



Why would someone want to write yet another programming language? And why do it in C#?
It's often taken for granted that you need an advanced degree in Computer Science - or a lot of stubbornness - to write a compiler. In either case, you'd have quite a few sleepless nights and broken relationships as a result. This article shows you how to avoid all that.
Here are a few advantages of writing your own language:
- Unlike most other languages, it's very easy to modify functionality because everything is in an easy-to-follow standard C# code with a clear interface for functions to be added. Any additional functions can be added to this language with just a few lines of code
- All of the keywords of this language (if, else, while, function, and so on) can be easily replaced by any non-English keywords (and they don't have to be ASCII, contrary to the most other languages). Only configuration changes are needed for replacing the keywords
- This language can be used as both as a scripting language and as a shell program, like Bash on Unix or PowerShell on Windows (but you will make it more user-friendly than PowerShell).
- Even Python doesn't have the prefix and postfix operators ++ and – with the killer argument, “you don't need them.” With your own language, you can decide for yourself what you need. And I'll show you how.
- Any custom parsing can be implemented on the fly. Having full control over parsing means less time searching for how to use an external package or a regex library.
- You won't be using any regular expressions at all! I believe that this is the main showstopper for a few people who desperately need to parse an expression but are averse to the pain and humiliation induced by the regex rules.
This article is based on two articles that I published in MSDN Magazine (see references in the sidebar). In the first article, I described the Split-and-Merge algorithm to parse a mathematical expression, and in the second one, I described how you can write a scripting language based on that algorithm. I called that language CSCS (Customized Scripting in C#). For consistency, I'll call the language that I'll describe in this article CSCS as well.
The CSCS language, as described in my second MSDN article, was not yet very mature. In particular, there's a section toward the end of the article mentioning some of the important features usually present in a scripting language that CSCS was still missing. In this CODE Magazine article, I'll generalize the CSCS language and show how to implement most of these missing features and a few others as well.
The Split-and-Merge Algorithm to Parse a Language Statement
Here, I'll generalize the Split-and-Merge algorithm to parse not only a mathematical expression but also any CSCS language statement. A separation character must separate all CSCS statements. I define it in the Constants.cs file as Constants.END_STATEMENT = ';' constant.
The Split-and-Merge algorithm consists of two steps. First, you split the string into the list of tokens. Each token consists of a number or a string and an action that can be applied to it.
For strings, the actions can only be a plus sign + (string concatenation) or Boolean comparisons, such as ==, <, >=, etc., giving a Boolean as a result. For numbers, there are a few other possible actions, such as -, *, /, ^, and %. The prefix and postfix operators ++ and -- and the assignment operators +=, -=, *=, etc., are treated as special actions for numbers. For strings, I implemented the += assignment operator only, because I couldn't find a reason for other assignment operators for strings.
The separation criteria for tokens are an action, an expression in parentheses, or any special function, previously registered with the Parser. In case of an expression in parentheses or a function, you recursively apply the whole algorithm to the expression in parentheses or to the function with its arguments. At the end of the first step, you'll have a list of cells, each consisting of an action and either a number or a string. This action is applied to the next cell. The last cell always has a null action. The null action has the lowest priority.
The second step consists of merging the elements of the list created in the first step. The merging of two cells consists of applying the action of the cell on the left to the numbers, or strings of the left and of the right cell. The merging of two cells can only be done if the priority of the action of the left cell is greater than or equal to the priority of the action of the cell on its right. Otherwise, you merge first the cell on the right with the cell on its right, and so on, recursively, until you reach the end of the list.
The priorities of the actions are shown in Listing 1. If they don't make sense for your usage, you can easily change them.
Listing 1: Priorities of the Actions
private static bool CanMergeCells(Variable leftCell,
Variable rightCell) {
return GetPriority(leftCell.Action) >=
GetPriority(rightCell.Action);
}
private static int GetPriority(string action) {
switch (action)
{ case "++":
case "--": return 10;
case "^" : return 9;
case "%" :
case "*" :
case "/" : return 8;
case "+" :
case "-" : return 7;
case "<" :
case ">" :
case ">=":
case "<=": return 6;
case "==":
case "!=": return 5;
case "&&": return 4;
case "||": return 3;
case "+=":
case "=" : return 2;
}
return 0;
}
Example of the Split-and-Merge Algorithm
Let's see how to evaluate the following expression: x == "a" || x == "b".
First of all, x must be registered as a function with the Parser (all CSCS variables are registered and treated as functions). Therefore, when the Parser extracts the token x, it recognizes that it's a function and replaces it with the actual x value, say, c.
After the first step, you'll have the following cells consisting of strings and actions: ("c", ==), ("a", ||), ("c", ==), ("b", ")"). The symbol ")" denotes a null action. The last cell always has a null action.
The second step consists in merging all the cells one by one from left to right. Because the priority of == is higher than the priority of ||, the first two cells can be merged. The action of the left cell, ==, must be applied, yielding to:
Merge(("c", ==), ("a", ||)) =
("c" == "a", ||) = (0, "||").
You can't merge the cell (0, ||) with the next one, ("c", ==), because the priority of the || action is lower than the priority of == according to the Listing 1. So we must first merge ("c", ==) with the next cell, ("b", )). This merge is possible and is analogous to the previous one: Merge(("c", ==), ("b", ")") ) = (0, ")").
Finally you must merge two resulting cells:
Merge ((0, ||), (0, ")")) =
(0 || 0, )) = (0, ")")
The result of the expression is 0 (when x = “c”).
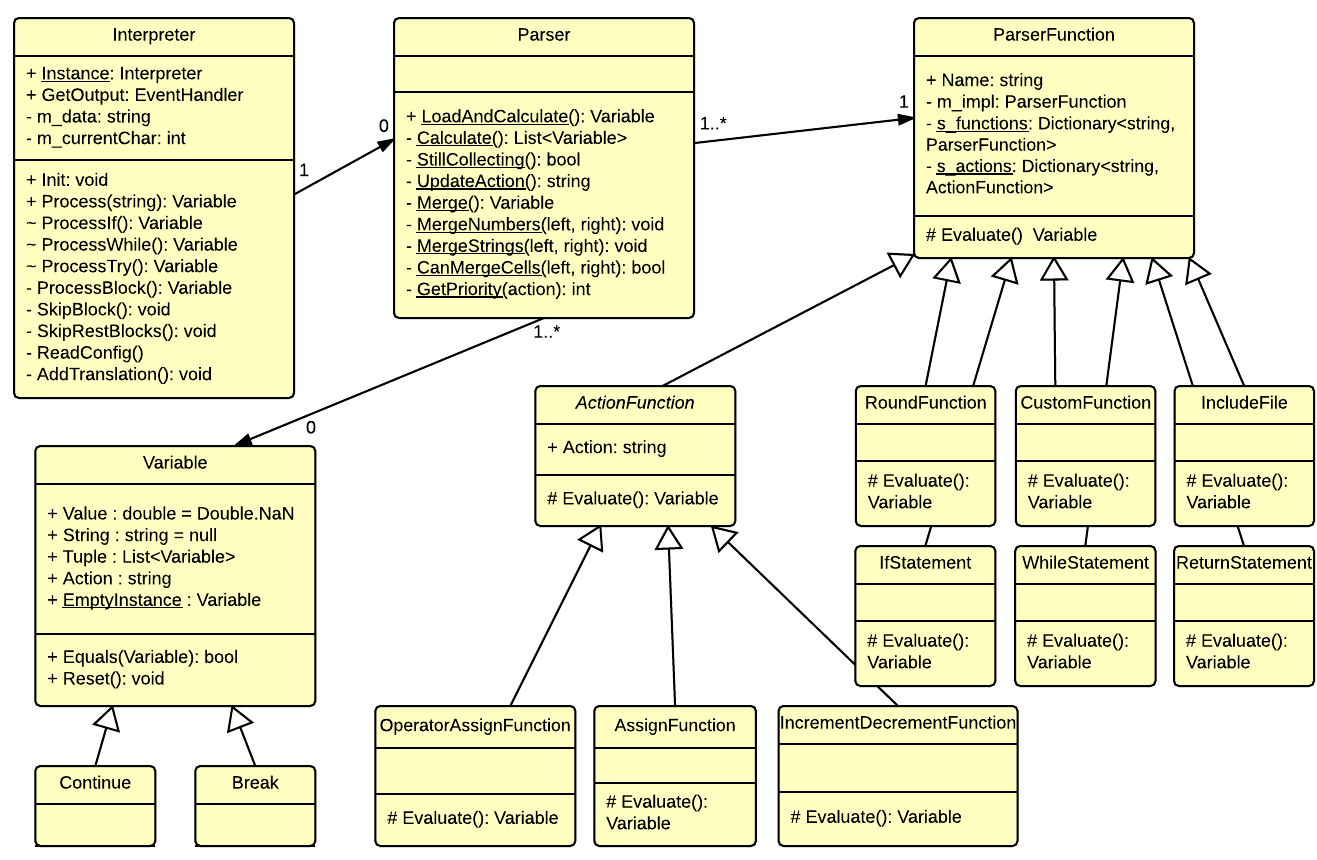
See the full implementation of the Split-and-Merge algorithm in the accompanying source code download (on the CODE Magazine website), in the Parser.cs file. Check out the UML diagram containing all of the classes used in parsing the CSCS language in Figure 1.
Using the algorithm above with recursion, it's possible to parse any compound expression. Here's an example of the CSCS code:
x = sin(pi*2);
if (x < 0 && log(x + 3*10^2) < 6*exp(x) || x < 1 - pi) {
print("in if, x=", x);
} else {
print("in else, x=", x);
}
The CSCS code snippet above uses several functions: sin, exp, log, and print. How does the Parser map them to the functions?
Writing Custom Functions in C# to be Used in the CSCS Code
Let's see an example of implementing the Round() function. First of all, you define its name in the Constants.cs file as follows:
public const string ROUND = "round";
Next, you register the function implementation with the Parser:
ParserFunction.AddGlobal(Constants.ROUND,
new RoundFunction());
In order to use all of the translations available in the configuration file, you must also register the function name in the Interpreter, so that it knows it needs to register all possible translations with the Parser:
AddTranslation(languageSection, Constants.ROUND);
Basically that's it; the Parser will do the rest. As soon as the Parser gets the Constants.ROUND token (or any of its translations from the configuration file) it calls the implementation of the Round() function. All function implementations must derive from the ParserFunction class:
class RoundFunction : ParserFunction
{
protected override Variable Evaluate(
string data, ref int from) {
Variable arg = Parser.LoadAndCalculate(
data, ref from, Constants.END_ARG_ARRAY);
arg.Value = Math.Round(arg.Value);
return arg;
}
}
Parser.LoadAndCalculate() is the main entry point of the Parser, which does all the work in parsing and calculating the expression and returning the result. Implementation of the rest of the functions looks very similar to the implementation of the Round() function.
Example: Client and Server Functions
Using functions, you can implement anything to be used in the CSCS language - as long as it can be implemented in C#, that is. Let's see an example of inter-process communication: an echo server in CSCS, implemented via sockets.
Define the CSCS function names of the server and the client in the Constants.cs:
public const string CONNECTSRV = "connectsrv";
public const string STARTSRV = "startsrv";
Then you register these functions with the Parser:
ParserFunction.AddGlobal(Constants.CONNECTSRV,
new ClientSocket(this));
ParserFunction.AddGlobal(Constants.STARTSRV,
new ServerSocket(this));
Check out the implementation of the ServerSocket in Listing 2. The implementation of the ClientSocket is analogous.
Listing 2: Echo Server Impelmentation
class ServerSocket : ParserFunction
{
internal ServerSocket(Interpreter interpreter)
m_interpreter = interpreter;
protected override Variable Evaluate(string data,
ref int from)
{
Variable portRes = Utils.GetItem (data, ref from);
Utils.CheckPosInt(portRes);
int port = (int)portRes.Value;
try {
IPHostEntry ipHostInfo = Dns.GetHostEntry(
Dns.GetHostName());
IPAddress ipAddress = ipHostInfo.AddressList[0];
IPEndPoint localEndPoint = new IPEndPoint(ipAddress, port);
Socket listener = new Socket(AddressFamily.InterNetwork,
SocketType.Stream, ProtocolType.Tcp);
listener.Bind (localEndPoint);
listener.Listen(10);
Socket handler = null;
while (true) {
m_interpreter.AppendOutput("Waiting for connections on " +
port + " ...");
handler = listener.Accept();
// Data buffer for incoming data.
byte[] bytes = new byte[1024];
int bytesRec = handler.Receive(bytes);
string received = Encoding.UTF8.GetString(bytes, 0,
bytesRec);
m_interpreter.AppendOutput("Received from " +
handler.RemoteEndPoint.ToString() +
": [" + received + "]");
byte[] msg = Encoding.UTF8.GetBytes(received);
handler.Send(msg);
if (received.Contains ("<EOF>")) {
break;
}
}
if (handler != null) {
handler.Shutdown (SocketShutdown.Both);
handler.Close ();
}
} catch (Exception exc) {
throw new ArgumentException ("Couldn't start server: (" +
exc.Message + ")");
}
return Variable.EmptyInstance;
}
private Interpreter m_interpreter;
}
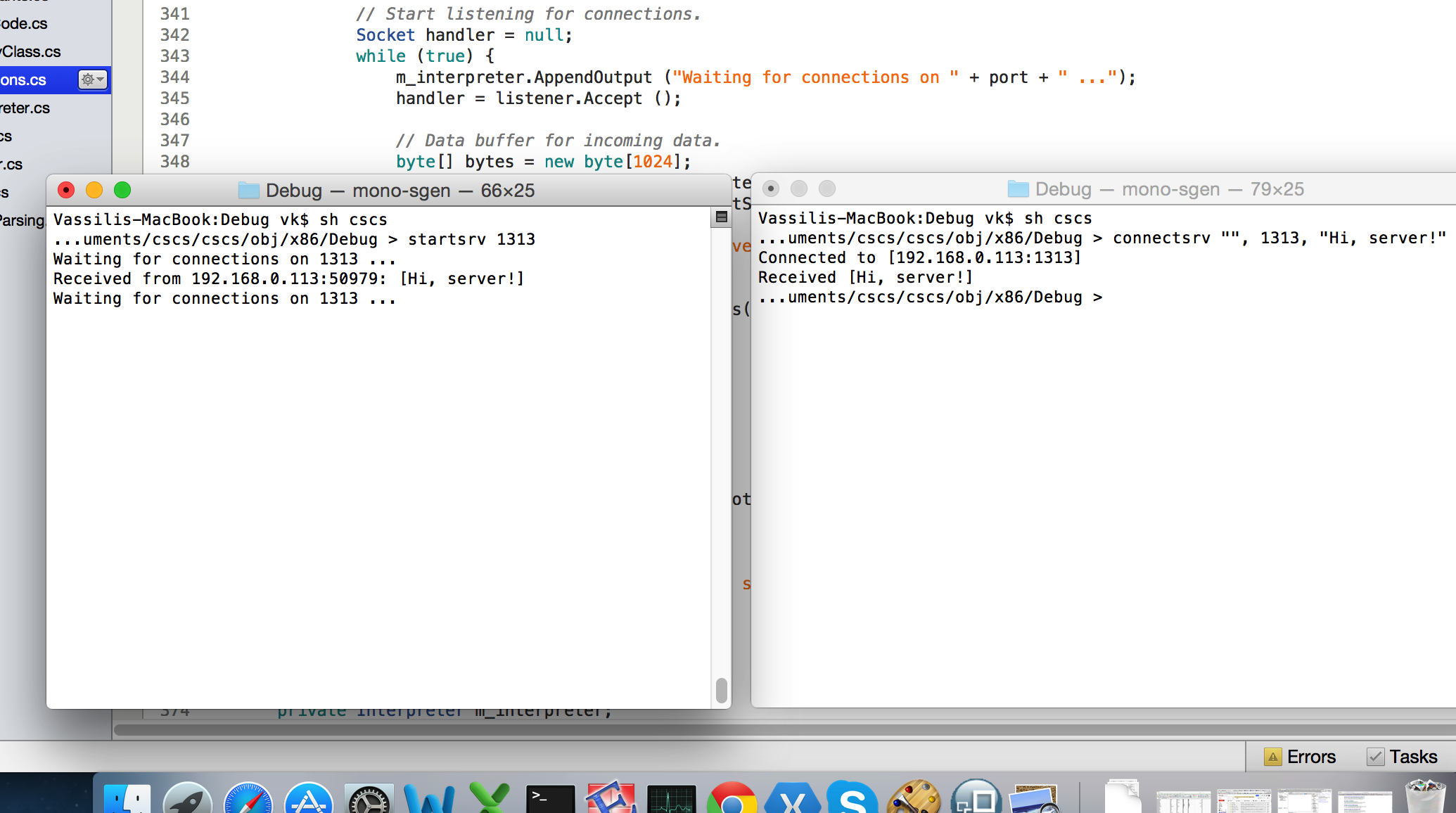
Figure 2 shows an example run of a client and a server on a Mac.
Any function that you want to use in CSCS can be implemented in C#. But can you implement a function in the scripting language, in CSCS itself?
Writing Custom Functions in CSCS
You define custom functions with the custom function definition in the Constants.cs file:
public const string FUNCTION = "function";
To tell the Parser to execute special code as soon as it sees the function keyword, you need to register the function handler with the handler. The Interpreter class does that:
ParserFunction.AddGlobal(Constants.FUNCTION,
new FunctionCreator(this));
You can provide a translation to any language in the configuration file and the same applies to all other functions. See the project configuration file in the accompanying source code download (on the CODE Magazine website). You'll find the Spanish keyword funci?n there. In order to use all of the available translations, you must also register them in the Interpreter:
AddTranslation(languageSection, Constants.FUNCTION);
Check out the implementation of the Function Creator in Listing 3.
Listing 3: Implementation of the Function Creator class
class FunctionCreator : ParserFunction
{
internal FunctionCreator(Interpreter interpreter)
{
m_interpreter = interpreter;
}
protected override Variable Evaluate(
string data, ref int from)
{
string funcName = Utils.GetToken(data, ref from,
Constants.TOKEN_SEPARATION);
m_interpreter.AppendOutput("Registering function [" +
funcName + "] ...");
string[] args = Utils.GetFunctionSignature(data, ref from);
if (args.Length == 1 && string.IsNullOrWhiteSpace(args[0]))
{
args = new string[0];
}
Utils.MoveForwardIf(data, ref from,
Constants.START_GROUP, Constants.SPACE);
string body = Utils.GetBodyBetween(data, ref from,
Constants.START_GROUP, Constants.END_GROUP);
CustomFunction customFunc = new CustomFunction(funcName,
body, args);
ParserFunction.AddGlobal(funcName, customFunc);
return new Variable(funcName);
}
private Interpreter m_interpreter;
}
It creates another function and registers it with the Parser:
CustomFunction customFunc = new CustomFunction(
funcName, body, args);
ParserFunction.AddGlobal(funcName, customFunc);
The name of the custom function to be registered is funcName. The Parser expects that the token with the function name will be the next one after the function token. Commas separate the tokens.
All of the functions that you implement in the CSCS code correspond to the different instances of the C# CustomFunction class.
During parsing, as soon as the Parser encounters the funcName token, it calls its handler, the CustomFunction, where all the action takes place. You can see the CustomFunction implementation in Listing 4.
Listing 4: Implementation of the custom function class
class CustomFunction : ParserFunction
{
internal CustomFunction(string funcName,
string body, string[] args)
{
m_name = funcName;
m_body = body;
m_args = args;
}
protected override Variable Evaluate(string data,
ref int from)
{
bool isList;
List<Variable> functionArgs = Utils.GetArgs(data,
ref from, Constants.START_ARG, Constants.END_ARG,
out isList);
Utils.MoveBackIf(data, ref from, Constants.START_GROUP);
if (functionArgs.Count != m_args.Length) {
throw new ArgumentException("Function [" + m_name +
"] arguments mismatch: " + m_args.Length + " declared, " +
functionArgs.Count + " supplied");
}
// 1. Add passed arguments as local variables to the Parser.
StackLevel stackLevel = new StackLevel(m_name);
for (int i = 0; i < m_args.Length; i++) {
stackLevel.Variables[m_args[i]] = new GetVarFunction(
functionArgs[i]);
}
ParserFunction.AddLocalVariables(stackLevel);
// 2. Execute the body of the function.
int temp = 0;
Variable result = null;
while (temp < m_body.Length - 1)
{
result = Parser.LoadAndCalculate(m_body, ref temp,
Constants.END_PARSE_ARRAY);
Utils.GoToNextStatement(m_body, ref temp);
}
ParserFunction.PopLocalVariables();
return result;
}
private stringm_body;
private string[] m_args;
}
Custom function does two things. First, it extracts the function arguments and adds them as local variables to the Parser (they'll be removed from the Parser as soon as the function execution is finished or an exception is thrown).
Second, the body of the function is evaluated, using the main Parser entry point, the LoadAndCalculate() method if the body contains calls to other functions, or to itself, the calls to the CustomFunction can be recursive. Let's see this with the factorial example.
Example: Factorial
The factorial notation is n! and it's defined as follows: 0! = 1, n! = 1 * 2 * 3 * ... * n.
In the notation, n must be a non-negative integer. Therefore it can be defined recursively as: n! = 1 * 2 * 3 * ... * (n - 1) * n = (n - 1)! * n.
In CSCS, the code is the following:
function factorial(n) {
if (!isInteger(n)) {
exc = "Factorial is for integers only (n="+n+")";
throw (exc);
}
if (n < 0) {
exc = "Negative number (n="+n+") for factorial";
throw (exc);
}
if (n <= 1) {
return 1;
}
return n * factorial(n - 1);
}
The factorial function above uses an auxiliary isInteger() function:
function isInteger(candidate) {
return candidate == round(candidate);
}
The isInteger() function calls yet another round() function. The implementation of the round() function isn't in CSCS but is already in C# code that you saw in the previous section.
Executing the factorial function with different arguments provides the following output:
.../Documents/cscs/cscs/bin/Debug>> a = factorial(-1)
Negative number (n=-1) for factorial
.../Documents/cscs/cscs/bin/Debug>> a = factorial(1.5)
Factorial is for integers only (n=1.5)
.../Documents/cscs/cscs/bin/Debug>> a = factorial(6)
720
The factorial code contains some throw() statements. This suggests that there should be something able to catch them.
Throw, Try, and Catch Control Flow Statements
The try() and throw() control flow statements can be implemented as functions in the same way that you saw the implementation of the Round() function above.
Both functions must be registered with the Parser first as well:
public const string TRY = "try";
public const string THROW = "throw";
The implementation of the throw() function follows:
class ThrowFunction : ParserFunction
{
protected override Variable Evaluate(
string data, ref int from)
{
// 1. Extract what to throw.
Variable arg = Utils.GetItem(data, ref from);
// 2. Convert it to a string.
string result = arg.AsString();
// 3. Throw it!
throw new ArgumentException(result);
}
}
The try function requires a bit more work, so it's easier to delegate all the work to the Interpreter, which can tell the Parser what to do:
class TryBlock : ParserFunction
{
internal TryBlock(Interpreter interpreter)
{
m_interpreter = interpreter;
}
protected override Variable Evaluate(
string data, ref int from)
{
return m_interpreter.ProcessTry(data, ref from);
}
private Interpreter m_interpreter;
}
In the Interpreter.ProcessTry() implementation, first you should note where you started the processing (so later on you can return back to skip the whole try-catch block). Then you process the try block, and if the exception is thrown, you catch it. In the Parser code, you throw only ArgumentException exceptions.
int startTryCondition = from - 1;
int currentStackLevel =
ParserFunction.GetCurrentStackLevel();
Exception exception = null;
Variable result = null;
try {
result = ProcessBlock(data, ref from);
}
catch(ArgumentException exc) {
exception = exc;
}
If there's an exception, or a catch or a break statement, you need to skip the whole catch block. For that, go back to the beginning of the try block and then skip it:
if (exception != null ||
result.Type == Variable.VarType.BREAK ||
result.Type == Variable.VarType.CONTINUE)
{
from = startTryCondition;
SkipBlock(data, ref from);
}
After the try block, you expect a catch token and the name of the exception to be caught, regardless of whether the exception was thrown or not:
string catchToken = Utils.GetNextToken(data, ref from);
from++; // skip opening parenthesis
// The next token after the try must be a catch.
if (!Constants.CATCH_LIST.Contains(catchToken))
{
throw new ArgumentException(
"Expecting a 'catch()' but got [" +
catchToken + "]");
}
string exceptionName = Utils.GetNextToken(data, ref from);
from++; // skip closing parenthesis
Why do you use a CATCH_LIST to see if the catch keyword is there and not just Constants.CATCH = "catch"? Because the CATCH_LIST contains all possible translations of the catch keyword in different languages. You provide them in the configuration file. For example, you can use atrapar in Spanish, or fangen in German.
In case of an exception, you must process the catch block. You first create an exception stack (what was called from what) and then add this information to the exception variable that can be used in the CSCS code that caught the expression:
if (exception != null) {
string excStack = CreateExceptionStack(
currentStackLevel);
ParserFunction.InvalidateStacksAfterLevel(
currentStackLevel);
GetVarFunction excFunc = new GetVarFunction(
new Variable(Double.NaN,
exception.Message + excStack));
ParserFunction.AddGlobalOrLocalVariable(
exceptionName, excFunc);
result = ProcessBlock(data, ref from);
ParserFunction.PopLocalVariable(
exceptionName);
}
In case there's no exception, skip the catch block:
else {
SkipBlock(data, ref from)
}
Let's try throwing and catching exceptions in action with the factorial function that you saw above. You use the following CSCS code that has some artificially created execution stacks for throwing an exception:
function trySuite(n) {
print("Trying to calculate the",
"negative factorial?");
result = tryNegative(n);
return result;
}
function tryNegative(n) {
return factorial(-1 * n);
}
try {
f = tryNegative(5);
print("factorial(", n, ")=", f);
} catch(exc) {
print ("Caught Exception: ", exc);
}
After running it, you get the following exception message:
Trying to calculate negative factorial...
Caught Exception: Negative number (n=-5)
for factorial at
factorial()
tryNegative()
trySuite()
Of course, this is a bare bones exception handling so you might want to add some fancier stuff, like at what line of the function the exception was thrown, function parameters, and so on.
How do you keep track of the execution stack? That is, of the functions being called? In ParserFunctions, you define the following static variable:
public class StackLevel
{
public StackLevel(string name = null) {
Name = name;
Variables = new Dictionary<string,
ParserFunction> ();
}
public string Name { get; set; }
public Dictionary<string, ParserFunction> Variables
{ get; set; }
}
private static Stack<StackLevel> s_locals =
new Stack<StackLevel>();
Each StackLevel consists of all of the local variables of the function being executed (including the passed-in parameters) and the function name. This is the name you see in the exception stack.
Each time you start execution of a new function (regardless of whether it's defined in the C# code or in the CSCS code), a new StackLevel is added to the s_locals stack. You pop up one StackLevel from the s_locals data structure each time you finish the execution of a function.
In the examples, you saw a few functions implemented in CSCS. Do all of the scripts have to be in the same file? Can you include other files containing the CSCS code?
Including Other Files Containing the CSCS Code
To include another module containing CSCS scripts, you use the same function approach as with all other functions, like you used with Round() or try/throw control statements. The include keyword is also defined in Constants.cs:
public const string INCLUDE = "include";
The function implementation is in the IncludeFile class deriving from the ParserFunction class:
ParserFunction.AddGlobal(Constants.INCLUDE,
new IncludeFile());
In the CSCS code, including another file looks like this:
include("filename.cscs");
As soon as the Parser gets the INCLUDE token (or one of its translations), the execution of IncludeFile.Evaluate() is triggered. This function must first extract the actual script from the file to be included:
class IncludeFile : ParserFunction
{
protected override Variable Evaluate(
string data, ref int from)
{
string filename = Utils.ResultToString(
Utils.GetItem(data, ref from));
string[] lines = Utils.GetFileLines(filename);
string includeFile = string.Join(
Environment.NewLine, lines);
string includeScript =
Utils.ConvertToScript(includeFile);
Then you process the whole script using the Parser main method, LoadAndCalculate(). Note that at the end, you return an empty result because there's nothing to return upon completion.
int filePtr = 0;
while (filePtr < includeScript.Length)
{
Parser.LoadAndCalculate(includeScript,
ref filePtr, Constants.END_LINE_ARRAY);
Utils.GoToNextStatement(includeScript,
ref filePtr);
}
return Variable.EmptyInstance;
}
}
All of the global functions added from the included file stay with the Parser after completion of the Include statement.
You can implement if, when, for, and other control flow statements in the same way you implemented the including of a file. I haven't implemented the for loop because its functionality can be easily achieved with a while loop. Here's an example of such a substitution of the for loop in the CSCS code:
i = 0;while (i++ < 10) {
if (i % 2 == 0) {
print (i, " is even.");
} else {
print (i, " is odd.");
}
}
Try to guess: In the CSCS code above, how many of the tokens are implemented as functions (that is, classes deriving from the ParserFunction class)? There are four: while(), if(), print(), and `++``. Else isn't a function by itself, it's processed together with if (similarly, catch is not a separate function but is processed together with try).
What about the i++ token inside of the while() statement? How is it implemented?
Implementing ++ and – Prefix and Postfix and Compound Assignment Operators
You can use the same approach for assignment as you did for including a file by implementing it as a function set(), for example. This is how I implemented the assignment in the first version of the language described in MSDN Magazine (See the sidebar for a link).
The assignment a = 5 is equivalent to set(a, 5), the prefix operator ++i is equivalent to set(i, i + 1). The postfix operator i++ is a bit longer: i++ is equivalent to set(i, i + 1) - 1 in CSCS.
A language with such awkward assignment operators can't, obviously, be part of the Premier League of programming languages. You need a different approach to have proper assignment operations.
I decided to take the following approach: Declare action functions, all deriving from the abstract ActionFunction class (that derives from the ParserFunction class). An action function is triggered as soon as the Parser gets any of the following action tokens: ++, --, +=, -=, *=, etc. In case of ++ and --, you need first to find whether it's a prefix or a postfix operator - the Parser will know that: In case of a prefix, it will have an unprocessed token before the action.
All of the actions must be registered with the Parser first:
ParserFunction.AddAction(Constants.ASSIGNMENT,
new AssignFunction());
ParserFunction.AddAction(Constants.INCREMENT,
new IncrementDecrementFunction());
ParserFunction.AddAction(Constants.DECREMENT,
new IncrementDecrementFunction());
Check out the implementation of the IncrementDecrementFunction() in Listing 5. The implementation of other action functions is analogous. As you can see, the Parser knows from the context whether it works with a prefix or a postfix operator and if it was triggered because of a -- or a ++ action. Note that at the end, the function returns either the current variable value (in case of the prefix) or the previous value in case of the postfix.
Listing 5: Implementation of the ++ and – operators
protected override Variable Evaluate(string data,
ref int from)
{
bool prefix = string.IsNullOrWhiteSpace(m_name);
if (prefix)
{// If it's a prefix we do not have variable name yet.
m_name = Utils.GetToken(data, ref from,
Constants.TOKEN_SEPARATION);
}
// Value to be added to the variable:
int valueDelta = m_action == Constants.INCREMENT ? 1 : -1;
int returnDelta = prefix ? valueDelta : 0;
// Check if the variable to be set has the form of x(0),
// meaning that this is an array element.
double newValue = 0;
int arrayIndex = Utils.ExtractArrayElement(ref m_name);
bool exists = ParserFunction.FunctionExists(m_name);
if (!exists)
{
throw new ArgumentException("Variable [" + m_name +
"] doesn't exist");
}
Variable currentValue = ParserFunction.GetFunction(m_name)
GetValue(data, ref from);
if (arrayIndex >= 0)
{// A variable with an index (array element).
if (currentValue.Tuple == null)
{
throw new ArgumentException("Tuple [" + m_name +
"] doesn't exist");
}
if (currentValue.Tuple.Count <= arrayIndex)
{
throw new ArgumentException("Tuple [" + m_name +
"] has only " + currentValue.Tuple.Count + " elements");
}
newValue = currentValue.Tuple[arrayIndex].Value + returnDelta;
currentValue.Tuple[arrayIndex].Value += valueDelta;
}
else // A normal variable.
{
newValue = currentValue.Value + returnDelta;
currentValue.Value += valueDelta;
}
Variable varValue = new Variable(newValue);
ParserFunction.AddGlobalOrLocalVariable(m_name,
new GetVarFunction(currentValue));
return varValue;
}
With this approach, you can play around with the assignments in CSCS as follows:
a = 1;
b = a++ - a--; // b = -1, a = 1
c = a = (b += 1); // a = b = c = 0
a -= ++c; // c = 1, a = -1
c = --a - ++a; // a = -1, c = -1
The Listing 5 has a section about arrays. I haven't talked about them yet. How do the assignments work with arrays?
Arrays
The declaration of an array is different from the declaration of a variable in CSCS. To declare an array and initialize it with data, you use the same statement. As an example, here's the CSCS code:
a = 20;
arr = {++a-a--, ++a*exp(0)/a--,
-2*(--a - ++a), ++a};i = 0;
while(i < size(arr)) {
print("a[", i, "]=", arr[i],
", expecting ", i);
i++;
}
The number of elements in the array isn't explicitly declared because it can be deduced from the assignment.
The function size() is implemented as a typical CSCS function returning the number of elements in an array. But if the passed argument isn't an array, it returns the number of characters in it.
Internally, an array is implemented as a C# list so you can add elements to it on the fly.
You access elements of an array, or modify them, by using the squared brackets. If you access an element of an array and that element has not been initialized yet, an exception will be thrown by the Parser. However, it's possible to assign a value to just one element of an array, even if the index used is greater than the number of elements in the array. In this case, non-existing elements of the array are initialized with empty values. This happens even if it's the first assignment for this array. For this special shortcut array assignment, the CSCS function set() is used:
i = 10;while(--i > 0) {
newarray[i] = 2*i;
}
print("newarray[9]=", newarray[9]); // 18
print("size(newarray)=", size(newarray)); // 10
Check out the array implementation in the accompanying source code download (available through the CODE Magazine website).
Compiling on Various Operating Systems
It's a common misunderstanding that C# is for Windows only. People may have heard of a few attempts to port it to other operating systems, but most think that those attempts are still in some kind of a work in progress.
After using Xamarin Studio for Mac for some time, I found that it's not quite a work in progress but rather a very powerful tool to build and run C# apps on a Mac. And it's free! The underlying free and open source Mono project currently supports .NET 4.5 with C# 5.0. Recently, Microsoft announced that it's planning to acquire Xamarin, so the support should continue and hopefully Xamarin Studio for Mac will be kept free (you can also use C# with Xamarin for iOS and Android programming, but this is already not free).
Xamarin doesn't support any Windows Forms, but what concerns the core C# language is that I didn't have to change a single line of code when porting my Visual Studio project from Windows. What I did have to change is the configuration file. For Windows the configuration looks like this:
<configuration>
<configSections>
<section name="Languages" type=
"System.Configuration.NameValueSectionHandler"/>
<section name="Synonyms" type=
"System.Configuration.NameValueSectionHandler"/>
Unfortunately, this wouldn't work with Xamarin. There you must add ,System to the type:
<configuration>
<configSections>
<section name="Languages" type=
"System.Configuration.
NameValueSectionHandler,System"/>
<section name="Synonyms" type=
"System.Configuration.
NameValueSectionHandler,System"/>
That configuration won't work with Visual Studio, so you must use different configuration files with Visual Studio than with Xamarin.
There's also a way to use C# macros if you want to have different code when you use your language on Windows and on Mac OS. This especially makes sense if you work with the file system.
Implementing a Directory Listing on Windows and on Mac OS
The Xamarin Studio uses the Mono Framework and the macro to use if you want to know if you're using Mono is #ifdef MonoCS. You can see it at work here:
public static string GetPathDetails(FileSystemInfo fs,
string name)
{
string pathname = fs.FullName;
bool isDir = (fs.Attributes &
FileAttributes.Directory) != 0;
#if __MonoCS__
Mono.Unix.UnixFileSystemInfo info;
if (isDir) {
info = new Mono.Unix.UnixDirectoryInfo(pathname);
} else {
info = new Mono.Unix.UnixFileInfo(pathname);
}
In the code snippet above, you see Unix-specific code to get the directory or file data structure. Using this structure, it's easy to find typical Unix permissions for user/group/others, which don't make sense on Windows:
char ur = (info.FileAccessPermissions & Mono.Unix.
FileAccessPermissions.UserRead) != 0 ? 'r' : '-';
char uw = (info.FileAccessPermissions & Mono.Unix.
FileAccessPermissions.UserWrite) != 0 ? 'w' : '-';
char ux = (info.FileAccessPermissions & Mono.Unix.
FileAccessPermissions.UserExecute) != 0 ? 'x' : '-';
char gr = (info.FileAccessPermissions & Mono.Unix.
FileAccessPermissions.GroupRead) != 0 ? 'r' : '-';
...
string permissions = string.Format(
"{0}{1}{2}{3}{4}{5}{6}{7}{8}",
ur, uw, ux, gr, gw, gx, or, ow, ox);
Take a look at Listing 6 for the complete implementation of the GetPathDetails() function.
Listing 6: Get directory or file info on Unix and on Windows
public static string GetPathDetails(FileSystemInfo fs, string name)
{
string pathname = fs.FullName;
bool isDir = (fs.Attributes & FileAttributes.Directory) != 0;
char d = isDir ? 'd' : '-';
string last = fs.LastAccessTime.ToString("MMM dd yyyy HH:mm");
#if __MonoCS__
Mono.Unix.UnixFileSystemInfo info;
if (isDir) {
info = new Mono.Unix.UnixDirectoryInfo(pathname);
} else {
info = new Mono.Unix.UnixFileInfo(pathname);
}
char ur = (info.FileAccessPermissions &
Mono.Unix.FileAccessPermissions.UserRead) != 0 ? 'r' : '-';
char uw = (info.FileAccessPermissions &
Mono.Unix.FileAccessPermissions.UserWrite) != 0 ? 'w' : '-';
char ux = (info.FileAccessPermissions &
Mono.Unix.FileAccessPermissions.UserExecute) != 0 ? 'x' : '-';
char gr = (info.FileAccessPermissions &
Mono.Unix.FileAccessPermissions.GroupRead) != 0 ? 'r' : '-';
char gw = (info.FileAccessPermissions &
Mono.Unix.FileAccessPermissions.GroupWrite) != 0 ? 'w' : '-';
char gx = (info.FileAccessPermissions &
Mono.Unix.FileAccessPermissions.GroupExecute) != 0 ? 'x' : '-';
char or = (info.FileAccessPermissions &
Mono.Unix.FileAccessPermissions.OtherRead) != 0 ? 'r' : '-';
char ow = (info.FileAccessPermissions &
Mono.Unix.FileAccessPermissions.OtherWrite) != 0 ? 'w' : '-';
char ox = (info.FileAccessPermissions &
Mono.Unix.FileAccessPermissions.OtherExecute) != 0 ? 'x' : '-';
string permissions = string.Format("{0}{1}{2}{3}{4}{5}{6}{7}{8}",
ur, uw, ux, gr, gw, gx, or, ow, ox);
string user = info.OwnerUser.UserName;
string group = info.OwnerGroup.GroupName;
string links = info.LinkCount.ToString();
long size = info.Length;
if (info.IsSymbolicLink) {
d = 's';
}
#else
string user = string.Empty;
string group = string.Empty;
string links = null;
string permissions = "rwx";
long size = 0;
if (isDir)
{
user = Directory.GetAccessControl(fs.FullName).GetOwner(
typeof(System.Security.Principal.NTAccount)).ToString();
DirectoryInfo di = fs as DirectoryInfo;
size = di.GetFileSystemInfos().Length;
}
else {
user = File.GetAccessControl(fs.FullName).GetOwner(
typeof(System.Security.Principal.NTAccount)).ToString();
FileInfo fi = fs as FileInfo;
size = fi.Length;
string[] execs = new string[] { "exe", "bat", "msi"};
char x = execs.Contains(fi.Extension.ToLower()) ? 'x' : '-';
char w = !fi.IsReadOnly ? 'w' : '-';
permissions = string.Format("r{0}{1}", w, x);
}
#endif
string infoStr = string.Format(
"{0}{1} {2,4} {3,8} {4,8} {5,9} {6,23} {7}",
d, permissions, links, user, group, size, last, name);
return infoStr;
}
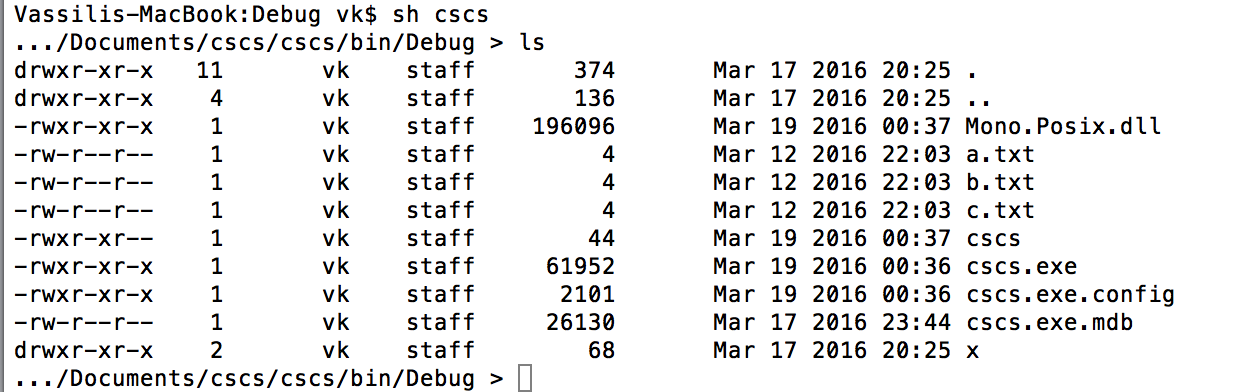
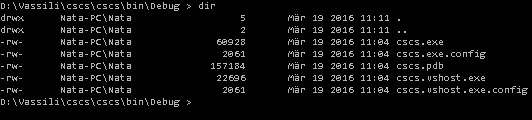
Figure 3 shows running the ls command on a Mac and Figure 4 shows running a dir command on a PC.
The question that might strike you now is: “How do I configure using the ls command on a Mac and the dir command on a PC for the same CSCS function?”
Keywords in Different Languages
If you want a keyword to be used in any other language, you must add a code so that you can read possible translations from the configuration file. For example, I defined the keyword for a function to show the contents of a directory as follows:
public const string DIR = "dir";
Now, if I want possible translations of this keyword I add in the Interpreter initialization code:
AddTranslation(languageSection, Constants.DIR);
Because ls isn't really a translation from dir to a foreign language, I added the Synonyms configuration section to smooth the differences between Windows and Mac concepts, so that they don't look so foreign to each other:
<Languages> <add key="languages" value=
"Synonyms,Spanish,German,Russian" />
</Languages>
<Synonyms>
<add key="del" value ="rm" />
<add key="move" value ="mv" />
<add key="copy" value ="cp" />
<add key="dir" value ="ls" />
<add key="read" value ="scan" />
<add key="writenl" value ="print" />
</Synonyms>
Using the same configuration file, you can add translations for the CSCS keywords in any language. Here's a valid CSCS code to check whether a number is odd or even using the German keywords:
ich = 0;
solange (ich++ < 10) {
falls (ich % 2 == 0) {
drucken (ich, " Gerade Zahl");
} sonst {
drucken (ich, " Ungerade Zahl");
}
}
Wrapping Up
Using the techniques presented in this article and consulting the accompanying source code download, you can develop your own fully customized language using your own keywords and functions. The resulting language will be interpreted at runtime directly, statement by statement.
The straightforward way of adding new functionality to the language is the following:
- Think of an English keyword (primary name) of the function to be implemented in English:
public const string ROUND = "round";
- Map this keyword to a C# class and register them both with the Parser:
ParserFunction.AddGlobal(Constants.ROUND,
new RoundFunction());
- Make it possible to read translations of this keyword from any language from the configuration file:
AddTranslation(languageSection, Constants.ROUND);
- Implement the class registered above with the Parser. The class must derive from the ParserFunction class and you must override the Evaluate() method.
That's it: using the technique above, you can implement not only the typical functions like round(), sin(), abs(), sqrt(), and so on, but most of the control flow statements, like if(), while(), break, return, continue, throw(), include(), etc. All variables declared in the CSCS code are implemented the same way: you register them as functions with the Parser.
You can use this language as a shell language to perform different file or operating system commands (find files, list directories or running processes, kill or start a new process from the command line, and so on). Or you can use it as a scripting language, writing any tasks and adding them to the scripts for execution. Basically, any task can be achieved in CSCS as long as it's possible to implement it in C#.
There are a few things that are still far from perfect and could be added to the CSCS language. For instance, the debugging possibilities are next to nil. The exception handling is quite basic, so adding the possibility for the exception stack to show the line of code where it occurred would be interesting. Also, currently, only the list data structure is supported in CSCS (I call it tuple). Adding the possibility to use other data structures, like dictionaries, for instance, would be also an interesting exercise: let me know what you come up with!
