


You've heard of Hadoop and the “circus” around big data; you've probably been interested enough to do a little research on the topic and you may be forgiven for thinking that this is only a toy in the Unix-like toy box.
I'm happy to tell you that's not the case. Hadoop is alive and well on the Windows platform, both standalone via the Hortonworks Data Platform for Windows or, if you prefer to use it as a service, you can do so through HDInsights on Azure. It's even available for you experiment with on your own development computers via the HDInsight emulator. The purpose of this article is to show you how to get up and running with the emulator so you can start extending your .NET skills into the big data arena.
Before I do that, however, I want to remove some of the confusion around the terms MapReduce and Hadoop. These two names seem to have become synonymous although in actual fact, they're very different. Let's look at them.
MapReduce
The best way to explain MapReduce is via an example. The canonical example for MapReduce is word count, so to stick with tradition, I'll make that the first example. Consider the following naïve algorithm for counting words in an input:
using System;
using System.Collections.Generic;
using System.Linq;
namespace Problem
{
class Program
{
static void Main()
{
"one, two, two, three,
three, three, four,
four, four, four"
.Split(',')
.GroupBy(x => x)
.ToList()
.ForEach(group =>
Console.WriteLine(
"{0} appears {1} time(s)",
group.Key.Trim(),
group.Count()));
}
}
}
The algorithm takes the provided string, splits it on the comma character, groups by the words themselves, and then, for each group, prints out the word and the number of occurrences of that word in the group. The output from this algorithm can be seen in Figure 1.
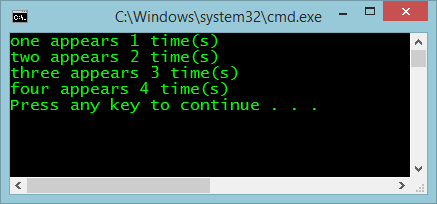
This algorithm is constrained both by memory and by CPU. It's constrained by memory because as the size of the input string doubles, it reaches a point where it can no longer read the input directly into memory. You can mitigate that by reading the input one line at a time from a file. The algorithm is further constrained by CPU due to the input string continuing to double; it reaches a point where it can no longer calculate the word count in a timely manner.
MapReduce is the algorithmic solution to this problem. By splitting the task into two functions: Map and Reduce. The Map function takes the input and maps it to a tuple output with a key and a value. In this case, the key is the word appears and the value is the integer 1, signifying that the algorithm has found this word once. The Reduce function groups the output of the Map function by key and then reduces that output down to another tuple output. This time, the key is the word, and the value is the summation of the number of times that word has appeared. For example, if the output from the Map function is: (“the”, 1), (“the”, 1), (“the”, 1), the output from the Reduce function is: (“the”, 3).
Listing 1 provides an example of the earlier wordcount algorithm expressed as a MapReduce.
Listing 1: The wordcount algorithm expressed as a MapReduce
using System;
using System.Collections.Generic;
using System.Linq;
namespace Solution
{
class Program
{
static void Main()
{
Reduce(Map("one, two, two, three, three, three," +
"four, four, four, four"));
}
private static List<Tuple<string, int>> Map(string input)
{
var list = new List<Tuple<string, int>>();
input
.Split(',')
.ToList()
.ForEach(word => list.Add(
Tuple.Create<string, int>(word, 1)));
return list;
}
private static void Reduce(List<Tuple<string, int>> list)
{
list
.GroupBy(tuple => tuple.Item1)
.ToList()
.ForEach(group => Console.WriteLine(
"{0} appears {1} time(s)",
group.Key.Trim(),
group.Count()));
}
}
}
You can see that the mapper splits the input and then emits a count every time it sees a word, and the reducer groups those words and performs a reduction by summation, giving the exact same result as the original algorithm, as can be seen in Figure 2.
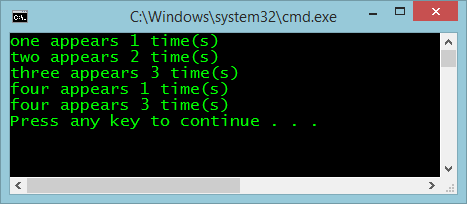
The advantage of the MapReduce algorithm is that it allows the original algorithm to be split across a grid of commodity-compute nodes in a cluster, so now when the size of the input doubles, you can simply double the size of the cluster to maintain speed of processing.
Although you've solved the scalability issue, you now have other issues to deal with. For example, you're responsible for splitting the input data across data nodes, for collecting the output of the mappers and forwarding it to the reducer nodes, for dealing with hard drive failures in the cluster, and etc. That's where Hadoop comes in.
MapReduce is a scalability algorithm and Hadoop is a framework that supports that algorithm.
Hadoop
MapReduce is a scalability algorithm and Hadoop is a framework that supports that algorithm. The internal workings of Hadoop are outside the scope of this article but it's time to set up an instance of Hadoop on your development computer so you can start using your .NET skills in the big data world.
The easiest way to get started with Hadoop is via the HDInsight Emulator, which is installable via the Web Platform Installer (WPI). Launch the WPI and search for HDInsight, as shown in Figure 3.
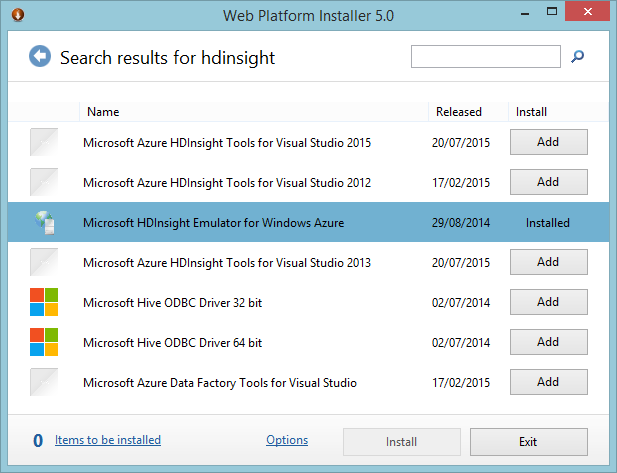
You can see that I already have the emulator installed on my computer. If you search for the emulator and it's not found, that's Microsoft's subtle way of telling you that the emulator is not available for your platform, which is most likely due to the fact that you're on a 32bit computer and the emulator requires a 64bit computer.
The installer installs both the Hortonworks Data Platform for Windows (DPW) and the HDInsight emulator because HDInsight has a dependency on the DPW. It also installs and starts a number of services, indicated in Figure 4.
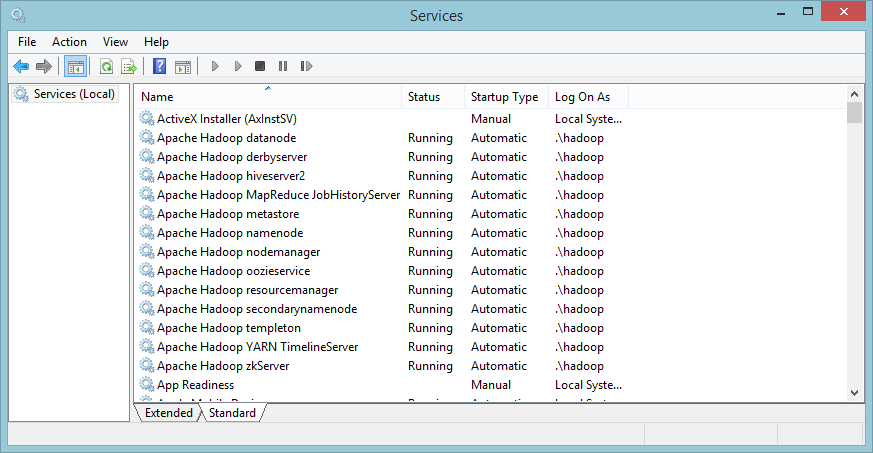
Any programming language that can read from and write to the console is allowed to define Hadoop jobs via its streaming API. As C# is a language that meets the requirements, you can now go ahead and write your first Hadoop job.
Because I've already used a word count example, I'm going to change things up a little and use the example of predicting a horse racing result based on a specified input. The first thing to do is to create a new solution and add two console projects to it, one for the mapper and one for the reducer.
In this example, the Map function reads the horse, jockey, and course names from the console, fetches a bunch of stats relative to that combination, and then emits a key value pair where the key is the horse and the value is a list of stats connected to that horse. The input is fed one line at a time to the program via the console by the Hadoop framework. This is achieved by the code in the following snippet:
static void Main()
{
string line = string.Empty;
while ((line = Console.ReadLine()) != null)
{
string[] fields = line.Split(',');
string horse = fields[0];
string jockey = fields[1];
string course = fields[2];
string stats = GetStatsForHorseJockeyCourse(
horse,
jockey,
course);
Console.WriteLine("{0}\t{1}", horse, stats);
}
}
The reducer takes the output of the mapper, again via the console as supplied by the Hadoop framework, and reduces the list of statistics to one overall “winning index” for each horse. The reducer then emits a key value pair where the key is the horse and the value is the overall index, as in the next bit of code:
static void Main(string[] args)
{
string line = string.Empty;
while ((line = Console.ReadLine()) != null)
{
string[] fields = line.Split('\t');
string key = fields[0];
string value = fields[1];
string[] stats = value.Split(',');
double index = stats.Sum(x => Convert.ToDouble(x));
Console.WriteLine("{0}\t{1:.00}",
key, index);
}
}
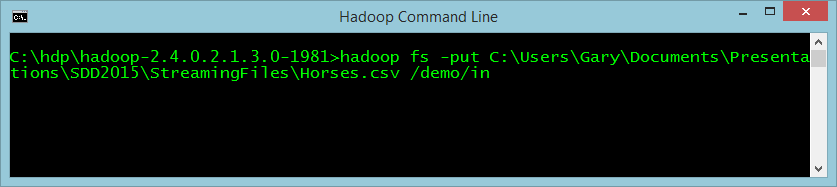
Now that it's compiled, there are a number of things to do before you can run this job on Hadoop. The first is that you have to store the input file onto the Hadoop cluster. To do this, open the Hadoop console window from the link installed to your desktop and use the Hadoop fs -put command, as seen in Figure 5.
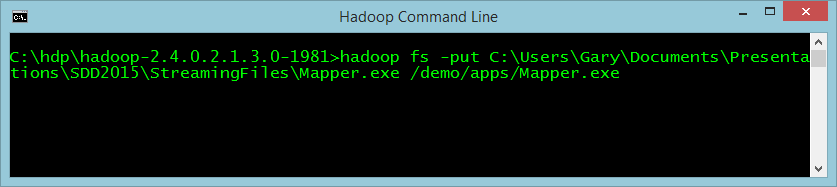
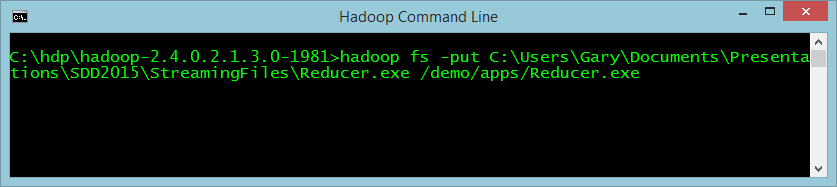
Now you need to push the Map and Reduce functions up to Hadoop too, as seen in Figure 6 and Figure 7.
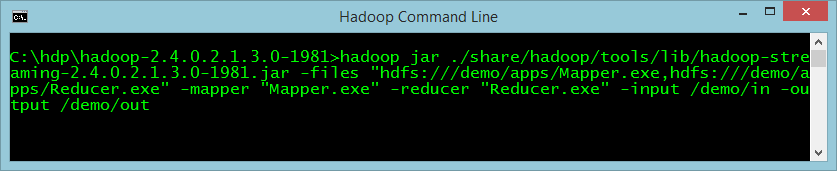
Now all you have to do is start this job using the Hadoop jar command. You use this command because the streaming API is defined as a jar file. The command has a number of parameters that tell Hadoop:
- Files: Where the mapper and reducer files are stored
- Mapper: Which file is the mapper
- Reducer: Which file is the reducer
- Input: Where the input file is
- Output: Where to put the output from the reducer
The command is executed as in Figure 8:
When the command has finished, there will be a part-n file in the output directory. In this example, it's called /demo/out. There's one file for each reducer. Because you're running the emulator, there will only be one reducer and so there will only be one file in the directory, part-00000, as shown in Figure 9.
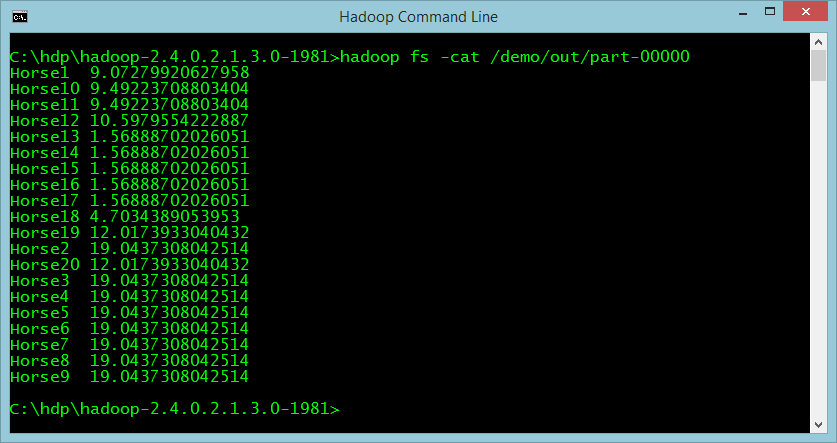
If you cat that file, you can see the output of the algorithm, which is each horse's name and its calculated “winning index,” as in Figure 10.
The Hadoop.MapReduce Package
I won't lie, that last exercise is a little long-winded. Fortunately, there's an easier way to work with Hadoop and that's via the Microsoft.Hadoop.MapReduce package. Once that package is added to your project, it becomes much easier to work with Hadoop.
There are only three things you have to do once you've added the package. The first of these is to define a mapper, as shown in Listing 2.
Listing 2: Define a mapper
public class Mapper : MapperBase
{
public override void Map(string inputLine,
MapperContext context)
{
string[] fields = inputLine.Split(',');
string horse = fields[0];
string jockey = fields[1];
string course = fields[2];
string stats = GetStatsForHorseJockeyCourse(
horse,
jockey,
course);
context.EmitKeyValue(horse, stats);
}
private static string GetStatsForHorseJockeyCourse(
string horse,
string jockey,
string course)
{
// Your code here ?
}
The only difference between the code in Listing 2 and the code defined for the streaming API version is that this class inherits from MapperBase.
The next thing you have to do, not surprisingly, is to define a reducer:
public class Reducer : ReducerCombinerBase
{
public override void Reduce(
string key,
IEnumerable<string> values,
ReducerCombinerContext context)
{
string value = values
.First()
.Split(',')
.Sum(x => Convert.ToDouble(x))
.ToString();
context.EmitKeyValue(key, value);
}
}
Again, the only difference between this version of the reducer and the previous version is that this one inherits from ReducerCombinerBase. The purpose of a combiner is outside the scope of this article; I'm not defining a combiner in the example.
The last thing you have to do is define the Hadoop job, which can be seen in the following snippet:
class Program
{
static void Main(string[] args)
{
HadoopJobConfiguration conf = new HadoopJobConfiguration()
{
InputPath = "/demo/in",
OutputFolder = "/demo/out"
};
Hadoop.Connect(new Uri("http://YOUR_MACHINE_NAME/"), YOUR_UID, YOUR_PWD)
.MapReduceJob
.Execute<Mapper, Reducer>(conf);
}
}
Here, all you're doing is instantiating a HadoopJobConfiguration object and setting the input and output directories, much like you specified in the earlier call. Now you can connect to the Hadoop emulator and execute a Map /Reduce job using the defined mapper and reducer.
I hope I've shown you that Hadoop is not just a tool in the Unix-like world and that it's usable on the Microsoft platform, which allows you to exercise the .NET skills you already have.
