


Thanks to the growing popularity of voice-enabled home assistant devices like Amazon Echo and Google Home, more attention is being paid to voice-enabling every day applications and devices. But voice technology is nothing new. Speech Synthesis Markup Language (SSML) has actually been around for quite some time.
What is SSML?
Speech Synthesis Markup Language (SSML) is an XML-based markup language, used in the generation of speech in a range of applications, including Windows, mobile, Web, and Internet of Things (IoT) devices. SSML gives developers and content creators the ability to not only generate speech, but also control the finer aspects, such as pronunciation, inflection, pitch, and more. This is also known as “prosody,” and I'll get to that in just a moment.
Prosody
Prosody (from the Latin prosidia) refers to the patterns of stress and intonation in a language. In the context of SSML, prosody is an element with six optional attributes: pitch, contour, range, rate, duration, and volume. Not all implementations of SSML include support for all attributes; for example, Amazon's Alexa Voice Service only supports the rate, pitch, and volume attributes, so I'll go into those in more detail below.
The rate attribute controls the speed of speech, and can contain one of the following five predefined values: x-slow, slow, medium, fast, and x-fast.
<speak>
<prosody rate="x-slow">Sometimes I speak very very slowly</prosody>.
I can also speak normally, and sometimes
<prosody rate="x-fast">I also speak very very quickly</prosody>.
</speak>
You can also use a percentage value. Anything below 100% slows down the speech, and values above 100% speed it up. Anything outside of the prosody tags automatically reverts to normal speech, but you can always specify the default rate as well, for clarity.
<speak>
<prosody rate="50%">This is slow</prosody>
<prosody rate="100%">and</prosody>
<prosody rate="150%">this is fast</prosody>.
</speak>
The pitch attribute raises or lowers the tone of the speech. Much like the rate attribute, you have five predefined values: x-low, low, medium, high, and x-high. You can also use a percentage value (ranging from -33.3% up to +50%) for more precise control.
<speak>
<prosody pitch="+50%">This is high</prosody>
and
<prosody pitch="-33.3%">this is low</prosody>.
</speak>
Finally, the volume attribute controls (surprise!) the volume of the speech. This time, you have six predefined values: silent, x-soft, soft, medium, loud, and x-loud. You can also provide a positive or negative amount to increase (or decrease) the relative volume. That last part is important. You aren't assigning a fixed volume, but changing it relative to the current volume. For more info on decibels (dB) as a comparative unit of measure, be sure to check out this Wikipedia article: https://en.wikipedia.org/wiki/Decibel.
<speak>
<prosody volume="x-soft">A whisper.</prosody>
<prosody volume="x-loud">I'm loud.</prosody>
<prosody volume="-6dB">Half as loud.</prosody>
</speak>
In addition to Prosody, SSML relies on the phoneme element to handle the articulation of the vowel and consonant sounds in spoken language.
Because these are all attributes of the <prosody> tag, they can be combined to produce some interesting effects.
<speak>
<prosody rate="150%"
pitch="+50%"
volume="x-soft">
A fast, high pitched whisper!
</prosody>
</speak>
Phonemes
A phoneme (from the French word phonème) is the smallest unit of speech, and distinguishes one sound from another within a language. The number of phonemes varies by language, usually ranging from 20 to around 60, and is considered to be the building block of all spoken languages. Sign language has phonemes too, but in the form of gestures, rather than utterances.
Example: The words hat, rat, cat, sat, fat and bat begin with the letters h, r, c, s, f, and b respectively, each of which is a consonant, and also represent a unique phoneme in the English language. Phonemes can also be represented by more than one letter, such as the ch sound in chair, or the ph in phone.
In the context of SSML, a phoneme is an element with two attributes: alphabet (optional) and ph (required).
The alphabet attribute specifies a dictionary of symbols that represent sounds. You can specify IPA, which stands for the International Phonetic Alphabet. You can also specify a vendor-specific dictionary, in the event that you're providing speech support on custom hardware. For Amazon's Alexa, you can also use x-sampa which is the Extended Speech Assessment Methods Phonetic Alphabet.
The ph attribute specifies a string containing phonemes to provide a pronunciation key for words and short phrases.
For example, the following snippet shows the phonetic pronunciation for tomato.
<speak>
<phoneme alphabet="ipa" ph="to? 'me? to?">
tomato
</phoneme>
</speak>
Here's a differing pronunciation of the same word.
<speak>
<phoneme alphabet="ipa" ph=="to? 'm? to?">
tomato
</phoneme>
</speak>
Most of the symbols aren't very intuitive by themselves, but there's a great reference available online provided by internationalphoneticalphabet.org. This chart shows each symbol in the IPA alphabet, how the sound is made, and plays the sound if you click on the symbol: https://www.internationalphoneticalphabet.org/ipa-sounds/ipa-chart-with-sounds/.
Keep in mind that these tags aren't mutually exclusive. To build on the previous example, you can nest <phoneme> tags inside your <prosody> tags, giving you significant control over the pronunciation of your text.
<speak>
<prosody rate="150%"
pitch="+50%"
volume="x-soft">
<phoneme alphabet="ipa" ph="to? 'me? to?">
A fast, high pitched, whispered tomato.
</phoneme>
</prosody>
</speak>
Most of the symbols aren't very intuitive, but
internationalphoneticalphabet.orgprovides a great reference available online.
Breaks and Emphasis
In speaking, when you REALLY need to make a point, you can inject a pause for dramatic effect, or emphasize a specific word. This is accomplished by the break and emphasis elements, respectively.
The break element can take a strength attribute or a time attribute. The strength attribute can accept values of none, weak, strong, and x-strong. Weak is roughly equivalent to the pause you would make after a comma, and strong and x-strong represent sentence and paragraph breaks.
<speak>
This <break time="200ms"/> is known as
<break time="2s"/> the Shatner pause.
This <break strength="weak"/> is a comma length pause
followed by a <break strength="x-strong"/>paragraph pause.
</speak>
The emphasis element supports a level attribute with three values: strong, moderate, and reduced. Greater emphasis has the effect of increasing the volume and slowing the rate of the speech.
<speak>
I <emphasis level="strong">really</emphasis>
Like pepperoni on my pizza.
</speak>
Interpreting Text with Say-As
The last element I'll introduce here is incredibly useful: the say-as tag. This gives direction to the speech parser on how it should interpret your text. It's supported by two attributes: interpret-as and the date specific format.
The interpret-as attribute supports a broad set of options, including but not limited to the following:
- spell-out: spells out each letter of the word
- digits: speaks each digit of a number separately
- date: treats the value as a date, can be formatted with the format attribute
- telephone: speaks 7 or 10 digit values as a telephone number
- expletive: replaces the text within the
say-astag with a “bleep”
The format attribute converts text to a date based on the following options: mdy (month, day, year), dmy, ymd, or any combination of the three (such as md, ym, y, d, etc.).
Testing and Implementation
If you want to test the SSML markup in this article, you have (at least) four options currently: the SSML Markup Tester, the Amazon Alexa Skills Kit Voice Simulator, Amazon Polly, and of course good old C# .NET. In this section, I'll show you three tools to test your SSML and then finish up with a small project that shows you how to implement (and test) it in .NET.
ETS SSML Markup Tester
This one is located at http://bit.ly/2r3ET2D. It's pretty simple, although I've found that it does occasionally get confused after using it a lot in one session. To use it, paste your snippet in the textbox at the top, and click the Speak button at the bottom, as shown in Figure 1. It's free, and doesn't require any additional sign up for configuration, but it can be a little buggy.
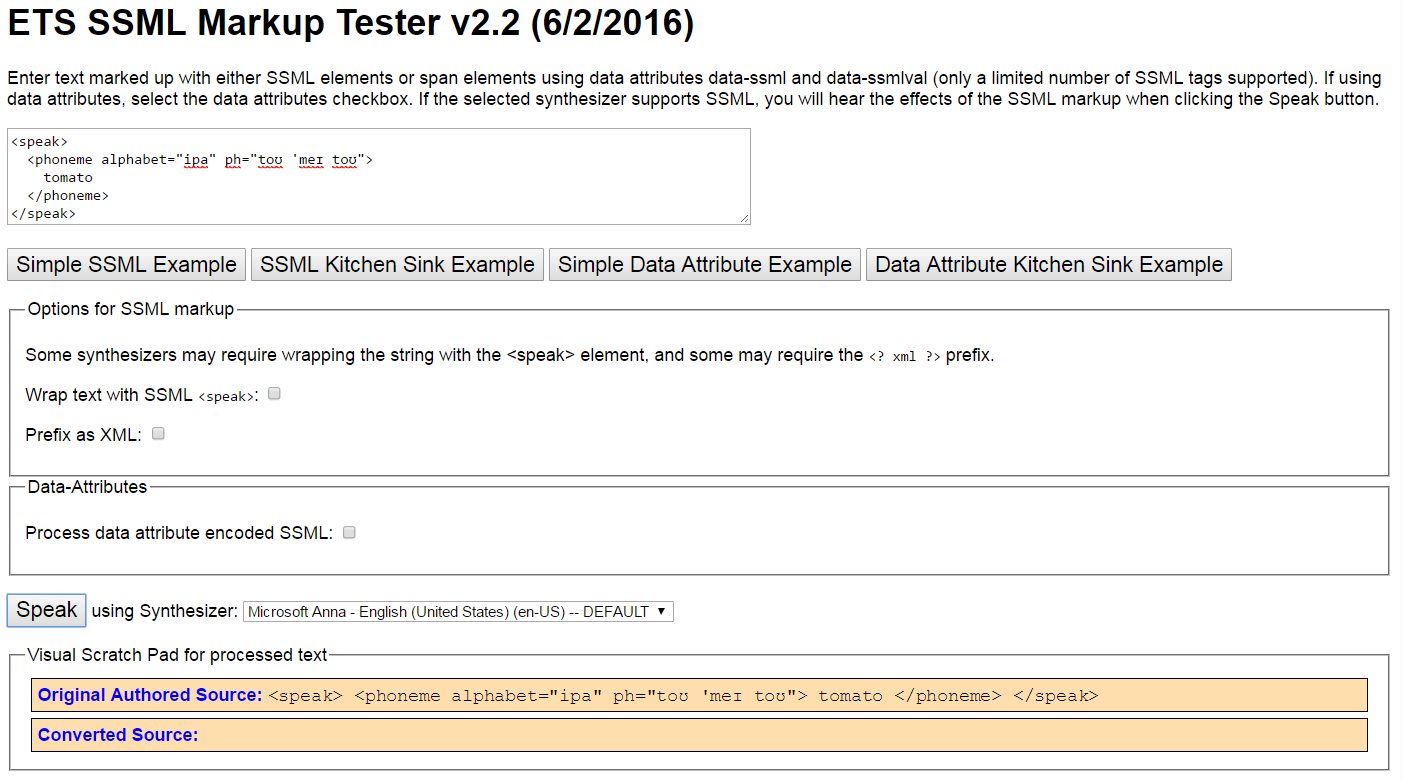
If you're pasting in a complete snippet with <speak> tags, you don't need to select anything else, but if you're only pasting the phonetic symbols, be sure to check the Wrap text with SSML
Amazon Alexa Skills Kit Voice Simulator
The second option, which is especially appealing if you're developing for Alexa, is the Amazon Alexa Skills Kit Voice Simulator. Getting to this one is a bit more complicated, and because it's only available as part of the skill submission process (see Figure 2), I can't link to it directly.
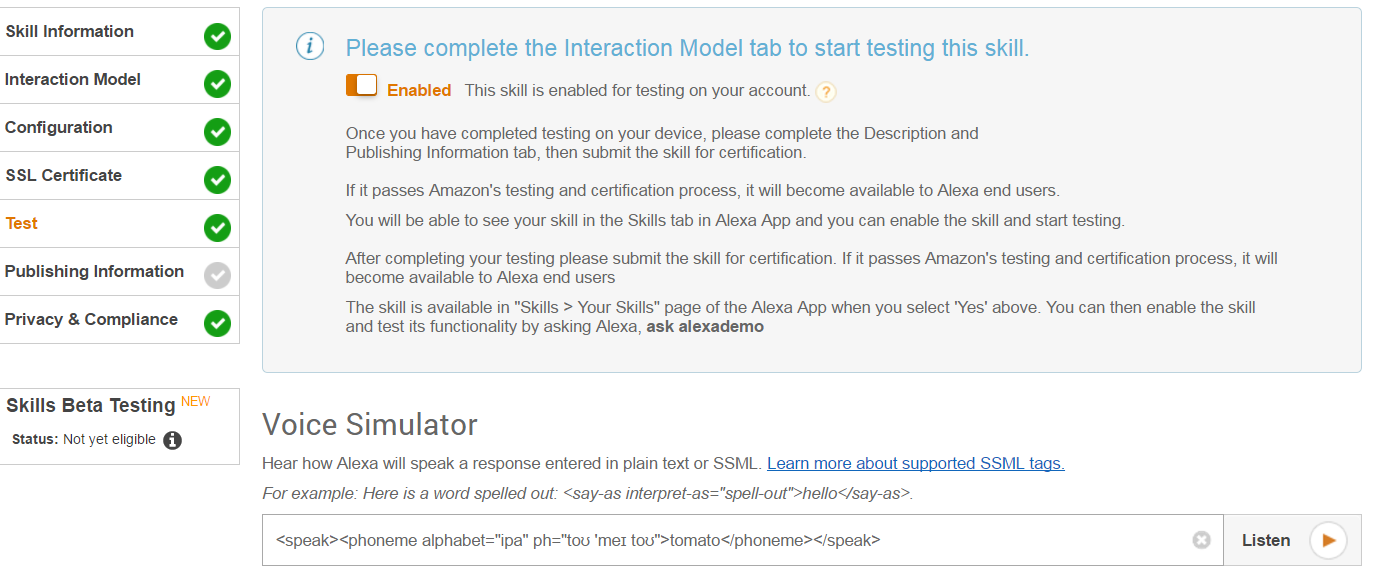
Fortunately for you, I've written a comprehensive guide to developing Alexa Skills, which was in the Mar/Apr 2017 issue of this magazine. If you don't have a print edition handy, you can also find it online at http://bit.ly/2qUNeIR.
You can paste your SSML markup directly into the Voice Simulator textbox and click the Listen button. There aren't any dialect or configuration options, and it's only spoken in Alexa's voice, but if you're developing an Alexa Skill, it's the way to go.
Amazon Polly
Amazon Polly is available at https://console.aws.amazon.com/polly/. It's free, but requires you to create an Amazon AWS account (also free) if you don't already have one. Once you're signed in, you'll be presented with a variety of voices and languages to choose from (as shown in Figure 3.)
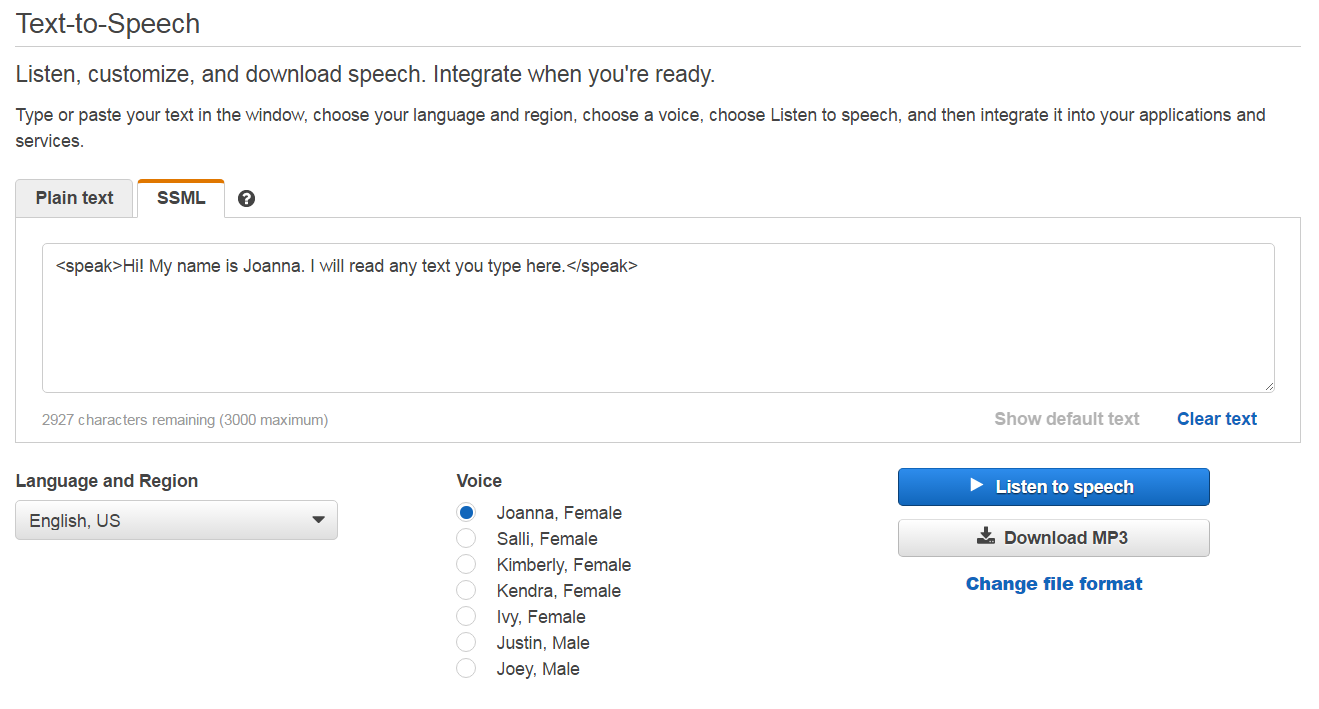
A cool feature of Amazon Polly is that it can also take your SSML content and generate MP3 files for you to download and use elsewhere.
If you're primarily interested in voice-enabling your .NET applications, the next section will be the most appealing to you.
A cool feature of Amazon Polly is that it can take your SSML content and generate MP3 audio files for you to download and use elsewhere.
Using SSML in Your .NET Applications
Last, but certainly not least, you can always incorporate SSML directly into your .NET applications, thanks to the System.Speech.Synthesis namespace. Much like the online tools, you'll use the IPA alphabet and the full range of supported tags you've just learned.
To illustrate how this works, I'll build a simple Console Application that reads a string of SSML and speaks it aloud.
Fire up Visual Studio (any version) and create a Console Application. I named mine SpeechTest.
Once you have your console application loaded, right-click on references in the Solution Explorer window and click Add reference. Check the box next to System.Speech and hit the OK button.
Add the following line at the top, to take advantage of the reference you just added:
using System.Speech.Synthesis;
Add the following code inside the Main() method:
using (var synth = new SpeechSynthesizer())
{
// Configure the audio output.
synth.SetOutputToDefaultAudioDevice();
var text = new PromptBuilder();
text.AppendSsmlMarkup("<say-as interpret-as = \"characters\"> Hello World! </say-as>");
synth.Speak(text);
}
Hit F5 and run your new speech-enabled application!
Feel free to experiment with the various tags covered in this article, as they're all part of the SSML standard. For more information on specific .NET implementation and the Speech.Synthesis namespace, be sure to take a look at the Microsoft documentation, which you can find here: http://bit.ly/2qhtUT6.
That's it for this issue. Thanks for reading!
