


When I was a kid, I loved baseball. I lived it 24/7. In the summertime, happiness meant a pickup game during the day and a Phillies doubleheader at night. I’m still a kid at heart and I still love baseball - and I also love SQL Server. And right now, happiness means seeing all the cool new features in SQL Server 2012. There are so many of them that I can’t list them in a single article. So, I’m penning a two-part Baker’s Dozen. The first part of this “twin-bill” (yes, expect a few baseball analogies!) will be 13 new T-SQL and database engine features in SQL Server 2012. The “night-cap” in the next issue will be 13 new features in SQL Server Integration Services and the new Business Intelligence Semantic Model.
Starting Lineup for Game 1
Normally, in Baker’s Dozen tradition, I say, “What’s on the menu?” This time I’m saying, “The starting lineup is as follows!”
- Leading off, the Baker’s Dozen Spotlight: The new Columnstore index in SQL Server 2012, which can provide dramatic performance improvements in many data warehousing scenarios
- Batting second, the new SSDT environment
- Batting third, the new sequence generator object
- Batting fourth, the new Lag and Lead functions
- Batting fifth, the Baker’s Dozen Potpourri: the new Percentile window functions
- Batting sixth, the new Fetch language feature for paging result sets
- Batting seventh, the new EXECUTE…WITH RESULTS for extending the use of stored procedure result sets
- Batting eighth, the new IIF feature
- Batting ninth, the new TRY…CONVERT feature
- Batting tenth (yes, I realize there are only 9 players on a team), a set of new date and DateTime functions
- Batting eleventh, the new THROW statement to throw an error
- Batting twelfth, two new string and formatting functions
- And last but not least, the new FileTable feature
Batter Up! The Demo Database for the Examples
As I am writing this article (early January 2012), SQL Server 2012 is in a release candidate status, which generally means that the product is beyond the beta/technology preview status and that a formal release to manufacturing (RTM) is next. At the PASS Summit in October 2011, Microsoft announced that SQL Server 2012 was on schedule for a formal release in the first half of 2012.
The examples use the AdventureWorks2008R2 OLTP database. (As of this writing, the AdventureWorks OLTP database hasn’t yet been updated for SQL Server 2012). You can find AdventureWorks2008R2 on the CodePlex site: http://msftdbprodsamples.codeplex.com/releases/view/55330.
Tip 1: The Baker’s Dozen Spotlight: The New Columnstore index
Over the last 3-5 years, many companies have sent a clear message that they view Microsoft SQL Server as a viable option for large database applications. No longer just a “database server for medium-size companies,” SQL Server has become the database of choice for companies like WiPro Technologies (2nd largest IT company in India), Arcelik (one of Europe’s largest manufacturers), and Clalit Health Services (Israel’s largest HMO) - all of whom have converted Oracle/SAP Systems to SQL Server.
But Microsoft hasn’t rested on the laurels that have helped it achieve a more “prime-time” status: they continue to augment their flagship database product. One can plainly see that in the Parallel Data Warehouse appliance that scales to petabytes (http://msdn.microsoft.com/en-us/library/ee730351.aspx). One can also see it in the topic of this first tip: the new Columnstore index that can increase the performance of data warehouse queries by anywhere from 10-100 times.
The new Columnstore index groups and stores data for each column and then join all columns to build the index. (By contrast, regular indexes group and store data for each row and then join all the rows to build the index.) Here are the major attributes of the Columnstore index (with an example to follow):
- Based on Microsoft’s Vertipaq technology that’s used in Microsoft PowerPivot - a highly compressed index, more compressed than a non-clustered covering index.
- Very easy to create (same syntax as an existing index, but with the Columnstore keyword).
- It is a read-only index: meaning that once you create it, SQL Server will not maintain it when you subsequently insert new rows to the table. This makes Columnstore indexes useful for data warehousing scenarios (where data is loaded on a schedule), not for OLTP systems (data inserted constantly).
- Utilizes read-ahead reads in IO statistics (SQL Server reading data into memory cache as a separate thread).
- Potentially dramatic effect on query performance - sometimes by a factor of 100x.
- Can handle all data types except varbinary, varchar(max), hierarchyid, timestamp, uniqueidentifier, sqlvariant, xml, image, text. In addition, no filtered indexes, no computed column.
- Has been described as a “covering index on massive steroids.”
- Can only have 1 covering index per table.
- Less IO; more can be stored in memory.
- Uses new batch execution mode in SQL Server 2012.
Some people look at the IO statistics from a Columnstore index and wonder if a Columnstore index will always perform better than a covering index. Often it will depend on the selectivity of the query. A query that retrieves a very small percentage of the data using an index seek might not take as much advantage of a Columnstore index as a query that retrieves a greater portion of data.
For an example, I’ve created a script (Listing 1) to create a 10 million row table - not as large as a production data warehouse, but certainly not a peanut database either. Listing 2 shows the creation of a Columnstore index and a query with a basic join and aggregation. Figures 1 through 3 show the performance differences - # of reads, execution time - between scenarios of a clustered index, a covering index and a Columnstore index.
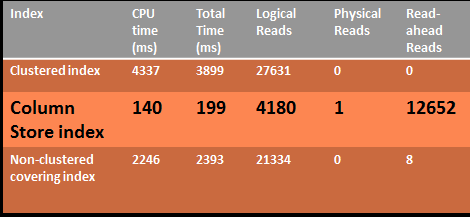
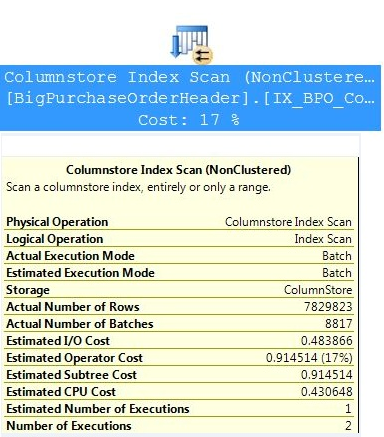
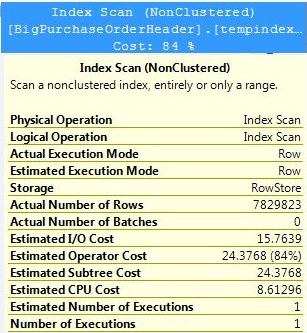
The performance numbers show that, indeed, Microsoft “hit the ball out of the park” with Columnstore indexes. This is one of the most significant enhancements in the history of SQL Server with regards to data warehouse query performance!!!
Microsoft hit the ball out out of the park with the new Columnstore Index. Any time a few feature cuts query execution time by a factor of 10 or greater, that’s a home run in any league.
Tip 2: The New SSDT (SQL Server Data Tools) Environment
One of the frustrations of SQL Server and Business Intelligence Developers has been the lag of Business Intelligence Development Studio (BIDS) with respect to Visual Studio. Additionally, developers working in BIDS often need to ALT-TAB back and forth with SQL Server Management Studio.
Fortunately, SQL Server 2012 comes with a tool called SQL Server Data Tools (SSDT), an integration environment that allows developers to work with Visual Studio and BI projects AND also access many of the capabilities that were previously found in SQL Server Management Studio.
(NOTE: SSDT was previously known as code-named “Juneau.”)
You can read more about SSDT here: http://msdn.microsoft.com/en-us/data/gg427686.
Tip 3: New Sequence Generator Object
Have you ever wanted a table-independent identity generator? Other databases (e.g. Oracle) have had a sequence generator to produce a new integer identity on demand, without association to a specific table. Imagine a scenario where you could create an integer value for every row in every table, where the value is unique across tables - and without the complexity of a uniqueidentifier.
SQL Server 2012 contains a new sequence generator database object that performs this very task (Listing 3).
The new sequence generator object in SQL Server 2012 allows database administrators to have a table-independent factory: one that produces an integer value that will be unique across every table/row in the database. This effectively creates the equivalent of a uniqueidentifer within a database.
Tip 4: The New Lag and Lead Functions
In the last few versions of SQL Server, Microsoft has implemented T-SQL language features that have an OLAP “feel” to them. For instance, GROUPING SETS in SQL Server 2008 allow SQL developers to produce multiple levels of subtotals from a query. And going back further, SQL Server 2005 introduced the RANK family of functions to assign a sequential ordering number “across” a set (or “window”) of rows. Many of these functions are ones you can find in the MDX programming language that’s used with OLAP databases.
The last few versions of T-SQL have contained new language features designed to provide additional analytic capabilities. Grouping Sets, LAG/LEAD, and Percentile Functions all give SQL developers better ways to work with data.
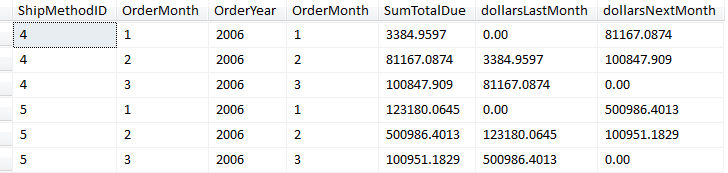
SQL Server 2012 introduces two new functions that have similar functionality in MDX: Lag and Lead. For instance, suppose you are generating a result set of sales by month - and for any one row, you wish to show sales for the prior month (the “lagging” month) and the next month (the “leading” month). Figure 4 shows an example of a result set that shows sales by month, along with the sales for the prior month and the next month. Listing 4 contains a complete example of LAG and LEAD, which both operate similar to the existing RANK function that generates a scalar value “over” a set of rows in a particular order.
lag( SumTotalDue, 1, 0) over
(partition by ShipMethodID
order by OrderYear, OrderMonth)
as dollarsLastMonth,
Listing 4 contains a complete example using LAG and LEAD, with the result set in Figure 4.
Tip 5: Baker’s Dozen Potpourri: the New Percentile Window functions
If the LAG and LEAD functions weren’t enough, Microsoft added several new functions for determining different percentile and median calculations. While not every SQL developer will use this - anyone looking to generate analytic statistics against relational data will find these functions a major hit - a solid double off the outfield wall.
From my own perspective, I welcome some of the new functions that will eliminate the need for workarounds that sometimes spark protracted discussions. For instance, SQL Server does not contain a mathematical median function, which is often necessary to calculate a “middle score/middle observation” that isn’t impacted by outlier conditions. In my Baker’s Dozen article in the November/December 2011 issue (QuickID 1112061), I showed a workaround for calculating a median average by assigning a row number and then averaging the middle values (which would be 1 value for an odd number of rows and 2 values for an even number of rows.)
DECLARE @NumObservations int = @@ROWCOUNT
;WITH ScoreCTE AS (
SELECT Id, Score,
ROW_NUMBER() OVER (ORDER BY Score)
AS ScoreRank
FROM @StudentScore)
SELECT AVG(Score) AS Median FROM ScoreCTE
WHERE ( ScoreRank IN
((@NumObservations+1)/2,
(@NumObservations+2)/2) )
While this type of code works, it’s usually better for a software product to provide a native function, providing the native function provides good functionality and performance. Fortunately, SQL Server 2012 provides two new functions (PERCENTILE_CONT and PERCENTILE_DISC) to natively handle a median calculation.
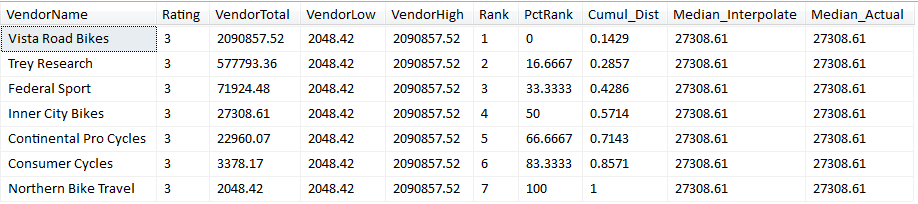
Figure 5 shows a screen shot for a result set that shows seven vendors, ranked by their sales dollars. See Listing 5 for a new code example, plus Figure 5 for the screen shot.
- First_Value - provides the first value (thus the name) across a set of rows, based on a particular order
- Last_Value - provides the last value across a set of rows, based on a particular order, with the option of specifying a “between” range
- PERCENT_RANK - the percentage of rows/values in the range/window (“distribution”) of rows that are the same or lower than the current row. For example, in Figure 5, the vendor Federal Sport has a percentile rank of 33.33%. That means that 33% (2 rows) of the total number of other rows (6 rows) have a sales dollar amount lower than vendor Federal Sport.
- CUME_DIST - similar to the Percentile Rank function in the example in Figure 5, the ranking for Vendor Federal Sport (3) divided by the total number of rows (7) (i.e., .4286). This number represents the relative position of the vendor with respect to the total number of rows.
- PERCENTILE_CONT and PERCENTILE_DISC, for all intents and purposes, both calculate the median score/value (i.e., “middle score”), over a set of rows. In Figure 5, the middle vendor dollar amount is Inner City Bikes with sales of $27,308.61. In this scenario, with an odd number of vendors in Figure 5, both functions return the same value. However, had the number of vendors in Figure 5 been an even number (such as 8 vendors), the PERCENTILE_CONT function would calculate/interpolate a median by taking the straight average of vendors 4 and 5.
Tip 6: New Fetch Language Feature for Paging Result Sets
When Microsoft introduced the new ROW_NUMBER function in SQL Server 2005, developers used it (in conjunction with the new common table expression capability) to generate an internal row number for paging result sets. While this worked quite well, it meant using either a subquery or common table expression, since a ROW_NUMBER (windowing) function cannot be used in the WHERE clause.
SQL Server 2012 now contains a new set of statements: offset and fetch next.
OFFSET (@PageNumber-1) * @RowsPerPage ROWS
FETCH NEXT @RowsPerPage ROWS ONLY
See Listing 6 for the full code example, which retrieves N number of rows based on page number Y (where both N and Y are variables). Listing 6 also contains the sample output.
Tip 7: The New EXECUTE…WITH RESULTS
Have you ever wanted to rename the columns from a stored procedure result set? Listing 7 shows an example of the new EXECUTE WITH RESULTS statement, which allows you to rename the columns from a result set.
Tip 8: The New IIF Feature
As an instructor, I sometimes have challenges in teaching students that certain Microsoft languages/tools have certain functions, but others don’t. Take, for instance, the IIF function. It exists in MDX and in SSRS, but not T-SQL….
Until now!!!
SELECT IIF(CreditRating=1,'Good Credit Rating',
'Bad Credit Rating')
AS CreditMessage, Name
FROM Purchasing.Vendor
Tip 9: The New TRY…CONVERT and TRY…PARSE Features
If you follow baseball closely, you know that some hitters in the lineup contribute not by hitting home runs, but by getting the “little things done” (like laying down a bunt, or hitting into an out that advances another base runner).
Well, SQL Server 2012 has a few of these types of “role players” that, while not huge features, can certainly help a team out. For instance, have you ever wanted to parse a value to see if it’s a valid date?
SELECT IIF(
TRY_CONVERT(date, '02/29/2010') is NULL,
'Invalid Date', 'Date')
AS TestDateResult
SELECT TRY_PARSE( 'cannot be a number' as int)
AS result1,
TRY_PARSE( '100' as int)
AS result2
Tip 10: A Set of New Date and DateTime Functions
Another nice “utility player” in the Microsoft line-up is the new set of date and DateTime functions.
For instance, creating a new date is as simple as using the new function DATEFROMPARTS:
SELECT DATEFROMPARTS( 2011, 12, 24) AS NewDate
SELECT datediff(mi,
DATETIMEOFFSETFROMPARTS
(2011, 01, 8, 8, 00, 00, 0, -5, 0, 7 ) ,
DATETIMEOFFSETFROMPARTS
(2011, 01, 8, 10, 30, 00, 0, -8, 0, 7 ))
As MinutesDiff
This next one is a personal favorite of mine: the ability to determine the last day of a month, using the new EOMONTH function:
DECLARE @date DATE
SET @date = getdate()
SELECT EOMONTH ( @date ) AS Result;
Tip 11: New Ability to Throw an Error
In SQL Server 2005, Microsoft made tremendous strides in exception handling with the implementation of TRY-CATCH. This allowed SQL developers to build more robust stored procedures with transactions and better error handling.
Part of the improved methodology in SQL Server 2005 was the ability to raise an error “politely” (using RAISERROR) back to the calling application. However, this introduced one complication: it changed the error line number.
Fortunately, Microsoft has further refined this capability by allowing developers to “throw” the same error that was “caught” to begin with:
CREATE PROCEDURE dbo.ThrowTest
as
BEGIN
BEGIN TRY
SELECT 1/0
END TRY
BEGIN CATCH
THROW
END CATCH
END
GO
EXEC dbo.ThrowTest
This further improves error-handling scenarios in SQL Server 2012.
Tip 12: New String and Formatting Functions
Suppose you’re working with an international application, and need to display currencies in different country currency formats (such as the output in Figure 6, which uses the different currency symbols).

SQL Server 2012 contains a new capability in the FORMAT function to render currency in different formats:
DECLARE @Dollars MONEY = 1412.95
SELECT
FORMAT(@Dollars,'c','en-US') [US],
FORMAT(@Dollars,'c','it-IT') [Italy],
FORMAT(@Dollars,'c','fr') [France],
FORMAT(@Dollars,'c','ar-SA') [Arabic],
FORMAT(@Dollars,'c','ja-JP') [Japan]
Tip 13: New FileTable
Many years ago, I worked on a major application that managed scanned images for verification of a business process. The application stored images in the file system (i.e. “outside the database”), with database references to the external file names. I felt very strongly after the experience that images and any other binary content belonged outside the database, with custom references inside the database to the content
Over the years I’ve (stubbornly) held to that view, even after Microsoft introduced the FileStream capability in SQL Server 2008. However, Microsoft has introduced a feature in SQL Server 2012 that has led to an apostasy for me (and probably others) with regards to this topic. The feature is called FileTable.
The SQL Server FileTable is a mechanism that allows you to map a folder/file system structure to special database table, where SQL Server maintains a relationship dynamically. Yes, it’s that simple. (FileTable builds on the concept of the FileStream object from SQL Server 2008). Listing 8 shows an example of creating a FileTable database, with a table that synchronizes a folder of images. The listing does the following:
- Configures the instance of SQL Server for FileStream access
- Creates an empty database FileTableExampleDB with FileStream capabilities
- Alters the new database and sets a FileStream directory name reference
- Creates a table with a reference to a specific directory (in this case, a folder that will hold images)
This means I can load the folder with images (Figure 7), and have a corresponding table (tblFileTableBaseballLogos) that’s associated with the images (Figure 8).

And most important, I can also issue standard DML statements against the table in SQL Server, and it will affect the contents of the folder!
DELETE FROM [dbo].[tblFileTableBaseballLogos]
Next Time Around in the Baker’s Dozen
In the “night-cap” of this Baker’s Dozen doubleheader (i.e., in the next issue), I’ll cover the new features in SQL Server 2012 Integration Features. SSIS has always been a good tool for ETL development, though certain aspects of the tool have had “opportunities for improvement.” Microsoft meticulously re-crafted many aspects of SSIS in SQL Server 2012. As a result, a good tool just got much better. Stay tuned!
