





When David LeBlanc and I wrote Writing Secure Code (Microsoft Press, 2001), we realized threat modeling was of utmost importance when delivering secure systems. You cannot build secure systems until you understand your threats. What we didn't realize is how well it would be adopted within Microsoft. Threat modeling has become the cornerstone of the design phase of new products; a product is not considered design complete without a threat model. In this article I'll explain the process of threat modeling and how you can use the process in your organization.
A member of the press asked me this question a few days after the Windows Security Push in February and March of 2002: “What was the most important skill your team taught developers, testers, and designers?” Without hesitating, I replied that we taught developers to trace every byte of data as it flows through their code and to question all assumptions about the data. For testers, it was data mutation. For designers it was analyzing threats. In fact, during the Windows Security Push (and all pushes that followed at Microsoft), we found that the most important aspect of the software design process, from a security viewpoint, is threat modeling.
Secure Design Through Threat Modeling
You cannot build secure systems until you understand your threats
The overriding driver of threat modeling is that you cannot build secure systems until you evaluate the threats to the application with the goal of reducing the overall risk. The good news is that threat modeling is simple, but it does require significant time investment to get right. For the lazy designer, threat modeling can form the basis of the security section of the design specifications!
Threat modeling also offers other benefits, including:
Threat models help you understand your application better. If you spend time analyzing the makeup of your application in a relatively structured manner, you cannot help but learn how your application works! I've lost count of how many times I've heard the phrase “Oh, so that's how it works!” during a threat-modeling session!Threat models help you find bugs. All groups I've worked with track how bugs are found, and lately many have added a new value to the “How Found” field of their bug databases: Threat Model. If you think about it, it makes sense. You can find bugs by looking at code, and you can find bugs by testing the application. In addition, you can find bugs by critically reviewing the application's design. In fact, we've discovered that about 50 percent of the bugs found are through threat analysis, with the other 50 percent comprising bugs found during test and code analysis.You'll also find complex design bugs that are not likely to be found in any other way. You will discover multi-step security bugs where several small failures combine to become one large disaster by using threat analysis techniques.## The Process
Analyzing threats can be a great deal of work, however, it's cheaper to find a security design bug at this stage and remedy the solution before coding starts. You must also keep the threat model current, reflecting new threats and mitigations as they arise.
Here is the threat-modeling process:
Assemble the threat-modeling team.Decompose the application.Determine the threats to the system.Rank the threats by decreasing risk.Choose how to respond to the threats.Choose techniques to mitigate the threats.Choose the appropriate technologies for the identified techniques.You might need to perform the process a couple of times because no one is clever enough to formulate all the threats in one pass. In addition, changes occur over time, you learn new issues, and the business, technical, and vulnerability landscape evolves. All of these have an impact on the threats to your system.
Let us look at each part of this process.
Assemble the Threat-Modeling Team
Gather members of the development group to perform the initial threat analysis process. Have one person lead the team; generally, this person is the most security-savvy person of the team. By “security-savvy” I mean that this person can look at any given application or design and work out how an attacker could compromise the system. The security person may not be able to read code but they should know where other products have failed in the past. This is important because threat modeling is more productive when people have an appreciation of how to attack systems.
Make sure at least one member from each development discipline is at the meeting, including design, coding, testing, and documentation. You'll get a broader view of the threats and mitigation techniques with a broader group. If you have people outside your immediate team who are good with security, invite themfresh eyes and questions about how things work often lead to interesting discoveries. However, don't have more than ten people in the room or the meeting will slow to a standstill and you'll make little progress. I've also found it useful to invite a marketing or sales person, not only to get input but also to educate.
Before the threat-modeling process is under way it's important to point out to all team members that the goal is not to solve problems at the meeting but to identify the components of the application and how they interact and, eventually, to find as many security threats as possible. The design and code changes (and arguments) are made in later meetings. Some discussion of mitigation techniques is inevitable; just don't let the conversation get too far into the details.
Also, the first meeting should use a whiteboard and should later be transcribed to an electronic form for further analysis and review.
Formally Decomposing the Application
If you have never performed threat analysis on your application, you probably have another category of security bugs you never knew you had!
Applications are built from individual features and each feature can be attacked. It is therefore important that you understand the components of the application. In my experience both data flow diagrams (DFDs) and UML activity diagrams make a useful decomposition technique for threat analysis. (Microsoft Visio Professional 2002 includes a Data Flow Diagram template and many UML templates.)
It is not the purpose of this article to teach you how to create DFDs or how to use UML. There are plenty of good reference books on the subject.
The guiding principle for DFDs is that you can decompose an application or a system into subsystems, and you can decompose subsystems into still lower-level subsystems. This iterative process makes DFDs useful for decomposing applications.
In the first phase of decomposition you'll determine the boundaries or scope of the system that you're analyzing as well as the boundaries between trusted and untrusted components. If you do not define the scope of the application you'll end up wasting a great deal of time discovering threats that are outside your scope and beyond the control of your application. Once you've completed this phase you'll drill down to lower levels by using level-0, level-1, and level-2 diagrams, and so on.
When you define the scope of the DFD, consider the following points:
Ignore the inner workings of the application. At this stage it does not matter how things work; you want to define scope, not functional details.To what events or requests must the system respond? For example, a stock market Web service could receive requests for a stock quote based on a ticker symbol.What responses will the process generate? In a stock quote example, the Web service could provide a time and a quote, including current ask and bid prices.Identify the data sources as they relate to each request and response. Some data sources are persistent (files, registry, databases, etc.), and others are short-lived or ephemeral (cache data).Ascertain who/what receives each response.Eventually you'll get to a point where you understand the composition of the application. Generally, you should have to dive down no more than four levels deep if all you are doing is threat modeling.
Determine the Threats to the System
Next you want to take the identified components from the decomposition process and use them as the threat targets for the threat model. The reason you analyze the application structure is not to determine how everything works, but rather to investigate the components, or assets, of the application and how data flows between the components. The components or assets are often called the threat targets. Before I dive into how to determine the threats to the system, let's look at a way to categorize threats. This becomes useful later because you can apply certain strategies to mitigate specific threat categories.
Using STRIDE to Categorize Threats
When you're considering threats, it's useful to look at each component of the application and ask questions like these:
Can a nonauthorized user view the confidential network data?Can an untrusted user modify a customer's record data in the database?Could someone deny valid users service from the application?Could someone take advantage of the feature or component to raise his or her privileges to that of an administrator?To aid asking these kinds of pointed questions, you should use threat categories. In this case we'll use STRIDE, an acronym derived from the following six threat categories:
Spoofing Identity
Spoofing threats allow an attacker to pose as another user or allow a rogue server to pose as a valid server. One example of user identity spoofing is illegally accessing and then using another user's authentication information, such as username and password. A good real-life example is an insecure authentication technique such as HTTP Authentication. Examples of server spoofing include DNS spoofing and DNS cache poisoning.
Tampering With Data
Data tampering involves malicious modification of data. Examples include unauthorized changes made to persistent data, such as that held in a database, and the alteration of data as it flows between two computers over an open network, such as the Internet. A real-life example includes changing data in a file protected with a weak Access Control List (ACL), such as Everyone (Full Control), on the target computer.
Repudiation
Repudiation threats are associated with users who deny performing an action without other parties having any way to prove otherwise. For example, a user could perform an illegal operation in a system that lacks the ability to trace the prohibited operations. Nonrepudiation is the ability of a system to counter repudiation threats. For example, if a user purchases an item, he might have to sign for the item upon receipt. The vendor can then use the signed receipt as evidence that the user did receive the package. As you can imagine, nonrepudiation is important for e-commerce applications.
Information Disclosure
Information disclosure threats involve the exposure of information to individuals who are not supposed to have access to that information. For example, a user might be able to read a file that she was not granted access to, or an intruder might be able to read data in transit between two computers. The spoofing example discussed earlier is also an example of an information disclosure threat because to replay a user's credentials, the attacker must view the user's credentials first.
Denial of Service
Denial of service (DoS) attacks deny service to valid users. For example, an attack could make a Web server temporarily unavailable or unusable. You must protect against certain types of DoS threats simply to improve system availability and reliability. A very real example of this includes the various distributed denial of service attacks (DDoS), such as Trinoo and Stacheldraht. You can learn more about these attacks at staff.washington.edu/dittrich/misc/ddos/.
Elevation of Privilege
In this type of threat, an unprivileged user gains privileged access and thereby has sufficient access to compromise or destroy the entire system. Elevation of privilege threats include those situations where an attacker has penetrated system defenses and effectively become part of the trusted system itselfa dangerous situation indeed. An example is a vulnerable computer system that allows an attacker to place an executable on the disk and then to wait for the next person to log on to the system. If the next user is an administrator, the malicious code runs within the security profile settings of an administrator.
Threats That Lead to Other ThreatsSome threat types can interrelate. It's not uncommon for information disclosure threats to lead to spoofing threats if the user's credentials are not secured. And, of course, elevation of privilege threats are, by far, the worst threatsif someone can become an administrator or can get to the root on the target computer, every other threat category becomes a reality. Conversely, spoofing threats might lead to a situation where escalation is no longer needed for an attacker to achieve his goal. For example, using SMTP spoofing, an attacker could send an e-mail purporting to be from the CEO and instructing the workforce to take a day off for working so well. Who needs to elevate their privilege to CEO when you have social engineering attacks like this?
Now we'll discuss the process of determining threats to the system. We'll use threat trees and you'll see how to apply STRIDE to threat trees.
Threat Trees
A well-known method for identifying possible failure modes in hardware is by using fault trees, and it turns out this method is also well suited for determining computer system security issues. After all, a security error is nothing more than a fault that potentially leads to an attack. (The hardware-related method is also often referred to as using threat trees, and some of the best threat tree documentation is in Edward Amoroso's Fundamentals of Computer Security Technology [Prentice Hall, 1994]).
The idea behind threat trees is that an application is composed of threat targets and that each target could have vulnerabilities that when successfully attacked could compromise the system. Threat trees describe the decision-making process an attacker goes through to compromise the component. When the decomposition process gives you an inventory of application components, you start identifying threats to each of those components. Once you identify a potential threat, you then determine how that threat could manifest itself by using threat trees.
Think for a moment about the payroll data that flows between the user (an employee) and the computer systems inside the data center and back; it's sensitive data, confidential between the company and the user. This is an example of an information disclosure threat. You don't want a malicious employee looking at someone else's payroll information, which means that your solution must protect the data from prying eyes. An attacker can view the data in a number of ways, but the easiest, by far, is to use a network protocol analyzer, or sniffer, in promiscuous mode to look at data as it travels between the unsuspecting target user's computer and the main Web server. Another attack might involve compromising a router between the two computers and reading all traffic between the two computers.
The top shaded box is the ultimate threat; the boxes below it are the steps involved to make the threat a reality. In this case the threat is an information disclosure threat (indicated by the (I) in the box): an attacker views another user's data.
For this threat to become a real exploit the HTTP traffic must be unprotected (1.1) and the attacker must actively view the traffic (1.2.). For the attacker to view the traffic, he must sniff the network (1.2.1) or listen to data as it passes through a router (1.2.2). The attacker can view the data in cases 1.2.1 and 1.2.2 because it's common for HTTP traffic to be unprotected. Note that for the router listening scenario (1.2.2) to be real, one of two facts must be true: either the target router is unpatched and has been compromised (1.2.2.1 and 1.2.2.2 must both be true) or the attacker has guessed the router administrative password (1.2.2.3). The small semicircular link between the two nodes symbolizes how the two facts are tied together. You could also simply add the word and between the lines.
Although trees communicate data well they tend to be cumbersome when building large threat models. An outline is a more concise way to represent trees. The following outline represents the threat tree in Figure 1.
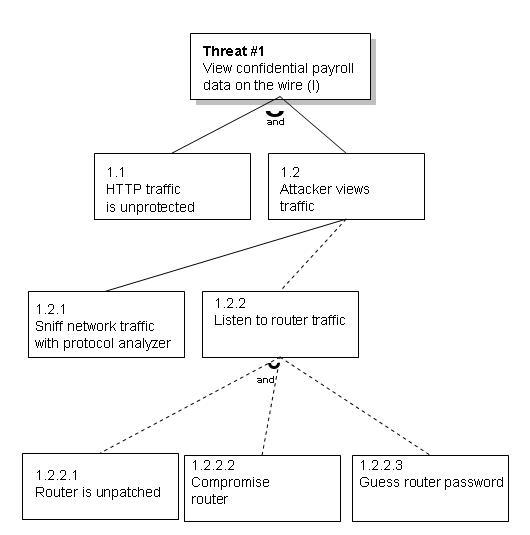
1.0 View confidential payroll data on the wire
1.1 HTTP traffic is unprotected (AND)
1.2 Attacker views traffic
1.2.1 Sniff network traffic with protocol analyzer
1.2.2 Listen to router traffic
1.2.2.1 Router is unpatched (AND)
1.2.2.2 Compromise router
1.2.2.3 Guess router password
1.2.3 Compromise switch
1.2.3.1 Various switch attacks
Small Enhancements to Make Threat Trees More Readable
You can make some small additions to threat trees to show the most likely attack vectors. First, use dotted lines to show the least likely attack points and solid lines for the most likely. Second, place circles below the least likely nodes in the tree outlining why the threat is mitigated. Figure 2 illustrates the concept.
Don't add the mitigation circles during the threat-modeling process. If you do you're wasting time coming up with mitigations; remember that you're not trying to solve the issues at the threat-modeling sessions. Save these actions for a subsequent meeting, once the design starts to gel.
There is an interesting effect of adding the “dotted-lines-of-most-resistance” to threat trees: they act as a pruning mechanism. This means you can perform tree-pruning, which makes focusing on the real issues much easier.
Items to Note While Threat Modeling
You need to track more than just the title and type of a threat; you should also determine and record all items listed in Table 1:
Rank the Threats by Decreasing Risk
Once you've created threat trees and captured the threats, you need to determine the most important threats so that you can prioritize your work. Work out which issues to investigate first by determining the risk the threat poses. The method you use to calculate risk is not important so long as you are realistic and consistent.
A simple way to calculate risk is by multiplying the criticality (damage potential) of the vulnerability by the likelihood of the vulnerability occurring1 is low criticality or likelihood of occurrence and 10 is high criticality or likelihood of occurrence:
Risk = Criticality * Likelihood of Occurrence
A bigger number means the threat poses a greater overall risk to the system. A simple model to follow might have the highest risk rating possible of 100. A threat this great would have a criticality rating of 10 multiplied by the greatest likelihood rating, also 10.
Bringing It All Together: Decomposition, Threat Trees, STRIDE, and Risk
To bring it all together, you can determine the threat targets from functional decomposition, determine types of threat to each component using STRIDE, use threat trees to determine how the threat can become a vulnerability, and apply a ranking mechanism to each threat.
Applying STRIDE to threat trees is easy. For each system inventory item, ask these questions:
Is this item susceptible to spoofing?Can this item be tampered with?Can an attacker repudiate this action?Can an attacker view this item?Can an attacker deny service to this process or data flow?Can an attacker elevate their privilege by attacking this process?Look at Table 2 and you may notice that certain data flow diagram items can have certain threat types.
Some of these table entries require a little explanation:
Spoofing threats usually mean spoofing a user (accessing their credentials), a process (replacing a process with a rogue, which is also a data-tampering threat), or a server.Tampering with a process means replacing its binary image or patching it in memory.Information disclosure threats against processes means reverse engineering the process to divulge how it works or to determine whether it contains secret data.An interactor cannot be subject to information disclosure; only data about the interactor can be disclosed. If you see an information disclosure threat against a user, you're probably missing a data store and a process to access that data.You cannot deny service to an interactor directly; rather, an attacker denies service to a data store, data flow, or a process, which then affects the interactor. Repudiation threats generally mean a malicious user denying an event occurred. Attacks could be due to actions take by the user, disrupting audit and authentication data flow on the wire or in a data store.You can elevate privilege only by taking advantage of a process that grants or uses higher privilege. Simply viewing an administrator's password (information disclosure) does not grant extra privilege. However, do not lose sight of the fact that some attacks are multi-step attacks and viewing an administrative password is a privilege elevation if a vulnerability exists such that the password can be replayed.## Going Over the Threat-Modeling Process One More Time
Let's review the threat-modeling process one more time to make sure it's well understood.
Step 1
Decompose the application into threat targets by using an analysis method such as data flow diagrams. In the case of DFDs, the threat targets are every data source, process, data flow, and interactor or actor.
Step 2
Using STRIDE, identify threats for each of the threat targets. These serve as the roots for the threat trees, there is one tree per threat goal.
Step 3
Build one or more threat trees for each threat target, as appropriate.
Step 4
Use a threat ranking method to determine the security risk for each threat tree.
Step 5
Sort the threats in order from highest to lowest risk.
Once you've done this, your next step is to determine how you deal with the threatsour next topic!
Choose How to Respond to the Threats
You have four options when considering threats and how to mitigate them.
Option One: Do Nothing
Doing nothing is rarely the correct solution because the problem is latent in the application, and the chances are greater than zero that the issue will be discovered and you will have to fix the problem anyway. It's bad business and bad for your clients because you might be putting your users at risk. If you decide to do nothing, at least check whether the feature that is the focus of the threat can be disabled by default. That said, you ought to consider one of the following three options instead.
Option Two: Warn the User
Inform the user of the problem and allow the user to decide whether to use the feature. Like doing nothing this option can be problematicmany users don't know what the right decision is. The decision is often made more difficult by convoluted text, written by a technical person, appearing in a warning dialog box. Users will ignore warnings if they come up too often and they don't have the expertise to make a good decision.
If you decide to warn the user about the feature in your documentation, remember that users don't read documentation unless they must!
Option Three: Remove the Problem
I've often heard development teams say that they have no time to fix a security problem, so they have to ship with the security flaw. This decision is wrong. Here's one last drastic optionpull the feature from the product. If you have no time to fix the problem and the security risk is high enough, you should consider pulling the feature from the product. If it seems like a hard pill to swallow, think of it from your user's perspective. Imagine that it was your computer that just got attacked. Besides, there's always the next version!
Option Four: Fix the Problem
The most obvious solutionremedy the problem with technologycan also be the most difficult because it involves more work for the designers, developers, testers, and, in some cases, documentation people. You can determine mitigation categories based on the threat category. The following shows some example techniques:
Spoofing - strong authenticationTampering strong authorization techniquesRepudiation digital signatures, timestamps, secure loggingInformation Disclosure strong encryption and key management, and strong access techniquesDenial of Service strong authentication and authorization, packet filteringElevation of Privilege don't run code as elevated accountsThe full list of potential mitigation techniques and technologies is beyond the scope of this article but you should always ask the question, “Does this mitigate the threat, or reduce the risk to an acceptable level?”
Summary
I strongly believe that threat modeling is a design necessity.. Without a threat model in place you cannot know if you have mitigated the most pressing threats. Simply playing Buzzword Bingo by liberally scattering security technologies around your application will not make it securethe technologies might be inappropriate and fail to mitigate threats correctly. I also have no doubt that if you expend the effort and build up-to-date and accurate threat models, you will deliver more secure systems. Experience shows that about half of the security flaws will be discovered from threat modeling because they find different threats than those found through code review.
The process is simple: assemble the team, decompose the application (for example using DFDs), determine the threats to the system using threat trees and STRIDE, rank the threats, and then choose mitigation techniques based on the STRIDE category.
Threat models are a critical component of a sound security development process. At Microsoft, we mandate threat models as part of the design phase sign-off criteria.
