





Microservices: a buzzword that everyone uses nowadays. Books, blogs, and articles praise them as the holy grail, a single approach that will solve all your problems. All of the nice features that come with this architectural style, like, for example, flexibility, modularity, or extensibility, appear awesome to architects, developers, and tech managers. Indeed, that's very attractive, and therefore the step from hearing about that style to adopting is one that most decision-makers take within seconds. But, honestly, do you know the feeling when something sounds too good to be true? When you have the feeling there must be a catch? I had that before applying microservices the first time.
Most of you know what I'm talking about. Developing microservices is hard and keeping them up and running is even harder. Constantly observing them and evaluating error logs causes pain. Further, every time you change something in a service, you must think about how it affects other services. What makes it so hard? What fundamental issues with microservices need careful thoughts?
First, defining the scope of a microservice turns out to be an extremely challenging task. When you define the scopes of your microservices to fine granular, the services become terribly chatty. By chatty I mean that to complete a client request, the microservices communicate a lot to gather all necessary information. Bear in mind that each service-to-service interaction comes at a price - labeled latency - which the client applications pay in terms of poor user experience. By contrast, when you define the scope of your microservices to coarse, you essentially build monolithic silos of services. The user experience may improve due to short response times, but you lose any kind of flexibility or extensibility without disrupting client applications.
Second, let's assume that you found the right granularity for your microservices and they nicely align among each other. Further suppose that all services are based on .NET technologies. When strictly applying microservices as an architectural style, you'll face a lot of code duplication, especially boilerplate code for infrastructure. Every microservice requires some initialization logic for a database, a connection to a tracing provider but also logging or health checking. Further, how do you use all these cross-cutting concerns and their implementations that all services share efficiently? In such cases, unfortunately, many developers apply one of the most famous anti-patterns: copy-and-paste. This comes with tons of disadvantages, most notably that identical code snippets appear in each service but also that bug fixes may take ages to go online.
Third, sometimes the organization of the source code becomes the main obstacle of development. Very often, all service implementations reside within the same solution. It sounds reasonable at a first glance, doesn't it? When everything resides in one place, it's easy to keep track of changes, it's easy to reuse stuff from other microservices (especially the models they implement), and so on. Wait. Rewind. Easy to reuse models from other microservices? That's a no-go. Why? Because every time you need to change a model that two or more services share (and use), all services must update. This is against the flexibility of the grail! So how do you escape from these issues? How do you navigate around them?
In this article, I want to take you on a journey of how to master these fundamental issues. I'll start by providing a blueprint for each microservice. The blueprint, a ports-and-adapters approach, defines the architecture of an individual microservice, especially how assemblies of a service depend on each other. Next, I'll show you how to apply patterns and principles from domain-driven design (DDD) to define the scope of each microservice. Why does it make sense to use them in this context? The services support a certain business and changes emerge (most of the time) from a certain business field. If you nicely align your microservice landscape with the shape of the business they support, changes affect (most of the time) only one individual microservice. To speed up the service development in general, I propose to use the service chassis pattern for all cross-cutting concerns, like database abstraction, logging, or tracing. Applying this pattern tremendously increases the development speed of your teams, because pushing trace information or logs is identical for all microservices. Distributing the service chassis as a NuGet package effectively decouples services from the implementations of the cross cutting concerns. Finally, I talk about source code organization, especially how to isolate microservice development to prevent the reuse of code that shouldn't be reused. Further, my method provides you with a manageable structure that lets you easily keep track of changes and release new services frequently without breaking your system all the time.
Let's Start the Journey!
I want to start this journey by talking first a bit about microservices in general. Precisely, I want to give you an impression of what microservices are about, which characteristics they have, and why it makes sense to adopt them.
In short, microservices correspond to a variant of service-oriented architecture (SOA) in which an application comprises several loosely coupled services. Each of the microservices delivers some business logic that produces value for your customer. The microservices within a microservice architecture have important characteristics:
- Services are autonomous: The approach for developing a microservice may differ from microservice to microservice, potentially even down to the programming language. It's up to the team that implements the microservice to decide which approach, technologies, and languages to apply or use.
- Services are independent: Deploying a new service or updating an existing microservice doesn't affect any of the other microservices within a microservice architecture. They run independent of each other, and teams change them on-the-fly, if necessary, without disrupting other services.
- Services are loosely coupled: In an ideal world, microservices couple only loosely among each other. By coupling, I mean here how the services depend on each other, which models they share, etc.
- Services build around business capabilities: In contrast to traditional service-oriented approaches, the services within a microservice architecture build and evolve around business capabilities rather than technicalities.
Figure 1 depicts a typical microservice architecture for a food ordering application. The client application accesses the microservices to deliver functionality to the user. Each of the microservices comes with its own database, and they don't depend on each other. A specific microservice here addresses exactly one part of the overall business domain. For instance, the order service deals with ordering meals at restaurants. The delivery service waits until the user completes an order and then notifies a courier to deliver the food to the user. For that purpose, the delivery service queries the account service to get the address of the user. However, the client application doesn't even know after completing the order that the delivery service looks up a free courier to bring the food to the user. And the client application also doesn't want to know how the back-end handles it: it just cares that someone completed the job.
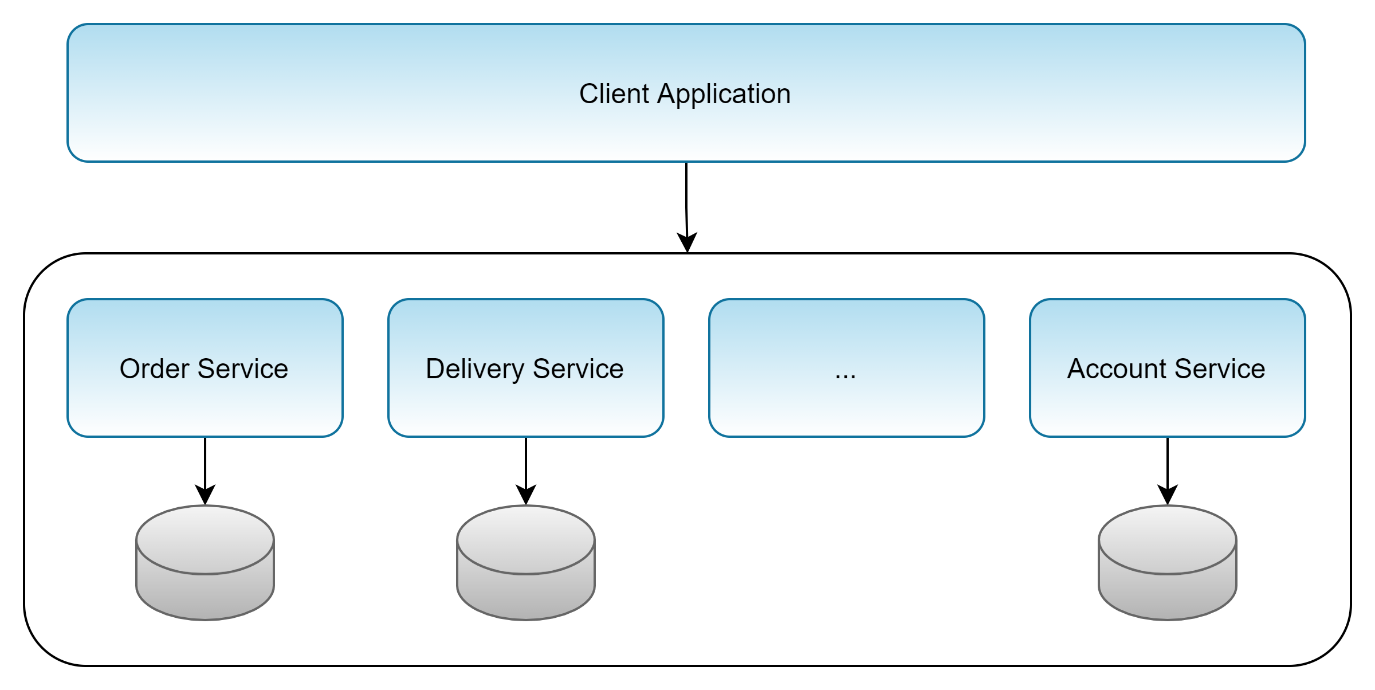
Usually, client applications communicate with the microservices by using HTTP requests. It has become quite common practice to rely on this protocol. However, you may also want to go with gRPC in some cases, or other protocols. Down the line, all of these technologies serve one ultimate purpose: abstracting the communication between client and microservices.
What makes microservices so powerful? The main reason, before we go on this journey, is the following: Applications get very slim, because all business logic runs in a back-end. In an extreme case, the application consists only of front-end code, and doesn't contain any form of business logic anymore. You write a mobile app and a desktop application with the same business logic without any overhead (in terms of business logic). Further, microservices enable you to write to multiple applications that rely only on a subset of the business logic by using only particular services. In other words, in choosing the services on which your application relies, you define the scope of functionality to deliver with your application. In addition, microservices eliminate the necessity to duplicate your business logic into multiple applications repeatedly. Furthermore, when you roll out a bug fix, the client applications don't require an update, because the update happens in the respective microservices only, and all client applications immediately receive the bug fix without any effort.
I hope I managed to convince you to adopt the microservices architectural style, which you'll now use as a starting point for your journey.
First Stop: The Blueprint of a Microservice
Before starting to code, you need to choose the implementation language and the architecture of the microservice. For the former, I assume C#. The latter choice is much more subtle, and a careful selection here will turn out to be essential later. Let's rough out some ideas about how to structure an individual microservice before you choose a pattern for the blueprint.
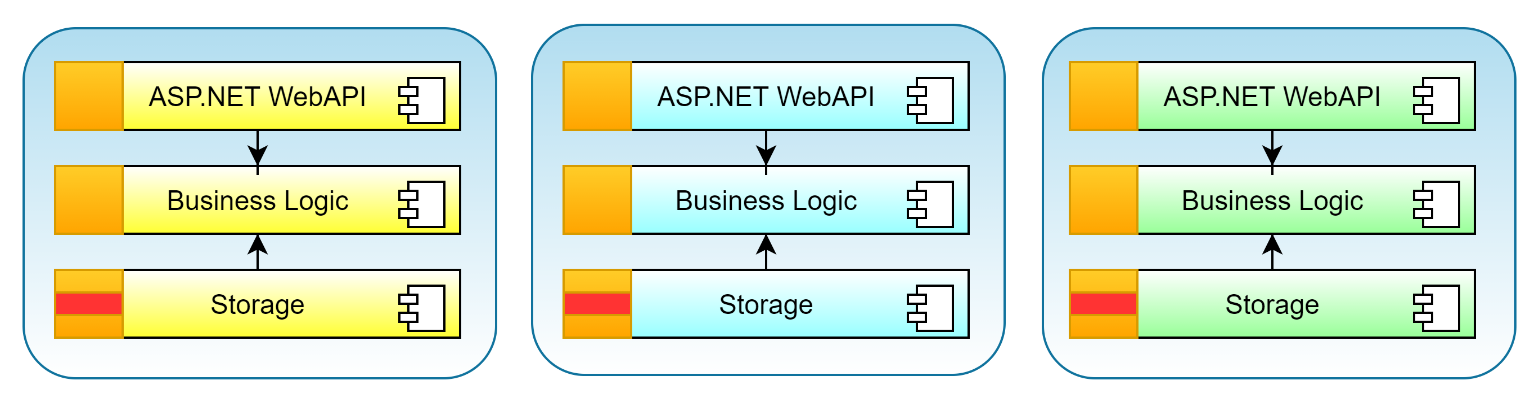
The first option corresponds to a layered approach for each service (see Figure 2). In such an approach, the dependencies between the projects comprising the service follow a strict hierarchical ordering. Usually, the layers include an ASP.NET WebAPI assembly (containing the HTTP endpoints of the service), a business logic assembly, and a storage assembly containing the data access layer. The ASP.NET controllers in the WebAPI assembly use the business logic assembly, which, in turn, uses the storage assembly.
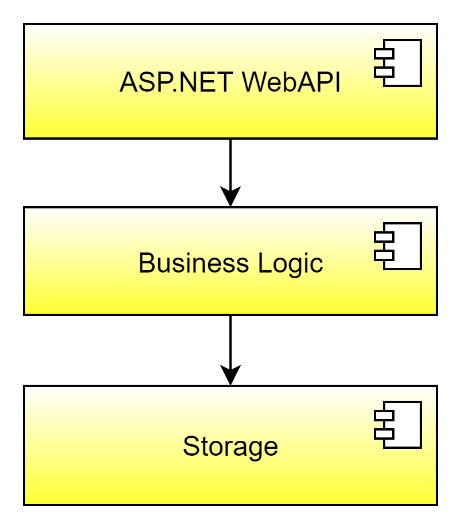
All dependencies point in a specific direction: from top to bottom. This approach is quite simple and common. However, it comes with several disadvantages. For example, because the business logic directly depends on the storage assembly, you can't simply exchange the database that the service uses without disturbing the business logic. That's rather awkward, especially when you think about running the services in a cloud with tons of different database products. The pain comes when you want to evaluate different products, because it triggers changes in your business logic assembly due to different provider APIs all the time. Therefore, let's rule out the layered approach to microservices.
Let's take a look at another option, a ports-and-adapters approach, like in Figure 3. In this architectural style, the business logic lies at the heart of your service, surrounded by all other assemblies that the service comprises. Such assemblies include storage and ASP.NET Web API, but maybe also other stuff, like logging, tracing, messaging, and others. Crucially, all these assemblies depend on the business logic assembly. You wonder why? Because the business logic assembly defines the interfaces, also known as ports, that the business logic intends to use to communicate with the outside world. This keeps the business logic extremely clean, because it defines - solely in terms of interfaces - how to interact with the environment but doesn't contain any implementation of them, known as adapters. The environment here includes all cross-cutting concerns to a service, like logging, tracing, messaging, health checks, or data storage. Of course, to bootstrap the service, the ASP.NET Web API part may require further dependencies for registering all implementations into a dependency injection framework. However, the ASP.NET Web API part doesn't logically depend on those implementations.
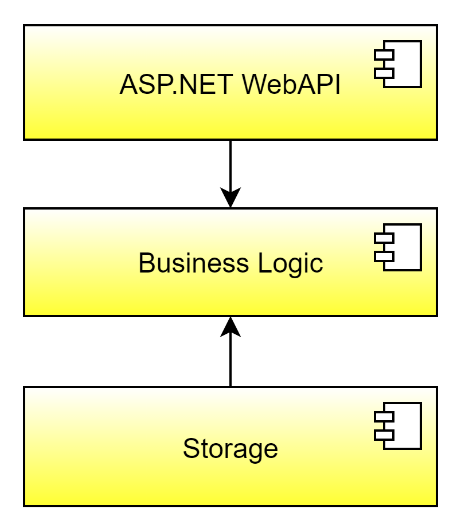
Let me make it more precise. Suppose the business logic assembly needs to persist data (which almost all services do at some point). For that purpose, the business logic assembly contains an interface, IRepository, which declares methods like Add, Update, Delete, and FindById. The business logic assembly uses this interface in workflows to persist or load business objects from a database. The implementation of IRepository resides within the storage assembly and may be dependent on the database provider. Abstracting the database access in that way enables you to easily replace the database provider that a service uses from the business logic perspective, because the business logic only knows about the interface, but not about the concrete implementation. In summary, I propose: The ports-and-adapters approach will serve as a blueprint for all microservices.
The ports-and-adapters approach serves as a blueprint for all microservices.
The blueprint of Figure 3 serves as a service skeleton, and because applications consume your services in the end, I further extend the blueprint slightly. For that purpose, put your application developer hat on, and think about how you'd like to consume the service. First, you need to know the endpoints the service offers. Second, you must know the data structures of the service to pass information to the service, or to get results from the service. The literature refers to this kind of data as data transfer objects, DTOs for short. The DTOs correspond to C# classes that consist only of properties with getters and setters - no methods. In C# 9 (.NET 5), it makes perfect sense to use the record feature to define the DTOs in a concise way. This reduces your overhead for such objects a lot. Finally, to offer the DTOs to the application developers, you create a service access assembly for each service. This assembly then contains all the DTOs and you distribute it as a NuGet package to the applications. If you want to raise the first stop to a five-star hotel, also create a service client implementation in this service access assembly. This service client wraps the transport protocol, like, for example, HTTP for client applications, thereby hiding the access to the service from the client. The service client knows how to reach out to the endpoints of the service, serializes and deserializes the DTOs, and deals with other concerns about the service, like, for instance, security. Figure 4 shows the final service blueprint.
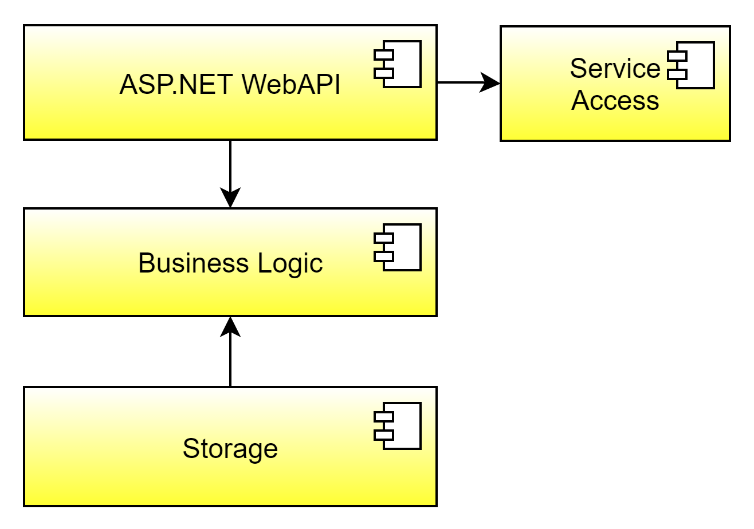
Next Stop: Service Scope
The ports-and-adapters architectural style serves now as blueprint for an individual microservice. But how do you define a microservice in the first place? Which logic should a service cover? Where do you draw a boundary between services? The second stop of the journey deals with these kinds of questions, and I'll provide you with some (hopefully satisfactory) answers.
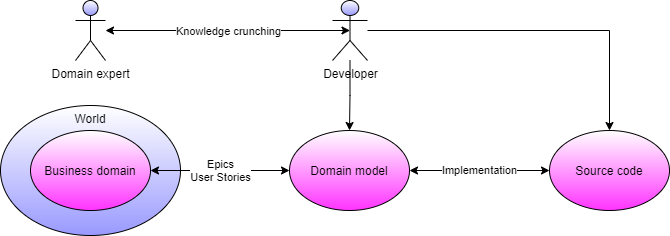
First, ask yourself why you implement the services. “Because I got told to do so by my boss” doesn't count as an answer here. “To support our clients in their business” sounds better, doesn't it? And this also gives you an answer to the question of what belongs to a particular microservice and what doesn't. Why? Because services support a certain business domain, they enable you to apply domain-driven design! Domain-driven design (DDD) differentiates two categories of players: the domain experts (aka the users) and the developers (aka you). Both have certain objectives. The domain experts want to use software that they like and which supports them, whereas the developers (should) want to deliver something useful to the domain experts. Both strive for the same goal: Useful software!
To reach that goal, DDD builds on a close collaboration between domain experts and developers. Specifically, the developers try to gather as much information as possible from the domain experts, which they use to (at least abstractly) align the software design (comprising classes, interfaces, and so forth) with the real-world business domain objects and their associations. For that purpose, the developers and domain experts catch up frequently to talk about the business domain, also called a knowledge-crunching session. These sessions produce either epics, which correspond to longer paragraphs describing certain domain processes, or user stories. Developers use these epics and user stories to ultimately design the business logic assembly of the service blueprint that you saw in Figure 3 and Figure 4.
A Short Break at the “Domain Model Motel”
After collecting some epics and/or user stories, the developers start designing a domain model. For that purpose, they use the epics and user stories to figure out the objects and their interactions in the business domain. DDD differentiates different kinds of objects in such models:
- Value objects: Objects without any meaningful identity to the business. You consider two value objects identical when all their properties match.
- Entities: Objects with a meaningful identity to the business. The difference from value objects is that even though two entities may have the same properties, they are not the same due to their identity.
- Aggregates: A group of objects that conceptually belong together and very often have some form of parent/child relationship around which you can build business invariants. They group entities and value objects together and accesses to child objects are only through the root of the aggregate.
- Services: Workflows that don't fit into any of the other kinds of objects. These often involve many entities or aggregates, and the service orchestrates the workflow in a stateless manner.
- Repository: An object to persist entities or aggregates.
- Factory: An object to create entities or aggregates.
- Domain event: An event happening in the domain that an expert cares about.
All of these objects boil down to C# classes (or interfaces) in the end, and the relationships among them align somewhat with the associations among the real-world objects within the business domain. However, keep in mind that you need only model what's crucial to the expert. Abstraction wins here! When you start modeling everything in the real world, you end up with an overly complicated model that no one understands, and which slows you down in the end. Specifically, when you model, and consequently also implement, all the objects that appear and interact in the business domain, both the crucial ones that the business absolutely requires and the non-crucial ones that the business doesn't really care about, you waste a lot of time. In contrast, when you figure out what's essential to support the business domain, then you get it right, and your software succeeds. Figure 5 summarizes the situation.
Let's consider a concrete example to illustrate the process to get to a domain model. Suppose you need to develop an application that supports an online shop, and you talk to an employee in the logistics/shipping department. He tells us the following:
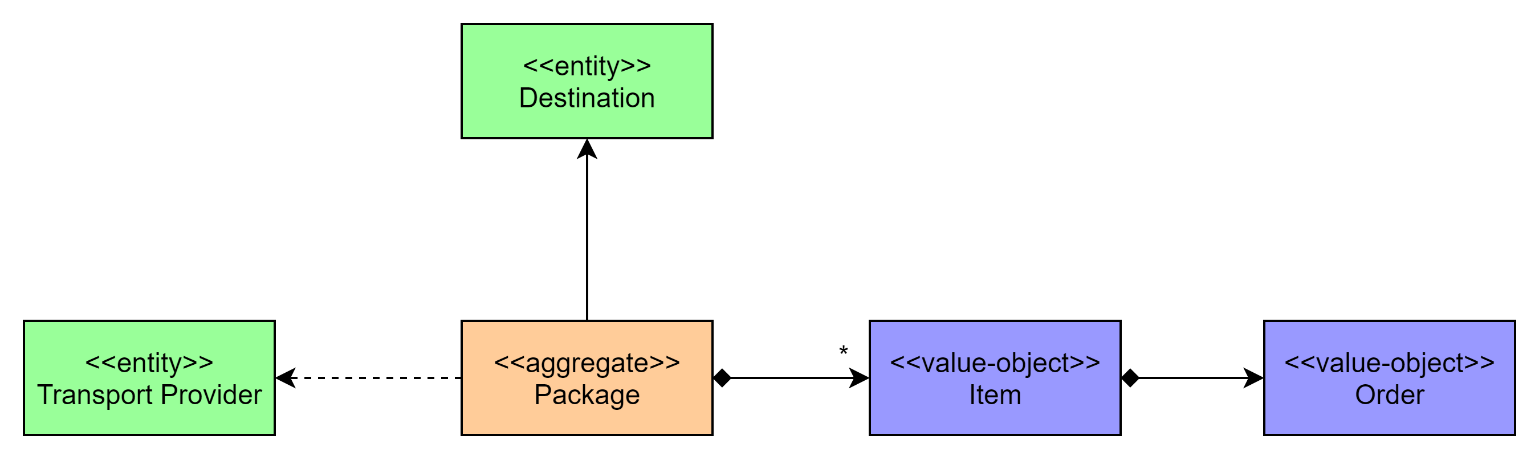
“I receive orders from customers in the shop directly after they pay, when their order completes. What's important for me is the weight and the dimensions of the items in the orders. I try to pack as many items as possible into a package, from potentially different orders, because then I minimize the shipping costs for the company. There's a maximum weight for each package, depending on the transport provider I choose. After sending the package, I can track the package until it reaches the destination. The destination of the package can change right up until the package leaves our department.”
This small paragraph gives us a lot of insights into the domain in which the employee works. For example, you infer that there exists something like an item. He characterizes the items by weight and dimensions and you safely assume that items don't change over time, thereby implying that they correspond to value objects. Each item links to an order. The state of an order doesn't change from the perspective of the employee. Further, the employee tries to pack as many items as possible into one package, which he sends to the customer via a transport provider, an entity. A package only makes sense if the employee puts at least one item in it, because otherwise he would have nothing to send, right? Additionally, the employee assigns each package a destination that he's free to change until the transport provider picks up the package. Finally, he tracks the package after sending it to the destination. So,you can conclude that the package is an aggregate. The resulting domain model subject to implementation looks something like Figure 6.
Before I move on to the hotel for this stop, I want to provide you with some guidelines and hints about how to identify value objects, entities, and all the other model elements in DDD. They aren't strict rules, just hints to help you:
- Nouns correspond very often to value objects, entities, or aggregates, hence classes.
- Objects that don't change after they “come to life” correspond to value-objects.
- Objects around which you can identify business invariants are usually aggregates.
- Objects that change the internal state during their lifetime suggest entities when you can't identify an invariant around a group of objects.
- Verbs usually refer to methods because they “act” on objects.
- Processes that involve many nouns point at services.
Hotel for a Stay at Service Scope: Bounded Context
If you talk to domain experts working in the same field, you most of the time end up with one domain model. What happens now if you talk to domain experts from several fields of the business? This leads us to the notion of sub-domains and bounded context.
Business domains naturally break down into smaller units, so-called sub-domains. Many times, sub-domains align with organizational boundaries of companies. Sub-domains correspond to cohesive parts of the overall business, and they have only very few connections to other sub-domains. To support sub-domains, or the cohesive parts of the overall business domain, DDD introduces the notion of bounded context.
A bounded context essentially boils down to an assembly or library that implements a domain model characterizing a cohesive part of the business domain. Most of the time, the bounded contexts align with the sub-domains of the business. To figure out where a domain model of a bounded context starts and ends, here are some ideas:
- The organizational unit of domain experts: Organizational units most of the time align with sub-domains, and they provide you with a good hint about where to cut a big model in two parts. Therefore, depending on which domain expert user stories originate from, you get a clue as to which bounded context to implement the user story.
- Same term in two or more user stories, but different meanings or characterizations: When you encounter the same term appearing in two user stories but with a different meaning, the respective user story implementation should reside in two individual bounded contexts. For example, suppose you have the user stories “As a customer, I want to be able to add items with a price to an order before completing the order such that I know how much I need to pay in the end” and “As a customer, I want to see pictures of the items I order such that I know what I am about to order” and “As a logistics employee, I want to know the dimensions of items such that I know how large a package needs to be” and “As a logistics employee, I want to be able to pack items according to destinations and characterized by weight into a package up to a maximum weight to minimize shipping costs.” The first two user stories tell us that a customer wants to place items with prices in orders to see how much the whole order costs, and that he also wants to see pictures of the items. Therefore, the customer cares about the price and pictures of items. In contrast, the logistics employee doesn't care about the price and pictures of an item at all. All he cares about is how to pack items in terms of weights and dimensions of potentially different orders together, up to a maximum weight, to minimize the shipping costs. As you can see, both users characterize “Item” totally different. This gives us the hint to implement the user stories in two different bounded contexts: the first two stories in the “Order,” and the second two stories in the “Shipping” bounded context, even though both refer to the same physical object. The two implementations will evolve completely differently, and further, changing them in one bounded context should not affect the other bounded context. Figure 7 shows the situation.
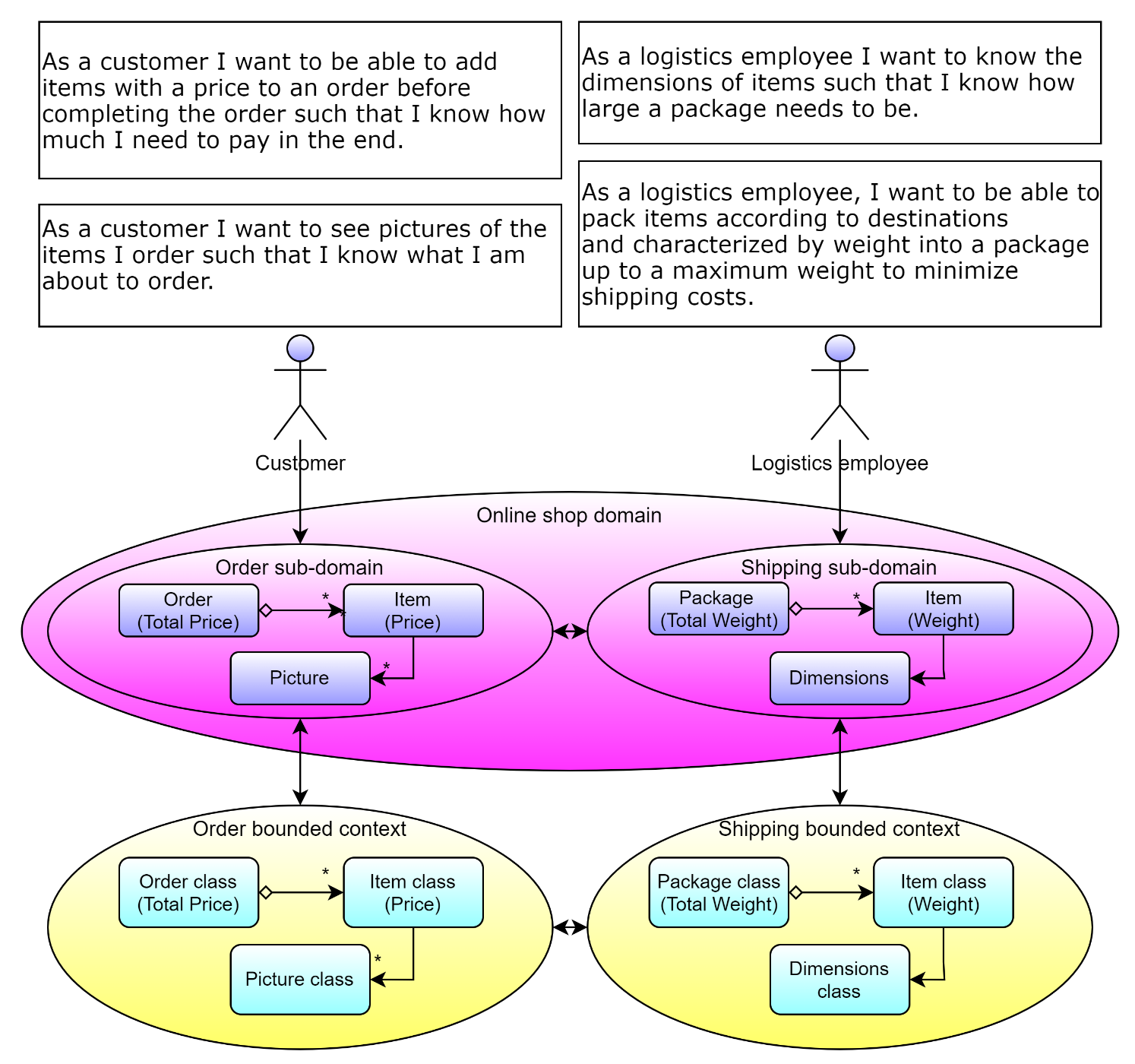
- Different terms for the same physical object in user stories: When you talk to your domain experts and they use different terms for the same object, you should implement the user stories in different bounded context. Why? Because the terms and words that domain experts use align with sub-domains. Each sub-domain comes with its own vocabulary to describe business processes. Therefore, when you identify that two user stories use different terms for the same object, you should implement them in different bounded context. This hint closely relates to organizational boundaries; however, I want to keep it as a separate hint for you.
Why are bounded contexts now so important? Let me provide some reasons why you want to stay in this hotel. First, they naturally somehow break down your whole implementation into smaller, more manageable units from a business logic perspective. Second, changes usually occur within a particular sub-domain, and they emerge from there. When your bounded contexts align with sub-domains, changes from one sub-domain will affect only one of your bounded contexts, thereby isolating changes within your application. Changes don't spread over many different assemblies when you align them with a bounded context, due to their cohesive implementation. Third, because bounded contexts only loosely couple to each other, for example via identifiers, you can easily exchange or evolve bounded contexts independent of each other without affecting or breaking other parts of your application. Finally, in case the business expands to new sub-domains, you don't have to change existing implementations, you simply add the new bounded context assemblies to your application.
How does this now relate to microservices? Well, because microservices support a certain business in the end, everything you went through before applies to them when you implement them using DDD.
Microservices align with bounded context.
Figure 8 shows the result of the stop.
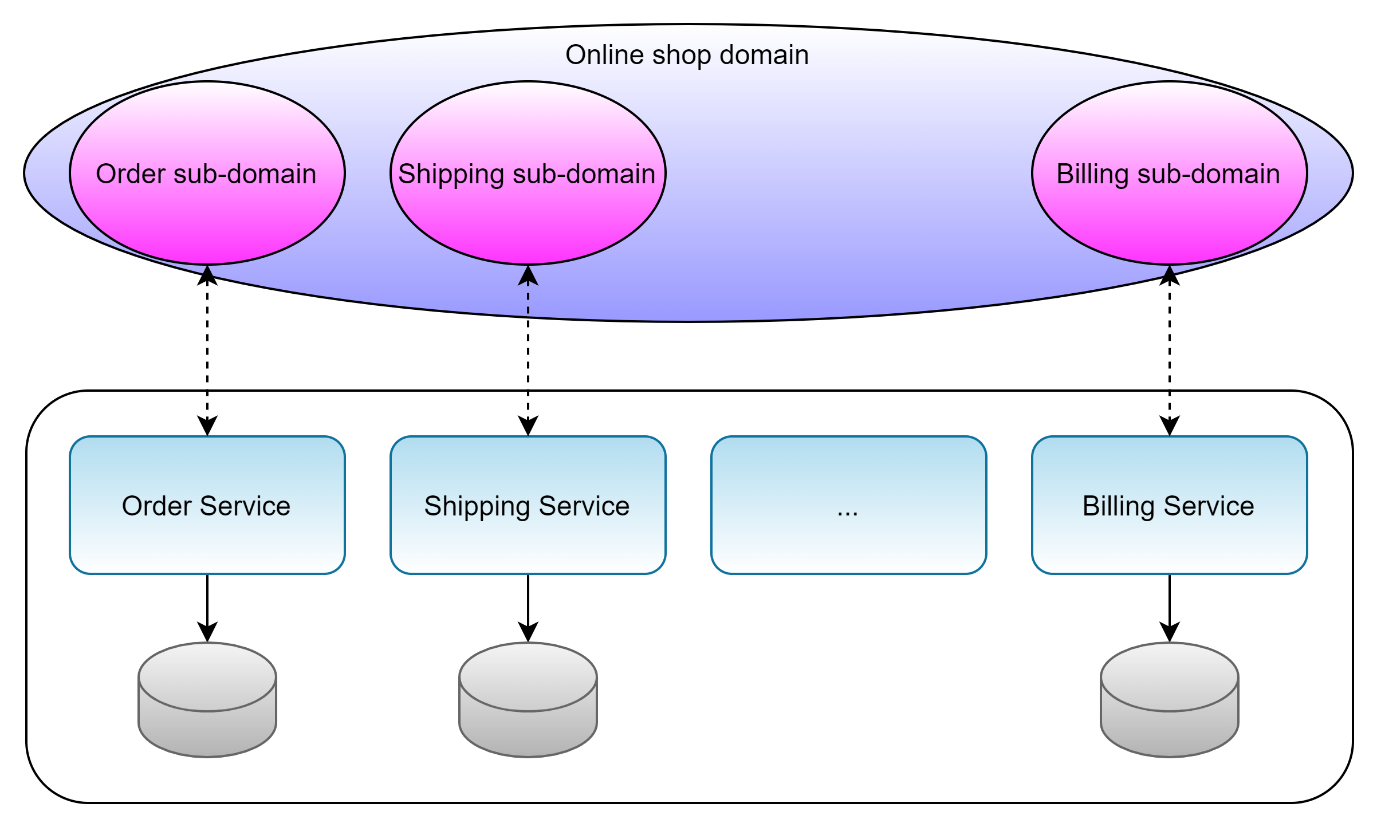
As you see in Figure 8, the whole domain breaks down into smaller sub-units. The back-end supports each of these sub-domains with exactly one microservice. Therefore, each microservice implements one bounded context. Further, to keep microservices independent of each other, they come with their own databases. This gives each microservice the freedom to use the most appropriate database technology, but also makes sure that changes to the data model in one microservice do not affect the other microservices at the level of persistence.
Detour: Save Money on the Journey by Minimizing Efforts
At the previous stop on the microservice journey, I showed you how to define the scope of a microservice by using patterns and principles from domain-driven design. You started the journey by selecting a blueprint for each individual microservice. In principle, we're done here! You can go and enjoy the rest of the day! However, I have more that I want to share with you, because it will speed up your service development tremendously.
So, let's go back to the service blueprint. I've chosen the ports-and-adapters approach for each microservice as the architectural style. When strictly adopting microservices, each of them, even though potentially written in the same language, contains its own source code for the common infrastructure, like, for example, tracing. When you have only two or three services, you can handle the duplication, but what about twenty or thirty of them? Even though the code duplication appears very little in each of them, a change in this duplicated infrastructure code suddenly propagates through thirty microservices. Developers must repeat the change over and over again, in thirty places. This is not only error-prone, it also takes a lot of time. Figure 9 shows the main underlying problem.
How to speed it up? Trust me, you don't want to make the same change in each service. I suggest applying the service chassis pattern. The services chassis pattern works in the following way: Whenever you come across a cross-cutting concern that you know all microservices use, you create an assembly that all of them rely on. This effectively moves all cross-cutting concerns into a set of reusable libraries, which is called a service chassis or service chassis framework. Nice, eh? Microservices reference the service chassis as assemblies. The cross-cutting concerns include logging, tracing, messaging (communication in general), health checks, middleware, and storage, depending on your services.
You now may say, well, centralizing all that stuff in one place becomes a bottleneck for service development, because all services share it. And it's true, it centralizes a lot of code, there's no doubt about it. However, consider for a second how often the service chassis requires changes compared to services. Services usually evolve fast, especially if you try to push new features to your clients every month or so. But switching the logging provider, or the messaging system, happens very rarely, if at all. So, the service chassis, once you decide for specific providers, stays very stable. Therefore, changes in the service chassis are very unlikely, which means that this shared dependency doesn't cause much trouble.
Changes in the service chassis are very unlikely, which means that this shared dependency doesn't cause much trouble.
The service chassis framework serves even more than just cross-cutting concerns. You should also put all common stable implementations that all microservices share into them. For example, setting up the service host, the Web application start-up and swagger generation look the same across all microservices (apart from some parameters like the service name). Further, to interact with your bounded context, you maybe implement for each use case a command like in the command pattern such that the Web API doesn't directly interact with the domain model. Because all commands look very similar (creating a scope for logging, creating a unit of work for database transactions, publishing result messages or events to a messaging system, etc.), you may end up with something like a BaseCommand in each microservice. Therefore, you move BaseCommand to your service chassis framework. Specifically, the overall service chassis framework consists of three different parts:
- ServiceChassis.WebApi: This assembly contains all of the code common to all Web API projects of your microservices. It includes setting up the service host, starting and connecting providers of cross-cutting concerns, together with their registration to the dependency injection framework.
- ServiceChassis.Domain: This assembly contains all of the code common to all bounded context assemblies of your microservices. It includes
BaseCommandimplementations and static factories to keep a reference to logging factories. Further, it also references interfaces from cross-cutting concerns that the bounded context assemblies require to work, like for instanceIRepositoryorIEventBus(for messaging). - ServiceChassis.Storage: This assembly contains all of the code common to all storage assemblies of the microservices. The storage assembly of a microservice defines the data model that the service requires and some mapping or initialization logic to tell the service chassis where to find the data model, but not more. It still somehow lacks the glue code to access a concrete database via a provider, like OR mappers. This other code for the object-relational (OR) mapping you defer to a service chassis storage assembly. That assembly initializes some OR mapper like EF Core, contains repository implementations, data storages, etc.
Figure 10 depicts a microservice using your service chassis framework. Observe that the three different kinds of service chassis assemblies reference a set of common cross-cutting concern assemblies.
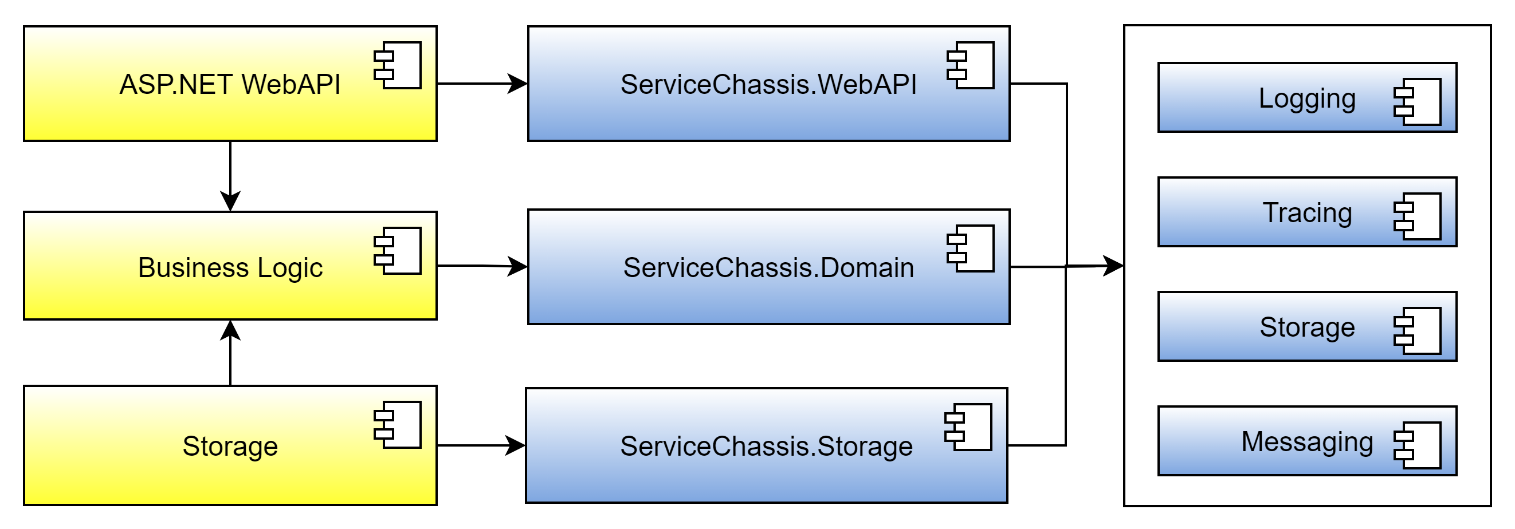
The services use a service chassis framework for cross-cutting concerns and common, stable implementations.
This looks like a good solution, however, by inspecting it closer, you'll observe several small things that you must tackle:
- How to hide concrete providers of cross-cutting concerns from your microservices.
- How to choose between different concrete implementations of a cross-cutting concern.
- How to efficiently distribute the cross-cut concerns to your microservices.
Let's start with the first one. How do you hide concrete providers of a cross-cutting concerns from your microservices? Well, for that purpose, C# defines interfaces, right? Every time you encounter a cross-cutting concern that your microservice requires, you simply introduce an interface for the cross-cutting concern you need to interact with. Of course, when defining these interfaces, be precise and define the interface in a logical, cohesive manner. Think about what the service chassis already supports, whether an interface already exists, and whether it makes sense to extend such an existing interface.
For example, consider messaging via an event bus. In case you're not familiar with messaging, don't worry, I'll provide a short description of how it works here. Suppose you have two microservices that need to communicate with each other. In principle, you have two options:
- Direct communication: In this scenario, the two services directly talk to each other. For instance, when the order service needs to communicate with the shipping service, the order service directly invokes the API of the shipping service. The order service needs to wait until the shipping service responds with the result of the operation, which completes the communication.
- Messaging: Here the services place messages on a dedicated component, usually referred to as message broker or event bus. Here's how it works. Suppose that the order service needs to communicate with the shipping service. The order service places a message for the shipping service on the event bus (publish), and the shipping service subscribes to messages that the order service publishes (subscribe). The event bus component is responsible for keeping track of which service subscribes to what kind of messages and notifies them when messages get published. The literature refers to this kind of communication style as publish-and-subscribe, and microservices that apply this style act in choreography. For instance, when the order service wants to tell the shipping service that it should prepare the shipping of an order, it publishes an OrderCompleted message on the event bus. The event bus, in turn, notifies the shipping service about the new order.
Figure 11 compares the two different communication styles from an architectural point of view.
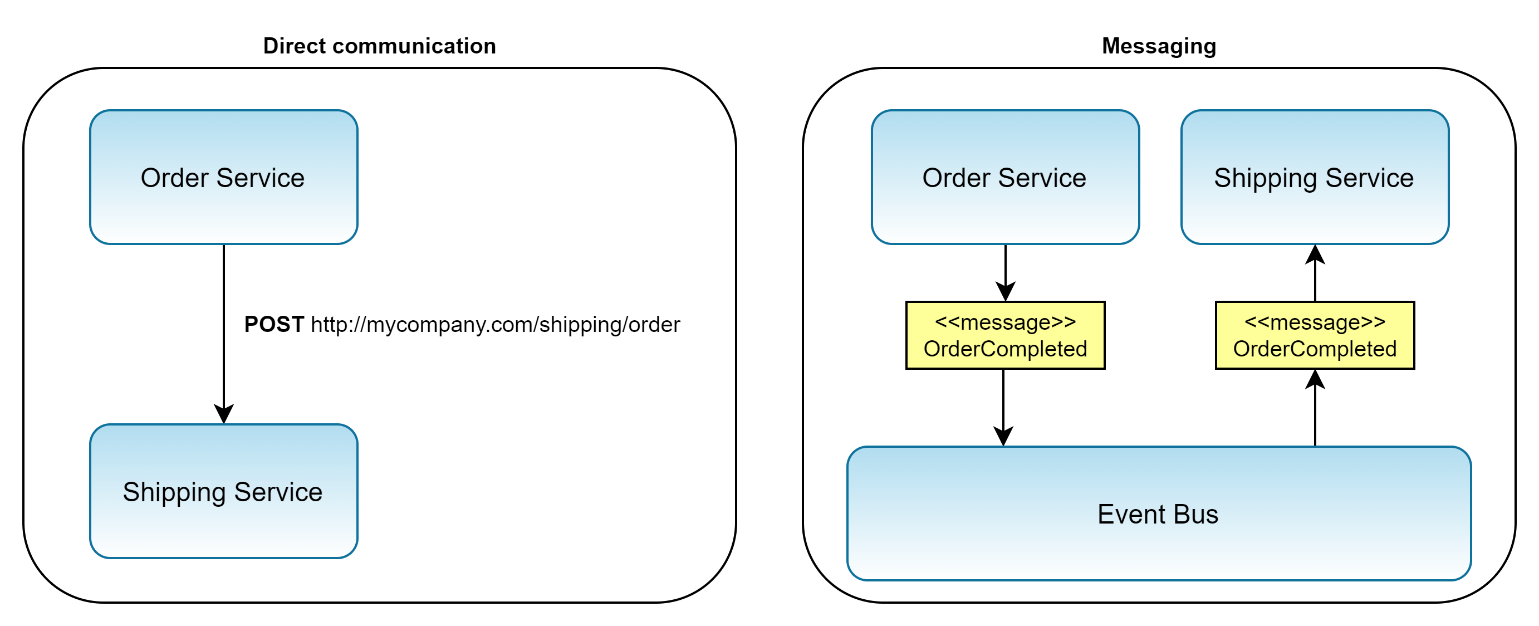
Both approaches have their advantages and disadvantages. Let's first investigate direct communication. In this approach, the services invoke each other directly by sending HTTP requests around. This is simple to implement and straightforward to understand, because it aligns with declarative programming languages like C#. However, direct communication comes with some big disadvantages. Services, for instance, couple very tightly to each other, a big disadvantage. For example, in Figure 11, the order service directly invokes some action on the shipping service. This means that whenever you can't reach the shipping service, the order service also stops working. That's a massive problem. Suppose your customers can't order because the shipping department needs to do maintenance. What a disaster! Your client won't sell any products! Additionally, the performance of direct communication becomes poor whenever many services need to communicate. Each and every service invocation costs time, which the user pays for with user experience.
Messaging mitigates some of these issues by effectively decoupling the two services. Both services couple to an event bus that facilitates the communication across all services. Therefore, services no longer directly depend on each other; instead, all services depend on the event bus. Having a single point of failure is never good, but here the pros outweigh the cons. Suppose, for example, you need to take down the shipping service due to maintenance. Now the order service doesn't care about it at all anymore! The order service continues publishing OrderCompleted messages on the event bus, and as soon as the shipping service comes back online, all the messages are received. Nice!
You can also use messaging to broadcast events in a microservice architecture. The service that produces the event simply publishes the message on the event bus. All services that care about this event subscribe to it. You can even use messaging to implement a reliable direct communication. This works in the following way: The service that wants to invoke a certain action in another service, such as the sender, publishes a Request event on the event bus. The receiver of this request listens to these request events and processes them. After completing the processing, it publishes a corresponding Result event on the event bus. By using the identifier of the request event within the response event, the initial sender knows that this result event corresponds to the previous request event. What you achieve by this is reliable and direct communication! Why? Because the receiver of the event doesn't need to be available when publishing the event in the first place. Similarly, when the receiver publishes the response event, the initial sender doesn't need to be available at all. The initial sender gets the result when he goes online the next time.
Enough with this short detour. I want to turn back to the service chassis and messaging. Now that you know how messaging works, the interface to such a system becomes rather straightforward, right? You need the following methods at least:
- Subscribe: With this method the service subscribes to events.
- Unsubscribe: With this method the service unsubscribes from events.
- Publish: With this method the service publishes a message on the event bus.
This ends up in the interface of Listing 1.
Listing 1: IEventBus interface for the service chassis
/// <summary>
/// Interface which all event bus/messaging system needs
/// to implement.
/// </summary>
public interface IEventBus
{
/// <summary>
/// Subscribing to an event with an event handler.
/// </summary>
void Subscribe<TEvent>(IEventHandler<TEvent> eventHandler)
where TEvent:IEvent;
/// <summary>
/// Unsubscribing from an event with an event handler.
/// </summary>
void Unsubscribe<TEvent>(IEventHandler<TEvent> eventHandler)
where TEvent : IEvent;
/// <summary>
/// Publishes the event on the event bus or messaging system.
/// </summary>
void Publish<TEvent>(TEvent @event) where TEvent:IEvent;
}
The interface contains only the three methods, not more. All services communicate with the event bus by using this interface only. This means that the services don't know which concrete provider, in the end, carries out the communication at all. They only rely on the IEventBus interface, not more. All of the events that the services publish should be kept centrally in a service chassis assembly, and all of them must implement the IEvent interface to comply with the interface of Listing 1.
For example, suppose the Web API project of the order service wants to place a new order. After placing the order in the database, the order service publishes an event, which other services subscribe to, like, for instance, the shipping service. Listing 2 shows the command to support this use case in the order service.
Listing 2: Command to add orders
class AddOrderCommand
{
private readonly IList<Guid> itemIds;
private readonly Guid customerId;
private readonly IServiceProvider serviceProvider;
public AddOrderCommand(IList<Guid> itemIds, Guid customerId,
IServiceProvider serviceProvider)
{
this.itemIds = itemIds;
this.customerId = customerId;
this.serviceProvider = serviceProvider;
}
public void Execute()
{
var eventBus = serviceProvider.GetService<IEventBus>();
using (var unitOfWork =
serviceProvider.GetService<IUnitOfWork>())
{
var orderRepository = unitOfWork.GetRepository<Order>();
var itemRepository = unitOfWork.GetRepository<Item>();
var order = new Order(customerId);
foreach (var itemId in itemIds)
order.AddItem(itemRepository.FindOneById(itemId));
orderRepository.Add(order);
eventBus.Publish(new OrderCompletedEvent(
order.OrderId, itemIds));
unitOfWork.SaveChanges();
}
}
}
It looks nice! The AddOrderCommand publishes the event OrderCompletedEvent after updating the repository, which makes sure that other services get the information about the new order. Importantly, the domain command, here AddOrderCommand, simply uses the IEventBus interface without knowing the concrete provider! Therefore, in case you decide to use a different event bus, the domain commands, and, in general, the business logic, stays the same. Dependency injection makes it possible!
Finally, you do the same trick for all your cross-cutting concerns, like logging, tracing, and others, which makes your service independent of any concrete cross-cutting implementation. You should structure the support for a specific cross-cutting concern in the following way:
- Define an
abstractionassembly, only containing the interfaces for how services want to interact with the cross-cutting concern, for exampleMessaging.Abstractions. Here you put the interface(s) for how to interact with the cross-cutting concern in a provider-independent way, and potentially also implementations that all providers have in common. - For each provider, define an assembly that implements the interfaces or extends the base implementations of the
abstractionassembly in a provider-specific way, for exampleMessaging.RabbitMQ. - Define an
initializationassembly, for exampleMessaging.Initialization, that the service chassis wrappers or services use to register the cross-cutting to dependency injection frameworks. Usually, this assembly contains very little code, only registrations to the dependency injection provider.
Each cross-cutting concern comes with an abstraction assembly, an initialization assembly, and provider-specific assemblies.
Next, I'll show you how to choose between different providers of cross-cutting concerns. For that purpose, recall that ASP.NET Web API projects require a configuration. This configuration may come from environment variables, or an appsettings.json file, depending on how you set up your service. For the sake of simplicity, I'll use the appsettings.json file, but you can do the same by using environment variables.
Each service comes with an appsettings.json file. Usually, such files contain information that the services require to run, like, for example, log level, connection strings to databases or similar. However, you can also use such files to configure the service chassis. By introducing a section in the appsettings.json file for each cross-cutting concern, you get the freedom to configure each service individually with respect to these concerns. The service chassis assemblies simply read the configuration during start up, and the initializer classes in the initialization assemblies of the cross-cutting concerns configure the chosen providers. Because all providers of a specific concern implement the same interface, the chosen provider is opaque to the service. Figure 12 shows the configuration approach with configuration files.
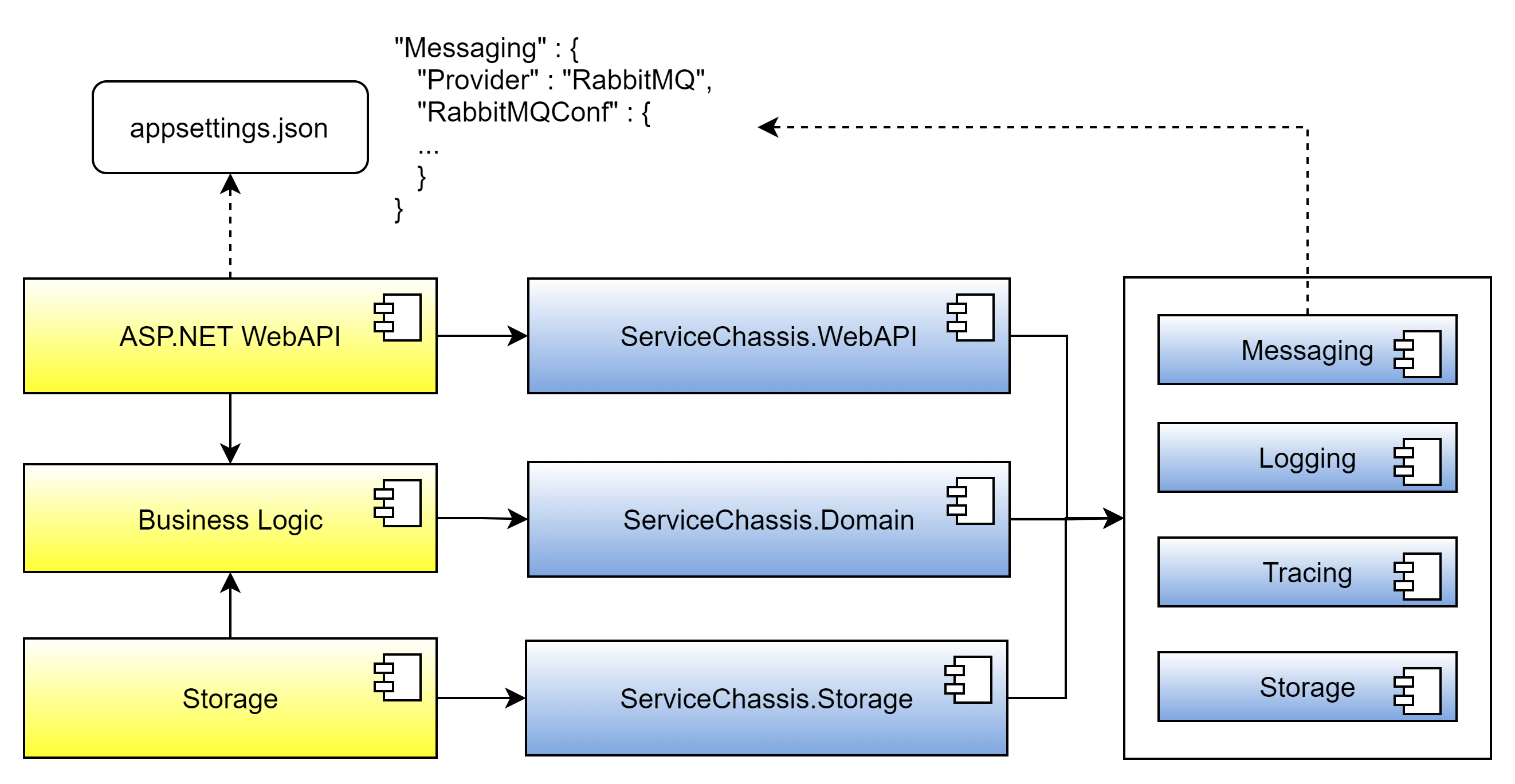
Make cross-cutting concerns configurable.
Finally, you want the services to use the whole service chassis in an efficient way. For that, several options are feasible:
- Option 1: Include the service chassis projects in your service projects.
- Option 2: Reference the service chassis assemblies.
- Option 3: Distribute the service chassis assemblies as NuGet packages.
Forget about option number one. This way of using the service chassis couples every service directly to the code base of the service chassis, which enables service developers to modify the service chassis within each service as they want. The problem here isn't the changes per se, but more how developers perform the changes. This approach can work when you have only two or three services, but when you have 30 or even more services, propagating changes in the service chassis framework to all services becomes extremely tedious.
Option 2 provides a cleaner solution. Referencing the service chassis as assemblies protects the service chassis framework from uncoordinated changes, thereby enforcing a certain pre-defined process to perform and roll out changes. However, I consider distributing these assemblies as still a problem, because it isn't clear how developers get to them.
Using NuGet packages to pack the service chassis assemblies together, Option 3, provides the cleanest solution. By using this approach, you get the benefits of Option 2 and solve the distribution problem in an elegant way. Service developers simply use a NuGet feed from within their service solutions to reference the service chassis framework. This gives you the freedom to control the versions of the service chassis framework efficiently, but also to perform changes in the framework in a controlled manner. The service chassis NuGet packages act like proxies for all cross-cutting packages, thereby reducing the number of references you must update in case some of the implementation changes.
Distribute the service chassis as NuGet packages.
Final Stop: How to Organize the Code Base
At the end of this trip, I want to talk about the organization of the whole code base. Why do I bother you with that? Well, organization is crucial, especially when you develop microservices. I have good reasons for that, because when the code base grows, and services communicate with each other, life starts to get tedious. You need to keep track of all changes happening in each service, which version of the service chassis the services use, which services communicate with each other, etc. There's a lot of stuff to oversee.
You should organize your source code cleanly from the beginning. Just letting the code base grow over time dooms you later when you realize you need to restructure everything. I want to save you this time. So where should I start? Well, I guess how to organize the repositories (see also Figure 13).
- One repository for each microservice
- One repository for each cross-cutting concern package (tracing, logging, etc.)
- One repository for the service chassis package
Have individual repositories for each service and each cross-cutting concern.
I know this reads as super strict and very picky, maybe even like an overkill, but I have my reasons for it. First, having a repository for each service enforces developers and teams to work independently from each other, specifically when you follow the common rule for microservices that one team develops one service. This gives you autonomy of teams because they won't interfere with each other during daily work. Second, having a repository for each cross-cutting concern gives you the same benefits as for services. Just suppose you have a team with three developers taking care of your cross-cutting concerns. Then you get the same autonomy as for microservices and also for evolving the cross-cutting concerns of your services. Particularly, developers changing different cross-cutting concerns don't interfere. Third, in case of using Git, which I assume you do, you can control the development process of services very nicely. For example, suppose your teams must fix a bug in the order service and implement a new feature in the shipping service. When you didn't properly split up your codebase beforehand into individual repositories, you have one repository hosting both services, and create two branches from the master to complete each task. In that case, things are already getting a bit messy. Therefore, it makes most sense to have one repository per service because it gives you more control.
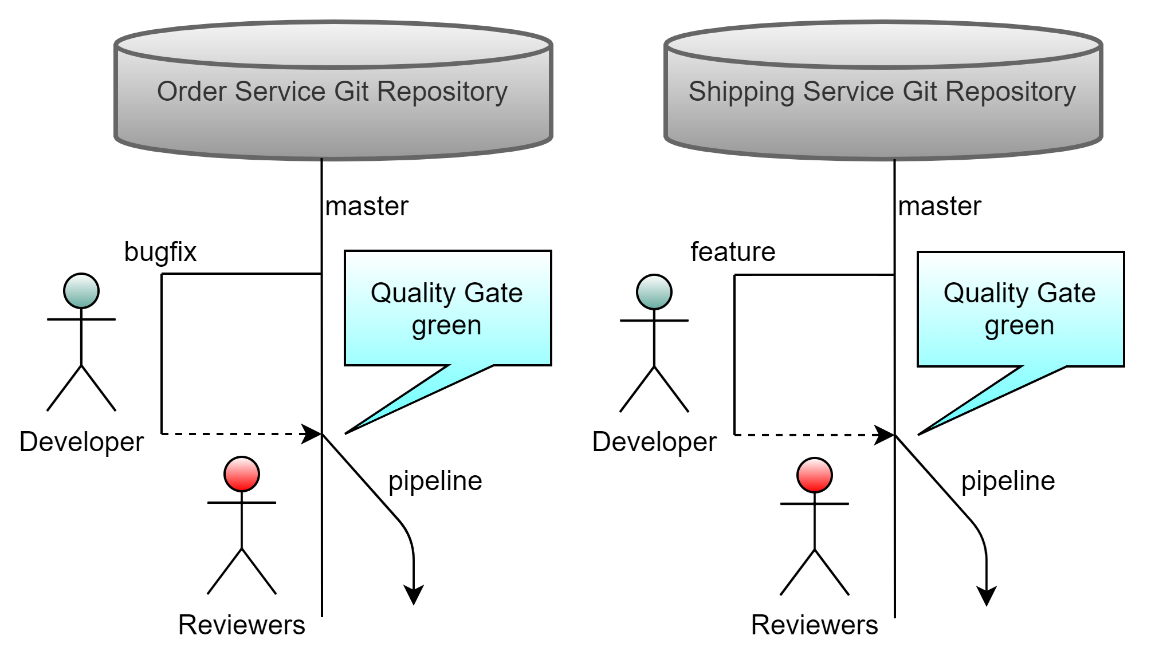
Let's walk through it step by step. Assume that you develop each microservice in a repository. Then you have at least a master branch within this repository, which corresponds to the latest release-able version of the service. Think about the following development process: For each feature or bug fix, you create a branch from the master, where developers work. In the end, when development completes, the developer creates a pull request from the feature/bug fix branch toward the master. Bringing the development back to the master by pull requests comes with a huge advantage: code reviews! Most source control systems let you configure mandatory/required reviewers for such pull requests, which makes sure that only reviewed code ends up in the master. Further, many static code analysis tools also nicely integrate with such systems and pull requests, and they even let you define quality gates with which the new code must comply prior to closing the pull request. By applying these techniques, you'll push the quality of your microservices to the next level! Finally, closing a pull request could also trigger different pipelines. For instance, the pipeline running on closing a pull request for a service could trigger a Docker build and push to a Docker repository. The pipeline for cross-cutting concerns could contain a push to a NuGet feed. Figure 14 summarizes these ideas.
Nicely separating services into individual repositories also gives you a lot of flexibility with regard to releasing your microservices. Assume that you ignore this article and put everything into one repository. And suppose you need to do a bug fix in the order service and a new feature in the shipping service. The bug fix in the order services completes sooner than the new feature implementation in the shipping services, which seems appropriate. In that case, you do a pull request from the bug fix branch master to complete the task. How do you nicely release that fix now? I mean, the feature branch of the shipping service remains open, which is not an issue in general. However, when you now release the order service, create a Docker image for the order service, and run it in Kubernetes or so, you also (I assume) archive your current master for maintenance or similar, or at least tag it. In that case, you probably need to archive or tag the whole master, even though you only changed one service. You oversee such a process for small numbers of services but consider that you have 30 services in the same repository. That will end up in a mess! The only way out of it is to split up this huge master into individual, independent pieces.
Splitting up the codebase in that way also naturally aligns with the dimensions in which applications usually change. Recall that changes to services most of the time emerge from the sub-domain they support. Therefore, having one repository per service gives you the right granularity to define and control the processes for releasing and evolving them. When a service requires a change, just create a new branch in the corresponding repository. When you need to release the service, close the pull request toward the master and release it. All other services and repositories don't need to be touched. The team implementing the changes works completely autonomously and independent of the other teams, providing them with a lot of flexibility.
Summary
Let me sum this journey up. I've shown you a way to efficiently develop microservices in the .NET environment. The journey included several stops. First, I looked at how to structure a microservice and how an individual microservice looks. Selecting one architectural blueprint for all microservices makes your life much simpler, because you can switch developers among teams quite easily. They know how all services look, which effectively reduces the time they need to understand overall service structures. Then I made a stop at service scope. This stop was essential to understand what makes up a single service. You align the scope of services with bounded-contexts from domain-driven design, which slices all your services in correspondence to the sub-domains of the business they support. Because changes usually emerge from there, you're prepared for them, and know exactly where to perform them. Apart from business logic, services also require some cross-cutting functionality like logging, tracing, and so on. The introduction of a service chassis helps you to tackle them in a consistent manner across all services and, at the same time, tremendously reduces the duplication of source code. Finally, applying the organizational approach from the last stop enables you to speed up development even more.
