


As .NET Core has evolved, Entity Framework Core (EF Core) has grown increasingly sophisticated from one version to the next. EF Core was a ground-up rewrite of the tried-and-true Entity Framework that began its life in 2008 and matured as it grew to version 6, originally released in 2013. The vision with EF Core was to remove barriers to modernization by shedding EF's old code base. The first version was, well, a v1 product, and made great headway allowing teams building modern software with .NET Core to leverage the new EF Core APIs. As EF Core progressed to versions 2.0 and 2.1, it became, as I noted in the July/August 2018 issue of CODE Magazine, definitely production ready. In addition to some long-requested features that EF's architecture had prevented, the second generation of EF Core brought in many (but not all) of the features that EF users had relied on and were missing in the earlier EF Core.
The Big Picture
EF Core 3.0 was released in late September 2019 along with .NET Core 3.0 and ASP.NET Core 3.0. The focus of EF Core 3.0 was to tune it up to be a stable and reliable foundation for its future evolution. Although there are some new and interesting features implemented (for example, support for mapping to Azure Cosmos DB), the new feature list is overshadowed by tweaks, fixes, and the major work item of EF Core 3, which was to revisit how LINQ queries are executed by EF Core.
Some of the work done to improve the APIs did result in something the EF team has been very cautious about since the beginning of EF: breaking changes. These weren't taken lightly. And the team has handled the breaking changes in a really transparent and responsible way. There is a detailed list of the breaking changes in the EF Core documentation (https://docs.microsoft.com/en-us/ef/core/what-is-new/ef-core-3.0/breaking-changes), categorizing each as either low, medium, or high impact. And for each change, you'll find descriptions of the old and new behavior, the reasoning behind the change, and how you can mitigate the effect of those changes in your existing code base. I'll discuss some of the breaking changes in this article, but I recommend reading through that list to be aware of all these items.
The fact that there are a slew of breaking changes is interesting, especially because the team has been so conservative over the iterations. EF Core 2.0 did have a few breaking changes, but with EF Core 3.0, my feeling is that it's like “ripping the bandage off.” If a few were necessary - such as renaming some of the raw SQL methods because of a big problem with interpolated strings–this was a good time to take care of other problems that would also result in breaking changes. In this way, breaking changes become a such a big part of the message for EF Core 3.0 that, hopefully, developers will pay close attention to them.
One other important impact that .NET Core 3.0 has had on EF is related to the new capability of formerly .NET Framework-only applications, such as Windows Forms and WPF, now being able to run on .NET Core 3.0. Many of these older solutions use Entity Framework, so EF6 also needed to run on .NET Core. Starting with the newly released EF 6.3, not only can you use EF6 in .NET Framework apps, but also with .NET Core 3.0 apps. This is possible because, in addition to running on .NET 4.0 and .NET 4.5, EF6.3 is cross-compiled to target .NET Standard 2.1. To test this out in an extreme case, I built a small ASP.NET Core 3.0 sample app in VS Code on my MacBook using EF 6.3 for its data access. You can see the code and further explanation at https://github.com/julielerman/Data-Points-August-2019-EF6-Core3.
Changes to Development Dependencies
EF Core 3.0 depends on .NET Standard 2.1 and no longer supports .NET Standard 2.0. This is important to understand because .NET Standard 2.0 is what .NET Framework relies on. You can't use .NET Framework with .NET Standard 2.1. For example, see this EF Core 2.1 tutorial in the official docs (https://docs.microsoft.com/en-us/ef/core/get-started/full-dotnet/new-db), which walks you through creating a .NET Framework 4.6.1 console app with EF Core 2.0. With EF Core 3.0, you'll need to use .NET Core application types. Both WPF and Windows Forms have moved to NET Core 3.0, so you do have a wide variety of application types available - these two as well as console and ASP.NET Core 3.0 apps. Currently Xamarin and UWP aren't running on .NET Standard 2.1, but they will be in the future, at which time, you'll be able to use the new EF Core in those apps as well.
.NET Standard 2.1 is installed as part of .NET Core 3.0 runtime. So, if you have the SDK installed for development, or the runtime installed for running apps, you'll have the right version of .NET Standard.
It's also important to know that Visual Studio 2017 doesn't support .NET Standard 2.1. If you're using Visual Studio or Visual Studio for Mac, you'll need the 2019 version. And it's recommended that you have the latest update as well. Visual Studio Code with the latest OmniSharp extension supports .NET Standard 2.1.
EF Core and Tooling Packages
Getting EF Core into your apps and using the Migrations commands has changed in a big way.
The Microsoft.EntityFrameworkCore, Microsoft.EntityFrameworkCore.SqlServer, and a few other EF Core NuGet packages were included with the Microsoft.AspNetCore.App (formerly Microsoft.Aspnet.All) package reference in ASP.NET Core projects. If you were building other types of projects, you had to explicitly reference the relevant EF Core package(s). Starting with version 3, there's a consistent experience, which is that you need to explicitly specify the EF Core package(s) you want - no matter what type of project you're building. EF Core won't be “served up” with the ASP.NET packages. Nor will you have extraneous packages such as SqlServer and Relational if you don't need them.
The EF Core command-line tools have been moving around across versions. In the first versions of .NET Core, you had to reference the DotNetCliToolReference package in order to use EF's CLI migrations tools, such as dotnet ef migration add. Then the EF tools were moved into the .NET Core 2.1 SDK, so they were just there. That meant that the release cycle of the EF tools was tied to the release cycle of the SDKs. Starting with 3.0, the EF tools are independent of the SDK and need to be installed explicitly. Something I kept forgetting to do on my various development computers but thankfully, the error messages were kind enough to remind me. You have two ways to ensure they are available.
The first is to install the dotnet-ef tools globally onto your development computer with:
dotnet tool install -g dotnet-ef --version 3.0.0
The Great LINQ Query Overhaul
Although one important improvement to LINQ queries has the possibility of breaking many applications, there were a number of changes made to improve LINQ queries overall. The driver was to fix problems related to evaluating part of queries on the client. The original implementation was dependent on re-linq, which provides higher-level abstractions of LINQ expression trees. But this was preventing the EF team from making the types of changes required to fix the evaluation problems. So re-linq was removed and everything broken by this removal needed to be rewired. Let's take a look at the client evaluation problem that started this important transition.
EF Core introduced the ability to internally break queries apart, discover which pieces could be translated to SQL and executed, and then which pieces of the query needed to be evaluated on the client in memory using the results of the server-side (database) query. Although this became the default behavior for queries, it was possible to tweak a DbContext configuration to make any query that contained client-side logic to throw an exception instead.
This feature was meant to simplify scenarios where you wrote LINQ queries that combined logic to be translated into SQL and executed on the server with logic that needs to be executed locally. Imagine, for example, that you have a local method to reverse a string:
private static string Reverse (string value)
{
var stringChar = value.AsEnumerable ();
return string.Concat(stringChar.Reverse());
}
You could use that as part of a LINQ query:
_context.People.Select (p => new {p.FullName,Reverse=Reverse(p.FullName)}).FirstOrDefault ();
EF Core is able to determine which parts of the query can be translated to SQL and which can't. It passes the SQL on to the database for execution, then performs the rest of the evaluation (e.g., Reverse) on the results after they've been returned from the database.
Client evaluation can also let you use the local logic in your query filters. Imagine using the same Reverse method as the predicate of a Where LINQ method.
_context.People.Where(p =>Reverse(p.FirstName)=="eiluJ").ToList();
Because EF Core can't translate Reverse into SQL, it first executes what it can to get the results and then performs the Reverse filter on the result set. With small sets of test data, this seemed innocuous. However, after releasing this into production where your People table might contain thousands or more rows, the query returns every row from the table into memory before performing the filter locally.
The earlier version did provide a warning in the logs that part of the query would be evaluated locally:
warn: Microsoft.EntityFrameworkCore.Query[20500]
The LINQ expression
'where (Reverse ([p].FirstName) == "eiluJ")'
could not be translated and will be evaluated
locally.
But this was too easy to miss. A lot of developers were experiencing performance and memory problems because they didn't realize that the filtering (or other processes such as grouping or sorting) was happening on the client. This could be because perhaps they weren't paying attention to the logs or these messages were buried among too many events in the logs.
For EF Core 3.0, after much deliberation, the decision was made to change the behavior so that EF Core throws an exception when queries contain client-side evaluation.
System.InvalidOperationException:The LINQ ex-
pression '(p) => ReverseString(p.FirstName) ==
"eiluJ"' could not be translated. Either rewrite
the query in a form that can be translated, or
switch to client evaluation explicitly by insert-
ing a call to either AsEnumerable(),
AsAsyncEnumerable(), ToList(), or ToListAsync().
See https://go.microsoft.com/fwlink/?linkid=2101038
for more information.
Although this switch of the configuration was the first step in this change to easily expose client-side evaluation, the team did much more than simply change the default. They revised how LINQ works when evaluating queries. As per the documentation, they made “profound changes to how our LINQ implementation works, and how we test it.” With the goal “to make it more robust (for example, to avoid breaking queries in patch releases), to enable translating more expressions correctly into SQL, to generate efficient queries in more cases, and to prevent inefficient queries from going undetected.”
With respect to the earlier configuration to either throw an exception or log a warning, this option no longer exists. Client evaluation will always throw an exception.
Changing how LINQ queries are translated by EF Core was a major undertaking for the team. And they also had to ensure that the great variety of ways you can construct a query would continue to be possible. The team maintained a detailed and public to-do list of all the previously supported capabilities and their working (or not yet working) state in EF Core 3 as they iterated through the various previews. There is also a great explanation of the proposal) for these changes on GitHub (https://github.com/aspnet/EntityFrameworkCore/issues/12795#issuecomment-410288296).
The key is to be aware of the portion of the query that will be evaluated on the client and write the query (or multiple queries) in a way that acknowledges that.
There's one other acceptable way to include client-evaluated logic in the query that's not mentioned in the exception. If the method is in the final projection of the query, it will succeed. The first query I showed above, with the Select statement, will succeed in EF Core 3.0 because the Select method is the last projection being called in the query. There's no need to move the executing method before Select. Although, in the case of that query, it won't change anything about the execution or the results.
_context.People.ToList().Select(p => new {p.FullName, Reverse=ReverseString(p.FullName)});
For the second example, where I was using Reverse to filter in a Where method, you need to rethink the query completely. Putting ToList() in front of the Where() method succeeds. However, it quietly forces the EF to retrieve all of the Person rows from the database. In this case, the code is pretty explicit and you should be aware of the cause and effect. Performance tests and logging are also your friends!
In the case of my particular query, it's an easy change: Just filter on the first name without it being reversed.
The effect of moving the executing method is most obvious, I think, with OrderBy.
This method will throw an error in EF Core 3.0
_context.People
.OrderBy (p => ReverseString (p.FullName))
.ToList ();
Calling ToList and then ordering the results explicitly succeeds:
_context.People
.ToList()
.OrderBy (p => ReverseString (p.FullName));
Keep in mind that for frequently used methods that you want to incorporate into queries, you have the option of creating scalar functions in your database and mapping them with DbFunctions. I created a module about this feature in one of my Pluralsight courses called EF Core 2 Beyond the Basics: Mappings (https://bit.ly/2LppcMj)
The bottom line is that the LINQ query overhaul accomplished a number of important goals. One was to relieve the side effect of the client-evaluation creating performance and memory problems. Another was to simplify testing for provider writers. Most importantly, the rewrite has set up a foundation to make additional translations easier to implement and eventually improve performance as well.
The ripple effect of the change required that they test every query translation possible. My examples were simple, but imagine this with relationships or owned entities across many providers.
Renamed Raw SQL Methods
Another pair of breaking changes important to highlight are:
- The method names for raw SQL queries have changed.
- The method names for raw SQL queries were moved from being extension methods on
IQueryable<T>to extension methods onDbSet<T>. - As a result of the extension method move, you can only call the extension methods at the beginning of a query on the DbSet.
EF Core 2.0 enabled the use of interpolated strings in the raw SQL methods. When executing the methods, EF Core didn't always interpret the interpolation as expected. In some cases, this problem could lead EF Core away from its parameterized query protection.
One example of the unexpected behavior is that ExecuteSqlCommand was able to parameterize interpolated strings that are part of the method call but not if they were passed in via another variable. This was a behavior of C# that eagerly transforms any interpolated string it sees into a string. Yet the raw SQL methods expect a FormattableString to be passed in. The next snippet is an example that throws an exception in EF Core 2.2. At least that's a better response than allowing a SQL Injection attack. Line wraps create yet another problem but imagine that myCommand is on a single line.
var first = "Smit";
var last = "Patel";
var myCommand = $"INSERT INTO People (Firstname,LastName) VALUES ({first}, {last})";
_context.Database.ExecuteSqlCommand(myCommand);
Where myCommand becomes the string:
INSERT INTO People (Firstname,LastName)
VALUES (Smit, Patel)
The database thinks Smit and Patel should be column names. You can see examples of the varying behavior in this GitHub issue: https://github.com/aspnet/EntityFrameworkCore/issues/10996.
The bottom line is that the team needed to handle plain strings differently from interpolated strings and the most clear-cut way to ensure that developers would get the results they expected was to remove the generally named methods (FromSql, ExecuteSqlCommand, and their async counterparts) and replace them with explicit methods (FromSqlRaw and FromSqlInterpolated, ExecuteSqlRaw, etc.). The Interpolated methods take a FormattableString object as the parameter.
The last line of the above example changes to:
_context.Database.ExecuteSqlInterpolated(myCommand);
You'll get a compiler error because myCommand is a string. Just change that to explicitly be a FormattableString.
FormattableString myCommand = $"INSERT INTO People ..."
Realigning the QueryType Implementation
Query types were introduced in EF Core 2.1 to enable querying data into types that don't have keys. The simplest example is having a type that maps to a database view. This is such a great addition to EF modeling. I wrote about query types in “Entity Framework Core 2.1: Heck Yes, It's Production Ready!” (https://www.codemag.com/Article/1807071/Entity-Framework-Core-2.1-Heck-Yes-It%E2%80%99s-Production-Ready!) in the July/August 2018 issue of CODE Magazine. The implementation was somewhat confusing. The feature introduced “cousins” to DbSet (DbQuery) and EntityTypeBuilder (QueryTypeBuilder). I wrote about query types and dug even deeper in my EF Core 2.1: What's New course on Pluralsight, and found it a bit convoluted to explain the ins and outs of configuring the DbContext and writing LINQ queries. In the long run, most of the rules are the same as working with DbSets and EntityTypeBuilder. So the EF Core team decided that for EF Core 3.0, they'd make everything an entity whether it has keys or not. The underlying behavior to differentiate entities with keys and without keys still exists and you can indicate keyless entities to the ModelBuilder simply by configuring an entity as having no key with ModelBuilder<Entity>().HasNoKey().
With this, you can use DbSets and EntityTypeBuilders for all the mapped types and not have to worry about the extra set of rules and classes that went along with query types.
Reverse Engineering Database Views into Entities
Now that there are keyless entities, it was a lot easier for the team to add database views into the scaffolding process.
Here's a simple view that I added to my database.
CREATE VIEW [dbo].[PeopleNamesView]
AS SELECT FirstName,LastName FROM People
You can scaffold with PowerShell in VS or with the CLI. Here's a CLI command I used:
dotnet ef dbcontext scaffold "Server=(localdb)\MSSQLLocalDB;
Database=PeopleDb"
Microsoft.EntityFrameworkCore.SqlServer
This generated a class:
public partial class PeopleNamesView
{
public string FirstName { get; set; }
public string LastName { get; set; }
}
More importantly, in the DbContext, it added a DbSet :
public virtual DbSet<PeopleNamesView> PeopleNamesView { get; set; }
And it created a mapping for the entity that specifies that it‘s keyless and maps to a view.
modelBuilder.Entity<PeopleNamesView>(entity =>
{
entity.HasNoKey();
entity.ToView("PeopleNamesView");
});
Now the view can be used as a keyless entity.
The New Azure Cosmos DB Provider
In my opinion, the most interesting (and to some, perhaps the most curious) feature introduced in EF Core 3.0 is the ability to use EF Core to interact with an Azure Cosmos DB database. The provider's NuGet package name is Microsoft.EntityFrameworkCore.Cosmos. For those of you unfamiliar with this database, it's Microsoft's cloud-based multi-model NoSQL database service. The data is stored as JSON documents and the underlying database engine allows you to interact with your data using SQL, MongoDB, Cassandra, Gremlin, or Table (key/value pair) APIs. I've done a lot of work with Azure Cosmos DB over the years, mostly using the SQL query language and sending the queries either with the NodeJS SDK or the .NET Client APIs.
Some may be curious why this new Cosmos DB provider exists for EF Core: Why use an ORM (Object Relational Mapper) to map to a data store that isn't relational? For developers accustomed to working with EF to interact with their data store, it's an easy leap to use EF when they want to target Cosmos DB. Additionally, having used the NodeJS SDK and .NET Client API, I really like the fact that EF Core can take care of all of the redundant set up for you that normally requires a lot of additional code to define objects to represent the Cosmos DB connection, the database, the containers and even the queries. With the EF Core provider, you can just define the connection settings in the options builder.
optionsBuilder.UseCosmos("endpoint", "account key", "databasename");
The endpoint and account key are tied to the pre-existing Cosmos DB account and the database name is for one that already exists or one you will let EF Core create. I've created variables for the endpoint and the accountkey (whose value I've abbreviated). The database name (not yet existing) will be CosmicPeople.
var endpoint = "https://codemagdb.documents.azure.com:443/"
var key = "S8nBvUYAQ4ZKboQ1Q97RPDuzlBQzV . . ."
optionsBuilder.UseCosmos(endpoint,key, "CosmicPeople");
With this in place, you can write and execute LINQ queries, and add, update, or delete data just as you would with any other EF Core provider. And all of these tasks leverage the investment you've already made in learning EF.
One other common question is about this provider's ability to create a new Cosmos DB database on your behalf. EF Core does this just as it would with any other database provider. However, like those other databases that can create a database for you on an existing database server, the Cosmos DB provider is only able to create databases on an existing Cosmos DB Account. And it's the account whose settings are critical with respect to cost and performance. EF Core can't affect those settings. Because the Cosmos DB APIs aren't (yet) interchangeable, that account does need to be created for the SQL API.
Each database has one or more containers and, because Cosmos DB is designed to handle large amounts of data, partitioning is important as well.
It's important to understand how different this is from a relational database. Data is stored as JSON documents in the database. A container isn't the same as a table. Differently structured documents can be stored in a single container as needed and a single document can contain a hierarchy of data.
It's important to understand how different this is from a relational database.
Some important defaults of EF Core's Cosmos provider to be aware of are:
- EF Core associates a single
DbContextto a container within the database. You can use theToContainer()mapping to associate specific entities with containers. - The container name is based on the context name, although you can use the
HasDefaultContainerName()method to change the name. - The partition key is null by default and all data is stored in the default partition of the database. You can configure entities to use specific partition keys with
HasPartitionKey()based on a property or a shadow property of an entity. If you configure one entity in a context, you need to configure all of them. - The provider injects a Discriminator property to tag each document with the name of its type so that EF Core can retrieve data.
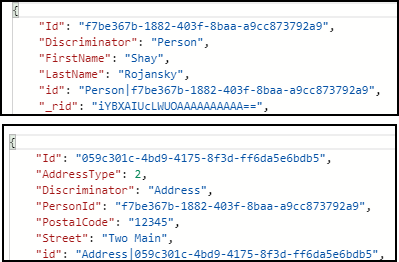
Entities are stored as separate documents, which means that you'll need to leverage some relational concepts in order to reconnect that data when you retrieve it. For example, if I build a Person object with an Address in the Addresses property such as:
var person = new Person {Id = Guid.NewGuid(), FirstName = "Shay", LastName = "Rojansky" };
person.Addresses.Add(new Address {Id= Guid.NewGuid(), AddressType = AddressType.Work, Street = "Two Main", PostalCode = "12345"} );
_context.People.Add(person);
_context.SaveChanges();
Figure 1 shows the two stored documents that result from this code. Notice the Discriminator property that EF Core added to each document.
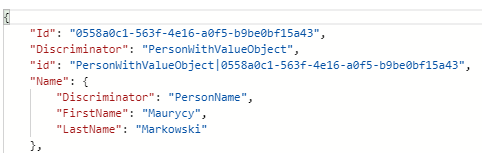
Although the related entities aren't stored together, EF Core's owned entities get stored as a sub-document. For example, here's a new class (PersonWithValueObject) with a Name property whose type (PersonName) is configured as an owned entity. My code creates a new PersonWithValueObject with the Name property defined.
var person = new PersonWithValueObject {Id =Guid.NewGuid(), Name=new PersonName("Maurycy","Markowski")};
Figure 2 shows that EF Core stored the owned entity as a sub-document. It still uses a Discriminator so that EF Core can properly materialize the object when you retrieve it with LINQ queries.
There's more to learn, of course, about interacting with Cosmos DB. You can check out the documentation as well as my two-part article about an earlier preview of the Cosmos provider in MSDN Magazine (https://msdn.microsoft.com/en-us/magazine/mt848702).
Additional Notable Changes
Although I can't describe every change and new feature, I'll briefly highlight a few more that are interesting and could apply to a lot of use cases.
Support for New C# 8.0 Features
C# 8 brings us some new super cool features and EF Core 3.0 is there for some of them. For example, support for asynchronous streaming, thanks to await foreach and the standard IAsyncEnumerable
Nullable and Non-Nullable Reference Types, also new to C#8, are supported by EF Core 3.0 as well. This C#8 feature allows you to explicitly signal permission (or forbid) to allow nulls into reference types like string. EF Core recognizes nullable reference types. This works for mappings and queries but not yet for scaffolding from an existing database
For example, if I add a new nullable string property to Person:
public string? Middle { get; set; }
The type is recognized by EF Core. A relevant column is created for the database table. And queries handle the nullable reference type as well, such as in the following query. Being new to nullable reference types, I expected to use p.Middle.HasValue() in the query but nullable reference types don't have the same behaviors as nullable value types like int?.
var people = _context.People.Where(p =>p.Middle!=null).ToList();
Interceptors
EF6 brought the great capability of intercepting events along the query pipeline, which is a feature we've been eagerly awaiting to return in EF Core. And EF Core 3.0 brings new APIs to perform the same type of functionality.
There are four classes that implement the IInterceptor. They're currently limited to the Relational providers.
- DbConnectionInterceptor
- LazyLoadingInterceptor
- DbTransactionInterceptor
- DbCommandInterceptor
Each class surfaces a slew of methods that you can tap into. Like EF6, you begin by defining an interceptor class that inherits from one of the above classes. Then you can register it to a provider on a particular context. For example:
using System.Data.Common;
using Microsoft.EntityFrameworkCore.Diagnostics;
public class MyInterceptor:DbCommandInterceptor{}
You can then override one of the many methods of the interceptor. For DbCommandInterceptor, you have access to methods such as CommandCreated, CommandCreating, and NonQueryExecutingAsync. If you used interceptors in EF6, these will be familiar. DbCommandInterceptor.ReaderExecuted gives you access to the command as well as the results of the executed command in the form of a DbDataReader.
public override DbDataReader ReaderExecuted( DbCommand command, CommandExecutedEventData eventData, DbDataReader result)
{
//do something
return result;
}
You can register one or more derived interceptors using a provider's AddInterceptors method. Here, I'm using the DbContext's OnConfiguring method.
optionsBuilder.UseSqlite("Filename=CodePeople.db").AddInterceptors(new MyInterceptor());
In ASP.NET Core, you'd do this as you register a DbContext in the Startup's ConfigureServices method, e.g.:
services.AddDbContext<PersonContext>(options => options.UseSqlServer(connectionstring).AddInterceptors(new MyInterceptor());
There are other ways to register interceptors, but this will likely be the most common approach.
N+1 Queries for Projections and Includes
Projections and Includes always caused N+1 queries to get the related data, even in cases where expressing the query in a single SQL statement seemed like the obvious thing to do. EF Core 3.0 fixes this problem.
In earlier versions of EF Core, you might have an Eager Loaded query such as:
context.People.Include(p=>p.Addresses).ToList();
This first executes a query to get the person types and then executes a second query to get address types using an inner join to relate them to the people table.
In EF Core 3.0, the query is much simpler, a single LEFT JOIN query:
SELECT "p"."Id", "p"."Dob", "p"."FirstName",
"p"."LastName", "p"."Middle", "a"."Id",
"a"."PersonId", "a"."PostalCode", "a"."Street"
FROM "People" AS "p"
LEFT JOIN "Address" AS "a"
ON "p"."Id" = "a"."PersonId"ORDER BY "p"."Id", "a"."Id"
The N+1 problem also affected projection queries where a single related object was part of the projection, such as this query where I'm retrieving only the first address for a person.
_context.People.Select(p => new { p.LastName, OneAddress = p.Addresses.FirstOrDefault() }).ToList();
This resulted in four queries! The same happens if you get a list of the related data, e.g.:
_context.People.Select(p => new { p.LastName, AllAddresses = p.Addresses.ToList() }).ToList();
In EF Core 3.0, both of these queries are now reduced to a single query using a LEFT JOIN. The query for the single related result is a little more complex (to my non-DBA eyes) but still does the trick!
Some Personal Favorites
There are three final things I want to call out because they make me happy.
The first is related to something I discovered when trying things every which way for one of my EF Core courses on Pluralsight. In previews of EF Core 2.0, the change tracker wasn't fixing up navigations from projection queries that included related data, such as the Person with Address queries above. The Addresses were retrieved and tracked by the change tracker, but if you examined the resulting Person types, the Addresses property was empty. This was fixed before EF Core 2 was released but there was a regression in a subsequent minor version (https://github.com/aspnet/EntityFrameworkCore/issues/8999) that caused a variation on the original problem. If a projection included an entity along with a filtered set of related entities, those entities weren't attached to the parent when the change tracker performed its “fix up.” Here's an example of a query exhibiting this problem. The projection returns person types and filtered related addresses.
_context.People.Select(p => new {Person=p, Addresses = p.Addresses.Where(a => a.Street.Contains("Main")) }).ToList();
I was happy to have a notification pop into my email inbox a few weeks before EF Core 3.0 was released telling me that the fix had finally been implemented.
The second change is tiny but fixed a hugely annoying behavior. The implementation of SQLite that was used by earlier versions of EF Core didn't have foreign key enforcement on by default. So EF Core had to change at the start of every DbContext interaction with the database. It did so by sending the command PRAGMA foreign_keys=1. For me, it was less of a performance issue than clutter in my logs. EF Core 3 now uses a new implementation of SQLite (by default), which has foreign key enforcement on by default.
And last but not least, a fix that is near and dear to my heart because it improves my ability to use Domain-Driven Design value objects. In earlier versions of EF Core, entities that are dependents in a relationship, with their properties mapped to the same table as the principal in the relationship, couldn't be optional. Under the covers, EF Core treats owned entities (which aren't true entities and aren't truly related) as if they were dependent entities. Owned entities are classes that don't have their own key property, are used as properties of entities, and are mapped to their owner using either the OwnsOne or OwnsMany mapping in the DbContext. Owned entities are how EF Core is also able to map value objects in the DDD aggregates.
The non-optional dependent meant that, regardless of your business rules, a value object property could never be null. There was a workaround for this which I wrote about in MSDN Magazine (https://msdn.microsoft.com/magazine/mt846463). Thankfully, EF Core 3.0 fixes the base problem and I'm able to remove the workaround from my code. Dependents that share a table with principals and owned entities (and therefore value objects) are now optional and can now be left null if your business rules allow that. EF Core can persist and retrieve the parent, comprehending the nulls.
Final Thoughts
Watching the EF team go through the process of reworking EF Core for this version has been impressive. Tightening up the APIs and embarking on the revision to the query pipeline was a major undertaking. They shared with us detailed weekly status updates (https://github.com/aspnet/EntityFrameworkCore/issues/15403) and even shared the burn-down chart that they used internally to track their progress.
Setting a goal for themselves of making EF Core 3.0 be a solid foundation for future innovation is a great indication of the planned longevity of EF Core.
And they brought EF 6 (with version EF 6.3) into the .NET Core family as well, so those of us with investments in EF6 can continue to benefit from that.
