


Readers aren't that interested in personal history. They want (and rightly so) meaningful content and code samples they can use in their work. I was a reader for almost two decades before I wrote my first article. I could quote the articles and code samples written by Dr. Dobb's Journal columnist Al Stevens from memory because I nearly worshipped his offerings. But occasionally I was interested in a personal story from a columnist and I have one relating to my future plans.
Exit Baker's Dozen…
In the summer of 2004, I penned my first article for CODE Magazine on the .NET DataGrid. I always wanted to write articles on productivity tips to help beginner- and intermediate-level developers. A fellow CODE Magazine author gave me a fantastic idea: “Here's what you do: Write 13 tips and call it a Baker's Dozen of Tips.” That name/brand wound up being a great form of identity/recognition. One time at a conference, someone approached me and say, “Hey, Kevin Goff! Baker's Dozen! I read your stuff!” I try to minimize using marketing terms, but that was real brand recognition.
Over the years, I've received encouragement and feedback from readers, and I greatly appreciate all of it. When CODE Magazine featured my September/October 2016 cover article on 13 great features in SQL Server 2016 with a box of pastries, I felt honored and humbled and grateful all at once. Just like the picture of the Boston Cream Pie on the cover, that entire idea was sweet!
It was a big challenge to write 13 meaningful tips. True, some tips have more pop than others, but I always wanted each tip to carry some level of value. Over the years, balancing that effort with a busy career and a family life, trying to write 13 worthy items just became too much. CODE Magazine's Editor-in-Chief Rod Paddock always wondered when the burden of writing 13 items would become overwhelming, and of course, it took me a long time to get past my stubborn nature and admit that the time had come.
I've only written a few full Baker's Dozen articles in the last two years, providing further evidence of how difficult it's been: All of the other articles have been shorter pieces on various SQL Server topics. Despite “never say never,” I believe I've written my last Baker's Dozen column. However, there's still plenty I want to write about. Where do I go from here?
“C'mon Batman, I Need a Name”
One habit I'll never drop is quoting movies (to the dismay of my editor). In “Batman Forever,” when Dick Greyson's character eagerly wants to join Bruce Wayne/Batman, he presses Bruce: “C'mon Bruce, I need a name!” (I loved Bruce's reply: "How about Dick Greyson, college student?")
Similarly, although maybe with less exuberance, I wanted to start a new brand, one that wouldn't burden me, one where I could naturally leverage what I've already been speaking about (data warehousing activities) for a long time.
Enter, Stages of Data….
Nearly every application I've built has been intensely data driven. I've dealt with data in health care, insurance, manufacturing, steel-making, finance, and several other industries. In every application, data goes through several stages before the business side can use it for meaningful information. When companies acquire other companies, that serves to compound the impact of “stages of data” and mapping data to conform to one common set of business definitions.
As an example, when an executive sees that a sales margin has dropped 15% for Product XYZ in a certain market, the lineage behind that number can be very complex. Therefore, it stands to reason that you must manage all of the steps that make up that lineage.
I like to quote movies, but I've also been known to read and quote more serious literature. William Shakespeare's “As You Like It” talks about the Seven Ages of Man, and of course, that play also contains the famous line, “All the World's a Stage.” The idea of the ages of man wasn't new: Aristotle wrote similarly about it. Likewise, Data Warehousing projects have life cycles, though, like snowflakes (no pun intended to star schema fans), no two life cycles are exactly the same. The more experience you have with the various life cycles, the more value you potentially can bring to future projects. In today's increasingly-competitive world, the more value you bring, the better!
That explains my new column name: “Stages of Data.” No one person, not even the greatest DW professional on the planet, can claim to have seen it all, but certainly, there are repeated themes across projects. Good data warehouse systems collect data from one or more systems and make it presentable to business users. When an executive gets a dashboard report showing that production is up in certain plants/sections, mechanical-shop defects are up in other areas, and monthly margin percentages dropped on certain products, that data has passed through many stages. If you don't properly manage all of the stages, from extraction to validation to mapping to final aggregation, you don't serve the business.
Okay, Production, Quality, and Margin Numbers. Sounds Simple, Doesn't It? Not Always
A monthly chart of these types of metrics might seem like a mundane task, right? Not exactly. Each metric represents a process. For each process, a system collects data either manually or through some automation. That data has a particular grain/level of detail. Keep something in mind: This is 2018, and many companies are merging/buying other companies, etc.
So that means that there are multiple source systems with different rules and different levels of detail. And even within one system, there can be sub-systems. Remember, the average turnover rate in this industry is about 18 months, which means that some teams aren't able to finish module/sub-system upgrades, which means any centralized solution might have to perform “double-reads” to get the full truth. Maybe your team agreed to do that for three months until new team members completed the upgrade. We all know how three months turns into six months, and what was once a short-term extra step has now become a (begrudgingly) accepted practice.
Then a new team comes in to build a new reporting system and no one formally documents the problem of having to do double-reads to get cost data. As a result, the new team believes that they only have to read X sub-systems to get a complete picture of the data, when it turns out that there are Y sub-systems.
Okay, convinced that it's not so simple? I'm just getting warmed up.
To Make Matters Worse….
There might be subject-matter data spread across sub-systems. Maybe cost-components A, B, and C are in sub-system 1, and cost-components C, D, and E are in sub-system 2. Perhaps sub-system 1 has some costs for component C that are not in sub-system 2, and vice-versa. It's possible that identifying the common values between sub-systems 1 and 2 for component C involve a mapping table that's maintained by some analyst in a spreadsheet.
Guess what? It could take days or even weeks of research to query (i.e., profile) that data to discover the whereabouts of that little detail.
Ever wonder why you read on LinkedIn that a high percentage of data warehouse projects fail? This is your future. Do you want it?
I've used a quote from a manager in the movie “A League of Their Own” many times: “It's supposed to be hard. The hard is what makes it great.” In the last year, my team put together a Costing Module that showed costs and profitability breakdowns based on raw cost and production data that the company had been collecting but never previously reported on accurately.
The production data went through many processes and gyrations such that no one source system accurately reflected the true picture of profitability. Our data warehouse Costing Module represented a “Version of Truth,” solving the proverbial Sphinx riddle by accounting for all the different stages of cost and production data in a methodical manner. The business was both stunned and happy. Acceptance by the business makes it GREAT.
At this point, some purists might say, “Okay, but that kind of mess is probably the exception.” I would debate otherwise. Although I can't speak for every environment out there, I'd bet an expensive dinner that it's common enough to be a big factor in why so many data warehouse projects fail (or only get half-built).
That's why I'm formally defining my new column brand here: “Stages of Data.” The more you know about the different stages that data can pass through, the different steps you need to look out for, and the more value you can bring to every step, the better.
I know others who have successfully built data warehouse functionality, and often these individuals have something in common: They are nearly “shadow-IT” in the business area, “shadow-business” in the IT area, and sometimes even competition for the company's formal research group. Because most shops either adopt (or pay huge lip service to) agile methodologies, a successful data warehouse professional needs to wear many hats in the course of a two-week development sprint. Versatility and, as I'll later discuss, preparation, are two of the many keys in a successful data warehouse project.
One last note: The concept of a “heads-down” developer is an oxymoron in the data warehousing world. Data warehouse professionals need to understand the proverbial big picture. If you hear a manager say that “heads-down” data warehouse developers can program from a complete spec, shoot them with a harmless water gun. If that manager also believes that someone can build complete data warehouse specs without tech knowledge and SQL skills, you have my permission to double-tap that water gun.
If your manager believes that someone can build complete data warehouse specs without tech knowledge and SQL skills, you have my permission to shoot them with a water gun.
High-level Topology, Revisited
Those who've read my recent articles should at least generally recognize the data warehouse topology diagram in Figure 1. I've modified it based on a recent speaking event where someone raised a question about a layer that I'd neglected to include: a report snapshot table layer.
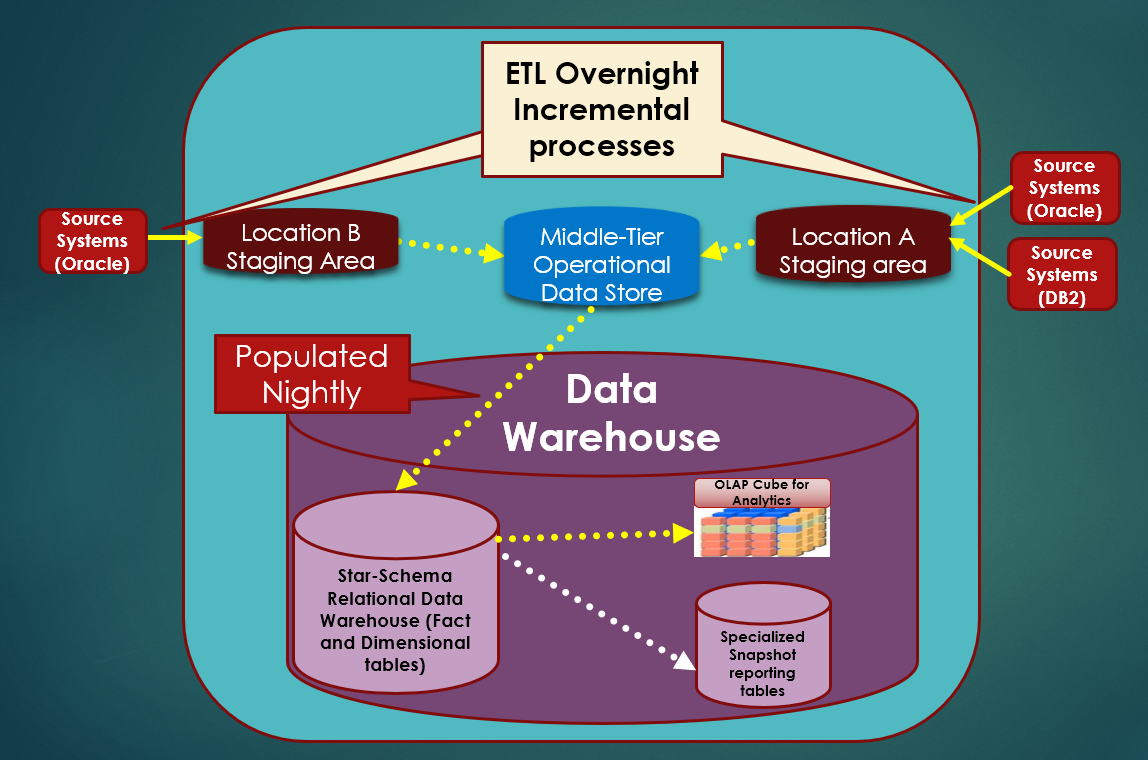
Ironically, I've used this layer for years, but never thought to include it in my presentation. Here's an example where report snapshot tables can help. Suppose you have an end-of-quarter lockdown process, and you report profitability and other metrics to executives. So maybe 30-60 days after March 31 every year, you close out the first quarter. The reason for the delay is to adjust for late-arriving sales adjustments and other lagging data.
When you close out the quarter, you might want to write out and preserve the state of the quarterly reporting data to a sales and margin snapshot table. That makes it easier (and usually faster) for people to retrieve and report on the data years later. No matter how much people have archived and changed the structure of data, you still have snapshots of the report data. I highly recommend this process. These tables are usually a fraction of the source data, because they're summarized for the lowest level of detail for the report and only contain columns associated with the report.
Additionally, I know people who also save all of the underlying data that makes up the report data! That can be a little more complicated if you're saving several years, as it might require a large amount of space. However, if you're in an environment where you need to justify something you reported on three or four years ago (I've been in that situation more than once), having all the underlying details that rolled up to the report snapshot might help you. Not too long ago, I had to defend a summarization from early 2015 that looked “odd.” Fortunately (it's a long story), I had a backup of the transactional data and was able to justify the summarization.
Data warehouse storage isn't the place to start nickel-and-diming about resources, ESPECIALLY if you work in a place where the level of accountability regarding reported numbers is very high. Repeat that 100 times.
Lessons Learned
If you read enough data warehouse material, you'll see a health list of “don't do this” recommendations. Some people call them “anti-patterns you want to avoid.” They're usually very good rules to live by. Here are some other random tips.
Random Tip #1: Avoid Spaghetti Reporting
The great thing about Figure 1 is that you can use it as a launching point for so many discussions and “lessons learned.” Here's a lesson to consider: the concept of spaghetti reporting. As a data warehouse environment grows and expands, users might demand reporting before the team has had the time to properly model the new data in the data warehouse. In some instances, the team might try to fast-track the process by building reports against both data in the data warehouse and data back in the ODS and even back in the staging area. The team might justify it as a short-term solution hack/workaround, but we all know how much short-term hacks wind up living in the proverbial basement long after they should have moved out and moved on!
I've faced the challenge the last few years, as business acquisitions have forced me to deal with reporting demands the very second I learned about new data I needed to load from the source area into the staging environment. If you're not careful, you can find yourself building a solution of 30 reports that read all over creation! That's not manageable over the long run.
Random Tip #2: Even If You Specialize, Don't Resist Wearing Many Hats
The second tip I'll tie back to Figure 1 is the value of being able to work in many different layers of the data warehouse. Yes, there are some people who want to do nothing but work in the ETL (extract, transform, and load) layer. There's nothing at all wrong with that, as most data warehouse applications require more effort in the ETL layer than any other single layer. But don't discount the idea of working in the reporting area. Here's where you really get to see the business application.
But above all, you really can't be a strong data warehouse professional without strong SQL programming skills, whether it's T-SQL in the Microsoft world, PL-SQL in the Oracle world, etc. Although my claim to fame has always been the Microsoft platform, I can read PL-SQL code and DB2 SQL code and I'm familiar with many of the nuances because I frequently have to read from Oracle and DB2 systems.
Random Tip #3: Make Your Work Available and Accessible and Let Others Promote It
Very early in my career, I loved being a “heads-down” developer. I was fairly successful and won two awards by the time I was 25 years old. However, I was able to do so because I was working for some FANTASTIC project managers who made it possible for me to sit at my desk and crank out code and listen to music on my Walkman with very little in the way of interruptions.
In many ways, those days are gone. If you work in data warehousing, it's extremely likely that you'll need to interface with the business and understand business requirements. You'll need to communicate actively with the business and you'll need to “speak their language.” That also means communicating aspects of the system in non-technical terms. I hate to use the term “political” here, but soft-skills are essential. If your data warehouse project is the newest project, you'll need the help of some key business people to champion your work. A single endorsement from a respected business user goes much further than ten developer-led presentations on new functionality that the business should be using. That's not to say that the latter doesn't have its place: but the former is how solutions grow in a company. I can't stress this enough.
A single endorsement from a respected business user can go further than ten developer-led presentations on new functionality.
Random Tip #4: The Many Pitfalls of TRUNCATE and LOAD
You might work in an environment where Figure 1 seems like overkill. Maybe you have one primary data source and it's one where you have control. That data source might not be terribly large, maybe 10 million rows and that's it. Additionally, you might only need to update your data warehouse once a day, overnight, and it doesn't matter if it takes 30 minutes to rebuild it. You might decide to do what's called a T&L, for Truncate and Load.
In a T&L, you truncate the data warehouse every night and reload everything from the source system. No need to worry about incremental updates, just a full refresh of the data. I've done it, and so have many of you. Yes, it's primitive. It can work, but you should know the risks!
You know about the first risk here: If the source data grows significantly larger and there's a need to refresh the data multiple times a day, the T&L approach becomes inefficient.
There's a second risk, one that's not as apparent. Perhaps you don't have control over those source systems and some of them wind up archiving or purging data. To make matters worse, maybe the purging follows a schedule that wreaks havoc on any relationships (or even assumptions of data) that you have in your data warehouse.
One day the data warehouse might seem fine, and the next day someone goes and runs a report for Q4 2017 and gets incomplete results, all because some of the source data used for that Q4 2017 result went through an archive process in the source system. Because you've been doing a T&L, your data warehouse winds up reflecting the archived state of the sourced system. That's NOT a good thing!
So be very careful about using T&L in an ETL strategy. Unless you have full control over your source data, you could be asking for trouble. At the very least, maintain a copy of what you extract, because the source system might wind up archiving it unexpectedly!
Random Tip #5: Don't Get Too Enamored with (Nor Too Frightened by) Emerging Technologies
As you go through the processes in Figure 1, there are many opportunities to use some of the newer technologies in SQL Server. Here are some examples:
- Use SQL Server In-Memory Optimized tables for the Staging area. As I wrote back in the September/October 2016 issue of CODE Magazine, In-Memory OLTP tables can speed read/write operations by two to three times or greater.
- Use SQL Server Temporal Tables or Change Data Capture to maintain historical versions of data in an operational data source.
- Use SQL Server columnstore indexes on significant Fact Tables for speeding up aggregations. I've written about columnstore Indexes several times in prior CODE Magazine articles.
- Use (or at least evaluate) newer reporting tools, such as Power BI.
- Use the SQL Server 2016 Query Store to monitor and manage query performance.
I know good developers who rarely (or never) use SQL constructs that Microsoft added after SQL 2005. I also know some people who quickly rush to use every new feature out of the box when Microsoft releases a new version or even interim release. Both sides might be well meaning but are potentially making mistakes.
Explore new database features, test them, study them, and use them judiciously. If you want to use In-Memory OLTP tables to speed your ETL, create a test environment and demonstrate over a period of time that In-Memory OLTP will help the performance of processing staging tables. Yes, creating and managing a test environment takes time, but it's the right thing to do.
If new index feature XYZ doesn't give you better performance, you likely don't have a compelling reason to use it.
Random Tip #6: Don't Think You Can't Benefit from Inspiration
Last spring, my family and I took a trip to Disney in Orlando, Florida. I won't talk about the great rides, great food, or great fun we experienced there, although we certainly had a blast. What I will talk about is Disney's incredible attention to detail and their commitment to high quality in every service they provide. The hotels are run very professionally, all staff are highly knowledgeable, and the landscaping is immaculate. When you just stop and look around at all the sites in any of the theme parks, you really get a sense of the incredible effort that went into creating the entire Disney experience.
That trip not only helped me recharge my batteries after months of long work hours, it also re-dedicated me toward providing the highest quality of work possible for my clients.
Here's another story. My family and I had to go through a legal hassle last year. The specifics don't matter (they're actually quite silly), and fortunately the story had a happy ending. But something else came out of it. The attorney who represented my family was one of the most professionally tempered individuals I've ever met. I've never seen someone show so much patience and so much vision and confidence that we would come out fine in the end.
The “other side” of the legal issue often took measures that we found unfair and antagonistic, and the natural human response was to react or retaliate. Our attorney was the model of “let cooler heads prevail.” He wound up being an inspiration for how I should deal with my clients. Most of the time I'm known as good-natured and flexible, but I‘ll admit to a few bouts of irritability when things get very rough. I learned some great lessons from this attorney and told him so.
If anyone tells me at the end of the year that they really liked working with me, I'll tell them I have Disney and a lawyer to thank grin. Don't forget that inspiration can come from many places.
Random Tip #7: Don't Underestimate What It Takes to Be a Leader
A team needs leadership. I wrote in an editorial years ago that leadership is a verb more than a noun, in recognition of all the active work that goes into leading and mentoring. I'm at my best when I'm relaxed and walking my team through a design review in the same way a scout master might tell a campfire story. But I can only make that possible if I'm PREPARED.
Don't underestimate how much preparation ultimately factors into success. Always think forward about a module you might have to design or code next month. Always think forward about technical hurdles or walls your team might face. If you anticipate them and act in a timely manner, you'll gain the trust of your team. A good leader is earnest and humble about all the things he or she needs to be prepared for. I'll admit when I got my first leadership position in my 20s, I was perhaps too much in love with the idea of being a leader. Now I know, after decades of lessons, the love and passion needed for the process, and that the rest will (hopefully) take care of itself.
Random Tip #8: Don't Assume That Your Error Logging and Backup Recovery Will Work the Way You Expect
You've written what you think is a world-class error handling and error logging routine, but are you sure it works? Are you sure the error logging will always write out the necessary information so that you can diagnose the problem causing the error?
You run backups every day, but suppose you have to restore specific database objects? Do you have an idea how long the process might take? Are you certain that the restore will work properly?
You can see the theme here. Never assume. Yes, testing takes time. But I'll trade 100 hours of testing time over a sleepless night trying to determine why an ETL process terminated.
On the Lighter Side
Nearly everyone in the industry has a few anecdotal stories about interesting exchanges with the business side. (I'm sure it won't surprise developers to know that business execs have similar stories about technical people!)
We've all heard the expression, “There's no such thing as a bad question.” My corollary is: “A bad assumption isn't necessarily bad, it just means someone has an honest gap in their knowledge.” Take, for example, the following exchange:
Business manager: “I know you're working on the data warehouse, but I'd like to start talking about designing some dashboards with some important KPIs.”
Me: “Great! Always happy to talk about that topic. What types of KPIs are you looking to show?”
Business Manager: “Well, I'd have to give it some thought, but certainly sales dollars are one.”
Me: “OK, sure, financials are always a big part of a KPI scorecard. I actually don't recall seeing any sales goals in the data. Do you have that somewhere?”
Business Manager (pausing, with a bit of a frown): “Well, not at the moment, not officially, but we shouldn't need that to show sales KPIs.” (Note: The manager's tone strongly indicates that the last part was a declaration, not a question, so I knew I might have a small challenge to face.)
I'll skip to the conclusion, although you can probably see where this was going. I explained to the manager that sales dollars constituted a measure, and that you'd need some other piece of information to evaluate and visualize actual performance (the P in KPI!). That other piece of information might be a rule that any monthly spike of 0.5% or more was very good, or it might be a goal table with sales objectives by salesman and month, to compare against the actual sales. By the end of the conversation, the manager realized there was more to it than he realized.
Yes, I've had that conversation many times over the years. Sure, it's human nature to be a little surprised when a conversation reveals that someone has an unexpected gap in their knowledge. But we're all human and no one is perfect, and even those who think “I always can tell when I don't know something” will someday find themselves in a room when he or she is the last to realize something that everyone else knows. It's a humbling world out there.
So Where Do We Go from Here?
If my handwriting weren't so bad, I'd take a picture of my whiteboard where I have a list of topics I plan to write about over the next year. I have an ETL example that I very much need to finish so that I can write about it. I'd like to talk about report architectures and also report delivery in a data warehouse environment. On that latter point, sometimes you have to tweak the best practices you think you're bringing to a company, in order to adjust to an organization's workflow. I'm thinking of naming my next Stages of Data article “Reporting for Duty,” as a reflection about managers who mandate systems to push report content to users instead of users seeking out the data on a Web page.
I'd also like to talk about Agile and Sprint practices in data warehouse environments: I had a somewhat negative view of this a few years ago, and although I haven't done a full 180, I've learned a few tricks to help leverage Agile.
Finally, I plan to devote an article to a topic that many data warehouse environments face: handling version history and implementing slowly changing dimension logic. As a basic example, suppose you have a product that goes through three price changes in two years, and you want to track sales and return metrics for each price time period. Or, you have a sales manager who managed one sales territory for years, and then moved on to a new sales territory, and you want to compare sales metrics for the two periods. In other words, you care about the history associated with those data changes.
So, I have officially bid Baker's Dozen a fond adieu. I'm on to the next stage. Literally.
