


The value of URLs for a website cannot be understated. The scheme of URLs can help give clues to visitors and machines alike regarding the structure of your website and well-crafted locations help facilitate search engine indexing, bookmarking and sharing. The role of URLs in Ajax applications becomes even more important as content is often changing on the page while the URL remains untouched.
Deep linking in an Ajax application is the practice of providing a link that returns a user to a particular set of content or state of the application. To achieve deep linking, you must manipulate the URL in one way or another in order to have unique URL values for different areas of the Ajax site.
To achieve deep linking you must manipulate the URL in one way or another in order to have unique URL values for different areas or state of the Ajax application.
A foundational principle of the Ajax design pattern is to limit the number of full requests back to the server so that background requests retrieve only the content required for a specific purpose. Therefore explicitly changing the window.location of the current browser window to keep URLs in sync with Ajax operations is ineffective because this causes the browser to load the given page from the server.
A common pattern to overcome this issue is to build sites that rely on hash values to uniquely identify content for the site. While hash-based implementations are pervasive, they are now not the only choice.
The Hash-Bang Pattern
The problem of deep-linking Ajax applications is usually solved by updating the hash value of the URL. This works nicely because the URL is updated for the page, without causing an unintended request back to the server. Using the hash symbol (#), along with a convention established by Google of including an exclamation point (!) directly after the hash, is commonly referred to as the hash-bang technique.
The promise of the hash-bang approach is that you can use this pattern to help provide unique URLs for your Ajax applications and Google will attempt to index content that included the exclamation point in the location.
Listing 1 includes a code listing that implements hash-bang navigation for your reference.
Note: There are two approaches used in the code sample that accompany this article. The HTML files used for both the hash-bang and history object sample are nearly identical. The only difference between the two is whether or not the pages are referencing the hash-bang script or the history object script. Listings 2, 3 and 4 show the code for the HTML files.
Advantages
Using the hash-bang pattern enables your website to have unique URLs that represent different levels of depth and content in your application. Further, changing the hash value successfully makes changes to the window location without forcing a full post back to the server - which is the central concern of Ajax applications.
The browser’s back and forward buttons keep track of the history state which includes different hash values. Extracting the hash value is easy with a simple call to window.location.hash and support for the associated hashchange event enjoys widespread browser support reaching back to IE 8, Firefox 3.6, Chrome 5, Safari 5 and Opera 10.6.
Disadvantages
Some developers criticize this technique because of its inability to keep what many consider to be “clean” URLs that are easy for users to hack and for search engines to index. Remember, the hash-bang design pattern was established by Google. Bing requires you set a special configuration option in their Webmaster tools to support what they call “Ajax Crawl Settings” and other indexing services may not support it at all.
Further, performance is ultimately affected when content is solely identified by unique hash values. Since the hash value is never sent to the server, Ajax applications must first serve the application shell, read the hash value and then finally send an additional request to the server for the content of the page.
In a famed attempt to change from standard URLs to hash-bag URLs, the article, “Gawker Learns the Hard Way Why ‘Hash-Bang’ URLs are Evil” (http://isolani.co.uk/blog/javascript/BreakingTheWebWithHashBangs) details how content heavyweight Gawker experienced unexpected pain in adopting a hash-based URL design. Content-rich sites want to take advantage of the benefits provided by a hash-based technique, but the sole reliance on JavaScript can prove too risky of an approach for some websites.
Lastly, for content sites with inner-document links that use hash values (e.g. #top to jump to the top of the page) may encounter a collision of hash values where the page is attempting to use the hash value as the unique identifier, but the content wants to use the hash value to jump to a different inner-document location.
The History Object in HTML5
Traditionally, the window.history object is mostly used to help you programmatically manipulate the browser history with functions like back and forward allowing your script to take the user to the previous or last page visited. With the advent of HTML5, the history object now features the pushState and replaceState functions as well as a new event available off the root window object called popstate.
The pushState function is responsible for changing the browser’s URL without initiating requests back to the server.
The pushState function is responsible for changing the browser’s URL without initiating requests back to the server. Arguments for the pushState function include:
-
state: The first argument allows you to pass state information to the popstate event when it fires. The value for state should be any construct that can be represented as a string; therefore, you can pass in JSON objects that are serializable. Generally you would want to at least pass in a reference to the destination URL, so it’s available when the popstate event is raised when the user clicks the back or forward buttons, but browser support for the state argument is inconsistent (meaning in some cases it doesn’t work at all). Null values are allowed. -
title: The second argument is a bit of a mystery. At present all browsers ignore this argument and there are lengthy discussions regarding what it should actually do when it is ever supported. Prevailing wisdom seems to be to pass in some sort of string (rather than a null) in order to keep your script future-proof in the event support for this argument begins to emerge. -
url (optional): Ironically, the only argument that enjoys consistent implementation is considered optional, but you’ll likely always need to pass in a value into the url argument. This argument represents the URL of where you want to update the browser’s location. The value you pass in is relative to the current page and adheres to the same origin policy, meaning if you attempt to pass in a location from a different server, an exception is thrown.
The replaceState function is the same as the pushState function in terms of functionality and arguments, except instead of creating a new history entry for the destination page, the current page is replaced in the browser history with the destination page passed into the function.
The final area of support for the new history API is the addition of the popstate event. The window.onpopstate event fires when a user clicks the back or forward button, and (in some browsers) when the page loads. The event arguments are designed to include information of the state information passed in by the first argument in the pushState or replaceState functions, but unfortunately not all browsers persist this information in the same way. Therefore the example in this article avoids using the state object and detects the current page by examining the current window location.
Advantages
Using the history object to manipulate the URL ensures that you always have a real URL (where the full contents of the location are sent to the server), but as you make changes you are ensured that you are not forced to make undesired requests back to the server.
Further, as users return to URLs generated by your script, the full page can be assembled and returned upon the first page request. This benefits search engines as well as the ultimate performance of your page since the entire contents of the page can be included in the initial payload of the page.
Disadvantages
The biggest disadvantage of using the new history object members comes down to browser support. At present, the browsers that support the new members include:
- IE 10
- Firefox 14 +
- Chrome 21 +
- Safari 5.1 + (Support is partial, but your script can work around these limitations)
- iOS Safari 5 +
- Opera 12 +
- Blackberry 7 +
- And the following browsers do not support the API:
- IE 9 and lower
- Opera Mini
- Android (support was included in version 2.3, but in current versions the feature is buggy)
The glaring issue with this support list is that IE 8 and IE 9, some of the most popular browsers used to access the web, do not include support for pushState, replaceState or the popstate event.
The disparity of support means that you need to make sure your site still operates effectively in any browser that doesn’t provide support for these members. What’s nice about the URLs you’re able to create using pushState is that they are full URLs where everything is sent to the server which allows you to serve the entire page and not just a fragment when the server receives a request for a full page. The example included in this article demonstrates how to use pushState with links that continue to work if JavaScript is disabled or if a non-supporting browser is running the page.
Concepts
The example implemented in this article uses the approach common to many Single Page Applications (SPA - http://en.wikipedia.org/wiki/Single_page_application) where a single page acts as the host page for other content loaded on demand into the page. In this case, the use of page templates ensures that every page, at one time or another, acts as the content host as well as a content page.
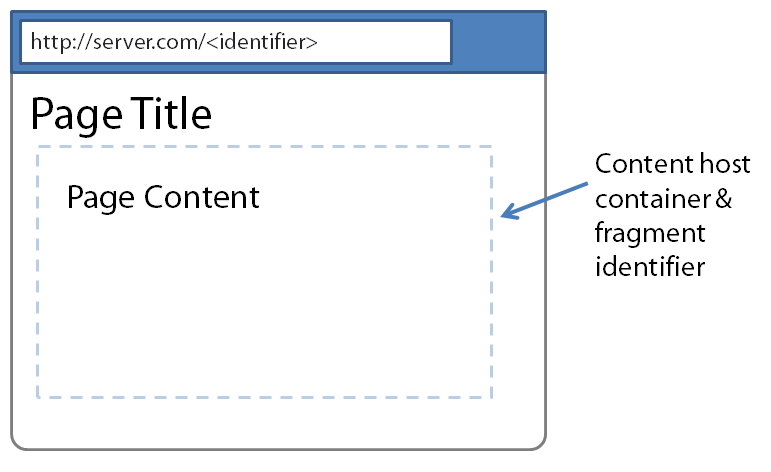
Figure 1 depicts how the HTML pages are structured. Each has the required structure around the page along with a content container whose inner HTML is replaced with a fragment of HTML from a content page. The identifier in the URL represents the unique identifier of the page content that is loaded into the page.
What makes use of the history object’s new members so valuable is that even though you can programmatically change the browser location without posting back to the server, at the same time that updated location is nothing more than a regular URL, which can be shared, copied or bookmarked. This means that you need to make sure your application works just as well upon the initial request of the page as it does when JavaScript is used to fetch the page.
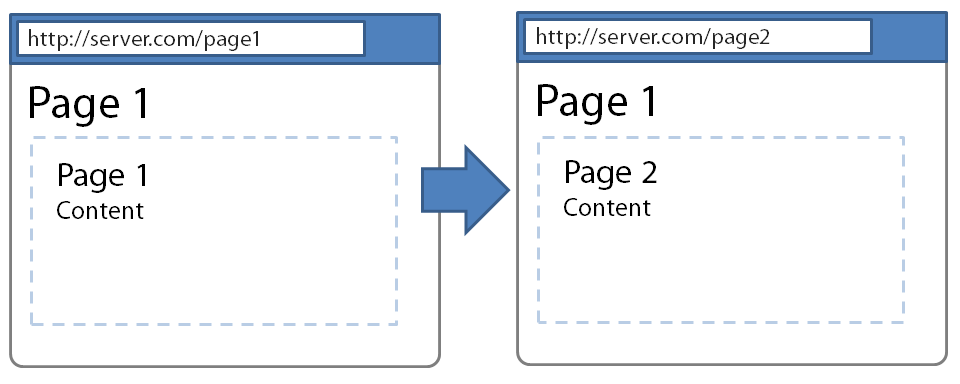
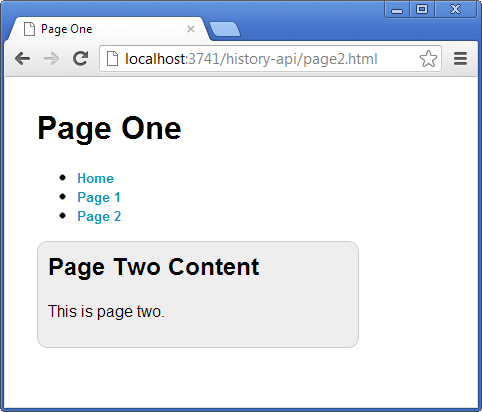
Figure 2 demonstrates how Page 1 is affected by navigating to Page 2 using the history.pushState function. The overall structure of the page is preserved and after the response of an Ajax call is received, only the page fragment is injected into the content container. Notice how the page title remains the same, but the URL and content in the container reflect content from Page 2.
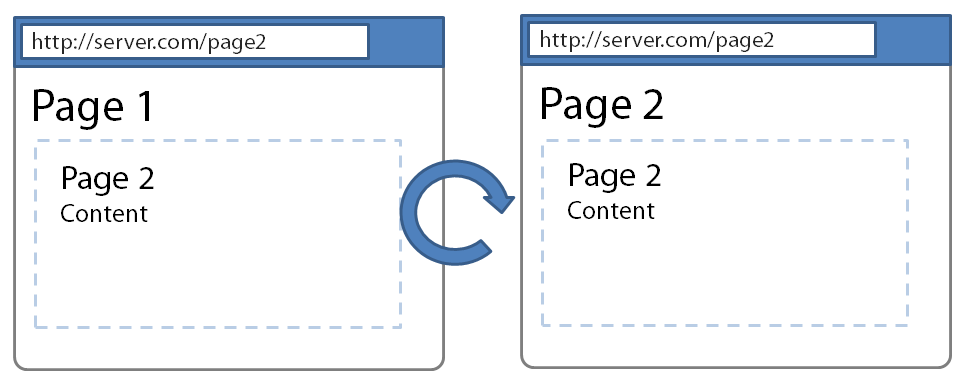
Consider though if you refresh the page after you navigated to Page 2 using pushState. Figure 3 shows how the page, when refreshed, keeps the correct URL and preserves the page content, but the page title reflects that it was served directly from Page 2.
This behavior is achieved by all pages having the same layout structure but include identifiers in the markup to specify the content fragment in the page. This is the same spirit in which a normal client/server web application would serve full HTML pages upon a standard GET request of the page, but then use a service in conjunction with an Ajax call to only update specific parts of the page.
Example
The example in this article, for simplicity’s sake, forgoes a server implementation and uses static HTML files as the content source. The jQuery Ajax APIs work just was well against static HTML files as they do calling a service to get an XML or JSON response. (In this example’s case, the XML response to the Ajax calls is just in the form of the HTML of the content page.)
Figure 4 depicts a Home page constructed in the same manner as described above with a common page structure, navigation and content container. When a user starts at the Home page and then clicks on the link for Page 1, the script makes an Ajax request for Page 1 and extracts the content fragment from the page. This fragment is injected into the content host of Home page. Figure 5 shows you how the page’s URL is updated, the basic structure of the page remains and the content from Page 1 is now injected into the page.
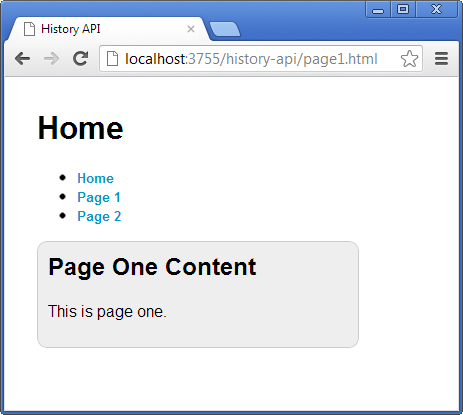
Should you refresh the page at this point, the browser then loads the markup for the entire page for Page 1 and Figure 6 shows how the URL and page-specific content remain the same, but now Page 1 now acts as the content host.
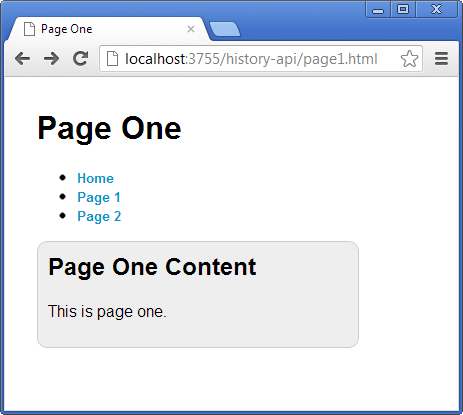
By clicking on the link for Page 2, Figure 7 now depicts how Page 1 now takes on the role of the host and displays Page 2’s content.
HTML
There are three HTML files in this sample: home.html (Listing 2), page1.html (Listing 3), and page2.html (Listing 4). Each page includes the same HTML structure, which includes standard root elements along with a page title, navigation links and a container element, which houses the page-specific content. This container has an ID of content-host so it can accept fragments from other pages and is marked with the CSS class named fragment so its contents can be extracted and rendered in other pages when they are acting as content host.
<h1>Home</h1>
<ul>
<li><a href="home.html" data-role=
"ajax">Home</a></li>
<li><a href="page1.html" data-role=
"ajax">Page 1</a></li>
<li><a href="page2.html" data-role=
"ajax">Page 2</a></li>
</ul>
<div id="content-host" class="fragment">
<h2>Home Page Content</h2>
<p>This is the home page of the application</p>
</div>
In addition, each of the anchor elements is marked with the data-role=“ajax” attribute in order to differentiate links in the application that require Ajax processing from any other links. All other anchors would likely link to other resources on the web or other content in the site that is not managed by the content host.
Note that the values of the href attributes are completely valid locations so if the browser for some reason doesn’t support the navigation scripts or if JavaScript is disabled, the links still work to navigate to the appropriate page.
The DIV element with the ID content-host is an element that accepts HTML fragments on demand to render content in the page.
Listing 5 shows the associated CSS.
JavaScript
All of the code discussed in this section executes inside the traditional self-executing jQuery load handler.
$(function () {
...
});
The getPageName function (Listing 6) is responsible for examining the current window location and extracting just the page name.
function getPageName() {
var
pathName = window.location.pathname,
pageName = "";
if (pathName.indexOf("/") != -1) {
pageName = pathName.split("/").pop();
} else {
pageName = pathName;
}
return pageName;
}
The script first looks to see if there are any forward slashes in the path name and if necessary, it strips out anything in the location before the page name and returns only the name of the current page.
The navigateToPage function is responsible for navigating the browser to the selected page. When using the History API, the URL is first changed, then the popState event is fired, therefore the first order of business is to examine the current location and extract the current page name. If the current page is not the page of origin then it can continue with the navigation.
function navigateToPage() {
var pageName = getPageName();
$.get(pageName, function (response) {
var
markup = $("<div>" + response + "</div>"),
fragment = markup.find(".fragment").html();
$("#content-host").html(fragment);
});
}
This example uses static HTML pages as the content source in order to keep the example simple. Your implementation will in all likelihood include a call to a service that returns a HTML fragment to inject into the content host.
Once a response from the call to $.get is recognized by the browser then the response argument includes the HTML from the content page. The HTML that is returned is the full HTML source from the content page (including the HTML, TITLE, BODY and other supporting elements). In order to make this HTML useful, only the fragment container’s inner HTML is needed to inject into the page.
jQuery’s flexible selection engine allows you to make selections against the existing DOM as well as arbitrary HTML strings. In this case, in order to select the fragment element in the HTML string, jQuery requires all elements to have a common root element so the HTML string is wrapped in a DIV and then the find function is used to locate the content fragment. Finally, the content fragment injected into the content container by calling the html function.
In order to wire up a click event handler to the right links on the page, a special selector is used to target the appropriate elements.
$("a[data-role='ajax']").click(function (e) {
if (Modernizr.history) {
e.preventDefault();
var pageName = $(this).attr("href");
window.history.pushState(null, "", pageName);
navigateToPage();
}
});
Using the attribute-based selector only selects anchors on the page that include the data-role=“ajax” attribute. With the click handler established, processing only happens for browsers that are reported by the Modernizr library to support the new HTML5 history object members. This approach is favorable so that any browsers that do not support the new functionality will continue on and process the links just like normal. When the Ajax interaction is bypassed, the content of the site is still served unhindered as if JavaScript is disabled or if the new history capabilities do not exist.
If the new functionality is present, then the default behavior of the anchor tag is halted by calling preventDefault. Next, the destination of the link is extracted from the current anchor element and then a call to window.history.pushState is used to update the current window location. As noted above, when calling pushState the API allows you to pass in a state object and title, but the state object is not consistently supported and the title is ignored by all the major browser players, so empty values are passed into these arguments. The desired relative destination is passed into the last argument (URL) which at this point is just the page name.
The next order of business is to make sure the back and forward browser buttons work correctly to keep the pages in sync as the user travels back and forth through the browser history. The popstate event is fired when the browser’s back and forward buttons are pressed. Additionally, some browsers raise the popstate event when the page loads.
In order to guard against browser inconsistencies, the implementation for the popstate event handler in this example includes a hack of sorts to make sure pages aren’t loaded multiple times and the appropriate page name is detected.
To begin, a variable is declared which is responsible for tracking how many times the popstate event has fired. In the case of WebKit browsers (Chrome and Safari) the popstate event fires when the page loads, while remaining browsers only raise the event when the browser travels back and forth through the history.
var _popStateEventCount = 0;
Next, the popstate event is handled and the _popStateEventCount is incremented each time the event is fired. Then, the current browser is evaluated using jQuery and if it’s a WebKit browser and this is the first time the popstate event has fired, then the processing is skipped. This effectively makes all the browsers behave in the same manner.
If it’s not a WebKit browser or the popstate counter is greater than one, then the event is firing as a result of the back or forward buttons being pressed and then the navigateToPage function is run rendering the desired page content in the container.
$(window).on('popstate', function (e) {
this._popStateEventCount++;
if ($.browser.webkit &&
this._popStateEventCount == 1) {
return;
}
navigateToPage();
});
This approach allows your pages to work in browsers that do not support pushState and operate consistently in browsers that do support the API, but differ on execution.
Supporting All Browsers
As with most areas of new HTML5 capabilities, the functionality found in the new history object is available via a polyfill library that can fill in the gaps for older browsers or those that are yet to implement the standard.
Quoting from the History.js GitHub home page (https://github.com/balupton/History.js/):
History.js gracefully supports the HTML5 History/State APIs (pushState, replaceState, onPopState) in all browsers. Including continued support for data, titles, replaceState. Supports jQuery, MooTools and Prototype. For HTML5 browsers this means that you can modify the URL directly, without needing to use hashes anymore. For HTML4 browsers it will revert back to using the old onhashchange functionality.
While the backwards compatibility feature is compelling, if you are building a public website, consider the ramifications of URL patterns changing with the browser type or version. Should you choose to later change the routing in your website you must account for not only the established URL patterns, but also the hash patterns produced by the History.js.
Resources
You can find the full source code for both the hash-bang and history examples discussed in this article at: https://github.com/craigshoemaker/HTML5HistoryDemo
If you are interested in reading more in-depth on either technique, please visit the following webpages:
Hash-bang
- Gawker Learns the Hard Way Why ‘Hash-Bang’ URLs are Evil - http://isolani.co.uk/blog/javascript/BreakingTheWebWithHashBangs
- Google Webmaster Tools: Getting Started with Ajax Crawling - https://developers.google.com/webmasters/ajax-crawling/docs/getting-started
- Thoughts on the Hashbang - http://www.adequatelygood.com/2011/2/Thoughts-on-the-Hashbang
HTML5 History
- Manipulating the browser history - https://developer.mozilla.org/en-US/docs/DOM/Manipulating_the_browser_history
- History API changes in Firefox 4 - https://hacks.mozilla.org/2011/03/history-api-changes-in-firefox-4/
- Manipulating History - http://diveintohtml5.info/history.html
Conclusion
Finding the balance between smooth application-like functionality and adhering to the rules and conventions of the stateless web is vital to building sites that are a delight for your users and perform well for search engines. While deep-linking Ajax applications using hash manipulation works for some, the drawbacks cannot be ignored. The HTML5 history APIs, while still emerging in some browsers, lead to clean URLs and an elegant fallback story. Further, since you’re working with normal URLs, indexing and sharing URLs works just like a regular non-Ajax page.
Listing 1: Hash-bang script (script.js)
$(function () {
function navigateToPage() {
var
hash = window.location.hash,
pageName = "";
if (hash != "") {
// change '#!/page1.html' to 'page1.html'
pageName = hash.substring(3, hash.length);
$.get(pageName, function (response) {
var
// Wrap the resulting HTML string with a
// parent node jQuery can properly
// select against it.
markup = $("<div>" + response + "</div>"),
// Extract the fragment out of the markup.
fragment = markup.find(".fragment").html();
$("#content-host").html(fragment);
});
}
}
$("a[data-role='ajax']").click(function (e) {
e.preventDefault();
window.location.hash = "!/" + $(this).attr("href");
});
$(window).on("hashchange", function () {
navigateToPage();
});
navigateToPage();
});
Listing 2: Home Page
<!doctype html>
<html>
<head>
<link rel="stylesheet" href="global.css" />
</head>
<body>
<h1>Home</h1>
<ul>
<li><a href="home.html" data-role="ajax">Home</a></li>
<li><a href="page1.html" data-role=
"ajax">Page 1</a></li>
<li><a href="page2.html" data-role=
"ajax">Page 2</a></li>
</ul>
<div id="content-host" class="fragment">
<h2>Home Page Content</h2>
<p>This is the home page of the application</p>
</div>
<script src="//<a href="http://www.modernizr.com/downloads/modernizr-">www.modernizr.com/downloads/modernizr-</a>
latest.js" type ="text/javascript"></script>
<script src="//<a href="http://ajax.googleapis.com/ajax/libs/jquery/1.8.2/">ajax.googleapis.com/ajax/libs/jquery/1.8.2/</a>
<a href="http://jquery.min.js">jquery.min.js</a>"></script>
<script src="script.js"></script>
</body>
</html>
Listing 3: Content Page (Page1.html)
<!doctype html>
<html>
<head>
<title>Page One</title>
<link rel="stylesheet" href="global.css" />
</head>
<body>
<h1>Page One</h1>
<ul>
<li><a href="home.html" data-role="ajax">Home</a></li>
<li><a href="page1.html" data-role=
"ajax">Page 1</a></li>
<li><a href="page2.html" data-role=
"ajax">Page 2</a></li>
</ul>
<div id="content-host" class="fragment">
<h2>Page One Content</h2>
<p>This is page one.</p>
</div>
<script src="//<a href="http://www.modernizr.com/downloads/modernizr-">www.modernizr.com/downloads/modernizr-</a>
latest.js" type ="text/javascript"></script>
<script src="//<a href="http://ajax.googleapis.com/ajax/libs/jquery/1.8.2/">ajax.googleapis.com/ajax/libs/jquery/1.8.2/</a>
<a href="http://jquery.min.js">jquery.min.js</a>"></script>
<script src="script.js"></script>
</body>
</html>
Listing 4: Content Page (Page2.html)
<!doctype html>
<html>
<head>
<title>Page Two</title>
<link rel="stylesheet" href="global.css" />
</head>
<body>
<h1>Page Two</h1>
<ul>
<li><a href="home.html" data-role="ajax">Home</a></li>
<li><a href="page1.html" data-role=
"ajax">Page 1</a></li>
<li><a href="page2.html" data-role=
"ajax">Page 2</a></li>
</ul>
<div id="content-host" class="fragment">
<h2>Page Two Content</h2>
<p>This is page two.</p>
</div>
<script src="//<a href="http://www.modernizr.com/downloads/modernizr-">www.modernizr.com/downloads/modernizr-</a>
latest.js" type ="text/javascript"></script>
<script src="//<a href="http://ajax.googleapis.com/ajax/libs/jquery/1.8.2/">ajax.googleapis.com/ajax/libs/jquery/1.8.2/</a>
<a href="http://jquery.min.js">jquery.min.js</a>"></script>
<script src="script.js"></script>
</body>
</html>
Listing 5: CSS (global.css)
body
{
margin-left:2em;
margin-top:2em;
font-family:Arial, Helvetica, sans-serif;
}
.fragment
{
-webkit-border-radius: 10px;
-moz-border-radius: 10px;
border-radius: 10px;
background-color:#eee;
border:1px solid #ccc;
padding:10px;
width:300px;
}
.fragment h2
{
margin-top:0px;
}
Listing 6: History API script (script.js)
$(function () {
function getPageName() {
var
pathName = window.location.pathname,
pageName = "";
if (pathName.indexOf("/") != -1) {
pageName = pathName.split("/").pop();
} else {
pageName = pathName;
}
return pageName;
}
function navigateToPage() {
var pageName = getPageName();
$.get(pageName, function (response) {
var
// Wrap the resulting HTML string with a parent node
// so jQuery can properly select against it.
markup = $("<div>" + response + "</div>"),
// Extract the fragment out of the markup.
fragment = markup.find(".fragment").html();
$("#content-host").html(fragment);
});
}
$("a[data-role='ajax']").click(function (e) {
if (Modernizr.history) {
e.preventDefault();
var pageName = $(this).attr("href");
window.history.pushState(null, "", pageName);
navigateToPage();
}
});
// Chrome & Safari (WebKit browsers) raise the popstate
// event when the page loads. All other browsers only
// raise this event when the forward or back buttons are
// clicked. Therefore, the '_popStateEventCount'
// (in conjunction with '$.browser.webkit') allows the page
// to skip running the contents of popstate event handler
// during page load so the content is not loaded twice in
// WebKit browsers.
var _popStateEventCount = 0;
// This event only fires in browsers that implement
// the HTML5 History APIs.
//
// IMPORTANT: The use of single quotes here is required
// for full browser support.
//
// Ex: Safari will not fire the event
// if you use: $(window).on("popstate"
$(window).on('popstate', function (e) {
this._popStateEventCount++;
if ($.browser.webkit && this._popStateEventCount == 1) {
return;
}
// The 'e.originalEvent.state' property gives
// you access to the state argument passed into
// the 'pushState' function, but browser support
// is inconsistent (Safari). Normally you might
// pass in the destination page name using the
// state object to the event arguments here, but
// since support is unreliable, this demo
// extracts the current page from the
// 'window.location' value.
navigateToPage();
});
});
