


Microsoft released Entity Framework, an ORM (Object Relational Mapping) tool, in 2008.
Entity Framework gives developers the ability to be abstracted from the underlying relational database management system and allows them to talk to a database using familiar LINQ-based syntax.
Entity Framework therefore simplifies the development process and greatly aids in improving productivity while working with a database. Entity Framework does so via a model that serves as a database abstraction. However, this technology is not database agnostic. As a result, if an application needs to be compatible with multiple databases, you have two choices. You could have multiple models, thus duplicating your efforts with each supported RDBMS (Relational Database Management System). Alternatively, you can use single model by deploying a technique that allows you to switch database support during deployment based on your target database. This article will show you how to use both techniques, thus making Entity Framework-based data access layer code database agnostic.
Deep Look into Entity Framework Model Structure
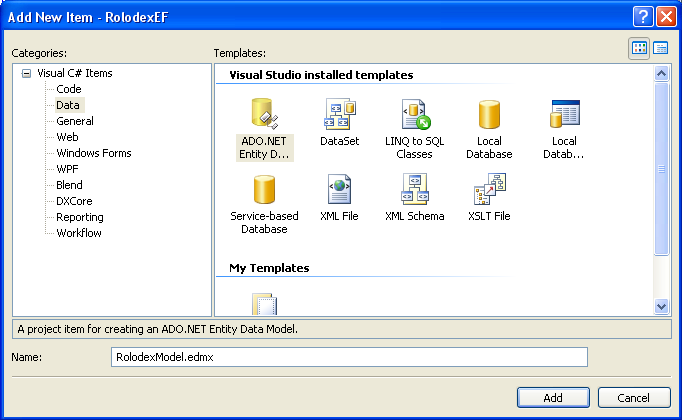
In order to be able to fully understand why Entity Framework is not database agnostic technology and how to make it such, a deep look into the workings of this ORM (Object Relational Mapping) tool is required. I’ll start by building a new model against a sample database that I’ll use in this article to demonstrate various concepts. First I will create a new project using Visual Studio 2008 SP1 and add a new item, specifying ADO.NET Entity Framework Model (Figure 1) as item type. In the next screen of the Add New Item wizard I choose to generate my model from a database. Then I’ll create a new connection, pointing it to the sample database (EFArticle). I will select all the tables from the database to include in the model. Next, I will complete the wizard and then build the project with all default settings. Notice that the wizard adds an app.config file to the project. It contains the connection string to connect to the database. You should understand the structure of this string:
<configuration>
<connectionStrings>
<add name="RolodexEntities"
connectionString ="metadata=
res://*/RolodexModel.csdl|
res://*/RolodexModel.ssdl|
res://*/RolodexModel.msl;
provider=System.Data.SqlClient;
provider connection string= &quot;
Data Source=.\sql2008;
Initial Catalog=EFArticle;
Persist Security Info=True;
User ID=efarticleuser;
Password=password;
MultipleActiveResultSets=True
&quot;" providerName="System.Data.EntityClient" />
</connectionStrings>
</configuration>
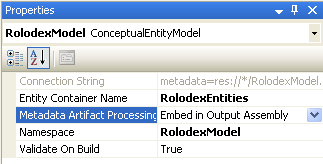
You can see the metadata specifications as part of the connection string. This metadata contains three main parts that make up an Entity Framework model. The first part is conceptual schema (the CSDL file). Entity Framework uses this schema to allow developers to construct .NET queries against an object-based model that this schema defines. In the second part of the metadata you can see the mapping schema (MSL file). Entity Framework uses the mapping schema to translate .NET queries information into database information, which is contained within the third part of the metadata called the storage schema (SSDL file). This part of an Entity Framework model contains information about the underlying RDBMS. You can take a closer look at all three parts by opening the model in an XML editor. To do so, just right-click on edmx (model) file in Solution Explorer, then choose Open With, then select XML Editor. All three schemas are compiled by default into a DLL of the project that contains the model. Each schema portion becomes a resource with the name that you can see as part of the connection string. For example, in the example for this article, the conceptual model will become a resource with the name of RolodexModel.csdl. The Entity Framework runtime will parse the connection string and retrieve appropriate information from an assembly. An alternative to embedded distribution of metadata (which will become important to you later) is to distribute each schema portion as a standalone file. You can switch to this behavior by opening a model in the default editor (ADO.NET Entity Data Model Designer) by double-clicking on the edmx file. Then you can right-click on the white space anywhere in the model design surface and choose Properties. The standard Properties window opens and will allow you can to choose the option to select different Metadata Artifact Processing - copy to output directory (Figure 2). If you choose this option, you will notice that the connection string will change accordingly.
Building an N-Tier Business Application that Interacts with Entity Framework
Next I want to show you how to build a sample application that uses Entity Framework as the data access layer. In my case, I will create two small applications - one in Silverlight, the other in WPF - to illustrate how to use Entity Framework to access the data. I will use the CSLA .NET framework (http://www.lhotka.net/cslalight/Default.aspx) to build my business layer that I will share between two applications. Because one cannot reach into a database from a Silverlight application, I will have a web application project (Rolodex.Silverlight.Web) that will contain a WCF service that my application will use to communicate with the database. CSLA .NET framework has a lot of plumbing already taken care of, so in my case I do not need to write any service code. I just need to define the service in a SVC file and include appropriate settings in the web.config file. If you take a look at the source code that is included with this article, you will find the Rolodex.Server project that contains my business classes that interact with Entity Framework. For example, Listing 1 shows how I am getting a list of companies from the Companies table inside the ReadOnlyCompanyList class.
If you are wondering what the ObjectContextManager class does, it is simply a convenience wrapper for Entity Framework’s ObjectContext class. Object Context itself is a representation of the underlying database and contains properties that represent each table in the database. Each table’s row is represented by a corresponding class that in turn contains properties that describe each column in the table. My ReadOnlyCompany class is a representation of a single row in the Companies table. What is important to notice here is the fact that I do not ever refer to the database itself or to the Entity Framework data provider anywhere in the code. It is very important to keep the program structure clean of low-level data access code. Low-level code, such as explicit calls to stored procedures, is not usually needed when you use Entity Framework anyway. The same is the case with all CRUD operations.
For example, Listing 2 shows how you can insert a new company. In this case, I simply create an instance of the Companies class, populate its properties, add it to the object context, then fire SaveChanges() to commit the new entity to the database.
Making Application Database Agnostic
You have to follow a few steps in order to achieve the goal of making the Entity Framework-based data access layer database agnostic. You have to identify what databases you would like to support, pick the provider or providers you want to use, and identify the process of creating many databases based on your primary development database. Then you can pick one of the two ways I describe in the article to implement in your application. I will now look into these steps in detail.
When Microsoft released Entity Framework, they went with a provider model to support multiple backend database solutions. Many companies have been working on implementing database-specific providers for many months. Now all major databases have Entity Framework compliant providers available.
Supported Databases
When Microsoft released Entity Framework, they went with a provider model to support multiple backend database solutions. Many companies have been working on implementing database-specific providers for many months. Now all major databases have Entity Framework compliant providers available. You can find an official list of them on the Microsoft website (http://msdn.microsoft.com/en-us/data/dd363565.aspx).
The first step in supporting multiple RDBMS is to narrow down your choices and pick a provider you would like to use. In my example, I already support SQL Server and I will add support for Oracle as well, concentrating my efforts on the two most popular RDBM systems. In order to do so, I will use DataDirect’s Oracle Entity Framework provider. In order to run the sample, you will also need to download and install a trial version of this provider here: http://www.datadirect.com/products/net/index.ssp.
The next step is to create an Oracle database with the same structure as the SQL Server database. You can do this in either of two ways. You can convert your SQL Server database to Oracle using any number of products that are designed to do just that. Alternatively, you can just define an Oracle database manually. A number of tools exist to accomplish the conversion task. I used SQLWays (http://www.ispirer.com/download/) for my demo. One thing to keep in mind is consistency between names in both databases. In order to keep consistent names in Oracle, I have to use quoted identifiers thus forcing Oracle not to uppercase all my table and column names, which is the default behavior. In my case, I also set up a login with a password that matches my SQL Server database as a convenience. In addition to that, I also put all tables into the schema for a new user (EFArticleUser with a password of “password”). Of course, you will have to have the Oracle database installed somewhere. You can always use the free Express edition of Oracle. You can download it here: http://www.oracle.com/technology/products/database/xe/index.html).
Once you complete the steps above, you are ready to start on the Entity Framework portion.
Supporting Oracle Database in a Sample Application
You can enable multiple RDBMS support in one of two ways without any code changes in the sample application.
I will examine how to do both.
There are two main ways that you can enable multiple RDBMS support without any code changes in an application:
- Swap out the DLL that contains the Entity Framework model.
- Alter the model at run time.
Swap Out the DLL that Contains Entity Framework
As I discussed previously, the keys to Entity Framework’s inner workings are schemas. If you open the designer file (RolodexModel.Designer.cs in my case) you will see that the code in that file is pretty generic and is generated when you save the model file. However, if you open the edmx file using XML editor, you will find one portion that will vary from database to database. Specifically, its storage schema or SSDL file. Now, what I need to do is replace the entire model in my application without having to modify any code in my business classes. To do so, I simply follow a few simple steps:
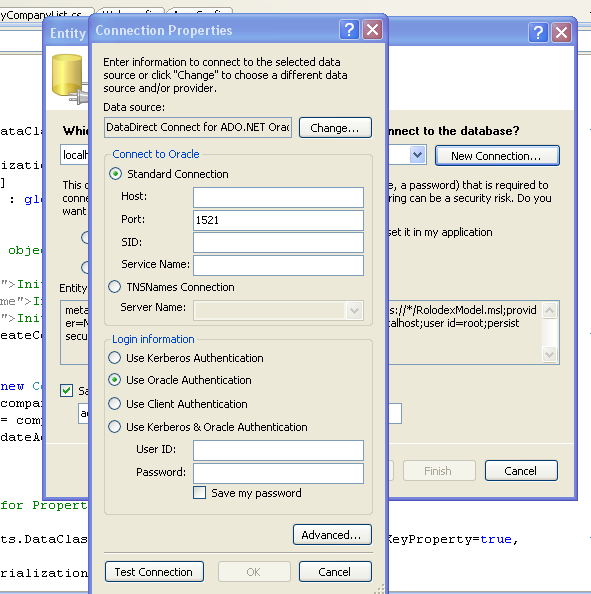
First, I will create a new model. I will start with a brand new class library project (RolodexEF.Oracle). Then, before I add the actual entity framework model, I must change namespace (and DLL name while I am at it) in order to ensure that all generated code will be the same in both SQL Server-based (RolodexEF) and Oracle-based (RolodexEF.Oracle) projects. This is a very important step because if I do not do this, my business layer code will not compile against the Oracle model. Next, I will create the actual model following mostly the same steps as I described above. There is one change I need to make, and that is to create a new connection using the DataDirect’s Oracle provider (Figure 3). Another thing to keep in mind here is the fact that you must use the same name for the model itself as well as its entities (object context). In my case I use RolodexModel and RolodexEntities respectively. Again, I select all the tables and save the model once it is completed.
The next step is to test the new model. In order to do this I will remove the reference to the project that contains SQL Server-based Entity Framework model (RolodexEF) from the project that contains business classes (Rolodex.Server) and instead add a reference to the new Oracle Entity Framework project (RolodexEF.Oracle). My solution should still build. In order to run it, I need to replace the SQL Server connection string with the Oracle-based string in web.config in the Rolodex.Silverlight.Web project. I can find this string in app.config in RolodexEF.Oracle project.
Now I am ready to run the application. In order to do the same at the install time, you have to have your website installer drop in the appropriate DLL and update the connection string.
Alter Entity Framework Model at Runtime
An idea to update the model at run time came to me during my work on a Silverlight project. One of the requirements was to support SQL Server and Oracle with Entity Framework without code changes. During the research phase it became obvious that the fact that Entity Framework embeds the storage schema file (SSLD file) is what causes the Entity Framework schema to be database specific. So, how can I get around this issue? I am going to replace the storage schema at runtime with the schema that matches the RDBMS I am running against.
In order to minimize the effort to accomplish this task, I am going to write a converter helper executable that will do this work for me. I will create a small console application called EntityFrameworkSSDLUpdater that is also included in the source code for the article. You can see the source code in Listing 3.
Note: lines of code that contain the Provider and ProviderManifestToken were split into multiple lines for formatting purposes only. They should be on a single line to match the SSDL file layout.
As you can see, altering of schema is a simple “search and replace” process. It results in swapping types that Entity Framework provider for SQL Server expects with types that DataDirect Oracle provider expects. I did not list code for every possible type, but you can see that there is not a whole lot of effort involved in supporting all types.
My converter performs the following steps:
- It searches a specified DLL (second parameter to the console application).
- It extracts out all SSDL files into a folder (first parameter to the console application).
- It alters SSDL files to satisfy the Oracle provider expected requirements.
Now the next step is to update web.config. I simply change the references to storage schema (SSDL) files with full path to SSDL file that my converter created as well as update the provider connection string:
<configuration>
<connectionStrings>
<add name="RolodexEntities"
connectionString ="metadata=
res://*/RolodexModel.csdl|
C:\RolodexModel.ssdl|
res://*/RolodexModel.msl;provider=DDTek.Oracle;
provider connection string= &quot;
Host=localhost;
Password=password;
Persist Security Info=True;
Service Name=xe;
User ID=efarticleuser
&quot;"
providerName ="System.Data.EntityClient" />
</connectionStrings>
</configuration>
Again, I manually perform the task that an installer should perform. An installer would also include all required SSDL files that will be generated by a build process during development off based on the SQL Server model. At this point I need to change the reference to the Entity Framework model project back to the SQL Server version of it (RolodexEF). Now I can run my application. I can use the SQL Server-based model to run against Oracle by swapping out the storage schema at deployment time.
Multiple DLLs versus Schema Updates
In my opinion, both methods are totally valid and achieve the same end result - my application can be run on Oracle and SQL Server without any code changes. I’d say that the method that involves altering storage schema is easier because I do not have to maintain two DLLs and two schemas. However, if my application has only a single model that includes all the tables in the database and no customizations, then maintaining two DLLs is probably easier/ less error prone. However, ifIf I have a dozen models (I have seen recommendations to keep the number of tables in a single model to fewer than 100-130 or so) with customizations, such as custom entities, the method that involves altering the schema will reduce development overhead. No matter which method you choose, you cannot reduce testing efforts during the development phase with regard to support of multiple database engines. However, if you have integration tests written, you can run them against both databases during the development process, thus assuring that your code actually works the same against Oracle and SQL Server. The same build process can also convert the test database from SQL Server to Oracle and prepare everything that is needed for integration testing. The same process would also be employed in the QA department.
Important Consideration
There is one very important aspect you must consider in advance when you think you want to have Entity Framework function against multiple databases. You must keep your databases compliant with each other. For example, SQL Server supports identifiers that can be 128 characters long, where as Oracle only supports identifiers that are 30 characters long. On the same note, SQL Server Identity columns are not natively supported in Oracle. You can use a combination of triggers and sequences, but your provider must support this functionality. Also, Oracle does not have the GUID data type, so in my example I used char(36) columns to simulate GUID-based design.
Conclusion
I demonstrated how to create a database-agnostic application using Entity Framework. As you can see, you need invest some effort into this task, but the amount of this effort is not insurmountable by any means. In an ideal world, this work would be handled by the Entity Framework itself. In other words, storage schema would not be built into the model, but could be either discoverable at run time or easily updatable at design time. It would be nice if the right-click menu in the model designer would contain an item called “Add RDBMS/Provider”.
In the mean time, you can choose one of the two options that best suits your needs.
Listing 1: Populate list of Companies
using (ObjectContextManager<RolodexEntities> manager =
ObjectContextManager<RolodexEF.RolodexEntities>
.GetManager(DataConnection.EFConnectionName, true))
{
foreach (var item in (from oneCompany in
manager.ObjectContext.Companies
orderby oneCompany.CompanyName
select
new { oneCompany.CompanyId,
oneCompany.CompanyName }))
{
Add(ReadOnlyCompany.GetReadOnlyCompany(item.CompanyId,
item.CompanyName));
}
}
Listing 2: Create new Company
using (ObjectContextManager<RolodexEntities> manager =
ObjectContextManager<RolodexEF.RolodexEntities>
.GetManager(DataConnection.EFConnectionName, true))
{
Companies newCompany = new Companies();
newCompany.CompanyId = ReadProperty(CompanyIdProperty);
newCompany.CompanyName = ReadProperty(CompanyNameProperty);
SmartDate added = ReadProperty(DateAddedProperty);
if (!added.IsEmpty)
newCompany.DateAdded = added.Date;
manager.ObjectContext.AddToCompanies(newCompany);
DataPortal.UpdateChild(
ReadProperty(ContactsProperty),
this,
newCompany);
manager.ObjectContext.SaveChanges();
}
Listing 3: SSDL file updater
class Program
{
static void Main(string[] args)
{
if (args.Length > 0)
{
string folder = args.First();
string dll = string.Empty;
if (System.IO.Directory.Exists(folder))
{
DirectoryInfo info = new DirectoryInfo(folder);
if (args.Length > 1)
{
dll = args[1];
Assembly assembly = Assembly.LoadFile(dll);
string[] resources =
assembly.GetManifestResourceNames();
string content = string.Empty;
foreach (var item in resources)
{
if (item.ToUpper().EndsWith("SSDL"))
{
using (Stream itemStream =
assembly.
GetManifestResourceStream(item))
{
using (StreamReader reader =
new StreamReader(itemStream))
{
content = reader.ReadToEnd();
reader.Close();
}
itemStream.Close();
}
File.WriteAllText(
string.Concat(info.FullName,
@"\",
item), content);
}
}
}
FileInfo[] files = info.GetFiles("*.ssdl",
System.IO.SearchOption.TopDirectoryOnly);
if (files != null &&
files.Length > 0 &&
files[0] != null)
{
foreach (var item in files)
{
string content = File
.ReadAllText(item.FullName);
content = content
.Replace(@"Schema=""dbo""",
@"Schema=""EFARTICLEUSER""")
.Replace(
@"Provider=""System.Data.SqlClient""
ProviderManifestToken=""2008""",
@"Provider=""DDTek.Oracle""
ProviderManifestToken=""10g""")
.Replace(@"Type=""money""",
@"Type=""number"" Precision=""19""
Scale=""4""")
.Replace(@"Type=""numeric""",
@"Type=""number""")
.Replace(@"Type=""nvarchar(max)""",
@"Type=""nclob""")
.Replace(@"Type=""decimal""",
@"Type=""number""")
.Replace(@"Type=""int""",
@"Type=""number"" Precision=""10""")
.Replace(@"Type=""smallint""",
@"Type=""number"" Precision=""5""")
.Replace(@"Type=""varchar(max)""",
@"Type=""clob""")
.Replace(@"Type=""varchar""",
@"Type=""varchar2""")
.Replace(@"Type=""datetime""",
@"Type=""date""")
.Replace(@"Type=""varbinary(max)""",
@"Type=""blob""")
.Replace(@"Type=""bit""",
@"Type=""number"" Precision=""1""")
.Replace(@"Type=""nvarchar""",
@"Type=""nvarchar2""");
File.WriteAllText(item.FullName, content);
}
}
}
else
{
Console.WriteLine("Target folder is invalid");
}
}
else
{
Console.WriteLine(@"Target folder is required
as command line parameter");
}
}
}
