


The integration of the .NET Common Language Runtime (CLR) inside SQL Server 2005 (SQL CLR 1.0) enabled database programmers to write business logic in the form of functions, stored procedures, triggers, data types, and aggregates using modern .NET programming languages.
This article presents the advances to the CLR integration introduced in SQL Server 2008, which significantly enhances the kinds of applications supported by SQL Server.
In particular, this article describes the support for large (greater than 8000 bytes) user-defined types and aggregates, multiple-input user defined aggregates, and order-aware table-valued functions. The CLR integration in SQL Server 2008 will also leverage the database scalar type extensibility introduced in SQL CLR 1.0 to provide a hierarchical identifier data type to enable encoding of keys describing hierarchies (folders, inheritance, etc) as well as a built-in framework for spatial applications. This framework includes: a class library for geometry types based on the Open Geospatial Consortium for both flat earth and round earth solutions, as well as a spatial index.
Large UDTs
SQL Server 2005 introduced user-defined types (UDTs) as a mechanism to extend the scalar type system of SQL. UDTs are not a general object-relational (O-R) mapping mechanism. That is, you should not use UDTs to model complex business objects such as employee, contact, customer, or product. For more general O-R mapping mechanisms, consider the LINQ to SQL or LINQ to Entities frameworks available in Visual Studio 2008. Microsoft designed SQL Server UDTs, implemented as CLR classes or structs, to model atomic scalar types such as monetary currency, geometry and spatial types (see section on spatial types), specialized date or time, etc.
To persistently store UDT instances, it must be possible to transform the state of the instance to and from its internal binary format. You can achieve this through a pair of routines for serialization and deserialization. The serialization routine transforms the run-time state of a CLR class or struct instance to a binary stream. The deserialization routine performs the inverse operation. SQL Server supports two forms of serialization: native (Format.Native) and user-defined (Format.UserDefined). All forms of UDTs in SQL Server 2005 have a size limit of up to 8000 bytes. SQL Server 2008 removes the size restriction of Format.UserDefined UDTs allowing UDTs up to 2 GB.
Microsoft designed SQL Server UDTs, implemented as CLR classes or structs, to model atomic scalar types such as monetary currency, geometry and spatial types, specialized date or time, etc.
Listing 1 shows a code fragment describing the definition of a Polygon type as a large UDT. To define a UDT as large, one only needs to specify a value of -1 for the MaxByteSize property of the SqlUserDefinedType custom attribute.
Handling User-defined Aggregates
A very welcome extensibility feature in SQL Server 2005 is the ability to implement user-defined aggregate functions. As with any such feature, the usage scenarios expand very quickly beyond those initially envisioned and require the platform to support additional behaviors and capabilities. SQL Server 2008 expands user-defined aggregates to support multiple input arguments as well as the ability to have results for the aggregate be larger than 8000 bytes.
Customers have frequently asked the SQL Server team to add support for a string concatenation aggregate function. As an explanation for why they want the request, a customer would typically explain how they’d like to stitch together a set of e-mail addresses with a semicolon as a delimiter. SQL Server 2008’s user-defined aggregate function addresses this request. The accumulate method of the aggregate class may look something like:
public void Accumulate (SqlString Value)
{
if (!Value.IsNull)
result+= Value.Value + ";";
}
If you tried this approach in SQL Server 2005 you quickly realized that the resulting concatenated string is constrained to an 8000-byte size limit. SQL Server 2008 doesn’t have this restriction and allows you to have an aggregate as large as 2GB. In addition, you do not need to change the managed code (C# in the snippet above)-you only need to change the T-SQL registration. The example below specifies nvarchar(max) as the return type of the aggregate function:
CREATE AGGREGATE dbo.concat
(@Value nvarchar(4000))
RETURNS nvarchar(max)
EXTERNAL NAME [concatProject].[concat];
You can use this aggregate in a query as you would use any other aggregate function:
SELECT dbo.concat(email) FROM dbo.attendees
WHERE …
Imagine now a scenario where the format of each concatenated value depends on some other e-mail-specific flags included in a separate column of the attendees table. SQL Server 2008 will let you create aggregates that take multiple columns as input as in the following query:
SELECT dbo.concat (email, format_flags)
FROM dbo.attendees WHERE …
This capability makes it simple to write more powerful aggregates such as weighted averages or other statistical functions such as median.
Order-Aware TVFs
One of the most powerful extensibility features enabled by the CLR integration in SQL Server 2005 is the ability to write table-valued functions in any .NET language. These are functions that have an initializer method to set up any necessary context and provide an enumerator and a method that is invoked once per row. You can see a canonical example in Listing 2 that shows return entries in the Event Log as a rowset in SQL Server.
Imagine now a query that wants to retrieve the first few (e.g., 10) records from the log in chronological order:
SELECT TOP 10 * FROM dbo.Initmethod('System')
ORDER BY timeWritten
If you examine the execution plan for this query, you will notice that the optimizer introduces a sort operator before returning the results so it can guarantee the top events given the particular requested order (Figure 1).
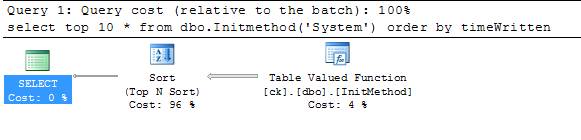
You can see from the execution plan that a large portion of the estimated execution cost goes into the sort operation. However, what happens if the table-valued function is already returning the data in the right order? The sort operation introduced by the optimizer is unnecessary. SQL Server 2008 introduces an additional ORDER clause in the CREATE FUNCTION statement that tells the optimizer the expected ordering of the results from the table-valued function:
CREATE FUNCTION [dbo].[InitMethod](@logname
[nvarchar](4000))
RETURNS TABLE (
[timeWritten] [datetime] NULL,
[message] [nvarchar](max) NULL,
[category] [nvarchar](4000) NULL,
[instanceId] [bigint] NULL
) WITH EXECUTE AS CALLER
ORDER ([timeWritten])
AS
EXTERNAL NAME
[SqlServerProject1].[TabularEventLog].[InitMethod]
Note how with this small enhancement, the execution plan for the same query shows no sort operation and the bulk of the cost happens in the CLR function itself (Figure 2).

Spatial Framework
Even though location is a concept prevalent in everything that people do, in recent years location awareness has become an integral part of everyday software applications. With the proliferation of mapping frameworks, GPS, and other location-aware devices, it is increasingly common to encounter spatial data, which often needs to be stored, queried, and reasoned upon. SQL Server 2008 leverages the CLR integration to provide native spatial data support.
Many business applications have some form of location data: sales regions, delivery routes, factory or point of sale locations, or employee addresses. Not only do business managers often require that applications store this information in a database, but business managers also commonly desire the ability to run queries that make use of the spatial semantics: What is the average distance that customers have to the nearest point of sale location? How do sales for a region compare to those from adjacent regions?
SQL Server 2008 supports storing and querying of geospatial data, that is, location data referenced to the earth. Without going into too much detail, two common models of this data are the planar and geodetic coordinate systems. The main distinction between these two systems is that the latter takes into account the curvature of the earth. SQL Server 2008 introduces two new data types: geometry and geography, which correspond to the planar and geodetic models.
SQL Server 2008 introduces two new data types: geometry and geography, which correspond to the planar and geodetic models.
SQL Server implements these data types as CLR types leveraging the User Defined Type infrastructure available in SQL Server 2005. Microsoft registers and includes these types in every installation of SQL Server, making it easy to create columns of either of these types on a table:
CREATE TABLE points_of_sale
(id int, name nvarchar(50), location geometry);
The Open Geospatial Consortium (OGC) defines canonical textual representation for a geometry known as the Well-Known Text (WKT). You can use the WKT to insert data into the points_of_sale table by using a static method that converts from WKT to an actual instance:
INSERT INTO points_of_sale (id, name, location)
VALUES (1000, N'Main Store',
geometry::STPointFromText('POINT (50 50)', 0));
You can later write queries against the table created above to answer business questions. For example, assume that you have a geometry variable that holds a polygon representing a given urban area. You can then write a query to retrieve from the database all points of sale that fall within the given urban area:
SELECT id, name
FROM points_of_sale
WHERE location. STIntersects(@urban_area) = 1;
At the same time, SQL Server 2008 provides new spatial indexing capabilities to speed up processing of queries involving spatial operations. As an example, the following statement would create an index on the table above:
CREATE SPATIAL INDEX SIndx_points_of_sale
ON points_of_sale(location)
WITH ( BOUNDING_BOX = ( 0, 0, 500, 500 ) );
The geometry data type works well for operations performed on instances spanning small areas. When operating on larger distances, you must take into account the curvature of the earth and this is when the geography data type comes into play. This is implemented as a separate CLR class. Even though the usage is very similar to that of the planar data type, methods invoked on the geodetic type operate on an ellipsoidal model of the earth.
Leveraging the integration of the CLR into the database engine, SQL Server 2008 introduces spatial data support, which will make development of location-aware applications become mainstream.
Hierarchical Identifiers
SQL Server 2008 introduces the HierarchyId type, designed to make it easier to store and query hierarchical data. Hierarchical data is defined as a set of data items related to one another by hierarchical relationships-relationships where one item of data is the parent of another item. Common examples include: an organizational structure, a hierarchical file system, a set of tasks in a project, a taxonomy of language terms, a single-inheritance type hierarchy, part-subpart relationships, and a graph of links among Web pages.
Consider the example organizational hierarchy in Figure 3.
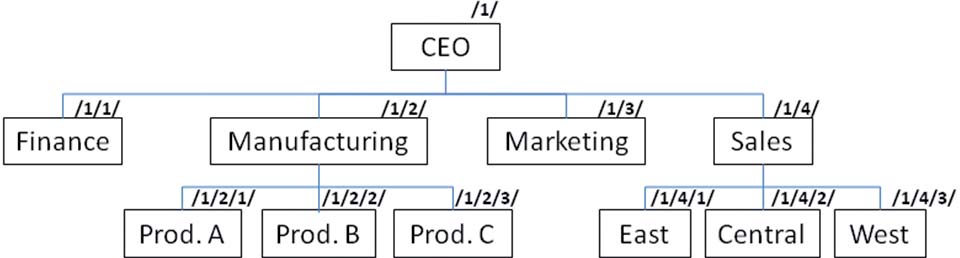
The number sequence indicated at the upper-right corner of every box represents a hierarchical identifier for the corresponding department. One could model this organization using the following table and index:
CREATE TABLE organization (
node hierarchyid primary key clustered,
level as node.GetLevel() persisted,
empid int unique,
name nvarchar(100)
…
)
CREATE UNIQUE INDEX org_idx ON organization
(level, node)
Inserting the CEO record:
INSERT organization (node, empid, name) VALUES
(hierarchyid::GetRoot(), 123, 'Frank Smith')
Adding an employee reporting to a manager:
CREATE PROC AddEmp (@mgrid int, @empid int, @name
nvarchar(100) ) AS BEGIN
DECLARE @mnode hierarchyid, @lc hierarchyid
SELECT @mnode = node FROM organization WHERE
empid = @mgrid
BEGIN TRANSACTION
SELECT @lc = max(node) FROM organization
WHERE @mnode = node.GetAncestor(1)
INSERT organization (node, empid, name)
VALUES (@mnode.GetDescendant(@lc, NULL), @empid,
@name)
COMMIT
END
Microsoft implemented the HierarchyId built-in SQL scalar type as a CLR UDT. Table 1 lists some of the key methods exposed by this type.
You can expect that this new data type will enable the efficient implementation of applications that access hierarchically organized data.
Summary
SQL Server 2008 builds on the CLR integration and scalar data type extensibility foundation laid out in SQL Server 2005. Microsoft has extended the UDT capabilities by allowing UDTs of size up to 2 GB. The SQL Server team have also illustrated two new capabilities-the spatial data type framework and the hierarchical id-built on the scalar UDT extensibility mechanism introduced in SQL Server 2005. These new capabilities will significantly enhance the kinds of applications supported by SQL Server. Other capabilities not described in this paper include often-requested enhancements such as the support for INullable<T> for describing parameters to functions and procedures and table-valued parameters.
