





Now that C# is scheduled for an annual release, which generally occurs in November each year, it's time to review the upcoming targeted enhancements for C# vNext: C# 10.0. Although there aren't any mind-blowing new constructs (it's implausible to introduce something like LINQ every year), there's a steady stream of improvements.
If I were to summarize C# 10.0, it would be removing the unneeded ceremony - such as extra curly braces or duplicate code - that doesn't add value. This synopsis shouldn't imply that the changes are irrelevant. In contrast, I think many of these changes are so strong that they will become the C# coding norm in the future. I suspect future C# developers will tend to forget the old syntax. In other words, several of these improvements are significant enough that you will likely never go back to the old way unless you require backward compatibility or need to code in an earlier version of C#.
File Scoped Namespace Declaration (#UseAlways)
To begin, consider an ever so simple feature called file scoped namespace declaration. Previously, namespace declaration involved placing everything within that namespace between curly brackets. With C# 10.0, you can declare the namespace before all other declarations (classes, structs, and the like) and not follow it with curly braces. As a result, the namespace automatically includes all the definitions that appear in the file.
For example, consider the following code snippet:
namespace EssentialCSharp10;
static class HelloWorld
{
static void Main() { }
// ...
}
// Additional namespace declarations are not
// allowed in the same file.
// namespace ScopedNamespaceDemo
// {
// }
// namespace AdditionalFileNamespace;
Here, the CSharp10 namespace is declared before any other declarations: a file scoped namespace syntax requirement. Additionally, a file scoped namespace declaration is an exclusive namespace declaration. No other namespaces, either traditionally curly-scoped or additional file-scoped, are allowed within the file.
Although not a significant change, I expect that I will always use this 10.0 feature going forward. Not only is the statement simpler without the curly braces, but it also means I no longer need to indent other declarations within the namespace. For this reason, I've tagged it with #UseAlways in the title. In addition, I think this feature warrants updating the C# coding guideline, assuming C# 10.0 or later: Do use file-based namespace declarations.
Global Using Directive (#UseAlways)
My #UseAlways recommendation might be surprising because namespace declarations haven't changed since C# 1.0, but C# 10.0 includes a second namespace-related change: global namespaces directives.
Good programmers refactor ruthlessly! Why is it, then, that C# forces us to re-declare a series of namespaces at the top of every file? For example, most files include a using System directive at the top. Similarly, a unit testing project virtually always imports the namespace for the target assembly under test and the test framework namespace. Why is it necessary to write the same using directive repeatedly for each new file? Wouldn't it make sense to write a single using directive that applies globally through the project?
Of course, the answer is yes. For namespaces that you have using directives throughout your project, you can now provide a global using directive that will import the namespace throughout the project. The syntax requires the new global contextual keyword to prefix a standard using directive, as shown in the following snippet within an XUnit test project:
global using EssentialCSharp10;
global using System;
global using Xunit;
global using static System.Console;
You can place the above snippet anywhere within your code. By convention, however, consider something like a GlobalUsings.cs or Usings.cs file. Furthermore, once the global using directives are in place, you can leverage them in all files within the project:
public class SampleUnitTest
{
[Fact]
public void Test()
{
// No using System needed.
DateTime dateTime = DateTime.Now;
// No using Xunit needed.
Assert.True(dateTime <= DateTime.Now);
WriteLine("...");
}
}
Note, global using directives include support for using static. As a result, you can have a WriteLine() statement with no “System.Console” qualifier. Global aliases using directive syntax are also supported.
In addition to coding global using statements in C# explicitly, you can also declare them within MSBuild (as of 6.0.100-rc.1). A Using element within your CSPROJ file for example (i.e., <Using Include="Microsoft.VisualStudio.TestTools.UnitTesting" />) generates an ImpklicitNamespaceImports.cs file that includes a corresponding global namespace declaration. Furthermore, adding a static attribute (e.g., Static="true") or an alias attribute, such as Alias=" UnitTesting", generates the corresponding static or alias directives. Furthermore, the some of the target frameworks include implicit global namespace directives. See https://docs.microsoft.com/en-us/dotnet/core/project-sdk/msbuild-props#disableimplicitnamespaceimports for a corresponding list. If, however, you prefer that no such default global namespaces get generated, you can turn them off with an ImplicitUsings element set to disable or false. Here's a sample PropertyGroup element from CSPROJ:
<PropertyGroup>
<ImplicitUsings>disable</ImplicitUsings>
<Using>EssentialCSharp10</Using>
<Using>System</Using>
<Using>Xunit</Using>
<Using Static="true">System.Console</Using>
</PropertyGroup>
Note that this is not yet working with Visual Studio 2022 Preview 3.1.
You don't want to convert all your using directives to global using directives, or you're likely to run into ambiguities in the unqualified type names. However, I expect at least a few global declarations in most projects - such as the default ones from the target framework at a minimum, hence the #UseAlways tag.
Constant Interpolated Strings (#UsedFrequently)
One feature that until now has no doubt irritated you is the lack of a method to declare a constant interpolated string, even though the value is entirely determinable from other constants or compile-time determined values. C# 10 addresses this issue. Here are some examples to consider:
const string author = "Mother Theresa";
const string dontWorry = "Never worry about numbers.";
const string instead = "Help one person at a time and always " +
"start with the person nearest you.";
const string quote = $"{ dontWorry } { instead } - { author }";
One case I particularly appreciate with constant interpolation is leveraging the nameof operator within attributes, as demonstrated in the following snippet:
[Obsolete($"Use {nameof(Thing2)} instead.")]
class Thing1 { }
class Thing2 { }
Prior to C# 10.0, the inability to use the nameof operator within a constant string literal was undoubtedly a source of consternation.
Lambda Improvements
C# 10.0 includes three improvements to lambda syntax support - both expressions and statements.
Attributes
With a host of new parameter attributes introduced with C# 8's nullable-references, the lack of attribute support in lambdas became even more noticeable. Fortunately, in C# 10, attributes on lambdas are now supported, including attributes on the return type:
Func<string?, string[]?>? Func = [return: NotNullIfNotNull("cityState")]
static (string? cityState) => cityState?.Split(", ");
Note that in order to have attributes on the lambda, it's also necessary to surround the parameter list with parenthesis. _ = [return: NotNullIfNotNull("cityState")] cityState => cityState?.Split(", ") is not allowed.
Explicit Return Type
If you're in the habit of using implicit type declaration with var, it's not that uncommon that the compiler is unable to figure out a method signature. Consider, for example, a method that returns null if it fails to parse text to a nullable integer:
var func = (string? text) => int.TryParse(text, out number)?number:null;
The problem here is that both int? or object would be valid returns. And it isn't obvious which to use. Although it's possible to cast the result, the syntax for casting large expression is cumbersome. A preferable alternative, and the one available starting with C# 10.0, is to allow for declaring the return type as part of the lambda syntax:
Func<string?, int?> func = int? (string? text) =>
int.TryParse(text, out int number)?number:null;
The added bonus for those using var less habitually is that the addition of the return type declaration enables quick actions to convert a var to the explicit lambda type, as demonstrated in the snippet above: Func<string?, int?>.
Note, lambdas declared with delegate { } syntax aren't supported: Func<int> func = delegate int { return 42; } won t compile.
Natural Function Types
Lastly, it's possible to infer a natural delegate type for lambdas and statements. Essentially, the compiler will do a “best fit” attempt to determine the signature of the lambda expression or statement and thereby allowing the programmer to avoid specifying redundant types when the compiler can infer the type.
Caller Expression Attribute (#UsedRarely)
This feature has three different usage profiles. If you write perfect code that never needs debugging or triage, this next feature is probably useless for you. Alternatively, if you use debug classes, logging classes, or unit test assertions, this could be invaluable without you even knowing it exists. You essentially reap the benefits of the feature without having to make any adjustments to your code. If you're a library vendor where you provide validation or assertion logic, it's paramount that you use this feature where applicable. It will significantly improve your API functionality.
Working with Caller Attribute Methods
Imagine a function that validates a string parameter - verifying that it isn't null or empty. You could leverage such a function in a property as follows:
using static EssentialCSharp10.Tests.Verify;
class Person
{
public string Name
{
get => _Name ?? "";
set => _Name = AssertNotNullOrEmpty(value);
}
private string? _Name;
}
There's no C# 10.0-specific feature visible in this code snippet. Name is a non-nullable property with an assert method that throws an exception if the value is null or empty. So, what's the feature?
The difference shows up at runtime. In this case, when the value is null or empty, the AssertNotNullOrEmpty() method throws an ArgumentNull exception whose message includes the argument expression, “value.” And, if method invocation was AssertNotNullOrEmpty("${firstName}{lastName}"), then the ArgumentNull exception message would include the exact text: "${firstName}{lastName}", because that was the argument expression specified when calling the method.
Logging is another area where this feature would prove very helpful. Rather than calling Logger.LogExpression($"Math.Sqrt(number) == { Math.Sqrt(number) }" you could instead call Logger.LogExpression(Math.Sqrt(number)) and have the Log() method include both the value and the expression in the output message.
Implementing Caller Attribute Methods
One of the big advantages of this Caller Attribute method is added functionality without the caller knowing or making any source code changes. When you're implementing an assert, logging, or debug type method, you need to understand how to declare and leverage the feature. Here's a snippet demonstrating the AssertNotNullOrEmpty() method implementation:
public static string AssertNotNullOrEmpty(
string? argument,
[CallerArgumentExpression("argument")]
string argumentExpression = null!)
{
if (string.IsNullOrEmpty(argument))
{
throw new ArgumentException(
"Argument cannot be null or empty.",
argumentExpression);
}
return argument;
}
The first thing to note is the CallerArgumentExpression attribute decorating the argumentExpression parameter. By adding this attribute, the C# compiler injects the expression specified as the argument into the argumentExpression. In other words, although the caller statement was coded as _Name = AssertNotNullOrEmpty(value), the C# compiler morphs the call into _Name = AssertNotNullOrEmpty(value, "value"). The result is that the AssertNotNullOrEmpty() method now has both the calculated value for the argument expression (in this case, it's value's value, as well as the expression itself). Thereby, when throwing the ArgumentException, not only can the message identify what was wrong, “Argument cannot be null or empty,” but it can provide the text for the “value” expression.
Notice that the CallerArgumentExpression attribute includes a string parameter that identifies which parameter's expression in the implementing method will be injected into the CallerArgumentExpression's parameter. In this case, because “argument” is specified, the expression from the “argument” parameter is injected into the value of argumentExpression.
The result is that you're not limited to only using the CallerArgumentExpression on one parameter. You could, for example, have an AssertAreEqual(expected, actual, [CallerArgumentExpression("expected")] string expectedExpression = null!, [CallerArgumentExpression("actual") ] string actualExpression = null!) and then provide an exception that shows the expressions, not just the end results.
There are a few coding guidelines to consider when implementing a CallerArgumentExpression method:
- Do declare the caller argument expression parameter as optional (
using "=null!") so that invoking the method doesn't require the caller to identify the expression explicitly. In addition, it allows the feature to be added to existing APIs without the caller code changing. - Consider declaring the caller argument expression parameter as non-nullable and assign null with the null-forgiveness operator (!). This allows the compiler to specify the value by default and imply that it's intended not to be
nullif an explicit value is set.
Parenthetically, it's unfortunate, but as of C# 10.0, you can't use the nameof operator to identify the parameter. For example, CallerArgumentExpression(nameof(argument)) won't work. That's because the argument parameter isn't in scope at the time the attribute is declared. However, such support is under consideration post-C# 10.0 (see Support for method parameter names in nameof(): https://github.com/dotnet/csharplang/issues/373).
Record Structs (#UsedOccasionally)
C# 9.0 added support for records. At the time, all records were reference types and potentially mutable. The advantage of adding the record types is that they provided a concise syntax for defining a new type with the primary purpose of encapsulating data (with less emphasis on providing behavior or a service). Now, records of both types have C# compiler-generated implementations of value equality, non-destructive mutation, and built-in display formatting.
Record Structs Versus Record Classes
In C# 10.0, the record feature was extended to allow for record value types (record structs) and record reference types (record classes). For example, consider the Angle declaration shown here:
record struct Angle(double Degrees, double Minutes, int Seconds)
{
// By default, primary constructor
// parameters are generated as read-write
// properties:
// public double Degrees {get; set;}
// You can override the primary
// constructor parameter implementation
// Including making them read-only
// (no setter) or init only.
public double Minutes { get; init; } = Minutes;
// Primary constructor parameters can be
// overridden to be fields
public int Seconds = Seconds;
}
Declaring the record as a value type involves adding the struct keyword between the contextual keyword record and the data type name. Like record classes, you can also declare a primary constructor immediately following the data type name. This declaration instructs the compiler to generate a public constructor (i.e., Angle [double Degrees, double Minutes, int Seconds]) that assigns the fields and properties (i.e., degrees, minutes, and seconds members) with the corresponding constructor parameter values. If not explicitly declared, the C# compiler generates properties corresponding to the primary constructor parameters (i.e., Degrees). Of course, you can add additional members to the record struct and override the generated properties with custom implementations even if the accessibility modifier isn't public or the property is read-only, init-only, or read-write.
Record structs include the same benefits of record classes except where behavior is inherent to C# value types. For example, equality methods (Equals(), !=, ==, and GetHashCode()) are all autogenerated at compile time. After all, perhaps these methods are the key feature justifying the record data type. Also, like record classes, records structs include a default implementation for ToString() that provides a formatted output of the property values. (The ToString() output for an instantiated Angle, for example, returns Angle { Degrees = 30, Minutes = 18, Seconds = 0 }). In addition, record structs include a deconstruct method that allows an instance of the type to convert into a set of variables corresponding to the primary constructor: i.e., (int degrees, int minutes, int seconds) = new Angle(30, 18,42). One last feature that both record types have in common is the with operator. It enables cloning the record into a new instance, optionally with modification on selected properties. Here's an example:
public static Angle operator +(Angle first, Angle second)
{
(int degrees, int minutes, int seconds) = (
(first.Degrees + second.Degrees),
(first.Minutes + second.Minutes),
(first.Seconds + second.Seconds));
return first with
{
Seconds = seconds % 60,
Minutes = (minutes + (int)(seconds / 60)) % 60,
Degrees = (int)(degrees + (int)((minutes +
(int)(seconds / 60)) / 60)) % 360
};
}
And, as a bonus, with support was added to structs (not only record structs) in C# 10.0.
Unlike record classes, record structs always derive from System.ValueType because they're .NET value types and therefore no additional inheritance is supported. In addition, record structs can be qualified with the readonly keyword (readonly record struct Angle {}), thus rendering them immutable once the type is fully instantiated. Given the readonly modifier, the compiler verifies that no fields (including automated property-backing fields) are modified once object initialization is complete. As demonstrated with the Seconds primary constructor parameter, another difference with record structs is that you can override the primary constructor behavior to generate fields rather than properties.
Parenthetically, you can also now declare a record reference type with the class keyword (using simple record <TypeName> is still allowed), thus providing symmetry between the two types of record declaration:
record class FingerPrint(
string CreatedBy, string? ModifiedBy = null) {}
Note: The readonly record modifier isn't allowed with record classes at this time.
Mutable Record Structs
One thing to be wary of is that, unlike a record class, record struct primary constructor parameters are read/write by default (at least in the Visual Studio Enterprise 2022 Preview [64-bit] Version 17.0.0 Preview 3.1 available at the time of writing). This default is surprising to me for two reasons:
- Historically, structs were declared immutable to avoid erroneously attempting to modify the struct by insidiously modifying a copy. This is primarily because passing a value type as a parameter, by definition, creates a copy. Modifying the copy is unexpectedly not reflected at the caller (if it wasn't obvious or well known that the type was a value type). Perhaps more insidious is a member that mutated the instance. Imagine a
Rotate()method on anAngleinstance that rotated the sameAngleinstance. Invoking said method from a collection, i.e.,Angle[0].Rotate(42,42,42), unintentionally doesn't change the value stored inangle[0]. - Parenthetically, mutable value types were far more problematic when modifying them inside a collection was allowable. However, something like
Angle[0].Degrees = 42is now prevented by the compiler even ifDegreesis writable, thus preventing unexpectedly not modifyingDegrees. - Mutable record structs, by default, would be inconsistent with record classes. Consistency behavior is a strong motivator when it comes to learning, understanding, and remembering.
Despite the considerations, there are important differences that distinguish the suitability of mutable record structs:
- Using a struct as a dictionary key does not carry the same risk of getting lost in a dictionary (assuming no self-modifying member is provided).
- There are reasonable scenarios where mutable fields are not problematic (like with
System.ValueTuple). - Supporting mutability and fields in record structs allows for tuples to easily be “upgraded” to record structs.
- Record structs include the
readonlymodifier, which renders it immutable with a single keyword.
Note: As of this writing in early September 2021, the decision about mutability by default has not been finalized.
It's relatively rare for developers to need custom value types, so I'm tagging this feature as #UsedOccasionaly. Even so, I appreciate all the careful thought put into the ability to define value-type records. More importantly, almost all value types require implementation for equality behavior. For this reason, I suggest you consider a coding guideline: do use record structs when defining a struct.
Default (Parameterless) Struct Constructors
C# has never allowed a default constructor (a parameterless constructor) on a struct. Without it, there also isn't support for field initializers on structs because there's no place for the complier to inject the code. In C# 10.0, this gap between structs and classes is closed with the ability to define a default constructor on a struct (including a record struct) and allowing field (and property) initializers on structs. The following snippet provides an example.
public record struct Thing(string Name)
{
public Thing() : this("<default>")
{
Name = Id.ToString();
}
public Guid Id { get; } = Guid.NewGuid();
}
In this example, you define an ID property that's assigned with a property initializer. In addition, the default constructor is defined and initializes the Name property to be the Id.ToString() value. It's important to note that the C# compiler injects the field/property initializer at the top of the default constructor. This location ensures that the C# compiler generates a primary constructor for the struct and ensures that it's invoked before the body of the default constructor is evaluated. Conceptually, this is very similar to how constructors on classes behave. Property and field initializers are also done inside of the generated primary constructor to ensure that those values are set before the body of the default constructor is executed. The effect is that the ID is sent by the time the user-defined portion of the constructor executes. Be aware that the compiler enforces the this() constructor invocation when a primary constructor is specified on the record struct.
Because default constructors were previously unavailable, guidelines dictated that default (zeroed out) values were valid even in an uninitialized state. Unfortunately, the same is true, even with default constructors, because zeroed-out blocks of memory are still used to initialize structs. For example, when instantiating an array of n Things - that is, var things = new Thing[42] - or when not setting member fields/properties in a containing type before accessing them.
Additional Improvements in C# 10.0
There are several other simplifications in C# 10.0. I put these in the category of you-didn't-know-this-wasn't-possible-until-you-tried. In other words, if you encountered these scenarios before, you were probably frustrated by the idiosyncrasy but worked around it and continued. With C# 10.0, the issue is eliminated. Table 1 provides a list of such features along with code samples.
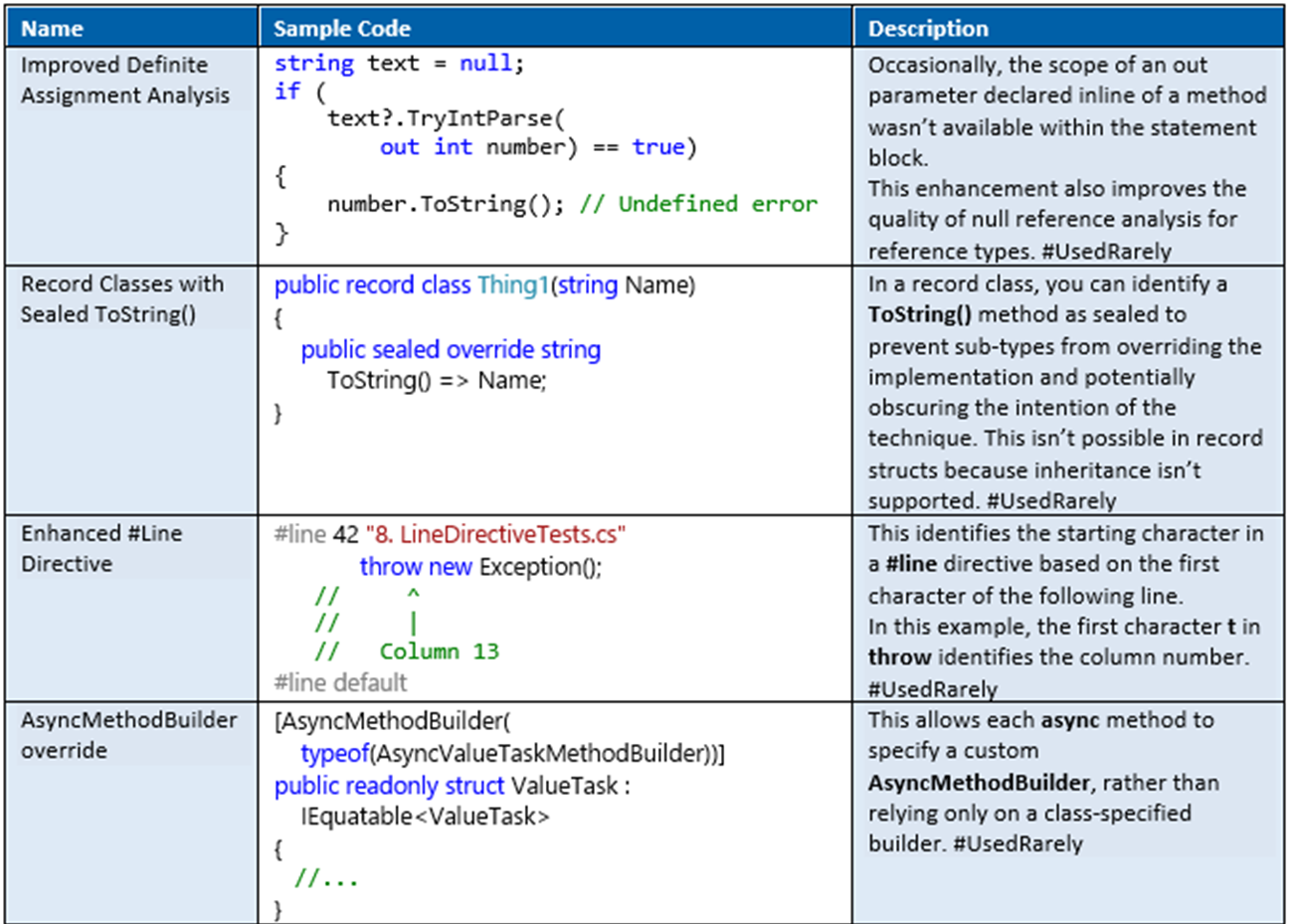

What's Not in C# 10.0
Several planned C# 10.0 features didn't make the cut.
nameof(parameter)inside an attribute constructor won't be supported.- There won't be a parameter null-checking operator that decorates a parameter and then throws an exception if the
nullvalue is used. - Generic attributes that include a type parameter when using the attribute.*
- Static abstracts members in interfaces forcing the implementing type to provide the member.*
- Required properties so that the value must be set in a compile time-verifiable way before construction completes
- Field keyword that virtually eliminates all need for a separate field to be declared.*
Asterisked (*) items are available in C# 10.0 preview, but are expected to be removed before general release.
Of these features, I was most looking forward to the null-checking operator, but at the same time, I'm holding onto hope for a more generic solution to arrive that provides parameter checking for more than just null. Having support nameof(parameter) in method attributes will also be great, both for CallerArgumentExpression attributes as well as ASP.NET and Entity Framework development.
Summary
There are many relatively small “improvements” of C# 10.0; I don't really see them as new features. Rather, they are the sort of things that I previously assumed were already possible only to encounter compiler errors after coding. Now with the improvements in C# 10.0, I'll likely forget the time prior when they didn't work.
Beyond just the improvements, admittedly there isn't anything revolutionary in C# 10.0, but it certainly includes some features that will change the way I code: global using directives and file-based namespace declarations, to name a few. Although it's something I'll rarely code myself, I'm eager for logging, debugging, and unit testing library developers to update their APIs with support for caller argument expression attributes. Triage and diagnostics will be easier with the new APIs. And, although I think that defining custom value is rarely needed, the addition of record structs certainly makes it easier with all the equality support. For this reason alone, I suspect it's rare that someone would define a custom value type without using record struct.
Putting it all together, C# 10.0 is a welcome addition with a healthy set of features and improvements - enough enhancements, in fact, that I'll be disappointed whenever I have to program with an earlier version of C#.
