


Mark this date: June 1, 2016. Why is that date significant? Because Microsoft formally released SQL Server 2016. Although I'm always excited about new releases of Microsoft's flagship database product, SQL Server 2016 represents one of the biggest leaps forward in the history of the product. I participated in a Microsoft launch event in New York City for SQL Server 2016 and performed a deep-dive session on the new in-memory enhancements in SQL Server 2016 Enterprise. In this latest installment of Baker's Dozen, I'll cover 13 talking points to serve as compelling arguments that SQL Server 2016 is a stunning new version that database environments should seriously consider.
What's on the Menu?
Here are the topics for today:
- An Overview of In-Memory Enhancements (Columnstore Indexes and Optimized In-Memory OLTP)
- Columnstore Index Functionality
- Baker's Dozen Spotlight: Performance benchmark examples for Columnstore Indexes
- In-Memory OLTP Functionality
- Performance benchmarks for Optimized In-Memory OLTP Tables
- Basic Row-Level Security
- Advanced Row-Level Security
- Native JSON Support
- Temporal Tables
- Query Store
- Analysis Services Tabular Enhancements
- SSRS Enhancements
- Miscellaneous: Other new features
#1: An Overview of In-Memory Enhancements (Columnstore Indexes and Optimized In-Memory OLTP)
Arguably, one of the most significant features in SQL Server 2016 is the expanded functionality of columnstore indexes and in-memory OLTP tables. (For those who are new to these features, columnstore indexes and in-memory OLTP tables only exist in the Enterprise Edition of SQL Server). Both columnstore indexes and in-memory OLTP tables allow database developers to designate an index/table as a purely in-memory structure. SQL Server works with these in-memory structures using highly optimized buffer pools that can process the data many times faster than traditional database tables. However, even though both columnstore indexes and in-memory tables represent “in-memory technology,” they're very different.
I'll start first with columnstore indexes. Four years ago, in the March/April 2012 issue of CODE Magazine, I wrote about columnstore indexes in SQL Server 2012. Columnstore indexes serve one major purpose: to scan and aggregate over large amounts of data. If you ask any DBA in any data warehousing environment about the types of SQL queries that cause performance issues, odds are good that the DBA will describe queries that scan/aggregate large tables as a pain point. No matter how well the DBAs and developers optimize table structures and queries, the row-by-row nature of scanning/aggregating impacts performance. Anyone who's analyzed query execution operators in SQL execution plans can attest to that.
Microsoft introduced columnstore indexes in SQL Server 2012 to help these types of data warehouse queries. Before I write more, it's important to think about the contents of a data warehouse fact table. A fact table (generally) stores two types of data: numeric integers that serve as foreign keys and relate to business master dimension tables, and numeric columns/measures that users want to aggregate. So a basic Orders fact table might look something like Figure 1:
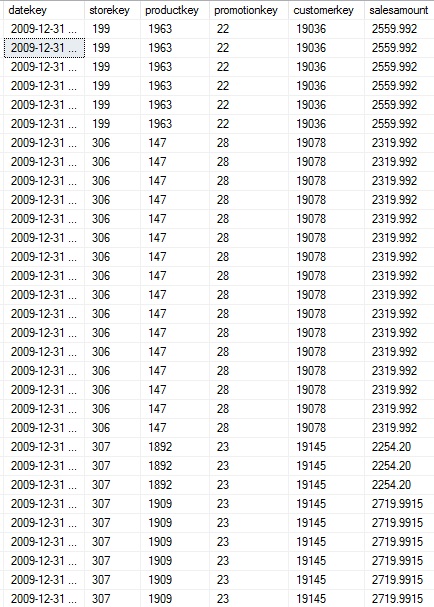
An actual fact table might contain hundreds of millions of rows; however, the table might store a single foreign key value (for a single product, a customer, a date, etc.) tens of thousands of times or more. Here's where the concept of a columnstore index comes in. It's an index in name only. The columnstore index stores repeated values as a vector (see Figure 2). The columnstore index also compressed the values, segments them, stores them in memory, and provides an optimized buffer pool for reading the data.
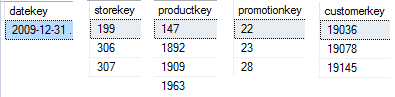
There's one more thing: The database engine reads these vectors in blocks of 1,000 in parallel. That's right - SQL Server has re-written execution operators that scan/aggregate columnstore data to do so using parallel processing. So Microsoft has baked a significant amount of functionality directly into the database engine when using columnstore indexes.
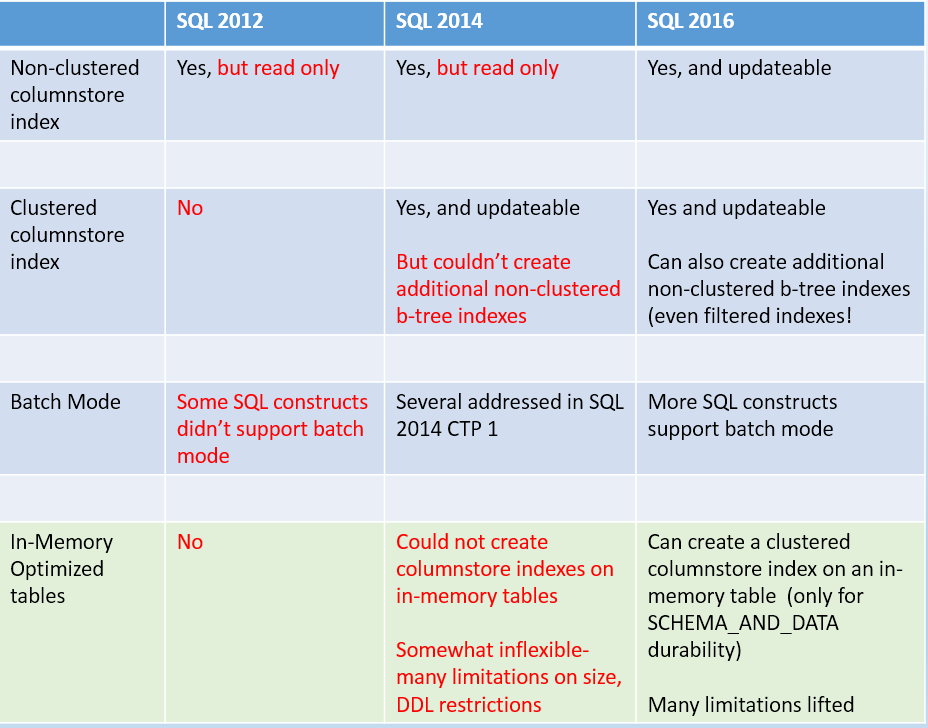
The bad news was that columnstore indexes had limitations in SQL Server 2012. First, a columnstore index was a read-only index. You couldn't insert rows into a table and expect the database engine to update the index or generate an error. That meant that you needed to drop the columnstore index on a table, add new rows, and then rebuild the columnstore index. This limited the use of columnstore indexes on tables that you updated on a periodic schedule-such as adding new rows to a fact table as part of an overnight batch process.
There were other limitations. You could only create non-clustered columnstore indexes, and not all T-SQL statements were optimized for columnstore index usage. Microsoft lifted some of these limitations in SQL Server 2014 (and subsequent service packs for 2014) by introducing a read-write (updateable) clustered columnstore index. However, the non-clustered columnstore index remained read-only, which frustrated database developers who wanted to stay with a non-clustered columnstore index but also wanted an updateable one. Additionally, even though developers could use clustered columnstore indexes for updateable scenarios, you couldn't add traditional b-tree (rowstore) indexes for selected key lookups. So although SQL Server 2014 added some new functionality for updateable clustered columnstore indexes, the product also introduced some scenarios along the lines of “if you want to use 1, you can do A and B but not C, and if you want to use 2, you can do B but not A and C, etc.”
SQL Server 2016 lifts most of the restrictions on non-clustered columnstore indexes.
SQL Server 2016 lifts most of the restrictions. Both clustered and non-clustered columnstore indexes are now updateable. Developers can create b-tree (rowstore) indexes on tables where either columnstore index exists. There's only one significant (but understandable) limitation: A table can only have one columnstore index. Data warehouse people can build clustered updateable columnstore indexes for data warehouse queries (and loads), and OLTP/Transaction database people can leverage non-clustered columnstore indexes in OLTP environments.
Next, I'll talk about In-Memory Optimized OLTP. Just like columnstore indexes, SQL Server allows you to store tables in-memory,-but that's where the similarity ends.
In-Memory OLTP tables started under the code-name of Hekaton for the SQL Server 2014 Enterprise release. In-Memory OLTP allows developers to designate specific tables as in-memory tables. Specifically, developers could designate tables as purely in-memory (which means that the contents disappear if someone restarts the server), or synchronized as FileStream data (which means that SQL Server retained the contents if someone restarts the server). The idea behind In-Memory Optimized tables was to offer performance gains in processing scenarios where developers didn't need the standard overhead of tables (such as locking and logging).
Scenarios such as heavy inserting into staging tables and heavy random reading, which generally don't rely on locking and logging, benefit from in-memory scenarios with a simpler row-format. That's generally what In-Memory OLTP provides: a simplified row-based format with a new buffer pool, with no I/O costs. Microsoft introduced this in SQL Server 2014 Enterprise. Although it shows great potential, In-Memory OLTP suffered from some significant restrictions:
- Depending on the types of key lookups, you might have to specify different collation sequences.
- You had to manually update database statistics after updating tables designated as In-Memory Optimized.
- You needed to specify all DDL definitions at the time you created the table. In-Memory Optimized tables didn't support ALTER TABLE statements.
- There were limits on Data Types.
- The memory limit was 256GB.
- You couldn't add a columnstore index to a table designated as In-Memory optimized.
Fortunately, SQL Server 2016 lifted many of these issues. The collation sequence requirement has been lifted, SQL Server now automatically updates statistics on In-Memory Optimized tables, you can now ALTER the structure of an In-Memory OLTP table, many data type limitations are gone, the memory limit is now one terabyte, and you can now add a columnstore index to a table you've previously designated as In-Memory OLTP.
In summary, columnstore indexes greatly improve performance for queries that scan and aggregate a large number of rows. In-Memory OLTP reduces overhead (and improves performance) when reading and inserting rows for certain heavy insert/heavy random reading patterns. In SQL Server 2016, Microsoft has removed many limitations in these two features to increase the scenarios where database developers can use them.
Microsoft has removed many limitations in these two features to increase the scenarios where database developers can use them.
Figure 3 provides a recap of the version history of in-memory technologies since SQL Server 2012 Enterprise.
#2: Columnstore Index Functionality/Usage
One of the great things about columnstore index functionality is that developers don't need to memorize very much syntax. The database engine does so much work for us! Here are examples for creating a non-clustered columnstore index and a clustered columnstore index.
CREATE NONCLUSTERED COLUMNSTORE INDEX
[IX_FactOnlineSales_ColumnStore_NONCL]
ON [dbo].[FactOnlineSalesDetail_NCCS]
(
-- Microsoft recommends specifying all
-- foreign key columns,
-- and aggregateable measure columns
[DateKey],
[ProductKey],
[StoreKey],
[PromotionKey],
[CurrencyKey],
[CustomerKey],
[SalesAmount]
)
CREATE CLUSTERED COLUMNSTORE INDEX
[IX_FactOnlineSales_ColumnStore_CL]
ON [dbo].[FactOnlineSalesDetail_CCS]
-- You don't specify columns for a clustered
-- columnstore index
Here are the key points to remember with creating columnstore indexes:
- For both types of indexes, you don't specify key columns. Remember that columnstore indexes are not indexes in the traditional sense of b-tree indexes for lookup values. Instead, they are compressed “mini-cubes” that store discrete vectors for the otherwise duplicated values that you would find in a fact table.
- For non-clustered columnstore indexes, you specify the columns that you want to include in the columnstore. To draw an analogy, the column list that you specify is similar to the columns that you'd include in an OLAP cube.
- For a clustered columnstore index, you don't specify any column list as well. SQL Server converts the existing table to a clustered columnstore.
At the risk of repetition, Microsoft enhanced both types of columnstore indexes in SQL Server 2016 as updateable. You can insert/update rows without needing to rebuild the index manually.
#3: Baker's Dozen Spotlight: Performance Benchmark Examples for Columnstore Indexes
To showcase the performance boosts from columnstore indexes, I'm going to take the FactOnlineSales table from the Microsoft ContosoRetailDW database. FactOnlineSales (a traditional data warehouse fact table) contains roughly 12.7 million rows. That's not the largest fact table in the word, but it's hardly child's play either.
Then I'll take the concept of a query that aggregates the SalesAmount column by the ProductKey. Remember that in a standard fact table, a single ProductKey could be stored tens of thousands of times across many orders. This is the type of query where columnstore indexes can yield huge performance boosts.
Here's the query I'll run:
SELECT DP.ProductName, SUM(SalesAmount) AS TotDue,
RANK() OVER
(ORDER BY SUM(SalesAmount) DESC)
AS RankNum
FROM DimProduct DP
JOIN FactOnlineSalesDetail_CCS FOS
-- run for each of four tables
WITH (INDEX
( [IX_FactOnlineSales_ColumnStore_CL] ))
-- use the corresponding index
ON DP.ProductKey = FOS.ProductKey
GROUP BY DP.ProductName
ORDER BY TotDue DESC
I'll run this query across four scenarios:
- Scenario 1: A version of the table without a columnstore index (with the 12.7 million rows) where you force the query to use a standard clustered index (yes, this version will be the slowest)
- Scenario 2: A version of the table without a columnstore index, where you force the query to use a covering index. Prior to columnstore indexes, this was the fastest way to optimize this type of aggregation query.
- Scenario 3: A version of the table with a non-clustered columnstore index
- Scenario 4: A version of the table with a clustered columnstore index
Figures 4 and 5 show the performance results. The results come from the SQL Server Query Store functionality, which stores query executions. I'll cover this feature (Query Store) in Item #10.

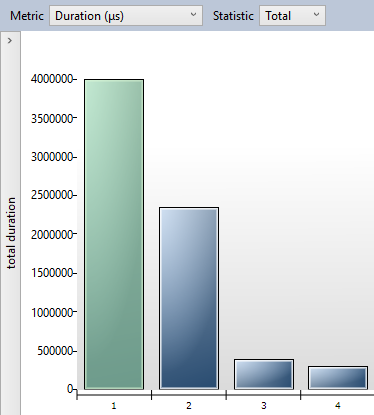
The results (expressed in nanoseconds) in Figures 4 and 5 are compelling. The columnstore versions of the query (Query IDs 3 and 4) run as much as eight to ten times faster than the two queries that use traditional indexes. Even more compelling, the query that uses the covering index, which was the best way to handle the query prior to SQL Server 2012 Enterprise-is still many times slower than columnstore indexes.
How can a new index provide such huge enhancements? I mentioned before that the columnstore index compresses foreign key values into vectors. I also mentioned that SQL Server provides a new buffer pool that reads the compressed index. SQL Server certainly contains many enhancements to process the columnstore index. But perhaps the single most significant function under the hood is specifically how SQL Server scans and aggregates the data.
Until SQL Server 2012 and the columnstore index, SQL Server processed data row-by-row. No matter how much faster the server, no matter how much server memory, SQL Server processed the data row-by-row. SQL Server 2012 and the columnstore index changed that. Figure 6 shows the execution plan for a columnstore index. Note the Hash Match aggregation and Index scan operators: Both use a new execution mode called Batch Mode. Batch mode processes the vectors from columnstore indexes in blocks of 900-1000 values in parallel. This results in major performance enhancements!
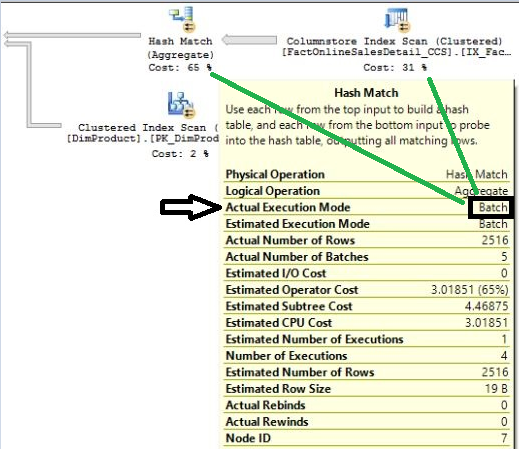
When a new type of index outperforms a covering index (the latter of which previously optimized report queries quite well) by a factor of eight, you know you're looking at a powerful feature! If you need to scan and aggregate over a large number of rows, look at the columnstore index.
When a new type of index outperforms a covering index (the latter of which previously optimized report queries quite well) by a factor of eight, you know you're looking at a powerful feature!
#4: In-Memory OLTP Functionality
In-Memory Optimized OLTP is an optimized row format for specific tables, with performance gains potentially several times over standard tables. The feature uses a new buffer pool targeting a memory-optimized structure. Data resides either in server memory or persisted with storage using SQL Server FileStream objects. Developers can still access these tables using standard T-SQL statements.
The new In-Memory optimized format contains reduced overhead, with no row locking/latching that you have with normal tables. The new format uses Optimistic Concurrency, so there is much less overhead. Developers can create either hash indexes or standard (range) indexes. Hash indexes can greatly optimize heavy random lookups.
Not all database applications will be able to use this feature. In-Memory optimized tables work best with large ETL staging tables, reading session database data quickly, and heavy random reads/high volume inserts.
If you process large ETL staging tables, need to read session database data quickly, deal with heavy random reads and/or high volume inserts, or need the best performance with lookup tables, look at in-memory optimized OLTP tables.
Here's how you create an in-memory optimized table:
create table dbo.StagePurchaseOrders_Hekaton_SO
( PurchaseOrderID int not null ,
VendorID int,
ProductID int,
OrderDate Date
not null index ix_TestDate,
constraint [IX_Hash_PurchaseOrderID]
primary key nonclustered hash
(PurchaseOrderID)
with (bucket_count=10000000) )
with (memory_optimized=on,
durability=schema_only)
Note the following:
- You use the keywords WITH MEMORY_OPTIMIZED to designate the table as an In-Memory Optimized table
- You have two options for the durability mode: SCHEMA_ONLY and SCHEMA_AND_DATA. SCHEMA_ONLY means purely in memory, which also means that you'll lose the data if the server crashes. In many ETL scenarios, that's not a problem. If you want to preserve the data in the event of a server crash, you should use SCHEMA_AND_DATA, which persists the data as SQL Server FileStream objects. Note that SCHEMA_ONLY performs better, although you should only use it when you truly don't care about losing information in the event of a server crash.
- You can create a hash index (in this case, on the primary key) for instant lookups. You need to define a bucket count for the hash index. Microsoft recommends that you specify a bucket count value that equates to roughly 1.5 to 2x the cardinality value count of the table. For instance, if you expect about five million unique Purchase Order IDs in the table, you should define a bucket count between 7.5 million and 10 million. Note that you won't achieve better performance by going over 2x the cardinality count; you'll only be wasting memory. However, you'll likely impact performance negatively by specifying a bucket count that's too low.
#5: Performance Benchmarks for Optimized In-Memory OLTP Tables
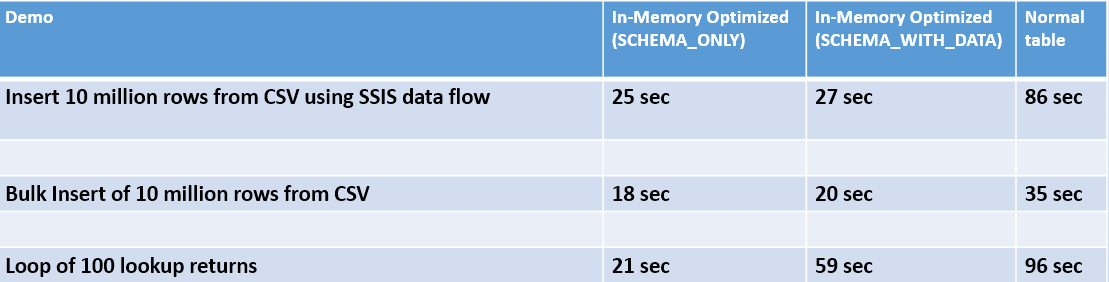
Listing 1 creates three demo tables: an in-memory optimized table (SCHEMA_ONLY), an in-memory optimized table (SCHEMA_WITH_DATA), and a standard SQL Server table.
Listing 1: Create Demo Database for In-Memory Optimized example
-- Step 1 of 5: create a new database
-- with in-memory optimized OLTP tables
CREATE DATABASE [OLTPDemo]
ON PRIMARY
( NAME = N'OLTPDemo',
FILENAME = N'C:\SQLDataTables\OLTPDemo.mdf' ),
FILEGROUP [SQL2016Demo]
CONTAINS MEMORY_OPTIMIZED_DATA
DEFAULT ( NAME = N'SQL2016Demo',
FILENAME = N'C:\SQLDataTables\OLTPDemo',
MAXSIZE = UNLIMITED)
LOG ON
( NAME = N'OLTPDemo_log',
FILENAME = N'C:\SQLLogTables\OLTPDemo_log.ldf')
-- Step 2 of 5: create 3 tables as staging tables
-- A regular SQL Server table
-- An in-memory OLTP table as a SCHEMA_ONLY table
-- An in-memory OLTP table as a SCHEMA_AND_DATA table
create table dbo.StagePurchaseOrders_Regular
( PurchaseOrderID int primary key , VendorID int,
ProductID int , OrderDate Date not null index ix_TestDate,
TotalDue money)
-- 2 new options.....memory_optimized with durability,
-- plus in-line index definitions for hash and range index
create table dbo.StagePurchaseOrders_Hekaton_SO -- Schema Only
( PurchaseOrderID int not null , VendorID int, ProductID int ,
OrderDate Date not null index ix_TestDate,
constraint [IX_Hash_PurchaseOrderID_SO] primary key
nonclustered hash (PurchaseOrderID)
with (bucket_count =10000000) )
with (memory_optimized=on, durability=schema_only)
-- new syntax, purely in-memory, no data persisted at all
create table dbo.StagePurchaseOrders_Hekaton_SD -- schema and data
( PurchaseOrderID int not null , VendorID int, ProductID int ,
OrderDate Date not null index ix_TestDate,
constraint [IX_Hash_PurchaseOrderID_SD] primary key
nonclustered hash (PurchaseOrderID)
with ( bucket_count =10000000) )
with (memory_optimized=on, durability=schema_AND_data)
-- data persisted
-- couldn't do this in 2014, but we can in SQL Server 2016
alter table dbo.StagePurchaseOrders_Hekaton_SO add Totaldue money
alter table dbo.StagePurchaseOrders_Hekaton_SD add Totaldue money
-- couldn't do this in 2014 , but we can in SQL Server 2016
alter table dbo.StagePurchaseOrders_Hekaton_SD
alter index [IX_Hash_PurchaseOrderID_SD] rebuild with
(bucket_count = 15000000)
-- Step 3 of 5: Add data (either SSIS package or Bulk Insert)
-- Now perform Bulk Insert from CSV file with millions of rows
-- Perform different operations to populate the 3 tables
-- In-Memory OLTP will be 2-3 times faster at populating tables
bulk insert dbo.StagePurchaseOrders_Hekaton_SO -- 18 seconds
from 'c:\SQL2016_InMemory\Ordertext.csv'
with (firstrow = 2, fieldterminator = ',', rowterminator = '\n')
bulk insert dbo.StagePurchaseOrders_Hekaton_SD -- 20 seconds
from 'C:\SQL2016_InMemory\Ordertext.csv'
with (firstrow = 2, fieldterminator = ',', rowterminator = '\n')
bulk insert dbo.StagePurchaseOrders_Regular -- 35 seconds
from 'C:\SQL2016_InMemory\Ordertext.csv'
with (firstrow = 2, fieldterminator = ',', rowterminator = '\n')
-- Note that for the In-Memory tables, there is no space used!
sp_spaceused 'StagePurchaseOrders_Regular'
go
sp_spaceused 'StagePurchaseOrders_Hekaton_SD'
go
Sp_spaceused 'StagePurchaseOrders_Hekaton_SO'
go
-- Step 4 of 5: Retrieve a single row and look at execution cost
declare @t1 datetime, @t2 datetime, @t3 datetime, @t4 datetime
set @t1 = getdate()
select * from dbo.StagePurchaseOrders_Hekaton_SO where
PurchaseOrderID= 811 -- roughly 1% of cost
set @t2 = getdate()
select * from dbo.StagePurchaseOrders_Hekaton_SD where
PurchaseOrderID= 811 -- roughly 1% of cost
set @t3 = getdate()
select * from dbo.StagePurchaseOrders_Regular where
PurchaseOrderID= 811 -- roughly 99% of cost
set @t4 = getdate()
select datediff(ms, @t1, @t2) -- schema only, 0 ms
select datediff(ms, @t2, @t3) -- schema with data, 90 ms
select datediff(ms, @t3, @t4) -- regular, 623 ms
-- Step 5 of 5: Loop with random lookups, look at times
set @t1 = getdate()
declare @Counter int = 1
declare @lookupValue int
declare @NumberLoops int = 100
DECLARE @ReturnDollarAmount money
while @counter <= @NumberLoops
begin
set @lookupValue =
(SELECT cast( RAND()*(1000000-1)+1 as int))
set @ReturnDollarAmount =
(select TotalDue from dbo.StagePurchaseOrders_Hekaton_SO
where PurchaseOrderID = @lookupValue)
set @counter = @Counter + 1
end
set @t2 = getdate()
set @Counter = 1
while @counter <= @NumberLoops
begin
set @lookupValue =
(SELECT cast( RAND()*(1000000-1)+1 as int))
set @ReturnDollarAmount =
(select TotalDue from dbo.StagePurchaseOrders_Hekaton_SD
where PurchaseOrderID = @lookupValue)
set @counter = @Counter + 1
end
set @t3 = getdate()
set @Counter = 1
while @counter <= @NumberLoops
begin
set @lookupValue =
(SELECT cast( RAND()*(1000000-1)+1 as int))
set @ReturnDollarAmount =
(select TotalDue from dbo.StagePurchaseOrders_Regular
WHERE PurchaseOrderID = @lookupValue)
set @counter = @Counter + 1
end
set @t4 = getdate()
select datediff(ms, @t1, @t2) -- schema only 21 seconds
select datediff(ms, @t2, @t3) -- schema with data 59 seconds
select datediff(ms, @t3, @t4) -- regular 96 seconds
Listing 1 also covers three demonstrations: an SSIS package to populate 10 million rows from a CSV file into each table (using a basic data flow pattern), a bulk insert routing to populate the same 10 million rows into each table, and then a loop to randomly read the rows based on a purchase Order ID lookup across 100 iterations.
Figure 7 shows the results. In all three cases, In-Memory Optimized runs roughly anywhere from two to three times faster than standard tables. Granted, different system configurations yield different numbers, but you should expect to see similar performance gains. Developers building ETL solutions for large loads, and/or performing heavy random reads on single key lookup values, should give In-Memory OLTP in SQL Server 2016 Enterprise serious consideration.
#6: Basic Row-Level Security
For over a decade, SQL developers have built hand-crafted solutions to deal with situations where users should only see certain rows. Here are some scenarios:
- Users can only see the orders they entered and nothing else
- Users can only see orders based on geography (i.e., region or territory definitions)
- Users can only see orders based on both geography and product definitions (i.e., for a region manager but only for certain product brands)
Prior to SQL Server 2016, developers needed to roll their own solutions for this. Those solutions included custom logic in stored procedures or views: These were often mixed with authorization tables and (possibly) parameterized table-valued functions (because SQL Server views cannot receive parameters).
Before I get into the new row-level security (RLS) in SQL Server 2016, let's stop and think about another feature in SQL Server: database triggers. You might be asking: what do database triggers (which only operate on DML statements) have to do with SELECT statements to filter based on authorization rules? Well, specifically, nothing; Triggers serve as an automated guard-dog, a night watchman. Triggers see every DML statement, regardless of where they originate. The greatest benefit of triggers is that you can rely on them (unless, of course, someone with the rights tries to disable them), regardless of who is trying to INSERT/UPDATE/DELETE a row.
With row-level security, you need something similar. You need a similar guard-dog that stands in front of the table and says (in effect), “I don't care where your SELECT statement came from, I'm going to run a rule to determine whether the specific user should see the rows.” That's what Microsoft has allowed us to do with RLS in SQL Server 2016.
In the proverbial nutshell, SQL Server 2016 RLS allows you to create a security policy that maps a filtering mechanism (a table-valued function) as a predicate onto an existing table. In layman's terms, SQL Server slaps on that security policy as an additional filter predicate on top of any additional querying on a table. Programmatically, that means that you first create a table-valued function that determines (row-by row) whether the current user can see a row.
CREATE FUNCTION dbo.ProductMasterPredicate
( @BrandManager AS varchar(50) )
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN SELECT 1 AS AccessRight
WHERE @BrandManager = USER_NAME()
OR USER_NAME() = 'dbo'
GO
After that, you create a security policy that maps the TVF to the table.
--Create Security Policy
CREATE SECURITY POLICY
ProductMasterSecurityPolicy
ADD FILTER PREDICATE
dbo.ProductMasterPredicate(BrandManager) ON
dbo.ProductMaster
WITH (STATE = ON)
Listing 2 contains the full code for the first sample example. Please note that I've added some comments in the code listing to accompany the scenario.
Listing 2: Basic Row Level Security example
CREATE TABLE dbo.ProductMaster
(ProductPK int identity primary key NOT NULL,
ProductName varchar(100),
ProductPrice decimal(14,4),
BrandManager varchar(30))
INSERT INTO dbo.ProductMaster
(ProductName, ProductPrice, BrandManager)
VALUES ('Dell Laptop i7, 500 GB', 1499.00, 'DellManager'),
('Dell Laptop i7, 1 TB', 1799.00, 'DellManager'),
('Lenovo Laptop i7, 250 GB', 1399.00, 'LenovoManager'),
('Lenovo Laptop i7, 1 TB', 1699.00, 'LenovoManager')
CREATE USER DellManager WITHOUT Login
CREATE USER LenovoManager WITHOUT Login
-- Grant SELECT rights on ProductMaster for 2 users
GRANT SELECT ON dbo.ProductMaster TO DellManager
GRANT SELECT ON dbo.ProductMaster TO LenovoManager
CREATE FUNCTION dbo.ProductMasterPredicate
( @BrandManager AS varchar(50) )
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN SELECT 1 AS AccessRight
WHERE @BrandManager = USER_NAME() OR USER_NAME() = 'dbo'
GO
--Create Security Policy
CREATE SECURITY POLICY ProductMasterSecurityPolicy
ADD FILTER PREDICATE dbo.ProductMasterPredicate(BrandManager)
ON dbo.ProductMaster
WITH (STATE = ON)
-- When we run "as" DellManager, we might want to view
-- execution plan
GRANT SHOWPLAN TO DellManager
-- Now run as DellManager
EXECUTE AS USER = 'DellManager'
select * from ProductMaster -- Only see rows for DellManager
REVERT-- Go back to admin user
-- Now run as LenovoManager
EXECUTE AS User = 'LenovoManager'
select * from ProductMaster -- Only see rows for LenovoManager
REVERT
select * from ProductMaster -- Back to admin, see all rows
#7: Advanced Row-Level Security
Row-level security in SQL Server 2016 is a powerful feature. Unfortunately, most online examples are very basic and don't cover even moderately complex business scenarios for restricting row access. I'm going to look at a requirement I've faced several times: end-user access to orders based on multiple business entities.
RLS in SQL Server 2016 is a powerful feature. Unfortunately, most online examples are very basic and don't cover even moderately complex business scenarios for restricting row access.
Listing 2 covered a very simple example based on a specific column. Now let's look at a more involved scenario, where user authorization is based on both geography and products. You can't use the model I used in Listing 2.
Suppose that you have an authorization table like the one in Figure 8. You have a user named Northeast_SouthEast_Bikes (yes, a contrived user name). That user can only see bike orders for the Northeast and Southeast Territories. Additionally, some other users might have partly overlapping coverage areas: For instance, another user might be able to see all bikes, and another user might be able to see a different product category for the Northeast and Midwest. The idea is for the filter predicate TVF (table-valued function) to read from this table.

Listing 3 shows the full example. Unlike Listing 2, Listing 3 must actually query both the Order header and Order detail tables, as the Order Header table stores the territory and the Order Detail stores the product definition. Please note that I've added some comments in the code listing to accompany the scenario.
Listing 3: More complex Row-Level Security example
CREATE TABLE dbo.SalesOrderAuthorization
(AuthorizationID int identity primary key,
UserName varchar(100),
TerritoryName varchar(50),
ProductCategoryName varchar(50))
insert into dbo.SalesOrderAuthorization
(UserName, TerritoryName, ProductCategoryName)
values ('NorthEast_SouthEast_Bikes', 'Northeast','Bikes'),
('NorthEast_SouthEast_Bikes', 'Southeast','Bikes')
CREATE FUNCTION dbo.fn_CanSeeSalesOrderDetail
( @SalesOrderDetailID int)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT 1 AS 'CanSeeSalesOrderDetail'
from dbo.SalesOrderAuthorization SOA
JOIN Sales.SalesTerritory ST
on ST.Name = SOA.TerritoryName
JOIN Production.ProductCategory PC
ON PC.Name = SOA.ProductCategoryName
JOIN Production.ProductSubCategory PSC
ON PSC.ProductCategoryID = PC.ProductCategoryID
JOIN Production.Product PR
ON PR.ProductSubcategoryID = psc.ProductSubcategoryID
JOIN Sales.SalesOrderDetail SOD
ON SOD.ProductID = pr.ProductID
JOIN Sales.SalesOrderHeader SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
and SOH.TerritoryID = ST.TerritoryID
WHERE soa.UserName = USER_NAME()
and @SalesOrderDetailID = SOD.SalesOrderDetailID
)
GO
create security policy SalesOrderDetailFilter
add filter predicate dbo.fn_CanSeeSalesOrderDetail (SalesOrderDetailID)
on Sales.SalesOrderDetail
with (state = on);
grant select on Sales.SalesOrderDetail to NorthEast_SouthEast_Bikes
grant select on Sales.SalesOrderHeader to NorthEast_SouthEast_Bikes
grant select on Production.Product to NorthEast_SouthEast_Bikes
grant select on Production.ProductCategory to
NorthEast_SouthEast_Bikes
grant select on Production.ProductSubcategory to
NorthEast_SouthEast_Bikes
grant select on Sales.SalesTerritory to
NorthEast_SouthEast_Bikes
grant select on dbo.SalesOrderAuthorization to
NorthEast_SouthEast_Bikes
execute as user = 'NorthEast_SouthEast_Bikes';
select * from Sales.SalesOrderDetail
revert ;
#8: Native JSON Support
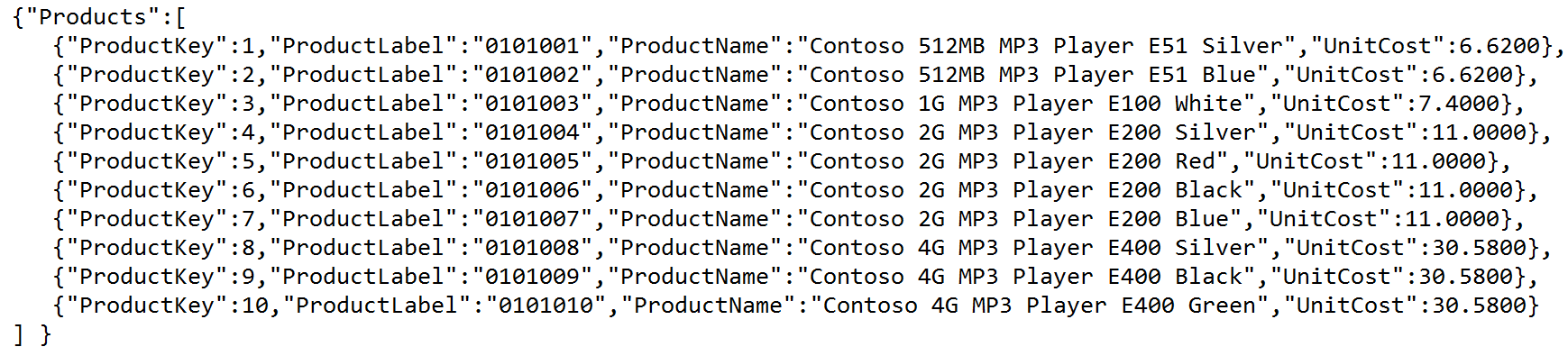
SQL Server 2016 provides built-in JSON functionality. For those not familiar with JSON, it's an open-source, lightweight data-interchange format. Many environments prefer JSON over XML. If you'll recall, Microsoft added XML/XQUERY capabilities in SQL Server 2005: They've now added JSON support in SQL Server 2016. Similar to the way you can specify FOR XML at the end of a query, you can also specify FOR JSON, like so:
select top 10
ProductKey, ProductLabel, ProductName, UnitCost
from dimproduct
for json path, root('Products')
Figure 9 shows the basic JSON output.
The SQL Server 2016 JSON enhancements also include functions to extract values from JSON text. For more information on JSON functionality in SQL Server 2016, I refer you to an excellent four-part series on Technet: https://blogs.technet.microsoft.com/dataplatforminsider/2016/01/05/json-in-sql-server-2016-part-1-of-4/
#9: Temporal Tables
Microsoft introduced Change Data Capture (CDC) in SQL Server 2008 Enterprise and I covered CDC back in the September/October 2010 issue of CODE Magazine. CDC is an impressive feature that scans the SQL Server transaction log asynchronously for changes, and writes out row versions to a change-tracking table. This gives database developers the ability to see the full history of rows and the state of rows before and after a change. For someone looking to implement a full audit-trail who also doesn't want to go to the effort of writing database triggers, CDC can be quite valuable.
Unfortunately, as CDC only exists in the Enterprise edition, database developers using lower versions can't take advantage of CDC. Fortunately, Microsoft created a new feature in SQL Server 2016 called Temporal Tables. I personally refer to Temporal Tables as “CDC-Lite.” The feature isn't as robust as CDC, but still might suffice for many environments. As the name implies, Temporal tables store changes to values over time.
To create a version history table that SQL Server will pair with a base table, you must add the code in the next snippet. Note the two additional generated columns: the WITH SYSTEM_VERSIONING option, and the reference to the history table.
CREATE TABLE dbo.ProductMaster
(
ProductID INT IDENTITY NOT NULL
CONSTRAINT PK_ProductID
PRIMARY KEY NONCLUSTERED,
-- remainder of columns
SysStart DATETIME2(0) GENERATED
ALWAYS AS ROW START NOT NULL,
SysEnd DATETIME2(0) GENERATED
ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME (sysstart, sysend)
)
WITH ( SYSTEM_VERSIONING = ON
( HISTORY_TABLE = dbo.ProductMasterHistory));
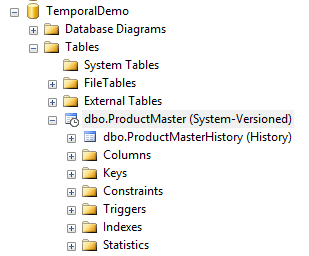
When you create a table as a Temporal table with System Versioning, you'll notice this in Object Explorer (Figure 10). Notice that SQL Server marks the table as System-Versioned and also shows the paired History table.
Listing 4 covers a scenario of inserting and updating rows in the core Product table. After the sample code inserts three rows into the Product table, a developer might assume or expect that the ProductMasterHistory history table also contains three rows to pair with the three inserts. It doesn't! So right away, you see one big difference between Temporal tables and traditional change tracking/audit trail tables: Temporal tables don't store the state of the initial insertion, but rather only the changes with respect to the previous version of the row over time.
Listing 4: Temporal table feature
-- Create a table with temporal options (i.e. store values over time)
-- Note the two system generated values for the row version start
-- and end date
-- Also note the SYSTEM_VERSIONING option and reference to history
-- table
CREATE TABLE dbo.ProductMaster
(
ProductID INT IDENTITY NOT NULL
CONSTRAINT PK_ProductID
PRIMARY KEY NONCLUSTERED,
ProductName VARCHAR(25) NOT NULL,
ProductPrice Decimal(14,4) not null,
SysStart DATETIME2(0) GENERATED ALWAYS AS ROW START NOT NULL,
SysEnd DATETIME2(0) GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME (sysstart, sysend)
)
WITH ( SYSTEM_VERSIONING = ON
( HISTORY_TABLE = dbo.ProductMasterHistory ) );
-- Two limitations right away: we can never TRUNCATE or DROP the table
-- Insert three rows
INSERT INTO dbo.ProductMaster (ProductName, ProductPrice)
VALUES ('Product ABCDE', 49.95),
('Product LMNOP', 54.95),
('Product VWXYZ', 99.95)
SELECT * from ProductMasterHistory
-- no rows, history table only stores changes
-- Wait a minute, and update all rows
UPDATE dbo.ProductMaster set ProductPrice = ProductPrice * 1.05
SELECT * from ProductMasterHistory
-- now you'll see the version of the rows before the update
-- Wait another minute again, and update all rows
UPDATE dbo.ProductMaster set ProductPrice = ProductPrice * 1.05
SELECT * from ProductMasterHistory
-- now you'll see the 2 older versions of the rows
Right away, you can see one big difference between Temporal tables and traditional change tracking/audit trail tables: Temporal tables don't store the state of the initial insertion, but rather only the changes of the prior row over time.
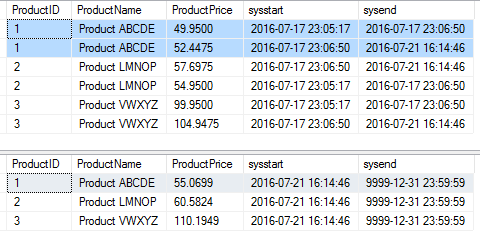
After I run multiple update statements (to increase each product price by 5%, and a second time by an additional 5%), I can then query both the core product master table and the product history table (Figure 11).
Here's the way Figure 11 reads:
- In the top table (the ProductMasterHistory table), you have two history rows for ProductID 1. The first row was the initial price of 49.95, inserted on 7/17/2016 at 23:05:17, and good through 23:06:50. The second row was for the first increase of 5%, bringing the price up to 52.4475. That change was done on 7/17/2016 at 23:06:50 and lasted until 7/21/2016 at 16:14:46, when another 5% increase was done.
- In the bottom table (the core ProductMaster table), the current state for ProductID 1 is a price of 55.0966. That row went into effect on 7/21 at 16:14:16.
- As a result, a developer needs to read the current row in ProductMaster and the history rows in ProductMasterHistory to construct a full audit trail.
#10: Query Store
Prior to SQL Server 2016, any time I showed query performance benchmarks, I usually turned on TIME and IO statistics to show execution times, and I also showed execution plans to pinpoint query issues. Although that certainly worked, it was tedious. Additionally, in production, if I ever wanted to see the execution performance of a query from a week ago, or if I wanted to see the average execution time of a query, I'd need to do a fair amount of work.
Fortunately, Microsoft has implemented a VERY nice feature called Query Store. Query Store tracks query executions, query and execution plans, and runtime statistics that you'd normally need to collect manually. This allows developers to look at query executions over time, analyze min/max/average execution times for queries, and even force query plans. Back in Figures 3 and 4, I used the SQL Server 2016 Query Store to track the executions of the four queries for the columnstore test.
SQL Server doesn't enable Query Store by default: You can enable it with the following command:
ALTER DATABASE [ContosoRetailDW]
SET QUERY_STORE = ON
Once you enable Query Store, you'll see a new section in Object Explorer called “Query Store” (as I have under the ContosoRetailDW database in Figure 12). I used the option for Top Resource Consuming Queries to view the execution plans for the four columnstore test queries. You can also use this information to view queries that have regressed (i.e., where execution performance has grown worse over time) and to view overall system resource usage. When I describe Query Store to people, I tell them, “Think about instances where query performance grows worse, and you need to turn on SQL Profiler to capture some of the information - -imagine how you wish you could have been capturing the resource/performance information at the time of the execution. That is what Query Profiler accomplishes for you.”
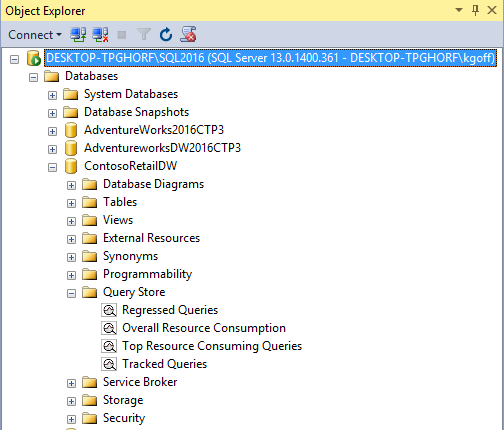
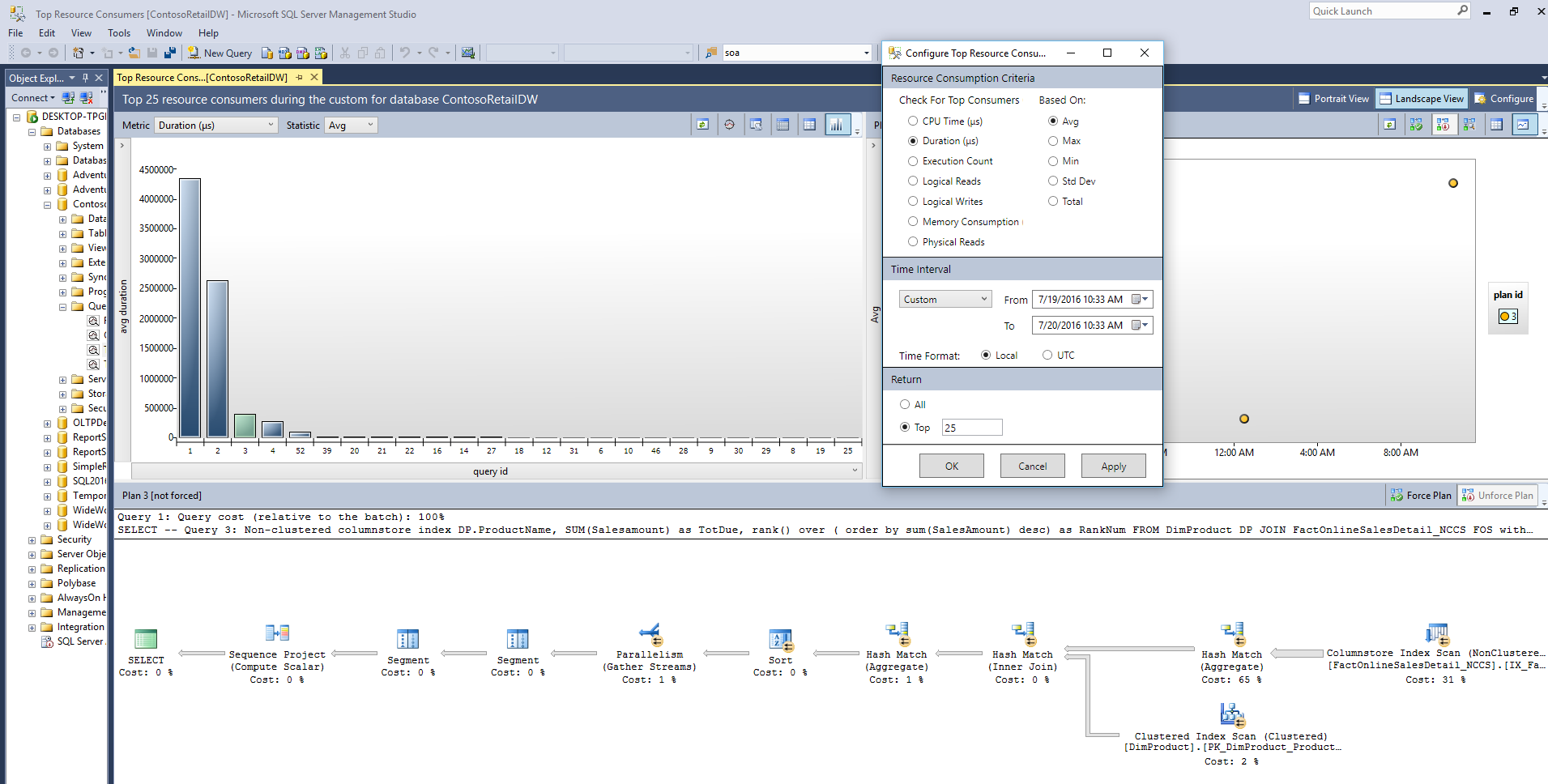
Figure 13 shows the entire screen for an area I've already been using: the Top Resource Consuming Queries section. There are many features in this interface, but I'll list the major ones:
- The ability to configure the time period of query execution to analyze
- The ability to select a specific query in the upper left and see the execution plan at the bottom and the specific executions on the right
- The ability to toggle between query metrics, such as CPU time, total time, memory used, number of reads, etc.
I've outlined the basics of the new Query Store feature. I strongly encourage database developers to research this feature to learn more about this great new capability.
I strongly encourage database developers to research this feature to learn more about this great new capability.
#11: Analysis Services Tabular Enhancements
In the July/August 2013 issue of CODE Magazine, I wrote a Baker's Dozen article that compared the traditional SQL Server Analysis OLAP functionality with the new SQL Server Analysis Services Tabular Model. Although many developers (myself included) were impressed with some of the features of the Tabular Model, I still concluded that SQL Server multidimensional OLAP was still the “king of the hill” with a larger and stronger feature set.
Microsoft added features to the Tabular Model in SQL Server 2016, and effectively closed the gap between the Tabular Model and traditional multidimensional OLAP. Here's a list of the major enhancements:
- The Tabular model supports parallel processing of multiple partitions. This is a huge performance enhancement for large Tabular models that require partitioning.
- The Tabular model supports display folders. This is a very nice feature for arranging attributes and measures for end users in tools like Excel.
- DirectQuery now supports Row-Level Security (the lack of support for this in SQL Server 2012 made DirectQuery very limiting).
- Creating visual relationships in a model now runs much faster in the interface.
- Support for bi-directional cross filtering. This is a personal favorite of mine, as it reduces the need for complex DAX expressions to build filter context definitions across multiple tables.
You can find the full list of enhancements here: https://msdn.microsoft.com/en-us/library/bb522628.aspx
#12: SSRS Enhancements
When Microsoft announced that they would add some visual enhancements to SQL Server Reporting Services (SSRS), some people speculated on the specifics and even jumped to some aggressive conclusions on what SSRS 2016 would look like.
The truth is that the enhancements are arguably more moderate than some expected. Still, SSRS 2016 received a very nice face-lift on an interface that Microsoft has been using for a long time. Here's a list of the major SSRS 2016 enhancements.
- SSRS now contains a new modern-looking Web portal that replaces the (very) dated Report Manager. Organizations can brand the Web portal with their own company logos and colors.
- Support for mobile reports and mobile report publishing
- A new HTML5 rendering engine to improve overall reporting browsing experience across multiple browsers. Here's an online example: https://msdnshared.blob.core.windows.net/media/2016/03/image334.png
- Ability to pin reports to a Power BI Dashboard
- Support for exporting SSRS reports to PowerPoint
- SSRS no longer requires a one-time download of an ActiveX control for printing. (This is a long overdue feature that will make some IT managers happy.)
- Ability to easily enable/disable SSRS report subscriptions and add subscription descriptions (again, this is a long overdue feature, but never too late!)
- A new custom parameter pane to rearrange the order and appearance of parameters. Although this feature doesn't give you absolute control over all report parameter behavior, it's still a big improvement over prior versions of SSRS.
- Finally, there's a new version of SQL Server Data Tools (for creating SSIS/SSAS/SSRS projects) with a simplified install/configuration.
#13: Miscellaneous: Other New Features
I've focused on the in-memory enhancements in SQL 2016, along with Row-Level Security, Temporal tables, query store, and SSAS Tabular/SSRS enhancements. If SQL Server 2016 only contained those enhancements, that would still make for a major and significant upgrade. But Microsoft didn't stop there: There are several other new features:
- Improved flexibility for configuring TempDB databases during set up
- Stretch databases (to store portions of a SQL Server database in the cloud)
- SQL Server R Services: a new platform to build analytic applications using the open source R language. This is a topic that could fill an entire article.
Final thoughts:
I mentioned at the beginning of this article that I delivered a deep-dive presentation on in-memory features at the SQL Server 2016 launch event in New York City in early June. As a SQL Server/Data Platform MVP, I'm extremely proud (and humbled) to represent such a fantastic new version of SQL Server. Even if your company/client doesn't have immediate plans, I strongly recommend that database developers get up to speed with SQL Server 2016.
