


I've been on both sides of the interview table. I've interviewed other developers, either as a hiring manager or as part of an interview team. I've also sweated through interviews as the applicant. I've written Microsoft certification questions, interview test questions, and have taken plenty of tests. Once I even pointed out where the answer sheet for a company's test questions was incorrect. So I'm going to borrow from those experiences in this installment of Baker's Dozen, by giving readers a chance to take a test on SQL Server and Transact-SQL topics.
A New Era of Baker's Dozen Articles
After roughly ten years and roughly 50 Baker's Dozen articles, I've decided that it's time to shake it up a little. For now and (at least) the immediate future, I'm going to present 13 test-style questions (or scenarios) on database topics, and see how readers do with the questions. Even if you're not specifically looking for ideas for test questions, the example questions might help you with various database programming tasks.
What's on the Menu?
This section lists the 13 test question topics in this article. With the exception of the last item, I'd categorize these questions as for beginning to intermediate developers. These are the types of interview questions I'd expect a mid-level database developer to be able to answer. In the first half of this article, I'll cover the test questions and in the second half, I'll cover the answers. Although this magazine isn't an interactive software product that requires you to answer before seeing the results, you'll at least have a chance to read the questions and try to answer unaided. That is, of course, if you can avoid peeking into the second half of the article to see the answers!
Several of the questions are multiple choice questions, where responses are either 100% correct or 100% incorrect. In a few cases (such as the topics on NOT IN vs NOT EXISTS and the MERGE statement), they're meant to trigger discussions exploring the knowledge and thought process in the response.
Here's the list:
- Scalar variables
- Comma-separated values from multiple rows subquery
- Date Arithmetic with Datetime and Date Data Types
- Subquery Syntax and results
- SCOPE_IDENTITY and @@IDENTITY
- Features of SQL Server Views
- The BETWEEN statement
- IDENTITY values and uniqueness
- Basic Syntax with VARCHAR
- NOT IN vs NOT EXISTS and Performance
- The REPLACE function
- Rules on indexes
- Baker's Dozen Spotlight: Advanced use of MERGE
1: Scalar Variables
Suppose you create a SQL Server table with the following DDL (data definition language):
CREATE TABLE dbo.ControlTable
(ControlID int identity, CompanyName varchar(100))
GO
Now suppose someone inserts a single row into the table. Someone else intends to update the row to adjust the company name, but accidently winds up inserting a new second row instead of updating the first row. Now you'll have two rows in the table, when you really wanted only one.
INSERT INTO dbo.ControlTable
(CompanyName)
VALUES ('Company ABC')
-- Someone needed to issue a correction
-- but accidently wound up inserting a new row
INSERT INTO dbo.ControlTable
(CompanyName)
VALUES ('Company ABC, INC')
Now suppose that you want to populate a scalar variable for the company name. You write two simple queries that read from the table and populate a scalar variable.
Example A
DECLARE @CompanyNameString varchar(100)
SELECT @CompanyNameString = CompanyName FROM ControlTable
SELECT @CompanyNameString
Example B
DECLARE @CompanyNameString varchar(100)
SET @CompanyNameString = (SELECT CompanyName FROM ControlTable )
SELECT @CompanyNameString
What are the results?
- Both Examples A and B generate an error because both examples are trying to read multiple rows into a single scalar variable.
- Example A generates an error message, and Example B returns one of the two
CompanyNamevalues. - Example A returns one of the two
CompanyNamevalues, and Example B generates an error message. - SQL Server converts the variables in both examples to table variables and returns both
CompanyNamevalues.
2: Comma-Separated Values from Multiple Rows
Suppose you create a SQL Server table with the following DDL, and then insert the following rows:
CREATE TABLE dbo.TestPurchases
( PurchaseID int identity,
Purchaser varchar(100),
PurchaseAmount money,
PurchaseReason varchar(100))
GO
INSERT INTO dbo.TestPurchases VALUES
('Kevin',50, 'SQL Book'),
('Kevin', 60, 'Steak dinner'),
('Steve', 55, '.NET Book'),
('Steve', 45, 'Music CDs'),
('Steve', 35, 'Lunch')
You want to build the result set shown in Figure 1: one row per Purchaser with the PurchaseReason column concatenated.

How can you accomplish this? (Select only one answer.)
- Use the T-SQL FOR XML PATH ('').
- Use the T-SQL STRINGCONCAT function.
- Use the SQL Server CLR and a .NET function.
- T-SQL cannot accomplish this. You'd need to use a reporting tool.
3: Date Arithmetic with DateTime and Date Data Types
Suppose you have two variables: a DateTime variable and a Date variable. You try to add a value of (1) day to both variables.
DECLARE @TestValueDateTime DATETIME = GETDATE()
DECLARE @TestValueDate DATE = GETDATE()
SELECT @TestValueDateTime + 1 -- Using DateTime
SELECT @TestValueDate + 1 -- Using Date
By default in SQL Server, what does SQL Server generate for the two SELECT statements after the code executes? (Select only one answer.)
- Both SELECT statements generate an error message.
- The first SELECT statement adds a single minute to the value of the
DateTimevariable, and the second SELECT statement adds a day to the value of theDatevariable. - Both SELECT statements add a single day to whatever was in each of the two variables.
- The first SELECT statement adds a day to whatever was in the
DateTimevariable, and the second SELECT statement generates an error.
4: Subquery Syntax and Results
Suppose you create a basic Vendor Master table and a related Order table, with orders for vendors. Here's the DDL and some test data. The data stores two vendors in the master table and two orders in the order table (one for each vendor).
CREATE TABLE dbo.VendorMaster
(VendorPK int, VendorName varchar(100))
CREATE TABLE dbo.OrderTable
(OrderID int, VendorFK int,
OrderDate Date, OrderAmount money)
INSERT INTO dbo.VendorMaster
VALUES (1, 'Vendor A'),
(2, 'Vendor B')
INSERT INTO dbo.OrderTable VALUES
(1, 1, cast('1-1-2008' as Date), 100),
(2, 2, cast('1-1-2009' as Date), 50)
You want to write a query that returns the vendors that have at least one order in the year 2008. How many rows will SQL Server return for the following query?
SELECT * FROM dbo.VendorMaster
WHERE VendorPK IN
(SELECT VendorPK FROM dbo.OrderTable
WHERE YEAR(OrderDate) = 2008)
By default in SQL Server, what does SQL Server store for the two variables after the code executes? (Select only one answer)
- One row
- Two rows
- Zero rows
- The query generates an error message.
5: SCOPE_IDENTITY() and @@IDENTITY
Suppose you create the following test table, which contains an identity column that SQL Server generates. You insert a row into the table.
CREATE TABLE dbo.TestTable1
(IdentityKey int identity, Name varchar(100))
INSERT INTO dbo.TestTable1 values ('Kevin')
You'd like to know and capture what SQL Server generated as an identity value for the INSERT, regardless of any other processes. You use both the SCOPE_IDENTITY() function and the @@IDENTITY system global variable.
SELECT SCOPE_IDENTITY()
SELECT @@IDENTITY
Both SELECT statements return a value of 1.
Can you name one scenario where SCOPE_IDENTITY() and @@IDENTITY don't return the same values? In other words, describe a situation where one statement returns the desired value of 1 and the other returns something other than a value of 1.
6: Features of SQL Server Views
Suppose someone creates a view against the Microsoft AdventureWorksDW database. You can assume that the tables FactInternetSales and DimDate exist in the database. You can also assume referential integrity between the two tables on the DateKey/ShipDateKey JOIN condition and that the column references are correct.
CREATE VIEW dbo.vwSalesByYear
@YearToRun int
as
SELECT FactInternetSales.ProductKey,
SUM(FactInternetSales.SalesAmount) AS AnnualSales
FROM FactInternetSales
JOIN DimDate on ShipDateKey = DateKey
WHERE DimDate.CalendarYear = @YearToRun
GROUP BY FactInternetSales.ProductKey
ORDER BY FactInternetSales.ProductKey
Assuming that all column and table name references are correct, how many problems do you see with this SQL Server view? (Select only one answer.)
- The view has one issue that generates an error.
- The view has two issues that generate errors.
- The question does not provide enough information.
- The view has no issues and will execute properly.
7: The BETWEEN Statement
Suppose you create a test table of LastName values. You insert nine rows into the test table, and then create an index on the LastName column.
CREATE TABLE dbo.NameTest
( LastName varchar(50))
INSERT INTO dbo.NameTest
VALUES ('Anderson'), ('Bailey'),
('Barry'), ('Benton'),
('Boyle'), ('Canton'),
('Celkins'), ('Cotton'),
('Davidson')
CREATE INDEX LastName ON dbo.NameTest (LastName)
You execute the following query:
select * from NameTest
WHERE LastName BETWEEN 'B' AND 'C'
How many rows does this query return? (Select only one answer.)
- Four rows
- Six rows
- Seven rows
- Zero rows
- The query generates an error message.
8: IDENTITY Values and Uniqueness
Suppose you create a table with the following DDL structure, including an identity column:
CREATE TABLE dbo.TestIdentity
(IdentityValue int identity,
IdentityName varchar(100))
Now suppose you insert two rows into the table. If you query the table after executing the inserts, you clearly see the values of 1 and 2 for the identity values.
INSERT INTO dbo.TestIdentity (IdentityName)
VALUES ('Kevin'), ('Steven')
SELECT * FROM dbo.TestIdentity
Yes or No, will the identity designation in this situation guarantee uniqueness for the IdentityValue column in this table?
9: Basic Syntax with VARCHAR
Suppose you query the Purchasing.Vendor table in AdventureWorks. The first eight rows (in Name order) look like Figure 2:
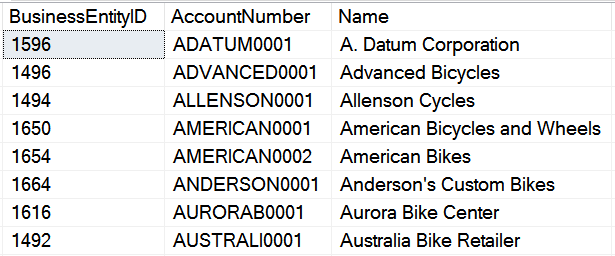
Suppose you want to retrieve all rows where the vendor name begins with the word “American.” You execute the following lines of code that uses the LIKE statement and the wild card character ('%') at the end of the lookup value.
DECLARE @TestValue varchar
SET @TestValue = 'American%'
select * from Purchasing.Vendor
where name like @TestValue
How many rows will the query return?
10: NOT IN vs NOT EXISTS and Performance
For years, developers and DBAs have debated the use of IN vs EXISTS, as well as NOT IN vs NOT EXISTS. This question looks at the performance differences between the two competing language statements.
Suppose you're working with a product dimension table of a few thousand products, and a large data warehouse fact table of sales transactions. Assume that the fact table could be hundreds of millions of rows.
You want to retrieve the products that don't exist in the fact table. Assume that the Product Key in the fact table permits null values. You write two different queries: one uses NOT EXISTS and the other uses NOT IN. Which of the two queries would you expect to perform better? Also, would you use one approach as a general practice over the other?
select * from DimProduct
where NOT EXISTS(
select * from FactOnlineSales
WHERE FactOnlineSales.ProductKey =
DimProduct.ProductKey )
select * from DimProduct
where ProductKey not
in (select ProductKey
from FactOnlineSales )
11: Use of REPLACE
Suppose you're trying to clean up a client database where users have spelled out the address notation “PO Box” in many different ways. You'd like to standardize all of the following possible spellings into a common strong, as shown in Figure 3:

You know that you can use REPLACE to substitute a partial substring, as follows:
REPLACE (AddressLine, 'P.O. Box', 'PO Box')
Does that mean you'd need to write a separate REPLACE function for every possible combination? That could mean a very long SQL statement. Is there a better way? Could you tell the REPLACE function to read from a table, or must you write a separate REPLACE statement for each possible combination of values?
12: Rules on Indexes
Select all statements that are true about database indexes in SQL Server. (There can be more than one correct statement.)
- A SQL Server table can have many non-clustered indexes, but cannot have more than one clustered index.
- A SQL Server table can have many clustered indexes, but cannot have more than one non-clustered index.
- The only way to establish uniqueness in a SQL Server table for a specific column is to define the column as a Primary Key.
- A column for a clustered index can be a different column than the column you define as the Primary Key.
- Non-clustered indexes can also include non-key columns to optimize queries that frequently retrieve those columns in addition to the key columns.
13: Baker's Dozen Spotlight: Advanced Use of MERGE
I'll close the round of questions with a more advanced question. This scenario might initially seem like an esoteric example, although the situation is a fairly common challenge in data warehousing environments. I ran into this situation in the field about two years ago. There's some important background to cover.
Suppose you have a product master table in an OLTP (transaction) system, as well as a Product dimension in a data warehousing environment.
CREATE TABLE dbo.OLTPProduct
( ProductSKU varchar(25),
ProductName varchar(100),
ProductPrice decimal(14,4),
LastUpdate DateTime )
CREATE TABLE dbo.DimProduct
( ProductPK int identity,
ProductSKU varchar(25),
ProductName varchar(50),
ProductPrice decimal(14,4),
CurrentFlag bit,
EffectiveDate Datetime,
ExpirationDate datetime)
Take special note that the Product dimension table contains columns for an effective date and an expiration date. The requirement here is to preserve historical changes in the table, for historical reporting purposes. For instance, a product might sell at $49.95 for a year, and then might see a price increase the following year. Analysts might want to report on sales under the old price as well as the new one. In the data warehouse, you store each version as a separate row with a separate surrogate key. You use the surrogate key “in effect at the time” of the sales transaction when you post sales to the fact table. This is known in the data warehousing world as a Type 2 Slowly Changing Dimension. (In a Type 1 scenario, you don't care about preserving history.)
OK, now populate some data. Start with an INSERT of one product, when the company first introduces the product.
INSERT INTO dbo.OLTPproduct
VALUES ('ABCDE', 'USB 64 GB Thumb Drive',
49.95, CAST( '7-1-2015' AS DATE))
After an overnight ETL (Extract, Transform, and Load) process to populate the DimProduct dimension, you'd expect both tables to look like Figure 4.

When you update the product's price, you want to “retire” the old version of the row in the product dimension, and then insert a new row into the product dimension with the new price.
UPDATE oltpproduct
SET ProductPrice = 54.95,
LASTUPDATE = GETDATE()
WHERE ProductSKU = 'ABCDE'
After another ETL process to update the data warehouse, you'd expect both tables to look like the results in Figure 5. Again, take special note that you don't want to overwrite the version of the product in the data warehouse product dimension. Instead, you want to retire the old row, and insert a new row (a new version of the ProductSKU) with a new price and a new effective date. Also note that the product dimension contains a flag for which version is current.
With the two versions of the row, any historical transaction fact tables with sales can point to the ProductPK of 1 for sales that occurred when the product sold at 49.95, and can point to the ProductPK of 2 for sales that occurred under the newer price. Again, this is classic fundamental Type 2 Slowly Changing Dimensions in a data warehouse environment.

OK, that was a significant amount of background. Now you get to the question. In T-SQL 2008, Microsoft introduced the MERGE statement, which allows developers to INSERT and UPDATE in one statement. MERGE initially seems like a good candidate to handle this situation of inserting a new row into the product dimension in response to an OLTP product insert, and then performing an update followed by a delete on an OLTP product update. However, there's a problem.
MERGE (targettable) Targ
USING (SourceTable) Src ON Targ.Key = Src.Key
WHEN NOT MATCHED then Insert...
WHEN MATCHED -- can we update and then insert?
You'd like to use the When Matched clause when you encounter a row in the source that matches a row in the target (based on the ProductKey), and then perform both an update and an insert to the product dimension. However, the MERGE statement doesn't allow you to perform both an UPDATE of the old row (to retire the old version) and an INSERT of the new version of the product row (with the new price). SQL Server only allows one DML statement for the WHEN MATCHED condition.
So here's the question: Is there some way you can still use the MERGE statement to retire the old version of the row AND insert a new version of the row when you detect a price change? Or do you need to look at another approach?
The Answer Sheet
Answer 1
For the Scalar Variables question (question 1), the answer is C. ("Example A returns one of the two CompanyName values, and Example B generates an error message.") The first query returns one of the two company values, and the second generates an error message. Although it's true that SQL Server scalar variables can only hold one value at any one time, SQL Server's specific behavior depends on how you're populating the variable. In the case of example A, a SELECT statement that populates a variable returns the last value from the rows that the query scans. In the case of example B, a SET statement generates an error if SQL Server attempts to read more than one row. This makes example A riskier, as the lack of an error message masks the problem: You might never realize that the code should have generated an error because of the multiple values. So the SET syntax is recommended over the SELECT syntax.
Answer 2
For Comma-Separated Values for Multiple Rows question (question 2), the answer is A (“use FOR XML”). Developers who weren't already aware of this feature (or didn't realize that FOR XML can generate concatenated lists) should remember that FOR XML is an extremely versatile function! You can combine FOR XML with the STUFF function.
SELECT Purchaser,
SUM(PurchaseAmount) AS TotPurchase,
( STUFF (( SELECT ', ' + PurchaseReason
FROM dbo.TestPurchases inside
where inside.Purchaser = Outside.Purchaser
FOR XML PATH ('')), 1,1,''))
AS Purchases
FROM dbo.TestPurchases Outside
GROUP BY Purchaser
If you're curious about the sequence of events, the FOR XML PATH ('') generates the most basic of XML strings. The comma at the beginning of the SELECT places a comma in front of every new value in the rows that the query reads. The STUFF statement at the end replaces the first character in the result set (the opening comma) with an empty string.
Answer 3
For the Date Arithmetic with DateTime and Date Data Types question (question 3), the answer is D (“The first SELECT statement adds a day to whatever was in the DateTime variable, and the second SELECT statement generates an error”). The first SELECT statement adds a day to whatever was in the DateTime variable, and the second SELECT statement generates the following error: "Operand type clash: date is incompatible with int."
SQL Server has always permitted developers to add days to a DateTime data type simply by using the arithmetic operator (+), even though most SQL professionals have always recommended the DateAdd function over the arithmetic operator. When Microsoft introduced the Date data type in SQL Server 2008, they enforced the use of DateAdd by generating errors if developers tried to add days to a Date type by using the plus sign. For companies that upgraded to SQL Server 2008, this created a problem for those who changed DateTime data types to Date data types if they also had production code that used the plus sign for date arithmetic!
DateAdd was always a much better option, as developers had the ability to specific the date part (e.g., wanted to add one month to a date, wanted to add three days to a date, etc.).
When Microsoft introduced the Date data type in SQL Server 2008, they enforced the use of DateAdd by generating errors if developers tried to add days to a Date type by using the arithmetic plus sign.
Answer 4
For the Subquery Syntax and Results question (question 4), the answer is B (“two rows”). Yes, you read that correctly; SQL Server returns two rows. If you thought the query would generate an error, I'll give half credit! Yes, the inside subquery refers to a foreign key by the wrong column name. If you simply execute the inside subquery, then yes, you'll generate an error. However, when SQL Server executes the entire query, SQL Server (for all intents and purposes) relaxes the rules for resolving references to the point where the database engine returns ALL rows to the left of the IN statement in the outer query. This can be very dangerous! The moral of the story here is to always make sure that you test the subquery portion of a derived table subquery. A second moral of the story is to use EXISTS instead of IN, which I'll discuss later.
Answer 5
The SCOPE_IDENTITY() and @@IDENTITY question (question 5) focuses on a topic that some developers (even experienced ones) aren't clear about. As a rule, if you want to know the single identity value that SQL Server assigns on a single insert, you should always use SCOPE_IDENTITY(). That raises the question: What's the difference between SCOPE_IDENTITY() and @@IDENTITY, especially since both features return a value of 1 in this situation?
Here's the official answer: SCOPE_IDENTITY() returns the last identity value that your INSERT created inside the current scope, whereas @@IDENTITY returns the last identity value that SQL Server generated as a result of your INSERT. What's the difference? There's a great one-word answer: triggers! Imagine a trigger that SQL Server fires as a result of your INSERT, and the trigger itself inserts a row to a different table that also had an identity column. The @@IDENTITY returns the identity that SQL Server generated in the trigger, whereas SCOPE_IDENTITY() continues to return the identity value from the table associated with the original INSERT statement. If you always want to retrieve the single identity value that SQL Server assigns for the INSERT statement you just executed, always use SCOPE_IDENTITY().
You can capture/redirect all of the identity values that SQL Server generates on multi-row INSERT by using the OUTPUT clause.
Notice that I've stressed “single identity value.” Suppose you fire an INSERT statement into a SQL Server table with an identity column by piping in a SELECT statement that returns multiple rows? As you saw in the Scalar Variables question, you can't redirect multiple rows into a single scalar value, and both SCOPE_IDENTITY() and @@IDENTITY return single scalar values. So how would you determine all the identity values in that situation? Fortunately, Microsoft addressed this situation back in SQL Server 2005 with the OUTPUT statement. You can capture/redirect all of the identity values that SQL Server generates on multi-row INSERT (or for that matter, any and all columns from the inserted table) by using OUTPUT as follows:
CREATE TABLE dbo.IdentityTest
(IdentityValue int identity,
Name varchar(100))
GO
INSERT INTO dbo.IdentityTest (Name)
OUTPUT Inserted.IdentityValue
VALUES ('Kevin'), ('Steven')
-- This will return 1 and 2
Finally, you can even redirect the results of the OUTPUT into an existing table. Keep all of these in mind the next time you need to capture multiple identity values from a single INSERT.
INSERT INTO dbo.IdentityTest (Name)
OUTPUT Inserted.IdentityValue
INTO SomeTableOfIdentityKeys
-- This table must already exist!
Answer 6
For the Features of SQL Server Views question (question 6), the answer is B (“The view has two issues that generate errors”). First, SQL Server views can't receive parameters. Second, SQL Server views can't have an ORDER BY statement. You can place a WHERE clause on the query that uses the view to restrict the rows, and you can also use an ORDER BY statement on the query that uses the view. However, you cannot use either feature inside a SQL Server view.
Answer 7
For the BETWEEN Statement question (question 7), the answer is A (“four rows”). Some developers answer this with B (six rows) and believe that the query will return the names “Canton” and “Celkins.” Well, imagine if you used the following query:
SELECT * FROM Purchasing.PurchaseOrderHeader
WHERE TotalDue BETWEEN 100 and 200
-- this won't return a TotalDue of 200.01
Would that query return a row where the Total Due is $200.01? The answer is no, and hopefully you can see the point. In both cases (the letter C and the value 200), you're using a value that's less precise (or too general) than the values SQL Server stores for that data type. Now it should be obvious, since 200.01 is greater than 200 and therefore outside the range, and Canton is alphabetically after C and therefore also outside the range.
Some developers make this mistake with Date and DateTime values as well. Suppose, in this example, the OrderDate column stored DateTime values, and the table contained rows with an order date of 1-31-2010 at 2 PM. In this example, SQL Server implicitly casts the value of “1-31-2010” as “2010-01-31 00:00:00.000,” which means that the query won't pick up orders throughout the day on 1-31-2010. In other words, the query won't return any rows beyond midnight for the ending date range.
SELECT * FROM Purchasing.PurchaseOrderHeader
WHERE OrderDate BETWEEN '1-1-2010'
AND '1-31-2010'
-- If OrderDate is a datetime, this won't return
-- a value of 1/31/2010 at 2 PM
The moral of the story here is to be careful using BETWEEN, especially when you specify values that represent some subset of the values that SQL Server is storing.
The moral of the story here is to be careful using BETWEEN, especially when you specify values that represent some subset of the values that SQL Server is storing.
Answer 8
For the IDENTITY Values and Uniqueness question (question 8), the answer is “no.” Actually, it's emphatically “NO!” An IDENTITY column by itself will not guarantee uniqueness. A DBA or developer can turn off identity value generation and manually insert a row, even one for a duplicate value. Granted, it would be wrong to do so, but the point is that SQL Server won't constrain a column as unique simply because you designated the column as an identity column.
SET IDENTITY_INSERT dbo.TestIdentity ON
INSERT INTO DBO.TESTIDENTITY
(IdentityValue, IdentityName)
values (1, 'Dupe Entry')
SET IDENTITY_INSERT dbo.TestIdentity Off
select * from TestIdentity
The only way to guarantee uniqueness is to define a unique constraint index, or define the column as a PRIMARY KEY.
Answer 9
For the Basic Syntax with VARCHAR question (question 9), the answer is zero rows. Some people might have guessed two rows. It's time for a little story. A long time ago, I was trying to debug a query that wasn't returning any rows based on the parameter. Finally, I added a PRINT statement to view the value of the parameter I was passing into the function that was returning zero rows. The value of the parameter was an empty string, even though I was passing in a string. The reason was that I hadn't specified a length of the varchar parameter. If you'll notice, in the code snippet for this question, I intentionally specified VARCHAR, and not VARCHAR(20) (or some other acceptable length). SQL Server permits you to define a varchar without a length, though you'd almost never do that.
Remember the old joke about the value of the comma? Borrowing from that old joke, it's the difference between saying, “We're going to eat, Kevin” and “We're going to eat Kevin.” SQL Server (just like any development tool) does exactly what you tell it to do, not what you expect it to do. Create a string variable without a length and SQL Server allocates exactly how much you specified!
SQL Server does exactly what you tell it to do, not what you expect it to do. Create a string variable without a length and SQL Server allocates exactly how many bytes you specified!
Answer 10
For the NOT IN vs NOT EXISTS and Performance question (question 10) – over the years, there's been substantial debate about using EXISTS vs IN, and NOT EXISTS vs NOT IN. Some argue that EXISTS provides more flexibility when dealing with a check on multiple columns, whereas others argue that IN is simpler if the query is only checking for an intersection with one value. Some argue that EXISTS generates better execution plans and performs better, while proponents of IN point out that often times, the execution plans are the same.
So, what's the answer here? Remember that the query in the question was looking for rows that did NOT exist in another result/query. As it turns out, SQL Server generates a better execution plan for NOT EXISTS if the subquery is dealing with columns that can contain NULL values. Had you not permitted NULL values on the ProductKey column, then there's a strong argument that the execution plans would have been the same.
So the moral of the story on this topic is that NOT EXISTS usually performs significantly better if you're examining nullable columns. Aside from that, results are about the same, although you should always examine each possibility to confirm that. I personally have switched from using IN to always using EXISTS/NOT EXISTS – not just for this scenario, but also because of the issue in the Subquery Syntax and Results question.
Answer 11
For the Use of REPLACE question (question 11), the answer is yes (you can tell the REPLACE function to read from a table). I might have answered incorrectly until a few months ago. I had a project that required me to replace a large number of misspellings and mis-standardizations for words like “PO Box.” I thought I would need one REPLACE statement for each possible value until I discovered that I could populate a table with the “before” and “after” values, and refer to them using a SELECT and a REPLACE. Listing 1 shows an example of this.
Listing 1: Using the REPLACE function to refer to values in a table
ALTER function [dbo].[ReplacePOBox]
( @ColumnValue varchar(100) )
returns varchar(100)
as
begin
declare @POValues table
(NewPOValue varchar(100), OldPOValue varchar(100))
insert into @POValues values
('PO Box' , 'PO BOX'),
('PO Box' , 'P.O.BOX'),
('PO Box' , 'P O BOX'),
('PO Box' , 'P. O. BOX'),
('PO Box' , 'P.O. BOX'),
('PO Box' , 'P O BOX'),
('PO Box' , 'P.O BOX')
SELECT @ColumnValue =
replace( @ColumnValue,
POValues.OldPOValue,
POValues.NewPOValue)
from @POValues POValues
RETURN @ColumnValue
end
GO
UPDATE SomeTable SET AddrLine = [dbo].[ReplacePOBox] (AddrLine)
Answer 12
For the Rules on Indexes question (question 12), items A, D, and E are true statements. The reason answer B is incorrect is because it's the reverse of correct answer A. The reason answer C is incorrect is because you can establish uniqueness on a column by creating a unique index.
Answer 13
For the Advanced Use of MERGE question (question 13), you can still use the MERGE statement. Although the WHEN MATCHED clause limits you to one DML statement, you can also use the COMPOSABLE DML feature of MERGE to output the results of an UPDATE (using the OUTPUT clause), as shown in Listing 2:
Listing 2: Example of Composable DML with a MERGE statement
INSERT INTO dbo.DimProduct
( ProductSKU, ProductName, ProductPrice, CurrentFlag,
EffectiveDate, ExpirationDate)
SELECT MergeOutput.ProductSKU, MergeOutput.ProductName,
MergeOutput.ProductPrice, MergeOutput.CurrentFlag,
MergeOutput.LastUpdate, null FROM
(
MERGE dbo.DimProduct Targ
USING dbo.OLTPProduct Src
ON Src.ProductSKU = Targ.ProductSKU
WHEN NOT Matched
THEN INSERT (ProductSKU, ProductName,
ProductPrice, CurrentFlag,
EffectiveDate, ExpirationDate)
VALUES (Src.ProductSKU, Src.ProductName,
Src.ProductPrice, 1,
Src.LastUpdate, null)
WHEN MATCHED AND
Targ.CurrentFlag = 1 and
Src.ProductPrice <> Targ.ProductPrice
THEN UPDATE SET Targ.CurrentFlag = 0,
Targ.ExpirationDate = getdate()
OUTPUT $Action as DMLAction, Src.ProductSKU, Src.ProductName,
Src.ProductPrice, Src.LastUpdate, 1 AS CurrentFlag )
AS MergeOutput
WHERE DMLAction = 'UPDATE'
Essentially, you're redirecting the OUTPUT of the MERGE (for DMLActions of UPDATE only) back into the result set pipeline, capturing them at the top of the query, and redirecting as an INSERT back into the Product Dimension. It's very powerful!
INSERT INTO dbo.DimProduct (Fields)
SELECT MergeOutput. Columns FROM (
MERGE dbo.DimProduct Targ
USING dbo.OLTPProduct Src
ON Src.ProductSKU = Targ.ProductSKU
WHEN NOT Matched THEN INSERT (values)
WHEN MATCHED THEN UPDATE
(retire old rows)
OUTPUT $Action as DMLAction, (Source columns), 1 AS CurrentFlag )
AS MergeOutput
WHERE DMLAction = 'UPDATE'
Final Thoughts
When I speak at community events or conferences, I usually end a session by asking attendees to raise their hands if they learned more than one fact or concept from the presentation. I certainly hope this article provided a few benefits to every reader, either to help with a programming challenge or to increase understanding of a particular SQL Server feature. Readers can certainly feel free to incorporate these topics into any interview test questions they're writing.
Fellow CODE Magazine author Ted Neward and I have both written and blogged about the benefits of speaking and writing about technical features, and how that process enhances a person's understanding. Taking a technical test, even for an informal academic exercise, can sometimes help a developer's thought process. So think of this as the CODE Magazine version of a New York Times crossword puzzle!
As I stated at the beginning of the article, I'm going to use this format for some of my Baker's Dozen articles in the future. In my next column, I'll cover some more advanced T-SQL and database topics. Down the road, I might expand it to cover test-style questions for other tools in the SQL Server Business Intelligence stack, since tools like Reporting Services and Integration Services continue to grow in use and popularity. Stay tuned!
