DataView and a RowFilter, or use a DataTable.Select(). New .NET developers sometimes ask which technique to use. In general, use a DataView for binding filtered results, and use an array of DataRows for scanning through the filtered results to perform processing, calculations, etc.
First, a DataView is simply a view of a DataTable, with a particular filter and sort order. Look at these examples of different filter and sort capabilities.
string cFilter; // Examples of RowFilter
cFilter = " Amount > 1000 ";
cFilter = "FirstName = 'Ken' OR EmpFlag = true";
cFilter = " City LIKE '%whatever%' ";
cFilter = "EmployeeID IN (12,144,54)";
// This assumes a Parent Relation
cFilter = "Parent(RelName) = 'National'";
string cSort = "Location ASC, Salary DESC";
DataView Dv = new DataView(MyTable, cFilter,
cSort, DataViewRowState.CurrentRows);
In the code snippet above, I used one of the DataView overloads to specify the filter and sort all at once. Sometimes developers will use the overload to merely supply the DataTable and then set the RowFilter and Sort properties in subsequent lines of code. This is actually less efficient and causes additional (and unnecessary) processing. It is better to make one call.
Also notice one of the examples uses a parent relation. If you have established a DataRelation and wish to filter on related parent (or child) rows, you can specify the Parent (or Child) keyword, along with the name of the DataRelation.
Finally, you can create several DataViews on a DataTable, each with their own filter and sort.
By contrast, the results of a DataTable.Select() are a collection of DataRow objects. You can use the same filter and sort syntax that you used for a DataView.
DataRow[] aRows = MyTable.Select(cFilter,cSort);
So when should you use a DataView, and when should you not? The answer is fairly simple. Use a DataView when you want to bind the results of a filter. The DataView implements IEnumerable, ICollection, and IList, making it ideal for databinding. You cannot bind a collection of DataRows that DataTable.Select() returns.
By contrast, however, you can do something with a collection of DataRows that you cannot do with a DataView-you can cast each of the rows as one of the strongly-typed objects from a typed dataset.
dsOrders odsOrder = new dsOrders();
// Run some process to populate orders
// Now perform a select and filter
DataRow[] aRows =
odsOrder.dtOrderHdr.Select(cFilter, cOrder);
// We can cast the collection of rows
// as the strongly-typed rows from our typed DS
foreach (dsOrders.dtOrderHdrRow oRow in aRows) {
cOrderNumber = oHeaderRow.OrderNumber;
So you generally want to use DataViews for binding filtered data, and an array of rows for instances where you need to scan through the rows to perform calculations or other processing.
Occasionally, you’ll encounter a situation where you have to copy a DataView back to a DataTable. You may need to copy a DataView to XML, or you may need to bind the results of a DataView to a .NET library or product that does not recognize DataViews (such as Crystal Reports). Visual Studio .NET 2003 does not provide any built-in capabilities to convert a DataView to a DataTable; fortunately, you can build a small but useful generic function to do the job.
public DataTable ViewToTable(DataView dv)
{
// Create a new table structure from the table
// object of the view, then loop through the view
// and import the rows into the new table
DataTable DtReturn = dv.Table.Clone();
foreach (DataRowView drv in dv)
DtReturn.ImportRow(drv.Row);
// Note that we have to use ImportRow
// There's no such thing as Row.Copy
return DtReturn;
}
You could modify this code rather easily to create a DataTable from an array of DataRows.
Last, but absolutely not least-Visual Studio 2005 developers can benefit from a new built-in ADO.NET function called ToTable() that converts DataViews to DataTables.
DataTable dtFromView = dv.ToTable();
ToTable also has another capability that will be music to the ears of developers who need the ability to filter on distinct values. Visual Studio 2003 developers commonly asked whether ADO.NET had an equivalent of SQL’s SELECT DISTINCT. As Visual Studio 2003 did not natively provide this functionality, developers had to either do without the capability, or they had to write custom code to accomplish the task.
ToTable contains an overload that allows developers to specify a list of columns in a similar manner that one would use in a SELECT DISTINCT statement.
bool lDistinct = true;
DataTable dtFromView =
dv.ToTable(lDistinct, "Column1", "Column2");
// You can even create a unique list from the
// DefaultViewof a DataTable
DataTable dtUnique =
dtMyTable.DefaultView.ToTable(true,
"Column1", "Column2");
Tip 5: DataSet Calculations
Developers can implement dataset calculations at two levels. On a row-by-row basis you can define a calculated DataColumn. For an entire DataTable (or a collection of rows) you can compute a SUM or COUNT.
Remember that you must also set the HtmlEncode property to false for any GridView columns that utilize DataFormatString. This is because of new security functionality in ASP.NET 2.0 to prevent cross-site posting.
You can create a calculated column as follows:
string cExpr = "HourlyRate * Hours";
Dt.Columns.Add("Pay", typeof(Decimal), cExpr);
If you’re using typed datasets, you can define a calculated column by setting the Expression property in the Dataset Designer.
You can perform a calculation on all rows of a DataTable by using the DataTable.Compute() method. Note that Compute returns an object that you can cast to the appropriate type.
string cExpr = " SUM(Hours)";
string cCond = " OTFlag = true";
decimal nTotHrs =
(decimal)Dt.Compute(cExpr,cCond);
Finally, you can automatically calculate aggregate amounts in a parent-child relationship. Suppose you have a DataTable of clients, a DataTable of orders, and a parent-child relationship based on the client ID. You could store a calculated column in dtClients to reflect the sum of orders for each client by using the expression SUM(Child.OrderAmount) in the parent table. If you are utilizing typed datasets, you can specify that expression directly in the Visual Studio 2005 DataSet Designer.
Tip 6: An Overview of the ASP.NET 2.0 GridView
Most browser-based database applications will need to make use of the functionality that the new GridView control (formerly the DataGrid control) offers in ASP.NET 2.0. Developers who come from the Windows Forms environment to Web Forms will discover that the GridView control differs greatly across the two platforms. The next four tips will cover some of the more common functionality.
Figure 2 shows a basic ASP.NET GridView. The example retrieves data from the Northwind database, binds the GridView to the dataset results, defines columns and alignments and formats, and displays any row with Freight greater than $100.00 in yellow. You can implement this in five steps:
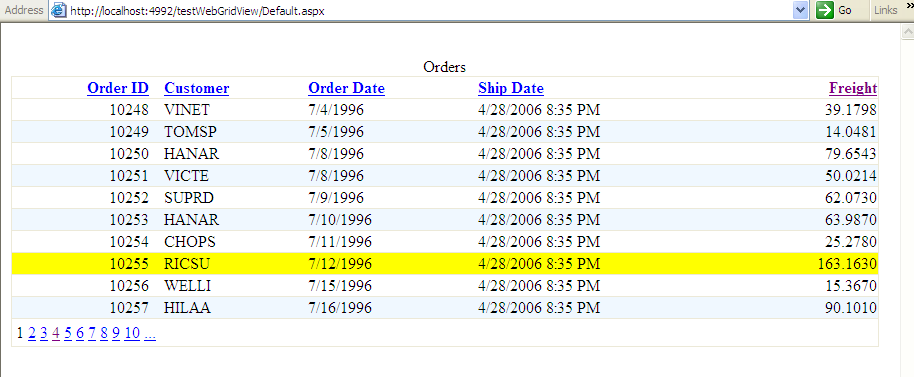
You first recreate this by dropping the GridView control from the Web Forms toolbox onto a Web Forms page. After the Web Forms Designer creates an instance of the GridView control on the page, right-click on the GridView to load the property page. Change the name (ID) to grdOrders, set AllowPaging to true, AllowSorting to true, and AutoGenerateColumns to false. If you want the alternating background color effect, expand the AlternatingRowStyle property and set the BackColor to the alternating color you wish.
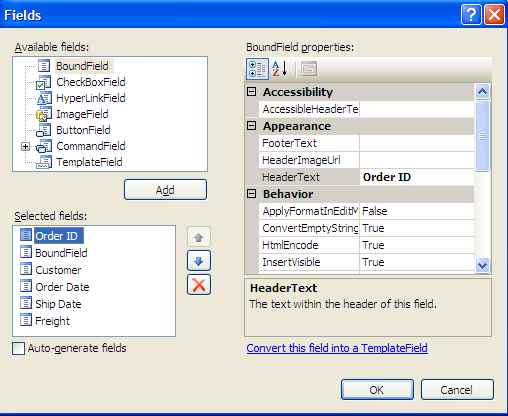
Second, since you set the AutoGenerateColumns property to false, you need to define the columns manually. In the property sheet, if you select the Columns collection, Visual Studio 2005 will display a dialog that allows you to define columns (Figure 3). This dialog allows you to add bound fields by highlighting BoundField, clicking Add, and setting the DataField property on the right. Also, for any columns the user may wish to sort, you can also define the SortExpression property.
Note that in the Gridview display in Figure 2, some columns are right-aligned. Also notice that the two date columns (Order Date and Shipped Date) are formatted differently: one shows the date only, and one shows the date as well as the time, in HH:MM format.
Once you add individual bound columns in Figure 3, you can set the HorizontalAlign property under the HeaderStyle and ItemStyle group properties. You can set the date formats in the DataFormatString property: the values are {0:d} for date only, and {0:g} for date/time that displays everything but seconds. Remember that you must also set the HtmlEncode property to false for any columns that utilize DataFormatString. This is because of new security functionality in ASP.NET 2.0 to prevent cross-site posting.
Now that you’ve designed the GridView, you can write the code to bind the Gridview.
DataSet dsData = this.GetData();
// Run whatever process you want, for the query
// SELECT OrderID, CustomerID, OrderDate,
// ShippedDate, Freight FROM Orders ORDER BY
// OrderID
this.grdOrders.DataSource = dsData.Tables[0];
this.grdOrders.DataBind();
Finally, you can implement the function to highlight rows with Freight greater than $100. You do so by tapping into the GridView’s RowCreated event, which allows you to cast the current GridView row as a DataRowView object. You can evaluate the value of freight, and set the background color.
protected void grdOrders_RowCreated(object sender,
GridViewRowEventArgs e)
{
if (e.Row.DataItem != null) {
DataRowView drv =
(DataRowView)e.Row.DataItem;
decimal nFreight =
Convert.ToDecimal(drv["Freight"]);
if (nFreight> 100)
e.Row.BackColor =
System.Drawing.Color.Yellow;
}
}
Note that in a production environment you’d want to abstract out the logic for freight in your business layer. You’d also want to use a CSS definition instead of hard-coding the alternate color.
Tip 7: Making Selections from the GridView
Beginners sometimes ask how to define a link for a particular row in a GridView, perhaps to launch another Web page with more details on the row (Figure 4).

You can accomplish this in multiple ways. One way involves three simple steps. First, you need to open the column designer for the GridView and add a ButtonField (as opposed to a BoundField) from the list of available fields. Keep the ButtonType as Link, set the Text to Open (or whatever text you wish), and set the CommandName to Select.
In the third step (yes, the third, you did not miss the second step) you’ll tap into the GridView’s SelectedIndexChanged event to determine the row associated with the Open link that the user clicks. You might wonder “how” specifically to determine the row. The GridView contains a design-time property called SelectedDataKey that you can set to a unique identifier (or identifiers). In this situation, the second step will set this to OrderID. Finally, the third step will read the value of SelectedDataKey in the SelectedIndexChanged event.
protected void grdOrders_SelectedIndexChanged
(object sender, EventArgs e)
{
int nOrderID =
(int)this.grdOrders.SelectedDataKey.Values
["OrderID"];
// Now we can load another page with the ID
}
A final note on this: if you want to display an icon instead of a text link (maybe an “open” or “edit” icon), repeat all the above steps, change the ButtonType from Link to Image, and set the ImageURL to the actual image.
In Tip 6 I showed you how to color a row based on a condition. You may also face a situation where you want to display an icon in the GridView based on a condition.
To accomplish this, you need to define a special TemplateField column in the GridView. To do so, open the actual HTML source for the Web page and add the following code as the first (or last) column in the GridView.
<asp:TemplateField >
<ItemTemplate>
<img src= '<%# GetPic(Container.DataItem) %>'/>
</ItemTemplate>
<ItemStyle Width="3px" />
<HeaderStyle Width="3px" />
</asp:TemplateField>
Your custom code will be the function GetPic, which will receive the current GridView row as a parameter and return the name of the icon image to use: either the desired icon if the row matches the condition or a blank .gif if the row does not match the condition. Note that you cannot return an empty string: the GridView will simply place the nasty little red ‘X’ in the cell.
protected string GetPic(object dataitem)
{
string cIcon = "";
// evaluate the row from the GridView
bool lFlag =
Convert.ToBoolean(DataBinder.Eval
(dataitem, "ShowPictureFlag"));
if (lFlag == true)
cIcon = "SpecialPic.gif";
else
cIcon = "Blank.gif";
return cIcon;
}
Tip 8: Sorting Using the ASP.NET 2.0 GridView
In Tip 6 you built a basic GridView, set the AllowSorting and AllowPaging properties to true, and defined the SortExpression for each databound column. When you run that GridView in a Web browser you will see each column heading as a link that you can click to sort. You’ll also see links at the bottom of the grid to navigate to another page, if the bound dataset contains more rows than can fit on a single page.
Unfortunately, when you click either of those links, things don’t go as planned and you’ll actually receive nasty runtime error messages (Figure 4 and Figure 5**).**


So what’s wrong? As the messages indicate, you need to add some code to the GridView’s Sorting event and PageIndexChanging event for the operations to work correctly. Because these events fire as part of a postback, you need to take a step back and look at your approach.
In both the Sorting event and PageIndexChanging event, essentially you’ll need to access the GridView’s datasource and modify the sort expression of the datasource’s DefaultView. However, as you look back to the basic code in Tip 6, you aren’t storing the datasource in any way that you can access it. So before you implement any custom sorting and paging code, you need to address this.
You may choose to store the GridView’s DataSource in the ViewState as a property, like so.
DataTable dtOrders
{
get { return (DataTable)ViewState["dtOrders"]; }
set { ViewState["dtOrders"] = value; }
}
However, if you have a fairly large result set, this means the page must carry the entire list of orders in the ViewState. (To see this, set up a Web page, store the result set in the ViewState, run the page, and click “View….Source”. It might be more than you bargained for!) In addition, not all datatypes will serialize. For instance, you cannot store a DataRow object in this manner.
Alternatively you could store the datasource in a session variable, at the time the databinding is performed. So to revisit the code snippet from Tip 6:
DataSet dsData = this.GetData();
// Run whatever process you want, for the query
// SELECT OrderID, CustomerID, OrderDate,
// ShippedDate, Freight FROM Orders ORDER BY
// OrderID
this.grdOrders.DataSource = dsData.Tables[0];
// Store the datatable as a Session Variable
Session["dtOrders"] = dsData.Tables[0];
this.grdOrders.DataBind();
Now that you’re storing the datasource in the session, you can access the Session variable in the Sorting event and modify the SortExpression of the datasource’s DefaultView accordingly. Note that the SortExpression comes from the SortExpression property that you initially defined for the column.
protected void grdOrders_Sorting
(object sender, GridViewSortEventArgs e)
{
DataTable dtOrders =
(DataTable)Session["dtOrders"];
if (dtOrders != null) {
dtOrders.DefaultView.Sort = e.SortExpression
this.grdOrders.DataSource =
dtOrders.DefaultView;
Session["dtOrders"] = dtOrders;
this.grdOrders.DataBind();
}
}
Note that the above technique isn’t new or earth-shattering-you can find the same or similar approach on dozens of different ASP.NET forums.
Tip 9: Paging Using the ASP.NET 2.0 GridView
Now that you’ve tackled the sorting, you can address the paging. When the user clicks on one of the page links at the bottom of the page, a postback occurs and the PageIndexChanging event fires. You can determine the page the user selected from the GridViewPageEventArgs parameter, and use that value to set the GridView’s PageIndex. Note that to retain any sorting that might have been done, you need to access the DefaultView property of the GridView’s DataSource.
protected void grdOrders_PageIndexChanging
(object sender, GridViewPageEventArgs e)
{
// must set new PageIndex and rebind
this.grdOrders.PageIndex = e.NewPageIndex;
this.grdOrders.DataSource =
((DataTable)Session["dtOrders"]).DefaultView;
this.grdOrders.DataBind();
}
Before you move on, a word about Session Variables. Some people use them, some don’t: some love them and swear by them, some argue against them for scalability issues, and some are in between.
Session variables are very easy, almost too easy to utilize. So of course, anything that is very easy to use can often be abused. The October 2003 issue of Visual Studio Magazine has an outstanding article by Leonard Lobel on managing session state. The article covers seven server-side state management techniques, including storing session information in SQL Server. If you want to learn more about this topic, you will greatly benefit from what Mr. Lobel has to say.
Tip 10: SQL Server 2005 TOP N
Anyone who has written SQL TOP N queries where N is a variable knows that in SQL 2000, you had to either use dynamic SQL, or set the ROWCOUNT (and reset it afterwards). Why? Because SQL 2000 treated the N as a literal.
-- Dynamic SQL to implement variable TOP N
DECLARE @nTop int
SET @nTop = 5
DECLARE @cSQL nvarchar(100)
SET @cSQL = N'SELECT TOP ' +
CAST(@nTop AS VARCHAR(4)) +
' * FROM ORDERS ORDER BY Freight DESC'
EXECUTE SP_EXECUTESQL @cSQL
-- Setting ROWCOUNT to implement variable TOP N
DECLARE @nTop int
SET @nTop = 5
SET ROWCOUNT @nTop
-- Get the top 5 with the most Freight
SELECT * FROM Orders ORDER BY Freight DESC
-- Set back to 0
SET ROWCOUNT 0
Fortunately, Microsoft enhanced the implementation of TOP N in SQL Server 2005 so that developers can treat the N as a variable, directly in the SQL statement.
-- New implementation in SQL Server 2005
DECLARE @nTop int
SET @nTop = 5
SELECT TOP (@nTop) * FROM Orders
ORDER BY Freight DESC
-- The N can even be the result
-- of another function
SELECT TOP( SELECT COUNT(*) FROM SHIPPERS)
* FROM ORDERS
Developers can also utilize variable TOP N in UPDATE, INSERT, and DELETE statements!
DECLARE @nTop int
SET @nTop = 100
UPDATE TOP (@nTOP) Orders
SET Freight = Freight * 1.1
Tip 11: SQL Server 2005 PIVOT
In the March/April 2005 issue of CoDe Magazine, I devoted a Baker’s Dozen article to productivity tips for T-SQL 2000. One of the tips presented code to build a result set for an accounting aging report, by using a CASE statement to place overdue invoice rows into aging bracket columns based on date range.
In essence, the example turned, or pivoted, rows into columns based on some criteria-in this instance, date range. While using CASE statements remains a valid approach, SQL Server 2005 provides new PIVOT capabilities to simplify the process.
Listing 1 demonstrates a full example of the new PIVOT capability. In the example, you calculate the number of overdue days between each invoice and an “as-of” date, and place the invoice amount into the corresponding bracket with the PIVOT statement.
Tip 12: Recursive Queries and Common Table Expressions in SQL Server 2005
One of the more interesting new capabilities in SQL Server 2005 is the ability to build recursive queries. As the name implies, recursive queries actually query against their own results as part of the entire process. For example, you might query against hierarchical data to extract a variable number of parent-child relationships.
Let me demonstrate recursive queries and common table expressions (CTEs) with a simple example. Listing 2 shows two simple examples of querying up and down a hierarchy. The process involves two parts. The main or “anchor” query pulls the initial result set into a CTE. The CTE in many ways resembles a derived table. The second part recursively queries the CTE for either parents or children, depending on how you write the query. By default, SQL Server 2005 allows 100 levels of recursion, though you can configure this threshold.
Tip 13: APPLY the Results of a Table-Valued UDF in SQL Server 2005
I have to admit, this is one of my favorite new features in T-SQL 2005. The name perfectly describes what it does-it allows a developer to directly APPLY the results of a table-valued UDF in a SQL SELECT statement, without need for temporary tables.
While T-SQL doesn’t lend itself to the level of program modularity that C# or Visual Basic developers enjoy, the new APPLY operator improves the integration of reusable table-valued UDFs with the different stored procedures that call them.
Let’s consider the following table-valued UDF, which returns a table variable of the TOP N orders for a given customer, based on Order Amount.
CREATE FUNCTION [dbo].[GetTopNOrders]
(@CustomerID AS varchar(10), @nTOP AS INT)
RETURNS TABLE
AS
RETURN
SELECT TOP(@N) OH.OrderID, CustomerID, OrderDate,
(UnitPrice * Quantity) as Orderamount
FROM Orders OH
JOIN [dbo].[Order Details] OD
ON OH.OrderID = OD.OrderID
WHERE CustomerID = @CustomerID
ORDER BY ORDERAMOUNT DESC
GO
Now suppose you want to query against the entire customer database, and for each customer, run the UDF to return the TOP N orders. SQL Server 2005 allows you to APPLY the results of the UDF directly against a query into the customer file.
DECLARE @nTopCount int
SET @nTopCount = 5
SELECT TOPOrd.CustomerID, TOPOrd.OrderID,
TOPOrd.OrderDate, TOPOrd.OrderAmount
FROM Customers
CROSS APPLY
DBO.TopNOrders(Customers.CustomerID,
@nTopCount) AS TOPOrd
ORDER BY TOPOrd.CustomerID,TOPOrd.OrderAmount DESC
On the Menu Next
As stated at the beginning of the article, this is the first of a two-part series on data handling capabilities. In the next issue, part two will cover .NET generics as well as the new ObjectDataSource tool in ASP.NET, and some more examples in T-SQL 2005. Stay tuned!
Closing Thoughts
Have you ever submitted something (an article, a paper, some code, etc.) and thought of some good ideas after the fact? Well, I’m the king of thinking of things afterwards. Fortunately, that’s the type of thing that makes blogs valuable. Check my blog (www.TheBakersDozen.net) for follow-up tips and notes on Baker’s Dozen articles…and maybe a few additional treats!
Listing 1: Using PIVOT in T-SQL 2005 to turns rows into columns
-- First, create some test data.
DECLARE @tInv TABLE (CustomerID char(15), InvoiceNo Char(20),
InvoiceDate DateTime, InvoiceAmount decimal(14,2),
ReceivedAmount decimal(14,2))
INSERT INTO @tInv VALUES ('Cust 1','ABC','09-01-2005', 1000, 0)
INSERT INTO @tInv VALUES ('Cust 1', 'DEF','10-01-2005', 2000, 100)
INSERT INTO @tInv VALUES ('Cust 1', 'GHI','11-01-2005', 3000, 3000)
INSERT INTO @tInv VALUES ('Cust 1', 'JKL','12-01-2005', 4000, 175)
INSERT INTO @tInv VALUES ('Cust 1', 'MNO','12-18-2005', 4000, 175)
INSERT INTO @tInv VALUES ('Cust 2', 'PQR','05-01-2005', 500, 250)
INSERT INTO @tInv VALUES ('Cust 2', 'STU','08-01-2005', 12000, 0)
INSERT INTO @tInv VALUES ('Cust 2', 'WYX','10-01-2005', 7000, 70)
INSERT INTO @tInv VALUES ('Cust 2', 'YYZ','12-01-2005', 3200, 1750)
-- Second, every aging report has an "as of" date.
DECLARE @dAgingDate DATETIME
SET @dAgingDate = '12-15-2005'
-- Third, create a table of aging brackets and their ranges.
-- This demonstrates how you can have configurable date ranges
-- (i.e. 1-45 days, 46-90, etc.).
DECLARE @tAgingBrackets TABLE ( StartDay int, EndDay int,
BracketNum int, BracketLabel char(20))
INSERT INTO @tAgingBrackets VALUES (0, 30,1, '1-30 Days')
INSERT INTO @tAgingBrackets VALUES (31, 60,2, '31-60 Days')
INSERT INTO @tAgingBrackets VALUES (61, 90,3, '61-90 Days')
INSERT INTO @tAgingBrackets VALUES (91, 120,4, '91-120 Days')
INSERT INTO @tAgingBrackets VALUES (121,99999,5, '> 120 Days')
-- Note: The BracketNum column is especially critical.
-- When we match up each amount due with the date range,
-- we'll place the amount due into that bracket.
-- Fourth, create a table variable to hold the result set.
DECLARE @tAgingDetails TABLE
(CustomerID char(15), InvoiceNo char(20), InvoiceDate DateTime,
Bracket1 decimal(14,2), Bracket2 decimal(14,2),
Bracket3 decimal(14,2), Bracket4 decimal(14,2),
Bracket5 decimal(14,2))
-- Fifth, run the query.
-- In the WHERE clause, use DateParts to determine the # of days
-- between the invoice date and the "as of date", grab the
-- corresponding bracket number…and at the end, PIVOT on
-- the sum of AmountOwed for the BracketNumber being in
-- one of the five brackets.
INSERT INTO @tAgingDetails
SELECT * FROM
(SELECT CustomerID,InvoiceNo, Invoicedate,
InvoiceAmount - ReceivedAmount AS AmountOwed, BR.BracketNum
FROM @tInvoices TI, @tAgingBrackets BR
WHERE InvoiceAmount - ReceivedAmount <> 0 AND
DATEDIFF(dd,Invoicedate,@dAgingDate) BETWEEN
BR.StartDay AND BR.EndDay ) as Temp
PIVOT ( SUM(AmountOwed) FOR BracketNumber In
( [1],[2],[3],[4],[5])) As X
SELECT * FROM @tAgingBrackets
SELECT * FROM @tAgingDetails ORDER BY CustomerID, InvoiceNo
Listing 2: Recursive queries and common table expressions
-- Let's create some hierarchical data.
-- A hierarchy of music information
-- music genres, instruments, and musicians.
-- This could be a hierarchy of company product lines,
-- or a Bill of Material structure, or
-- even a company's organizational database.
-- Each row contains a PK and a reference to it's parent.
DECLARE @tMusicData TABLE (MainPK int, ParentPK int, Name char(50))
INSERT INTO @tMusicData VALUES (1,NULL,'Musicians')
INSERT INTO @tMusicData VALUES (2,1,'Jazz')
INSERT INTO @tMusicData VALUES (3,1, 'Rock')
INSERT INTO @tMusicData VALUES (4,1, 'Classical')
INSERT INTO @tMusicData VALUES (5,2,'Saxophone')
INSERT INTO @tMusicData VALUES (6,2,'Trumpet')
INSERT INTO @tMusicData VALUES (7,3,'Guitar')
INSERT INTO @tMusicData VALUES (8,4,'Piano')
INSERT INTO @tMusicData VALUES (9, 5,'Charlie Parker')
INSERT INTO @tMusicData VALUES (10,5,'John Coltrane')
INSERT INTO @tMusicData VALUES (11, 6,'Miles Davis')
INSERT INTO @tMusicData VALUES (12, 7,'Eddie Van Halen')
INSERT INTO @tMusicData VALUES (13, 6,'Franz Liszt')
DECLARE @cSearch char(50)
SET @cSearch = 'Charlie Parker'
-- You want to query on a single row, and get every parent
-- to which it belongs.
-- MusicTree is the CTE (similar to a derived table).
WITH MusicTree (ResultName, PKValue)
-- First, the main, or "anchor" query
AS (SELECT Name, ParentPK
FROM @tMusicData
WHERE Name = @cSearch -- This pulls out Charlie
UNION ALL
-- Second, the recursive query.
-- Note that it queries from the CTE, MusicTree, for
-- all the parents.
SELECT Name, parentPK
FROM @tMusicData
INNER JOIN MusicTree
ON PKValue = MainPK )
SELECT * FROM MusicTree
-- Results:
-- Charlie Parker
-- Saxophone
-- Jazz
-- Musicians
-- Let's try again, but this time, query for all the children.
SET @cSearch = 'Saxophone'
WITH MusicTree (ResultName, PKValue)
-- This time, we reverse the searches on MainPK and ParentPK.
AS (SELECT Name, MainPK
FROM @tMusicData
WHERE Name = @cSearch
UNION ALL
SELECT Name, MainPK
FROM @tMusicData
INNER JOIN MusicTree
ON PKValue = ParentPK)
-- Results:
-- Saxophone
-- Charlie Parker
-- John Coltrane
| Kevin S. Goff, a Microsoft MVP award recipient for 2006, is the founder and principal consultant of Common Ground Solutions, a consulting group that provides custom Web and desktop software solutions in .NET, VFP, SQL Server, and Crystal Reports. Kevin has been building software applications since 1988. He has received several awards from the U.S. Department of Agriculture for systems automation. He has also received special citations from Fortune 500 companies for solutions that yielded six-figure returns on investment. He has worked in such industries as insurance, accounting, public health, real estate, publishing, advertising, manufacturing, finance, consumer packaged goods, and trade promotion. In addition, Kevin provides many forms of custom training. |
