



Full title: Introducing .NET Core 2.1 Flagship Types: Span <T> and Memory <T>
.NET Core 2.1 is the latest release of the general-purpose development platform maintained by Microsoft and the .NET open source community. .NET Core is cross-platform and open source and consists of a .NET runtime, a set of reusable framework libraries, a set of SDK tools, and language compilers. Amongst many great features, this new release focuses on performance and brings us the System.Memory library that is available right out of the box and is also available as a standalone package on NuGet. Today, .NET developers write performance-critical server applications and scalable cloud-based services that are sensitive to memory consumption. To address these developer scenarios, .NET Core 2.1 introduces two flagship types into the ecosystem, namely Span<T> and Memory<T>, which are used to provide scalable APIs that don't allocate buffers and avoid unnecessary data copies.
Hot off the Press: Span<T>
Span<T> is a newly defined type in .NET within the System namespace that provides a safe and editable view into any arbitrary contiguous block of memory with no-copy semantics. You can use Span<T> as an abstraction to uniformly represent arrays, strings, memory allocated on the stack, and unmanaged memory. In some ways, it's analogous to C# arrays, but with the added ability to create a view of a portion of the array without allocating a new object on the heap or copying the data. This feature is called slicing and types with this feature are known as sliceable types. Span promises type and memory safety with checks to avoid out-of-bounds access, but that type of safety comes with certain usage restrictions enforced by the C# compiler and runtime. There's also a corresponding read-only flavor of Span<T>, unsurprisingly called ReadOnlySpan<T>. Span<T> and the other types discussed here are part of the .NET Core 2.1 release and require C# 7.2 language version to use.
Span promises type and memory safety.
Note: Going forward, I'll refer to Span<T> and ReadOnlySpan<T> as span, for brevity. When discussing something unique to ReadOnlySpan, or specific to the element type T, I'll make an explicit distinction.
Let's Take a Peek Inside Span
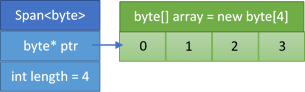
Roughly speaking, you can visualize span as a struct containing two fields: a pointer and a length (see Figure 1).

Now, suppose you have an array of bytes allocated somewhere on the heap. You can wrap a span around this byte array by passing it to the span constructor. Doing so assigns the pointer field to the memory address where the data starts (0th element of the array) and sets the length field to the number of consecutive accessible elements (in this case, it's the length of the array), as shown in Figure 2.
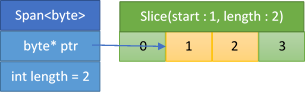
If you're only interested in a portion of the array, you can slice the span to get the desired view (Figure 3). Slicing is quite efficient because you don't need to allocate anything on the heap or copy any data when you're creating the new span.
Let's see how you can do all this in C# code. Span has a constructor that accepts an array and there's an extension method on the array itself to support fluent interface (method chaining). The implicit cast from array to span makes the conversions easy, especially when passing arrays to methods that accept spans.
byte[] array = new byte[4];
// using ctor: public Span(T[] array)
Span<byte> span = new Span<byte>(array);
// using AsSpan extension method
Span<byte> alt = array.AsSpan();
Span<byte> slice = alt.Slice(start:1, length:2);
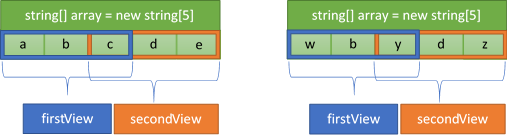
Keep in mind that spans are only a view into the underlying memory and aren't a way to instantiate a block of memory. Span<T> provides read-write access to the memory and ReadOnlySpan<T> provides read-only access. Therefore, creating multiple spans on the same array creates multiple views of the same memory. Like with arrays, you can use the Span<T> indexer to access or modify the underlying data directly. Furthermore, slices of spans allow you to safely access the data within the viewing window because spans enforce boundary checks. Let's try to modify the underlying array using the span indexer and see how the changes affect the elements of the array (observe the modifications to the array in Figure 4). Notice that span prohibits access to elements outside the window by throwing an IndexOutOfRangeException.
Span<T>provides read-write access to the memory andReadOnlySpan<T>provides read-only access.
string[] array = { "a", "b", "c", "d", "e" };
// Using Span ctor (array, start, length)
// Note that the spans overlap
var firstView = new Span<string>(array, 0, 3);
var secondView = new Span<string>(array, 2, 3);
firstView[0] = "w";
// array = { "w", "b", "c", "d", "e" }
firstView[2] = "x";
// array = { "w", "b", "x", "d", "e" }
secondView[0] = "y";
// array = { "w", "b", "y", "d", "e" }
// Throws IndexOutOfRangeException
firstView[4] = "a";
Span<T>, as conceptualized in Figure 1, is available as part of .NET Core 2.1 and can be used by any application that targets it, right out of the box. However, this variety of span (which I'll refer to as “built-in span”), is only available on applications running on .NET Core 2.1. This is because you require a newer version of the runtime and just-in-time compiler (JIT) that understands the semantics of span as described so far. The actual implementation of span contains a field of an internally defined type (instead of a raw pointer), which the runtime recognizes as a JIT intrinsic. When the JIT encounters this field at runtime, it generates assembly code as if span had contained a ref T field instead. That's how you get the pointer-like semantics and performance characteristics described earlier while sidestepping the memory safety concerns that are common when using pointers directly. Because span contains what can be thought of as a ref T field, it's considered to be a ref-like type. For my purposes here, that essentially means that the lifetime of span is constrained to the execution stack. I'll further explore the implications of ref-like types later in this article. Also, if you are curious, you can view the original specification document for span by following the links in the reference section (https://aka.ms/span-spec).
The lifetime of span is constrained to the execution stack.
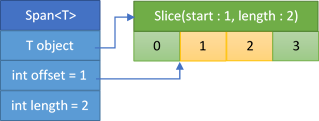
At this point, you might be wondering if you can still use span in applications that target older runtimes, like .NET Core 2.0, or ones running on .NET Framework for desktop. You certainly can, by using the portable implementation of span. Portable span doesn't require special handling from the JIT compiler or a runtime with special knowledge of the type. It essentially consists of three fields (instead of the two described previously): an object, an offset, and a length (see Figure 5).
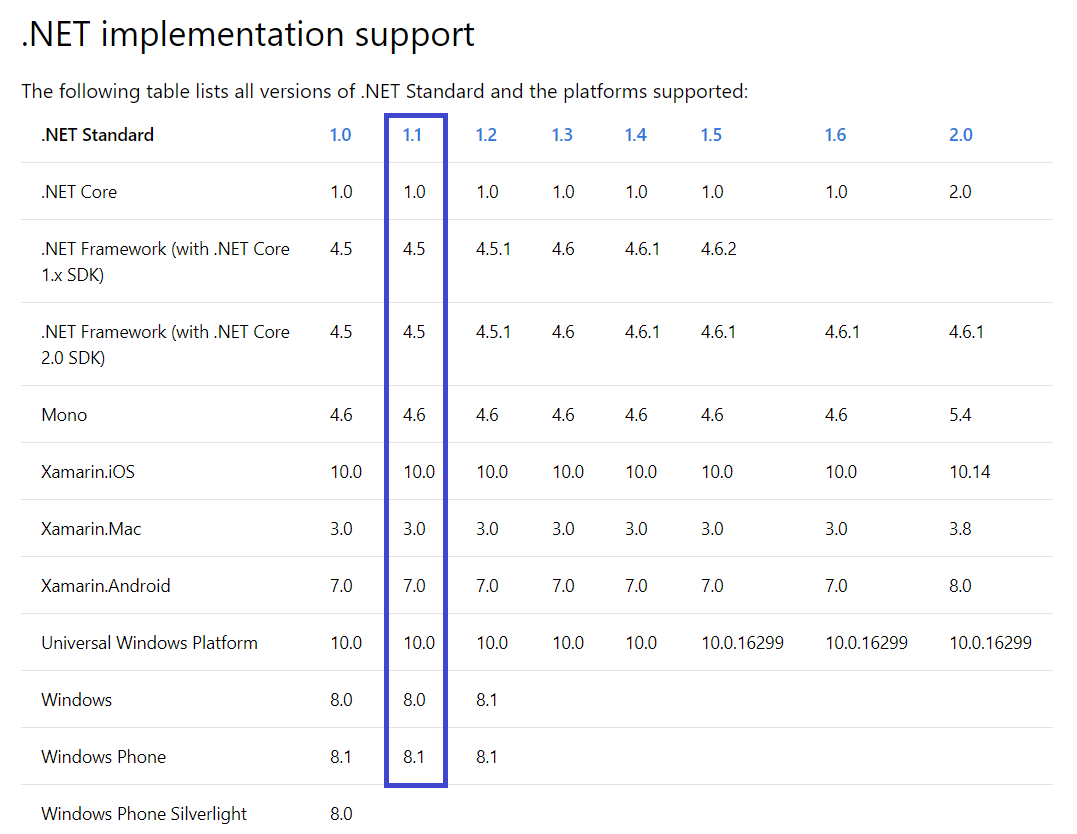
Due to the extra field and computation of the offset, some portable span APIs are slightly slower than the built-in span APIs that come with .NET Core 2.1. You can use portable span by adding a reference to the System.Memory NuGet package in your applications directly (https://aka.ms/nuget-package). The System.Memory package is compatible with any .NET platform that implements the .NET Standard 1.1 specification. Basically, you can reference the System.Memory package on all the active .NET platforms that developers target, as detailed in Figure 6.
If you're unfamiliar with .NET Standard, please refer to the references sidebar for more details.
Some Disassembly Required
Let's walk through some code samples that showcase usage and performance of Span APIs in more detail.
Sample 1: Return the Sum of the Elements of a Byte Array
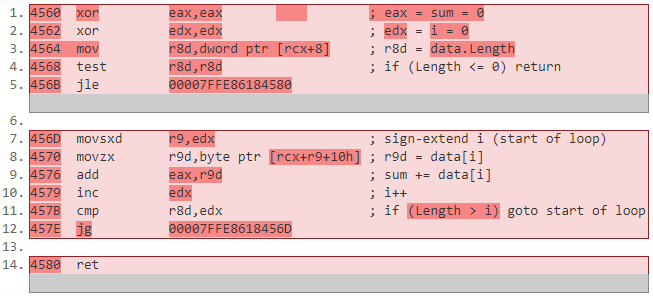
Consider the naive implementation of a method that accepts a byte array as a parameter and returns the sum of all the elements by looping through it.
public static int ArraySum(byte[] data)
{
int sum = 0;
for (int i = 0; i < data.Length; i++)
{
sum += data[i];
}
return sum;
}
What changes would you have to make to use span instead? Can you spot the difference?
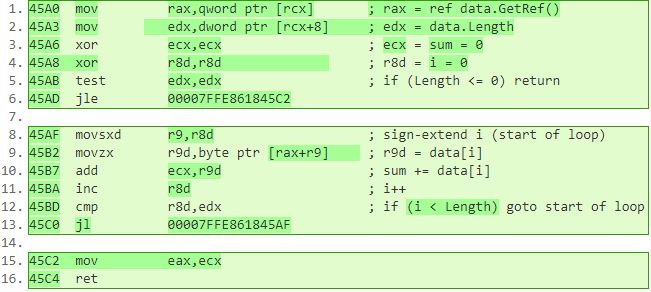
public static int SpanSum(Span<byte> data)
{
int sum = 0;
for (int i = 0; i < data.Length; i++)
{
sum += data[i];
}
return sum;
}
In case you missed it, the only change necessary is to the type of the input parameter (from byte[] to Span<byte>). Additionally, no code changes are needed at the call site in this case, because you can rely on the implicit cast from array to span.
static void Main(string[] args)
{
byte[] data = { 1, 2, 3, 4, 5, 6, 7 };
ArraySum(data); // returns 28
SpanSum(data); // returns 28
}
You might be asking, what's the catch? Is there a performance downside of using a span over an array? Let's answer this by comparing the disassembly of the two methods (the annotated machine instructions are shown in Figure 7 and Figure 8). If you focus on the instructions comprising the loop body (lines 7-12 versus 8-13), you'll notice that the disassembly is essentially identical (barring some registers being swapped). This was made possible by meticulous optimizations to the JIT.
As an aside, the other differences within the disassembly (outside the loop) are due to quirks in how the JIT assigns arguments and local variables to registers and should have a negligible effect on runtime performance. Let's confirm that by measuring the execution time of the two methods using the .NET benchmarking library – BenchmarkDotNet.
private byte[] data;
[GlobalSetup]
public void Setup()
{
data = new byte[10_000];
new Random(42).NextBytes(data);
}
[Benchmark(Baseline = true)]
public int ArraySum() => ArraySum(data);
[Benchmark]
public int SpanSum() => SpanSum(data);
As you can see from the output, there is practically no difference in performance between iterating spans and arrays. The small difference in the execution time is within the margin of error.
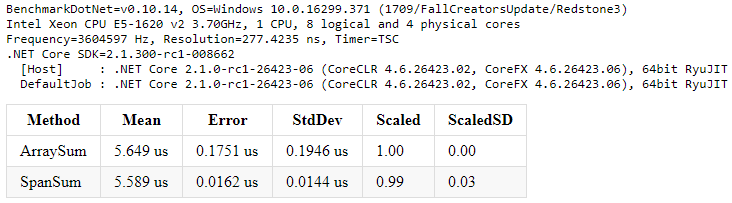
There's practically no difference in performance between iterating spans and arrays.
Sample 2: Return the Sum of a String Containing Comma Separated Integers
Let's parse some numbers by using the familiar and widely available string APIs. Notice that you pass in a substring to the int.Parse() method.
public static int StringParseSum(string data)
{
int sum = 0;
// allocates
string[] splitString = data.Split(',');
for (int i = 0; i < splitString.Length; i++)
{
sum += int.Parse(splitString[i]);
}
return sum;
}
Now, to re-write the method with span, you can leverage the span-based overload of int.Parse, which is one of the many overloads added in .NET Core 2.1. The distinction here is that you pass in a slice of a span to the parse method instead of a substring.
ReadOnlySpan<char> span = data;
int sum = 0;
while (true)
{
int index = span.IndexOf(',');
if (index == -1)
{
sum += int.Parse(span);
break;
}
sum += int.Parse(span.Slice(0, index));
span = span.Slice(index + 1); // skip ','
}
return sum;
Let's go one step further with the string parsing code to explore the benefits of using the new span-based Utf8Parser APIs (which is also within the System.Memory library accessible from the System.Buffers.Text namespace). Strings in C# are encoded as UTF-16 characters. By making a small compromise between execution-time performance and the number of bytes allocated, you can encode the incoming string data as UTF-8 characters by calling the GetBytes method on the System.Text.Encoding class.
// allocates
Span<byte> utf8 = Encoding.UTF8.GetBytes(data);
int sum = 0;
while (true)
{
Utf8Parser.TryParse(span, out int value, out int bytesConsumed);
sum += value;
if (utf8.Length - 1 < bytesConsumed)
break;
// skip ','
utf8 = utf8.Slice(bytesConsumed + 1);
}
return sum;
You can get rid of the allocation due to the encoding step by renting an array from an ArrayPool that's available within the System.Buffers namespace. You can pass this rented array to the GetBytes method overload that accepts a span (with an implicit cast from array to span) and return it back to the pool once you're done with it. The following sample uses the default implementation of ArrayPool to get an array of the required length that will contain the encoded bytes that need to be parsed. The parsing loop remains unchanged and continues to use the Utf8Parser API, just like before.
int minLength = encode.GetByteCount(data);
byte[] array = pool.Rent(minLength);
Span<byte> utf8 = array;
int bytesWritten = encode.GetBytes(data, utf8);
utf8 = utf8.Slice(0, bytesWritten);
int sum = 0;
// Same parser loop as before
pool.Return(array);
return sum;
private static Encoding encode = Encoding.UTF8;
private static ArrayPool<byte> pool = ArrayPool<byte>.Shared;
Like sample 1, there's no change necessary at the call site. That's because there is an implicit cast from string to ReadOnlySpan<char> in .NET Core 2.1. If, however, you're targeting an older runtime and using portable span, the implicit cast on string isn't available. To work around that, there's an extension method on the string called AsSpan(), which returns a ReadOnlySpan<char>. This extension method, along with several others, is available in the MemoryExtensions class within the System.Memory assembly.
static void Main(string[] args)
{
string data = "1, 2, 3, 4, 5, 6, 7";
StringParseSum(data); // 28
SpanParseSum(data); // 28
SpanParseSumUsingUtf8Parser(data); // 28
Utf8ParserWithPooling(data); // 28
// Only required for older runtimes
SpanParseSum(data.AsSpan());
}
Let's compare the different string parsing techniques you've defined. Notice from Figure 10 that you gain a 20% performance improvement by directly using the APIs available on span instead of string, and you get rid of all intermediary allocations. Although you end up allocating a small byte array, if you encode the incoming string data as UTF-8, by leveraging the Utf8Parser APIs, you get a ten-times reduction in execution time! Additionally, you can pool your arrays to eliminate all the allocations without noticeably impacting performance.
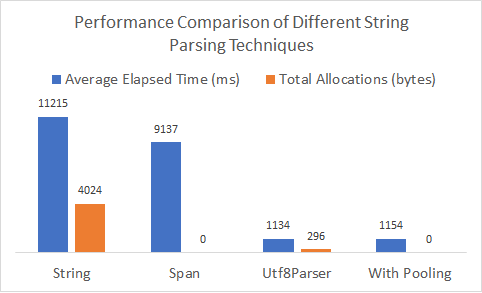
Are you interested in seeing other performance improvements across .NET Core 2.1? See the links in the References sidebar for more places to read about it.
Sample 3: Return the Last Element of the Array by Reversing It First, While Keeping the Original Intact
If you recall, I mentioned that Span<T> can be used to represent arbitrary memory. Now that you have learned how to create a span from arrays and strings, what if you wanted to create a span around memory that's allocated on the stack to retain memory safety guarantees? You could do this by refactoring an array-based implementation that starts off allocating on the heap.
public static int HeapAllocReverseArray(int[] data)
{
// Heap-allocated array for defensive copy
int[] array = new int[data.Length];
Array.Copy(data, array, data.Length);
Array.Reverse(array);
return array[0];
}
Let's say that you know the input array is small enough to fit on the stack (assume, for now, that you already verified that the length is below a certain threshold). In that case, you can avoid the heap allocation by using memory allocated on the stack. Leveraging stack allocated memory is only a viable strategy for small, constant-sized buffers, say 128 bytes, because the default stack size per thread on Windows is one megabyte. This forces you to use unsafe code because you're now dealing with pointers.
public static int UnsafeStackAllocReverse(int[] data)
{
unsafe
{
// We lose safety and bounds checks
int* ptr = stackalloc int[data.Length];
// No APIs available to copy and reverse
for (int i = 0; i < data.Length; i++)
{
ptr[i] = data[data.Length - i - 1];
}
return ptr[0];
}
}
You can re-write this by wrapping a Span<T> around the stackalloc pointer (by calling the constructor that lets you create a span from unmanaged memory via a pointer). You're still in unsafe territory due to the use of pointers. However, you can now take advantage of the newly added APIs like CopyTo and Reverse to have a cleaner implementation.
public static int UnsafeStackAllocReverse(int[] data)
{
unsafe
{
int* ptr = stackalloc int[data.Length];
// Using Span ctor that takes a pointer
var span = new Span<int>(ptr, data.Length);
// Easy to use span APIs
data.CopyTo(span);
span.Reverse();
return span[0];
}
}
Building on top of the previous code snippet, you can go one step further, and remove all use of pointers and unsafe code. You do this by leveraging inline initialization of stackalloc span, a new language feature in C# 7.2. This way, you end up with a completely safe, span-based implementation of the sample. Additionally, you can now write the method without needing separate code paths between the stack-allocated and heap-allocated copy of the array.
public static int SafeStackOrHeapAllocReverse(int[] data)
{
// Chose an arbitrary small constant
Span<int> span = data.Length < 128 ?
stackalloc int[data.Length] :
new int[data.Length];
data.CopyTo(span);
span.Reverse();
return span[0];
}
Is There Anything Span Can't Do?!
There are some trade-offs to consider when determining where using span is beneficial. You should be using spans predominantly in synchronous, performance-sensitive code paths where you want to avoid excessive data copies and allocations. This includes any scenario that involves substantial string manipulation or buffer management, or where you previously had to rely on writing unsafe code to get pointer-like performance in your libraries and server applications. Due to its design as a ref-like type, span comes with the following set of restrictions that are enforced by the C# compiler and the core runtime:
- Span can only live on the execution stack.
- Span cannot be boxed or put on the heap.
- Span cannot be used as a generic type argument.
- Span cannot be an instance field of a type that itself is not stack-only.
- Span cannot be used within asynchronous methods.
You can find additional background on the restrictions on ref-like types by following the link in the References sidebar.
Due to its design as a ref-like type, span comes with a set of restrictions that are enforced by the C# compiler and the core runtime.
Due to limitations and complexity from using span, if your scenario involves writing user-facing and UI-heavy applications, you should continue to use the well-understood strings and arrays. Furthermore, if your scenario involves prototyping or rapid application development (RAD), where developer productivity takes precedence over application performance, using spans won't be as beneficial.
Span<T> gains certain benefits because of these restrictions. These limitations enable efficient buffer access, safe and concrete lifetime semantics that are tied to stack unwinding, and they circumvent concurrency issues like struct tearing. To support the developer scenarios that cannot be addressed by span due to its usage constraints, .NET Core 2.1 also provides another type called Memory<T>.
Hot off the Press: Memory<T>
Memory<T> is another new sliceable type within the System namespace that acts as a complement to Span<T>. Just like span, it provides a safe and sliceable view into any contiguous buffer, such as arrays or strings. Unlike Span<T>, Memory<T> doesn't come with the stack-only limitations because it's not a ref-like type. Therefore, like any other C# struct, you can put it on the heap, use it within collections or with async await, store it as a field, or box it. Whenever you need to manipulate or process the underlying buffer referenced by Memory<T>, you can access the Span<T> property and get efficient indexing capabilities. This makes Memory<T> a more general purpose and high-level exchange type than Span<T>. Like span, Memory<T> also has a read-only counterpart, aptly named ReadOnlyMemory<T>. The original specification document for Memory<T> is available on GitHub for you to review (https://aka.ms/memory-spec).
Unlike
Span<T>,Memory<T>doesn't come with the stack-only limitations because it's not a ref-like type.
Note: Going forward, to disambiguate from “memory” I'll refer to Memory<T> and ReadOnlyMemory<T> explicitly with the generic type T specified.
Let's Take a Peek Inside Memory<T>
You can visualize Memory<T> as a struct containing three fields: an object, an index, and a length (see Figure 11).

The object field lets Memory<T> behave like a union type because it can represent an array/string or a MemoryManager (more on that later). As a performance optimization, the highest order bit of the index field is used to discern between the types of the object that the Memory<T> is wrapped around because that field can't be negative (negative indices don't have any semantic meaning). For it to be the heap-able counterpart to span, many of the Memory<T> APIs are like the ones available on span (array-based constructors, Slice overloads, CopyTo, implicit operators, etc.).
Memory<T> contains two unique APIs that are worth highlighting. The first one is the span property that I mentioned earlier, which can be passed around within the sequential sections of your application and let you index into the underlying buffer as you would with an array. The second one is the Pin method, which gives you a MemoryHandle to the original buffer and informs the garbage collector (GC) to not move the buffer in memory. MemoryHandle is essentially a disposable wrapper around the GCHandle and is only necessary for advance scenarios, such as interop with native code.
You can treat
Memory<T>as a factory for spans.
For common uses where Memory<T> represents an array or string, and you aren't dealing with manual management of the lifetime of those objects, you can simply treat Memory<T> as a factory for spans. However, given that its functionality can be extended via the MemoryManager to support different ownership and lifetime semantics, I want to provide you with some usage guidelines and best practices when dealing with Memory<T>. These guidelines apply to ReadOnlyMemory<T> as well.
- Where possible, synchronous methods should accept
Span<T>arguments instead ofMemory<T>, whereas asynchronous methods should acceptMemory<T>arguments. - Methods without return types (i.e., void methods) that take
Memory<T>as an argument shouldn't use it after the method returns (within background threads, for instance). - Async methods that take
Memory<T>as an argument and return a task shouldn't use it after the method returns (i.e., after the method caller that's waiting on that task continues its execution). - If you define a type that either takes in a
Memory<T>in its constructor or has a settableMemory<T>property on it, that type consumes theMemory<T>instance provided to it. EachMemory<T>instance can have just one consumer at a time.
You can read the detailed Memory<T> usage guidelines by following the link in the References sidebar.
Owners, Consumers, and Managers: Here be Dragons
You may have noticed that I previously mentioned some terminology like ownership and consumer. Let's briefly discuss the lifetime semantics of Memory<T> and some of the challenges it hopes to address. Within libraries and user applications, buffers encapsulating runtime memory occasionally get passed around between methods and need to be accessible from multiple execution threads. This leads to the issue of lifetime management of the memory and requires an understanding of three core concepts:
- Ownership: Every buffer has a single owner, responsible for its lifetime management and cleanup. This ownership can be transferred.
- Consumption: At any given time, there's a single consumer of the buffer that can read from it or write to it.
- Leasing: The lease is the restricted time duration, during execution, that any given component can act as a consumer of the buffer.
These are useful concepts for you to keep in mind because they help in identifying and avoiding use-after-free bugs in your code, which is a common class of problem when dealing with memory management. The IMemoryOwner<T> interface and the MemoryManager<T> abstract class that implements it aim to provide crisp delineation between transfer of ownership and consumption of memory so that Memory<T> can be extended to support advance developer scenarios (for example when writing Web servers). IMemoryOwner controls the lifetime of Memory<T>. You can get an instance of IMemoryOwner by renting it from a pool by calling Rent on an implementation of MemoryPool<T> and you can release it back to the pool by disposing of it. Like how you would use an ArrayPool, here's the code to write if you want to pool instances of Memory<T> and leverage IMemoryOwner to properly manage its lifetime and release.
// Your workhorse method
public void Worker(Memory<byte> buffer);
private static MemoryPool<byte> pool = MemoryPool<byte>.Shared;
public void UserCode()
{
using (IMemoryOwner<byte> rental = pool.Rent(minBufferSize: 1024))
{
Worker(rental.Memory);
}
// The memory is released back to the pool
}
There's a lot you can do with these new types. If you're interested, there are additional code samples and details on replacing the implementation of Memory<T>, sub-classing MemoryManager<T>, and creating your own custom MemoryPool<T> within the References sidebar.
Tricks of the Trade
Here are some straightforward but subtle guidelines to ensure that you're using the new Span<T> and Memory<T> APIs as efficiently as possible.
Tip 1: Use Memory.Span.Slice() Instead of Memory.Slice().Span
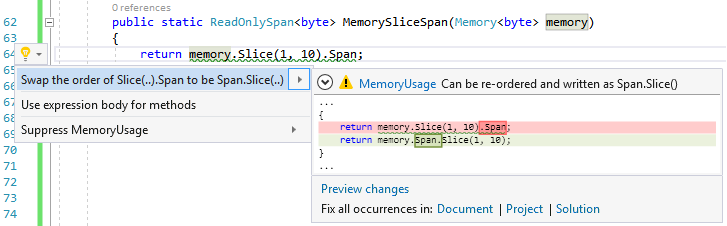
Because Memory<T> is a larger struct, slicing it tends be relatively slower compared to slicing Span<T>. Additionally, accessing the Span<T> property on Memory<T> has a non-trivial cost. Therefore, minimize accessing the span and cache it in a local variable. Try to pass the span to the sequential, synchronous methods rather than to Memory<T> directly, especially where you tend to slice the data in a loop. You can see the offending code and suggested fix in Figure 12. Slicing the Memory<T> can still be useful for scenarios where you want to persist sections of the data on the heap, which can't be done with spans (for instance, if you need to store it in a collection or pass it to an asynchronous method).
Tip 2: Use AsSpan() Instead of AsSpan().Slice()
You may prefer the readability of the fluent interface coding style and chain method calls together. One such scenario where you might be inclined to use the fluent pattern is if you have an array or string and want to get a subsection as a span. To do so, you could call AsSpan() and then slice the span based on the start index and length. It's slightly faster if you call the AsSpan() overload that takes the start index and length as parameters, which essentially does the cast and slice in one step. You can see the offending code and suggested fix in Figure 13.
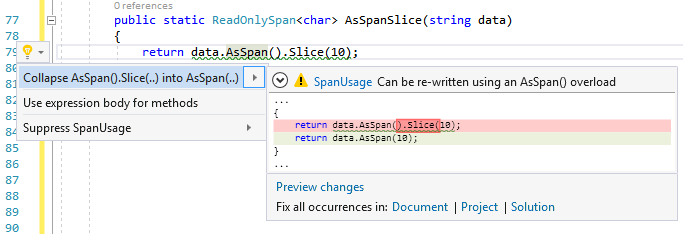
Figure 12 and Figure 13 show the MemoryUsage and SpanUsage code analyzers in action with code fix suggestions within Visual Studio. You can install and contribute to these code analyzers and help catch instances of the sub-optimal usage patterns described above (see the References sidebar for more on this).
What About Discontiguous Buffers?
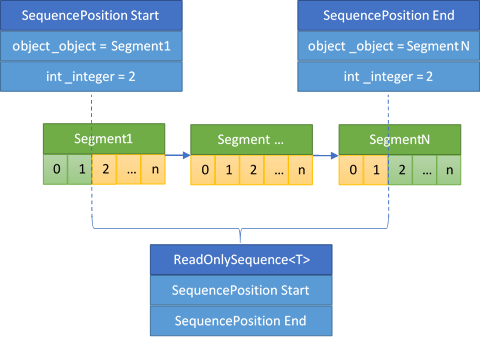
Both Span<T> and Memory<T> provide functionality for contiguous buffers such as arrays and strings. System.Memory contains a new sliceable type called ReadOnlySequence<T> within the System.Buffers namespace that offers support for discontiguous buffers represented by a linked list of ReadOnlyMemory<T> nodes. I won't go into too much detail here, but the basic structure of a ReadOnlySequence is based on two cursors within the sequence, known as SequencePosition (presented in Figure 14).
The following code snippet shows us how you can create a single segment ReadOnlySequence directly from an array or ReadOnlyMemory. Furthermore, just like Span<T> and Memory<T>, you can slice ReadOnlySequence<T> without having to deal with stitching together the fragmented buffers yourself.
int[] array = { 1, 2, 3, 4, 5 };
var sequence = new ReadOnlySequence<int>(array);
sequence = sequence.Slice(1, 3);
// sequence = { 2, 3, 4 }
ReadOnlyMemory<int> memory = array;
sequence = new ReadOnlySequence<int>(memory);
sequence = sequence.Slice(1, 3);
// sequence = { 2, 3, 4 }
To use ReadOnlySequence as a linked list of buffers, you must subclass and provide a concrete implementation of the abstract ReadOnlySequenceSegment<T> class, which conceptually represents a node within the sequence. You can then pass the start and end segment to the appropriate ReadOnlySequence constructor. The ReadOnlySequenceSegment class is defined as follows:
public abstract class ReadOnlySequenceSegment<T>
{
// The value of the current node.
public ReadOnly`Memory<T>` Memory
{ get; protected set; }
// The next node within the sequence.
public ReadOnlySequenceSegment<T> Next
{ get; protected set; }
// The sum of node lengths before current.
public long RunningIndex
{ get; protected set; }
}
Let's assume that you have the following concrete implementation of ReadOnlySequenceSegment.
class Segment<T> : ReadOnlySequenceSegment<T>
{
public Segment(ReadOnly`Memory<T>` memory) => Memory = memory;
public Segment<T> Add(ReadOnly`Memory<T>` mem)
{
var segment = new Segment<T>(mem);
segment.RunningIndex = RunningIndex + Memory.Length;
Next = segment;
return segment;
}
}
You can then create a ReadOnlySequence from instances of Segment<T> to represent disjointed buffers and slice them just like single segment sequences.
int[] array1 = { 1, 2, 3 };
int[] array2 = { 4, 5, 6 };
var segment1 = new Segment<int>(array1);
Segment<int> segment2 = segment1.Add(array2);
sequence = new ReadOnlySequence<int>(
segment1, startIndex: 0,
segment2, endIndex: 3);
sequence = sequence.Slice(1, 3);
// sequence = { 2, 3, 4 }
Because ReadOnlySequence provides APIs that obfuscate the underlying structure of how the segments compose the sequence, you can view it as a single continuous buffer to build higher-level stream-like APIs. The PipeReader and PipeWriter classes within the System.IO.Pipelines namespace that are used by the ASP.NET Core Web server are an example of such APIs (the References sidebar has the link to its original specification document).
Summary
If you're working on making your server applications more efficient, developing highly scalable APIs, or even if you just like to keep up with what's on the cutting edge of .NET, I encourage you to give Span<T> and Memory<T> a try. These sliceable types were designed with a focus on runtime and memory efficiency for cloud-based scenarios and adhere to the philosophy of no allocations and no data copies. I hope you are eager to try out these new .NET Core 2.1 features within your libraries and applications and take advantage of all the performance optimizations that accompanied this release. Better yet, I welcome you to join in on the fun as part of the .NET open source community on GitHub to help build the next set of features and libraries for everyone to use.
You can download all the code samples shown in this article from the CODE Magazine link associated with this article. Run them yourself!
