



Unless your battery is really, really good, you’ll eventually want to store your Ink.
In some situations, simple file storage or XML serialization is sufficient for your needs, but in the majority of business applications, you’ll want to move Ink into and out of a relational database. Here’s how.
The SQL standard does not provide an Ink storage type, so the question is what shape the underlying database should take to accommodate your needs? This is a vital question due to another important factor: the persistence formats provided by the Tablet PC SDK do not expose any properties because they’re totally opaque.
You should not depend on the garbage collector to efficiently recycle ink-collecting objects.
If you’ve chosen a database rather than a file system for storage, it’s probable that you’ve done so because you’re interested in some type of querying, filtering, or association with the Ink, so in most situations, you end up explicitly storing some derived data (its location, the recognized text, the color of the strokes, etc.) alongside the Ink.
On the other hand, creating a normal-form representation of all the data associated with the Ink datatype would be daunting and inefficient (a Point table joined to a Stroke table by a many-to-many association table? Good luck with that!). So you face immediate trade-offs. What derived data do you need to store to satisfy your query requirements? Should you store an XML representation of the Stroke in an XML column and, barring XLINQ, end up with an application that combines SQL and XQuery operations? Should you just store the raw representation, re-inflate the Ink on the client-side, and do queries and filters on native Ink objects?
There can be no single correct answer for these questions, although you should bear in mind that Tablet clients have processor, memory, and power constraints that can make large in-memory working sets problematic.
However unlikely it is that you will store just the Ink, let’s leave those issues aside for the first example, and just concentrate on moving Ink in and out of the database. To store Ink, you can use a few different types for your data field. In SQL Server, the best choices for storing a BLOB are varbinary(MAX) or image. For no particular reason other than familiarity, I chose an image field.
In SQL Server, create a database called Ink, a table called Example1, and give the table two fields: Ink of type image and Length of type int.
In Visual Studio 2005, create a new Windows application and drop two buttons onto the resulting Form1. Label them Save and Load. You should see something along the lines of Figure 1.
Although this article was written based on ADO.NET 2.0 and Visual Studio 2005, the Tablet-specific code is based on the Tablet SDK version 1.7 and can be used with either version of ADO.NET. Obviously, the tools and the database-related class names will be somewhat different, depending on whether you’re using the 2003 or 2005 versions of Visual Studio and ADO.NET.
Now add some Ink. The first thing to do is add a reference to the Microsoft Tablet PC API assembly and add a using Microsoft.Ink; statement to your Using block at the top of Form1.cs. With the reference resolved, the next task is to instantiate an InkOverlay object and associate it with a Control.
Although this article was written based on ADO.NET 2.0 and Visual Studio 2005, the Tablet-specific code is based on the Tablet SDK version 1.7 and can be used with either version of ADO.NET.
Because this is playing fast and loose, just associate the InkOverlay with the main form’s surface. Add a member called io of type InkOverlay and a member called isDisposed of type bool. Instantiate io in the Form1() constructor, passing in the Control on which you wish to gather Ink using io = new InkOverlay(this) and set its Enabled property to true. You don’t have to explicitly initialize the isDisposed member because you want its value to be false, the default for bool variables.
It’s important to know that Ink collection relies on non-managed resources, so you should not depend on the garbage collector to efficiently recycle Ink-collecting objects. That should be done by calling the Dispose() method of your InkOverlay and using the Dispose(bool) pattern in your code to control that call. Part of this pattern is that your code must expect Dispose(bool) to be called multiple times, so the call to io.Dispose() is placed within a test assuring that the call is safe:
protected override void Dispose(bool disposing)
{
if (disposing && (components != null))
{
components.Dispose();
}
if (disposing && ! isDisposed && io != null)
{
io.Dispose();
isDisposed = true;
}
base.Dispose(disposing);
Run the program and you should be able to Ink on the main form. Now save the data. Back in Visual Studio, add an event handler to the Save button, and add the code in Listing 1. This is bare-bones code; in a real application, you’d make the acquisition of a database connection and the creation of the SqlCommand the responsibility of a stand-alone class, but this code shows all the components in a single piece.
The first step is to get the BLOB of Ink data: this is done in the first line of the method with the call to io.Ink.Save(PersistenceFormat.InkSerializedFormat). The next chunk of code is the bare basics of getting the data into the database: the instantiation of appropriate ConnectionStringSettings, SqlConnection, SqlCommand, and SqlParameter objects and the use of cmd.ExecuteNonQuery() to perform the actual insertion.
Finally, after the Ink has been pushed up to the database (or, more accurately, the byte[] representing the Ink data), you clear the Ink from the InkOverlay by calling DeleteStrokes() and triggering a repaint with a call to this.Invalidate().
Now add the code in Listing 2 as an event handler for the Load button. The first section of code is database boilerplate. By the time execution gets to the comment Retrieve Ink bytes, you’ve advanced the SqlDataReader sdr to the first row of the database. The three lines following are used to move the data into the inkBytes variable of type byte[].
The last task is to load the InkOverlay with the data represented by inkBytes. There are three rules:
- You cannot programmatically load data into an InkOverlay that is Enabled.
- You cannot load data into a non-empty Ink object.
- Mistakes with Ink sometimes throw cryptic exceptions and sometimes just silently fail, so follow the other two rules.
At this point, Example1 should give you what you need to store and load Ink from the database, except that no matter much data you store in the database, you’ll always retrieve the first record. Let’s fix that.
DataBinding and Ink
Create a new Windows application called Example2. In the Solution Explorer, add your reference to the Microsoft Tablet PC API and add a New Item, choosing Dataset. When the Dataset Designer appears, drag the Ink table from the Server Explorer onto the Designer. Switch back to the Visual Designer for Form1 and drag a Panel, BindingNavigator, a BindingSource, and an instance of your DataSet Designer-generated InkTableAdapter onto the Designer. Set the DataSource of the BindingSource to your just-created DataSet and set the BindingSource of the BindingNavigator to your just-created BindingSource.
Every navigation event creates a new Ink object, even when the corresponding record has been visited before. There’s a definite trade-off here: convenience versus memory and processor resources.
Open the code view for Form1 and add io and isDisposed members as in Example1. Initialize these as before, and additionally, add databinding code like this:
public Form1()
{
InitializeComponent();
io = new InkOverlay(panel1);
io.Enabled = true;
Binding inkBinding =
new Binding("Tag",
bindingSource1, "Ink", true);
inkBinding.Format +=
new ConvertEventHandler(
inkBinding_Format );
panel1.DataBindings.Add(inkBinding);
inkTableAdapter1.Fill(dataSet1.Ink);
}
This code binds the Ink value of bindingSource1 to the Tag property of the object that ends up owning the Binding (it will be panel1, as seen in the second-to-last line of the snippet). The Tag property is a general-purpose field that can be used for custom data-binding, as you’re doing here. You need custom data-binding because you cannot automatically bind the Ink property of the io overlay to the byte[] coming through the BindingSource. (Maybe in a future SDK, there will be an automatic conversion between the two types.) To affect the custom code, attach a ConvertEventHandler to the inkBinding’s Format event. Finally, add the new Binding to the DataBinding of panel1 and fill dataSet1 with the InkTableAdapter.
The ConvertEventHandler delegate you defined is inkBinding_Format:
void inkBinding_Format
(object sender, ConvertEventArgs e)
{
//Is this the DB byte array?
if (e.Value.GetType() == typeof(byte[]))
{
Ink ink = new Ink();
byte[] inkBytes = (byte[])e.Value;
ink.Load(inkBytes);
lock (io)
{
io.Enabled = false;
io.Ink = ink;
io.Enabled = true;
}
}
}
This is reminiscent of the code in Listing 2: a new Ink object is created, an inkBytes variable is filled with the data, and ink.Load() puts them together. Most importantly, you lock and disable the InkOverlay before assigning the newly created Ink to it.
Implement the Dispose(bool) pattern as previously discussed, run the application, and you should be able to move forward and backward through the Ink objects created in the Example1. It’s very convenient, very easy, but be clear about what you have. The database sucked down all of the byte arrays and stored them in DataSet1. Additionally, every navigation event creates a new Ink object, even when the corresponding record has been visited before. There’s a definite trade-off here: convenience versus memory and processor resources.
To avoid client-side resource strain, there are two strategies:
- Client-side caching strategies
- Server-side query strategies
Client-side caching involves creating a Collection of Ink objects when the data is initially brought down from the server and then data-binding to that. This reduces the per-navigation event performance and memory-management penalty, but does not reduce the memory footprint of the DataSet, which is likely to be the largest problem when dealing with hundreds or thousands of returned records.
Improving Performance While Adding Full-Text Search
I’ve come full circle to the initial discussion of trade-offs between normal form, query scenarios, and performance. Neither of the two extremes (Fully normalize your Point data and Store nothing but BLOBs) are likely to be correct. Instead, the right approach varies from application to application.
You could recognize the Strokes as a single whole, but in many applications, an Ink object contains a mix of text and drawing areas.
For the final example, take one piece of data derivable from Ink (the recognized text) and associate it with an Ink store. Full-text search requires a considerable departure from the SQL standard, so this example is highly specific to SQL Server 2005.
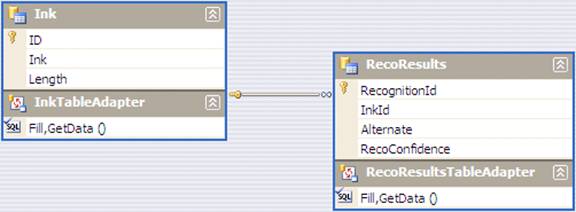
First, add an ID field of SQL type uniqueidentifier to the Ink table and set it to be the primary key. Create another table, RecoResults, which also has a uniqueidentifierId, a foreign key to Ink table (InkId) an ntext field called Alternate, and another called RecoConfidence. (See Figure 2.)
After creating the RecoResults table, open SQL Server Management Studio, right-click on the table, and choose Define Full-Text Index…, to create a full-text index for the Alternate column via a simple wizard.
Back in Visual Studio in the Example1 event-handler for Save, modify the SqlCommand so that it includes a new Guid to ID the Ink. After the Ink is inserted, add a call to a new method:
AddRecognizedText(conn,
(Guid)cmd.Parameters["@Id"].Value,
io.Ink.Strokes);
To call AddRecognizedText(), you need an open SqlConnection, the Guid of the row in which you’ve stored the Ink’s data, and the Strokes collection that represents the pen-down to pen-up strokes in the Ink. In the Tablet PC SDK, recognition is done by a RecognitionContext object. The first block of code in Listing 3 is the boilerplate code to get a default context, here called ctxt.
You could recognize the Strokes as a single whole, but in many applications an Ink object contains a mix of text and drawing areas. (For instance, in an image annotation application, you might draw dent #1 and draw an arrow to the relevant portion of the photo.) Divvying up a Strokes collection into text and non-text is done by the Divider class.
After instantiating the divider object and calling Divide() on it, you end up with a DivisionResult object. Typically, this holds some mix of Drawing, Paragraph, Line, and Segment results, which you iterate by calling ResultsByType() with the appropriate type.
Keeping in mind that you’ve only requested Paragraphs, iterate each DivisionResult and use the ctxt to perform recognition on the Strokes collection of the DivisionResult. If the RecognitionStatus is NoError, you know that you have some recognized text. The handwriting recognition typically returns more than one RecognitionAlternate, each of which has a RecognitionConfidence of Strong, Intermediate, or Poor. The recognized text is available from the ToString() method of the RecognitionAlternate. In Listing 3, the innermost loop inserts each possible Recognition, along with its Confidence, into the RecoResults table of the database. To query this data, use the SQL Server-specific Contains() function. Here’s an example.
SELECT Id, Ink, Length FROM Ink, RecoResults WHERE
RecoResults.InkId = Ink.ID AND
Contains(RecoResults.Alternate, 'foo') AND
RecoResults.Confidence = 'Strong'
An interesting thing about this query is that you cannot use the DISTINCT qualifier, as the presence of an image column disqualifies that argument. So you can either accept duplicates in the return (but remember that a duplicate here means duplicating the byte[] BLOB) or use a two-stage query in a stored procedure (which is certainly what I’d choose in a production application), selecting the DISTINCT InkIds from the RecoResults table and then using those to query the Ink table.
Fill Up With Ink
Although it is not possible to add Ink directly into a database, the techniques shown in this article show how easy it is to convert Ink to and from a BLOB and work on that basis. Databinding is also easy, although as discussed in Example 2, a client-side DataSet containing the entire database’s worth of Ink data is unlikely to be a good idea. Instead, look at your usage and query scenarios, and directly store the Ink-derived metadata in appropriate tables (or, if you prefer, XML columns) as you did in Example3. At that point, recovering the desired Ink is simply a matter of working back to the ink data via standard database joins. It couldn’t be easier!
