





Most professional software developers understand the academic definitions of coupling, cohesion, and encapsulation. However, many developers do not understand how to achieve the benefits of low coupling, high cohesion and strong encapsulation, as outlined in this article. Fortunately, others have created stepping stones that lead to these goals,
resulting in software that is easier to read, easier to understand and easier to change. In this article series, I will define three of the primary object-oriented principles and show how to reach them through the five S.O.L.I.D. design principles.
Have you ever played Jenga? It’s that game of wooden blocks that are stacked on top of each other in rows of three. In Jenga you try to push or pull a block out of the stack and place it on top of the stack without knocking the stack over. The player that causes the stack to fall loses.
Have you ever thought you were playing a game of Jenga when you were writing or debugging software? For example, you may need to change one field on one screen. You study the stack of code, you look for that little space of light peaking between the classes, and you make the change in the one place that you thought would be safe. Unfortunately, you didn’t realize that the code you were changing was referenced in several critical processes through some strange levels of indirection. The resulting crash of the software stack has left you the loser, cleaning up the mess with your boss breathing down your neck about the customer being upset about their lost data, and … How many times have you been there? I can’t even begin to count how often it’s happened to me.
Software development does not have to be like a game of Jenga.
There is good news, though: software development does not have to be like a game of Jenga. In fact, software development should not be like any game where there are winners and losers. What you want, instead, is a sustainable pace of software development where everyone wins. You want to ensure that you don’t overwork the developers, that you don’t pressure managers to say “just get it done,” and the customer gets the software they want in a timeframe they agree to.
A Sustainable Pace
When trying to set a sustainable pace in any endeavor, you first need to understand how far you need to go. You also need to know how fast you need to get there. For example, if you want to run a 50-meter dash, you should run as fast as you possibly can and then push yourself to try to run faster. However, if you want to run an 800-meter race you should set a somewhat slower pace. When you start talking about significant distances like a marathon, the pace becomes significantly slower. For such a distance, you want to set a pace that you can maintain throughout the race.
In software development, you can think of the pace you need to run as the timeline of the project combined with the expected features and functionality.
In software development, you can think of the pace you need to run as the timeline of the project combined with the expected features and functionality. For shorter timeframes, you need to run faster. However, you also have to consider how much functionality you can reasonably add to your system, given a short timeframe. If you only need a few features and you need to get it done quickly, you may need to sprint toward the goal. If your customer expects you to cram too many features into a short timeframe, you have a higher likelihood of burning out. Imagine trying to sprint for the duration of a marathon, or even a 1600-meter race. The probability of sustaining that pace for that distance is going to approach zero as you continue moving forward. You need to work with your management, your team, and your customers to set the expectations of how fast you can run for a given period.
Assuming that you have a reasonable number of features for a given timeframe, you now have to set the pace for feature development in your daily activities. Object-oriented software development has various principles, patterns and practices that help you achieve the sustainable pace you need. The principles include coupling-the extent to which the parts of the system rely on each other; cohesion-the extent to which the parts of a system work together for a single purpose; and encapsulation-the extent to which the details of implementation are hidden. Built on top of these principles are various design and implementation patterns such as strategy, command, bridge, etc. When you combine these principles, patterns and practices they will help you to create systems that are well factored, easy to understand, and easy to change.
The Object-Oriented Principles
Ideally, you want to ensure that your systems have low coupling and high cohesion. These two principles help you to create the building blocks of a software system. You also want to ensure that you have self-contained building blocks-that is, they are well encapsulated. You don’t want the concerns of one building block leaking into other blocks. If you create building blocks that have the correct size and shape, you can put them together in meaningful ways to solve your problems.
Often it seems that developers only discuss these principles in academic settings. Most universities with degrees that cover software development provide at least a cursory introduction to them. However, many software developers seem to miss their correct usage, causing more problems than they solve. Indeed, developers can very easily misapply these principles in the wrong place at the wrong time. To avoid this situation, you need to understand how coupling, cohesion, and encapsulation correctly play into developing software solutions.
Low Coupling
Coupling in software development is defined as the degree to which a module, class, or other construct, is tied directly to others. For example, the degree of coupling between two classes can be seen as how dependent one class is on the other. If a class is very tightly coupled (or, has high coupling) to one or more classes, then you must use all of the classes that are coupled when you want to use only one of them.
You can reduce coupling by defining standard connections or interfaces between two pieces of a system. For example, a key and a lock have a defined interface between them. The key has a certain pattern of ridges and valleys, and the lock has a certain pattern of pins and springs. When you place the right key in the lock, it pushes the pins into a position that allows the mechanism to lock or unlock. If you place the wrong key into the lock, the pins will not move into the correct position and the mechanism won’t move.
In software development, developers also work with standard connections and interface definitions. Object-oriented languages such as C++, C#, Java, and Visual Basic have some constructs that allow you to define those interfaces implicitly and explicitly. Whether it’s a class’ public methods and properties, an abstract base class, an explicit interface or other form of abstraction, these constructs allow you to define common interaction points between parts of your system. Without abstraction to decouple these common points of interaction, you are left with pieces of the system that must know about each other directly. Basically, this means you are stuck with a key that is welded directly to the pins of a lock, preventing you from removing the key, and compromising the security of that lock.
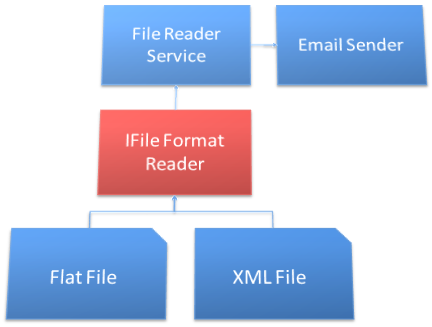
Imagine that you are working with the structure in Figure 1. The software works fine, at the moment, and you can fix bugs when you need to. Then your boss hands you a new requirement and you realize that the module highlighted in red can handle most of the requirement. You would like to reuse that module but you don’t need any of the surrounding modules for this new feature. When you try to pull out the module in red, though, you quickly realize that you’ll have to bring several more modules with it due to the high coupling between this module and the ones surrounding it.
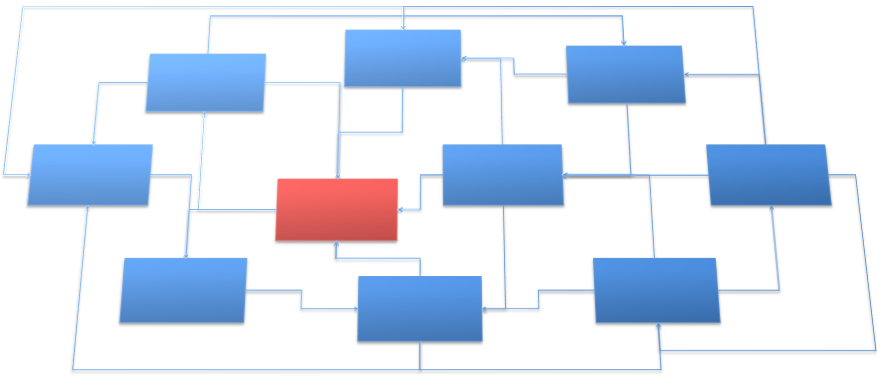
Now imagine a class that has zero coupling. That is, the class depends on nothing else and nothing else depends on it. What benefit does that offer? For one, you can use that class anywhere you want without having to worry about dependencies coming along with it. However, you essentially have a useless class. With zero coupling in the class, you won’t be able to get any information into or out of it. Try to create a class in .NET that does not rely on anything-not an integer, not a string, not a Console or Application static reference; not even the implied object inheritance of every construct in .NET. Go ahead… try it… see how useful that is in your system.
Coupling is not inherently evil. If you don’t have some amount of coupling, your software will not do anything for you.
Coupling is not inherently evil. If you don’t have some amount of coupling, your software will not do anything for you. You need well-known points of interaction between the pieces of your system. Without them, you cannot create a system of parts that can work together, so you should not strive to eliminate coupling entirely. Rather, your goal in software development should be to attain the correct level of coupling while creating a system that is functional, understandable (readable by humans), and maintainable.
High Cohesion
Cohesion is the extent to which two or more parts of a system are related and how they work together to create something more valuable than the individual parts. Think of the old adage, “The whole is greater than the sum of the parts.”
People seek high cohesion in sports teams, for example. They want to have a team of basketball players that know how and when to pass the ball, and how and when to score. Everyone expects the individual players to play together as a team to increase the chances of the team winning the game. Companies also seek cohesion in their project teams at work. They put developers and user interface designers together with business analysts and database administrators, along with other roles and responsibilities. The intent of creating teams of cross-functional skill sets is to use the strengths of each team member to counter the weaknesses of others. You likely also look for cohesion in the technology you are using and the software that you are writing. You probably want a database system that connects easily to your programming language of choice. You also want a user interface technology that makes it easy to wire up the business logic and data access. Cohesion is all around. You only need to recognize it for what it is.
In software systems, developers talk about high-level concerns and low-level implementation details. This scale of concern can help you understand the many perspectives of cohesion within your software. How well do the lines of code in a method or function work together to create a sense of purpose? How well do the methods and properties of a class work together to define a class and its purpose? How well do the classes fit together to create modules? How well do the modules work together to create the larger architecture of the system? Understanding the perspective that you are dealing with at any given time will help you understand the extent to which the pieces are cohesive.
Understanding the perspective that you are dealing with at any given time will help you understand the extent to which the pieces are cohesive.
Examine the puzzle-picture of my son in Figure 2. If you separate all of the individual pieces, what do you have? You have a series of pieces that provide very limited value on their own. The intrinsic value of an individual piece is only that it can be combined with other pieces. I’m not interested in playing with a single piece, though. I want to have enough pieces to complete the puzzle in question. I want a highly cohesive system of pieces.

A complete puzzle has much more value than the all of the individual pieces. Knowing that the puzzle pieces should create a picture of my son also provides a higher level of value to me-more value than any other random puzzle. A puzzle where all of the pieces are black, or a puzzle that shows a picture of a field, will not inspire the feelings of love in me the way a picture of my son will. This desire to complete the picture of my son provides motivation to not only put the puzzle together, but to put the right pieces in the right places.
If cohesive systems-software, puzzles, or otherwise-have multiple parts coming together to create more value than then individual parts, it stands to reason that you cannot create a highly cohesive system out of large, all-in-one pieces. For example, a software system cannot be cohesive if it is made up of excessively large “god” classes. These types of classes tend to have too many concerns within them to create any cohesion outside of themselves. A single class that does all of the actions in the following bullet list has far too many concerns to be cohesive with anything else.
- Load data from a file or database
- Process the data into a structure
- Display the data to the user
- Obtain input from the user on what to do with the data
- Perform the actions requested by the user
- Persist the changes back to the file or database
The processes listed here are very common. Many software systems use some form of this basic workflow. However, including all of these processes in a single class would make it difficult to create a cohesive system. You might see cohesion between high-level processes but you lose the ability to create cohesion at lower levels such as methods and classes.
To create a more cohesive system from the higher and lower level perspectives in this example, you can break out the various needs into separate classes. You might separate the user interface needs, the data loading and saving needs, and the processing of the data. Having these smaller parts, each with their own value in the overall process, gives you a much more cohesive system from the various perspectives.
Encapsulation
Most developers define encapsulation as information hiding. However, this definition often leads to an incomplete understanding and implementation of encapsulation. It seems that many people see the word information and think data or properties. Based on this they try to make public properties that wrap around private fields, or make properties private instead of public. This perspective, unfortunately, misses out on a tremendous opportunity that encapsulation provides: to hide not just data, but process and logic as well.
Strong encapsulation is evidenced by the ability for a developer to use a given class or module by its interface, alone. The developer does not, and should not, need to know the implementation specifics of the class or module. Figure 3 represents a well-encapsulated process where the calling objects, represented by blue boxes, do not have to know about the implementation detail of the red box. The red box should be free to change its implementation without fear of breaking the code that is calling it, so long as the public interface or the semantics of that interface do not change.

Encapsulation helps reduce duplication of data and processes in your system. Whether you have a business process, a single point of common data, or a technical or infrastructure process, you should have one and only one implementation to represent the item in question.
If you plan to use a circular saw to cut a piece of wood, you probably don’t care about how the motor in that saw works. You only care that when you pull the trigger, the blade spins at a rapid rate and allows you to easily cut the wood.
In situations where you need to use a process in more than one location, proper encapsulation combined with low coupling will help to ensure that you have a part that can create cohesion in the system. For example, if you plan to use a circular saw to cut a piece of wood, you probably don’t care about how the motor in that saw works. You only care that when you pull the trigger, the blade spins at a rapid rate and allows you to easily cut the wood. The saw has encapsulated the process of causing the blade to turn through a simple, public interface-the handle with the trigger. Additionally, the saw itself contains other forms of encapsulation such as the connection points between the saw blade and the motor. This allows you to replace the saw blade without having to reconstruct the motor, the trigger mechanism, or any other part of the saw.
Object-Oriented Principles in Our Day to Day Jobs
Developers hear about these and other principles of object-oriented development fairly regularly during their professional career. These real-world discussions often center around how the principles would be “nice to achieve,” though, relegating them to the realms of the ivory tower academic. When it comes to the everyday work of software development, it seems that most developers either don’t understand how to get to these principles or don’t think it’s possible in a reasonable time frame. However, these principles are not just for the academics. Developers should apply them to their development efforts. The question should change from “Can you apply the principles, here?” to “How do you correctly apply the principles, here?”
S.O.L.I.D. Stepping Stones
When you start asking the question of how, it’s a little like looking at a marathon race and wondering how you end up at the finish line. Obviously, for a marathon you arrive at the finish line by running one step at a time. Software development lets you move one step at a time toward your object-oriented goals, as well. The steps are composed of additional principles and implementation goals, such as those outlined in the SOLID acronym:
-
S: Single Responsibility Principle (SRP) -
O: Open-Closed Principle (OCP) -
L: Liskov Substitution Principle (LSP) -
I: Interface Segregation Principle (ISP) -
D: Dependency Inversion Principle (DIP)
Originally compiled by Robert C. Martin in the 1990s, these principles provide a clear pathway for moving from tightly coupled code with poor cohesion and little encapsulation to the desired results of loosely coupled code, operating very cohesively and encapsulating the real needs of the business appropriately.
The Single Responsibility Principle says that classes, modules, etc., should have one and only one reason to change. This helps to drive cohesion into a system and can be used as a measure of coupling as well.
The Open-Closed Principle indicates how a system can be extended by modifying the behavior of individual classes or modules, without having to modify the class or module itself. This helps you create well-encapsulated, highly cohesive systems.
The Liskov Substitution Principle also helps with encapsulation and cohesion. This principle says that you should not violate the intent or semantics of the abstraction that you are inheriting from or implementing.
The Interface Segregation Principle helps to make your system easy to understand and use. It says that you should not force a client to depend on an interface (API) that the client does not need. This helps you develop well-encapsulated, cohesive set of parts.
The Dependency Inversion Principle helps you to understand how to correctly bind your system together. It tells you to have your implementation detail depend on the higher-level policy abstractions, and not the other way around. This helps you to move toward a system that is coupled correctly, and directly influences that system’s encapsulation and cohesion.
Throughout the rest of this article, I will walk through a scenario of creating a software system. You will see how the five SOLID principles can help you to achieve strong encapsulation, high cohesion, and low coupling. You will see how you can start with a 50-meter “get it done now” dash, and end with a long term marathon of updates to the system’s functionality.
Setting the Pace: A 50-Meter Dash
To help understand how you can achieve the goal of an object-oriented system through the use of the SOLID principles, I’ll walk you through a simple scenario, a solution, and the resulting expectations.
Scenario: Email an Error Log
One day at the office, your manager walks into your cube and looks like his hair is on fire. He informs you that his manager, the CTO, just got off the phone with a very irate customer. Apparently, one of your company’s hosted applications is throwing exceptions and preventing the customer from being able to complete their work.
The CTO has informed your manager that he needs immediate knowledge of the exceptions being thrown from this system, and personally wants to see an email in his inbox for every exception thrown, until the system is fixed. Your manager, worried about keeping his job, now wants you to create a quick-and-dirty application that allows a network operations person to send the contents of a log file to the CTO. Furthermore, this thing has to be out the door and in the hands of the network operations person before lunch-a couple of hours from now. Using a running analogy, you are now engaged in a 50-meter dash. You need to crank this code out and deliver it as quickly as possible.
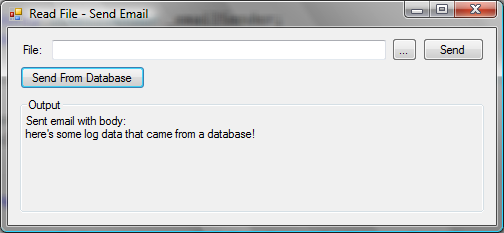
Solution: Select a File and Send It
A few hours after that conversation with your manager, you have produced a very simple system that allows the user to select a file and send the contents of that file via email (Figure 4).
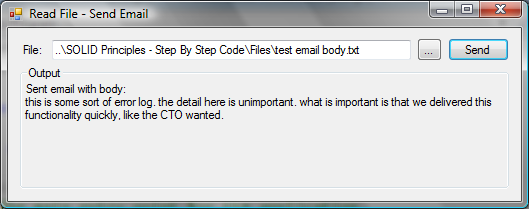
The implementation of this application is very crude by your own standards: you coded the entire application in the form’s code, did no official testing, and did the bare minimum of exception handling (Listing 1). However, you got the job done.
New Expectation: All Errors Emailed
A week after you wrote that quick-and-dirty email sending application, your boss is back in your cube to talk about it again. This time, he informs you that your application was a smashing success and the CTO has mandated that all systems send error log emails to a special email address for collecting them. The CTO wants you, specifically, to handle this since your original application was received so well.
Resetting the Pace
As your first assignment, after hearing about this new mandate from the CTO, you want to figure out what log files the network operations personnel will need to send, and how they want to facilitate this. After some discussion with the operations group lead, you have agreed to add two new aspects of functionality of the system:
You have also negotiated a slightly better timeframe with the network operations people than your manager gave you for the original application. They have agreed to a delivery date of close-of-business, tomorrow.
With this new deadline and the new requirements in mind, you decide to settle in for a slightly longer race than the original 50-meter dash. The code you started with was sufficient at the time, but now you need to enhance and extend it. You could consider this a 100- or possibly a 400-meter race at this point. The good news is that you know how to set your pace according to the situation you find yourself in.
Single Responsibility Principle
The Single Responsibility Principle says that a class should have one, and only one, reason to change.
This may seem counter-intuitive at first. Wouldn’t it be easier to say that a class should only have one reason to exist? Actually, no-one reason to exist could very easily be taken to an extreme that would cause more harm than good. If you take it to that extreme and build classes that have one reason to exist, you may end up with only one method per class. This would cause a large sprawl of classes for even the most simple of processes, causing the system to be difficult to understand and difficult to change.
When the business perception and context has changed, then you have a reason to change the class.
The reason that a class should have one reason to change, instead of one reason to exist, is the business context in which you are building the system. Even if two concepts are logically different, the business context in which they are needed may necessitate them becoming one and the same. The key point of deciding when a class should change is not based on a purely logical separation of concepts, but rather the business’s perception of the concept. When the business perception and context has changed, then you have a reason to change the class. To understand what responsibilities a single class should have, you need to first understand what concept should be encapsulated by that class and where you expect the implementation details of that concept to change.
Consider an engine in a car, for example. Do you care about the inner working of the engine? Do you care that you have a specific size of piston, camshaft, fuel injector, etc? Or, do you only care that the engine operates as expected when you get in the car? The answer, of course, depends entirely on the context in which you need to use the engine.
If you are a mechanic working in an auto shop, you probably care about the inner workings of the engine. You need to know the specific model, the various part sizes, and other specifications of the engine. If you don’t have this information available, you likely cannot service the engine appropriately. However, if you are an average everyday person that only needs transportation from point A to point B, you will likely not need that level of information. The notion of the individual pistons, spark plugs, pulleys, belts, etc., is almost meaningless to you. You only care that the car you are driving has an engine and that it performs correctly.
The engine example drives straight to the heart of the Single Responsibility Principle. The contexts of driving the car vs. servicing the engine provide two different notions of what should and should not be a single concept-a reason for change. In the context of servicing the engine, every individual part needs to be separate. You need to code them as single classes and ensure they are all up to their individual specifications. In the context of driving a car, though, the engine is a single concept that does not need to be broken down any further. You would likely have a single class called Engine, in this case. In either case, the context has determined what the appropriate separation of responsibilities is.
Separating the Email Application
After some quick analysis of your existing application’s code, you decide that the new requirements are really two distinct points of change. Following the Single Responsibility Principle, these two points show you where you need to separate the existing code into multiple classes (Figure 6).
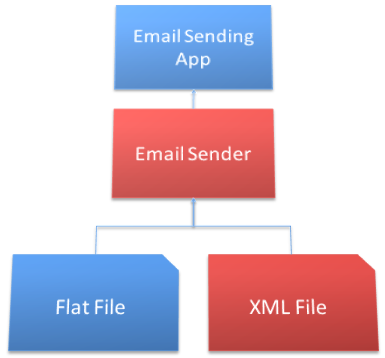
A new EmailSender object will provide the ability for the network operations personnel to have an API to code against. Additionally, separating out the format reading from the form is necessary to allow the form or the API to read the file format.
To simplify the API that the network operations people need, you decide to put the file reading code into the email sender (Listing 2). This will provide a simple enough interface and let you get the functionality out the door in a timely manner.
In the interest of time and not neglecting your other responsibilities, you decide to go ahead and create a single FormatReader class to handle both of the file formats. This code only needs to know if the contents are valid XML. A quick hack to load the contents into an XmlDocument should be sufficient for this small application.
string messageBody;
try
{
XmlDocument xmlDoc = new XmlDocument();
xmlDoc.LoadXml(fileContents);
messageBody = xmlDoc.
SelectSingleNode("//email/body")
.InnerText;
}
catch (Exception)
{
messageBody = fileContents;
}
return messageBody;
The lesson to remember in this release of the application is that the Single Responsibility Principle is driven by the needs of the business to allow change. “A single reason to change” helps you understand which logically separate concepts should be grouped together by considering the business concept and context, instead of the technical concept alone.
Extensibility and Coming Requirements
A few days after delivering the API set to your network operations department, your manager is back in your cube with good news-the operations personnel love what you have done for them. The API you delivered was very simple and they were able to get the email process up and running in no time at all.
With this success in mind, your manager has been trying to drum up additional uses for your new application. In this effort, he has heard some rumbling about needing to send log messages from more than flat files or XML files. He expects the official request for features to come in soon, and wants you to get a head start on being able to extend the application in this manner.
Given the operations group capabilities-they write some code, though it is usually some sort of scripting-you decide that they should be able to extend the supported file formats whenever they need to. After a quick discussion with the operations personnel, they agree and appreciate your confidence in their abilities. From that discussion and the direction from your manager, you decide to move forward on the ability to add new file formats as needed.
Open-Closed Principle
The Open-Closed Principle says that a class should be open for extension, but closed for modification. In other words, you should be able to easily change the behavior of the class in question without having to modify it.
The next time you are at a hardware store, look at the power tools. You will notice that there are a wide range of saw blades that can attach to a single saw. One blade compared to another may not look very different at first, but a closer inspection may reveal some significant differences. Some blades are constructed with different metals, the number of teeth or edges may vary, and the material that is used for the teeth is often designed for special purposes. No matter what the difference, though, if you are comparing two blades that attach to the same type of saw, they will have one thing in common: how they attach to the saw-the interface between the saw and the blade.
The individual differences of the blades are what make each type of blade unique. One blade may cut through wood extremely quickly, but leave the edges rough. Another blade may cut wood more slowly and leave the edges smooth. Still others may be suited for cutting metal or other materials. The wide variety of blades, combined with the common method of attaching them to the saw, allows you to change the behavior of the saw without having to modify the mechanical portion of the saw.
So, how do you allow a class’s behavior to be modified without actually modifying the class? The answer is surprisingly simple and there are several methods for doing this.
Have you ever implemented an interface in a class and then passed an instance of that class into another object? Perhaps you implemented the IPrincipal interface for custom security needs. Or, you may have written your own interface such as the classic example of IAnimal, and implemented a Cat and a Dog object from this interface. The ubiquitous nature of explicit interfaces in .NET, as well as abstract base classes, delegates, and other forms of abstraction, all provide different ways of allowing custom behavior to be supplied to existing classes and modules. You can use design patterns such as Strategy, Template, State, and others to facilitate the behavioral changes through the use of such abstractions. There are still other patterns and abstractions, and other methods of injecting behavior and altering the class at runtime. Chances are, if you have written an application that required even a small amount of flexibility, you have either provided a custom behavior implementation to an existing class, or have written a class that required a custom behavior to be supplied.
Restructuring for Open-Closed
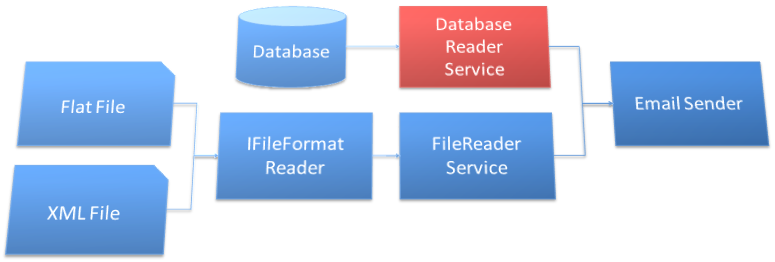
Given the need for multiple, unknown file types to be parsed, you decide to supply an interface that can be implemented by any number of objects, from any number of third parties, including the network operations personnel. In addition to the actual file parsing, you will need the interface to tell you whether or not the specific implementation can handle the current file contents. Your resulting application structure looks more like Figure 7, with the IFileFormatReader interface defined as follows:
public interface IFileFormatReader
{
bool CanHandle(string fileContents);
string GetMessageBody(string fileContents);
}
Since you know that there are multiple file formats being read now, you also decide to move the existing code that reads the flat file and XML file formats into two separate objects. The flat file reader can handle any non-binary log file, so you decide that this handler does not need to determine if it can handle the file contents sent to it. It only needs to say that it can handle the format, and then send the original content back out. You rewrite the implementation of the flat file format reader as follows:
class FlatFileFormatReader: IFileFormatReader
{
public bool CanHandle(string fileContents)
{
return true;
}
public string GetMessageBody(
string fileContents)
{
return fileContents;
}
}
The XML file format reader will contain a check to see if the XML is valid. The GetMessageBody method will then parse the XML for the content, as shown in Listing 3.
Next, you want to introduce the FileReaderService class. This will use the various IFileFormatReader implementations and is where the behavioral change will occur when the various format readers are supplied.
To support an unknown number of file format readers, you decide to store the list of registered format readers in a simple collection:
IList<IFileFormatReader> _formatReaders = new
List<IFileFormatReader>();
public void RegisterFormatReader(
IFileFormatReader fileFormatReader)
{
_formatReaders.Add(fileFormatReader);
}
The RegisterFormatReader method allows any code that calls the FileReaderService API to register as many format readers as they need. Then, when a file needs to be parsed, a call to a GetMessageBody method is made, passing in the contents of the file as a string. This method runs through the list of registered format readers and checks to see if the current one can handle the format. If it can, it calls the GetMessageBody method of the reader and returns the data.
public string GetMessageBody(string fileContents)
{
string messageBody = string.Empty;
foreach(IFileFormatReader formatReader
in _formatReaders)
{
if (formatReader.CanHandle(fileContents))
{
messageBody = formatReader
.GetMessageBody(fileContents);
break;
}
}
return messageBody;
}
At this point, if there is no registered reader that can handle the file contents, an empty string is returned. You realize that you need to add a default file reader. The intention is to ensure that all log files are handled, regardless of the content. If a file can’t be handled by any other reader, you will want to return all of the content through the flat file format reader.
By adding a separate RegisterDefaultFileReader method, you can ensure that only one default exists. Listing 4 shows the resulting GetMessageBody implementation.
Finally, you need to update the usage of the FormatReader object in your EmailSender. You need to register both the XML file format reader and the flat file format reader in the constructor of the email sender class.
private readonly FileReaderService
_fileReaderService = new FileReaderService();
public EmailSender()
{
_fileReaderService.RegisterFormatReader(
new XmlFormatReader());
_fileReaderService.
RegisterDefaultFormatReader(
new FlatFileFormatReader());
}
Happy Consumers and More Requirements
A few days after releasing this version of the application and API, you hear that the operations group loves your IFileFormatReader and the extensibility it brings to the table. They have successfully implemented several format readers and are planning on more.
A short time later, a new request comes in that you were not expecting. One system the operations group must support logs all of its errors to a database, not a text file. Moreover, according the operations personnel, they cannot write code that hits the database in question. Apparently, that’s “above their pay grade.” They need someone on the development staff to do it, and are asking for your help.
The most challenging part of this new requirement is the CTO being involved, again. Due to the high visibility of this project and the potential for lost revenue if errors are not proactively corrected, he wants your application updated to support reading from the database, immediately. According to your manager, when the CTO says “immediately” he usually means before the end of the day. It’s only a few hours before the day ends and you’ve been running on very little sleep for the last few days, but you think you can bang out a working version and get it to the operations group in time to make the CTO happy.
Liskov Substitution Principle
The Liskov Substitution Principle says that an object inheriting from a base class, interface, or other abstraction must be semantically substitutable for the original abstraction. Even if the original abstraction is poorly named, the intent of that abstraction should not be changed by the specific implementations. This requires a solid understanding of the context in which the interface was meant to be used.
To illustrate what a semantic violation may look like in code, consider a square and a rectangle, as shown in Figure 8. If you are concerned with calculating the area of a resulting rectangle, you will need a height, a width and an area method that returns the resulting calculation.

public class Rectangle
{
public virtual int Height { get; set; }
public virtual int Width { get; set; }
public int Area()
{
return Height * Width;
}
}
In geometry, you know that all squares are rectangles. You also know that not all rectangles are squares. Since a square “is a” rectangle, though, it seems intuitive that you could create a rectangle base class and have square inherit from that. But what happens when you try to change the height or width of a square? The height and width must be the same or you no longer have a square. If you try to inherit from rectangle to create a square, you end up changing the semantics of height and width to account for this.
public class Square : Rectangle {
public override int Height {
get { return base.Height; }
set { base.Height = value;
base.Width = value;
}
}
public override int Width {
get { return base.Width; }
set { base.Width = value;
base.Height = value;
}
}
}
What happens when you use a rectangle base class and assert the area of that rectangle? If you expect the rectangle’s area to be 20, you can set the rectangle’s height to 5 and width to 4. This will give you the result you expect.
Rectangle rectangle = new Rectangle();
rectangle.Height = 4;
rectangle.Width = 5;
AssertTheArea(rectangle);
private void AssertTheArea(Rectangle rectangle)
{
int expectedArea = 20;
int actualArea = rectangle.Area();
Debug.Assert(expectedArea == actualArea);
}
What if you decide to pass a square into the AssertTheArea method, though? The method expects to find an area of 20. Let’s try to set the square’s height to 5. You know that this will also set the square’s width to 5. When you pass that square into the method, what happens?
Rectangle square = new Square();
square.Height = 5;
AssertTheArea(square);
private void AssertTheArea(Rectangle rectangle)
{
int expectedArea = 20;
int actualArea = rectangle.Area();
Debug.Assert(expectedArea == actualArea);
}
You get the wrong result because 5 x 5 is 25, not 20. That is too high, so now try a height of 4 instead. You know that 4 x 4 is 16. Unfortunately, that’s too low. So the question is, “how can you get 20 out of multiplying two integers?” The answer is: you can’t.
The square-rectangle issue illustrates a violation of the Liskov Substitution Principle. You clearly have the wrong abstraction to represent both a square and a rectangle for this scenario. This is evidenced by the square overriding the height and width properties of the rectangle, and changing the expected behavior of a rectangle.
What, then, would a correct abstraction be? In this case, you may want to use a simple Shape abstraction and only provide an Area method, as shown in Listing 5. Each specific implementation-square and rectangle-would then provide their own data and implementation for area allowing you to create additional shapes such as circles, triangles, and others that you don’t yet need. By limiting the abstraction to only what is common among all of the shapes, and ensuring that no shape has a different meaning for “area” you can help prevent LSP violations.
A Quick-and-Dirty Database Reader
After fuelling up with another energy drink and shaking off the sleep you so desperately want, you dive into the code for the database reader. Given the short time frame, you decide to take a shortcut and not introduce a new abstraction or a new method to the API. Rather, you decide to hard code the behavior of reading from the database into the application, facilitated by the use of a special file format reader. You know it’s not the brightest moment in your career, but you just want to get it out the door and go home for the night. What should have been an 800-meter race has now become a 50-meter dash in your mind. Listing 6 shows the result.
You deliver the working code on time, and manage to make it home before falling asleep while driving. Overall, you consider it to be a successful day.
The following week, you hear word that the network operations personnel liked the ability to read from a database. In fact, they liked it so much that they told another department about this feature. What they didn’t know, though, was that the code you delivered was written for one very specific database and didn’t actually read the connection string from a file. You knew that the security guys would have your head if you stored the real connection information in a plain text file, so you hard coded it into the file reader service. You created the “server=” content of the file as a placeholder to let you know that you should use the database connection reader.
So, when the network operations personnel gave your code to the other department, everyone started wondering why the other department was now reading log files from the network operations center. All eyes are now looking squarely at you.
Revisiting the Database Reader
All of the eyes looking squarely at you were from your friends in the company, fortunately. After explaining the stress and sleeplessness that undermined your ability to code that day, they all laughed and asked when you would have a new version ready for them. Remembering that sprinting out of the gate during a marathon race is likely to cause the same problems again, you inform them that you’ll need a day or two to get the situation sorted out correctly. There’s no immediate need or CTO putting on the pressure at this point, so everyone agrees to the general timeline and waits patiently while you work.
After a quick discussion with some coworkers, you realize that you had changed the semantics of the file format reader interface and introduced behavior that was incompatible. After a little more discussion, you end up with the design represented by Figure 9, and the change turns out to be fairly simple.
By introducing a separate database reader service, you can remove the type-checking code from the file reader service.
By introducing a separate database reader service, you can remove the type-checking code from the file reader service. You can set up the database reader to read the required connection string from the company standard storage for sensitive data. That decision makes the people in network operations, security, and the other department that wants to use the code, happy.
Next, you update the UI to include a “Send From Database” button as shown in Figure 10. This button calls into the same email sender object that you’ve been using as the public API. However, the email sender now has a ReadFromDatabase method along with a ReadFromFile method. This keeps the public API centralized while still providing the functionality that the various departments need.
public class EmailSender
{
public void ReadFile()
{ /* ... */ }
public void SendEmail()
{ /* ... */ }
public void ReadDatabase()
{ /* ... */ }
}
With this newly structured system in place, you deliver the solution to both of the waiting departments. Your friends are happy to hear that you’ve been getting more sleep and that the application they’ve been waiting for is “finally done” -a day earlier than promised.
Still More Use for Your Application
Shortly after delivering the updated version of the application with the database reading capabilities, another department gets wind of it and they want to use the API. After a quick conversation with them to find out if your application is what they really need, you deliver the working bits. A day later, one of the developers from that department stops by your cube with a confused look on his face. After some quick chat, you realize that he’s confused by the email sender object. It seems that he doesn’t understand why there’s a “read from database” and “read from file” method on an object that is supposed to send email.
Interface Segregation Principle
The Interface Segregation Principle says that a client (the calling class or module) should not be forced to depend on an interface that it does not need. If there are multiple concerns represented by an interface, or the methods and properties are unclear, then it becomes difficult to know which methods should be called when. Therefore, you should separate the interface into logical pieces, based on the needs of the consumers.
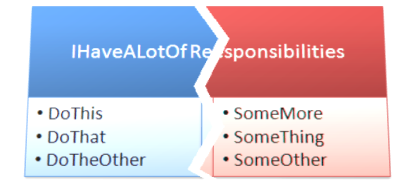
To a certain extent, ISP can be considered a sub-set, or more specific form of the Single Responsibility Principle. The perspective shift of ISP, though, examines the public API for a given class or module. Looking at the IHaveALotOfResponsibilities class in Figure 11, you can see not only a set of methods that you should break into multiple classes for the sake of Single Responsibility, but a very fat interface that may confuse any of the calling clients. If I want to use IHaveALotOfResponsibilities, do I need to call the “Do…” methods? If so, do I need to call them before the “Some…” methods? Or can I just call the “Some…” methods? Or ???
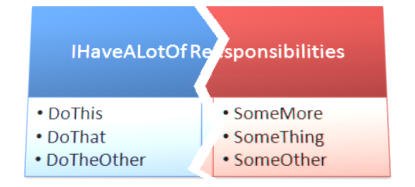
Rather than forcing a developer to know which methods they should call to facilitate the functionality, you should provide a separated set of interfaces that encapsulate the processes in question, independently. This helps to prevent confusion and also helps to cut down on semantic coupling-the idea that a developer has to know the specific implementation of the class to use it correctly.
Violations of ISP are not just found in software, though. Most professional workers in modern society have worked in an office at one time or another. Depending on the size of the office-how many people are working there-you will typically find one or more, very large, all-in-one business machines. These machines print, copy, fax, scan & email, and other functions.
Think back to the last time you had to use one of these large, multi-function machines. They typically have control panels that include 15 to 20 buttons, an LCD display of some sort, and various other forms of input. The number of functions combined with the number of input options often creates a very frustrating user experience. What buttons or controls do you need to operate the machine? How can you ensure that it is going to create a photocopy of a document instead of scanning and emailing it? Do you need to “clear” the current settings? Do you need to type in a number of copies now, or scan the document first and then tell it how many copies to print? What about the brightness, contrast, or paper size of your copy? Did the machine remember the settings from the last user, who wanted to scan a document and email it to someone? The number of options is overwhelming. The instructions are difficult to follow and you’re not always sure that it did what you want. The worst outcome is when an error messages pops up after performing what you believe is the correct sequence of steps. What does “PC LOAD LETTER” mean, anyway?
The large number of capabilities and options that these all-in-one copiers provide may offer some advantages to an office environment. They provide a relatively low cost, high quality, document-centric set of solutions. Unfortunately, they typically come at the cost of a confusing interface. (I, for one, have spent a good number of hours trying to remember how to scan and email a document to myself vs. making a photocopy on the machines in my office.) If manufacturers want to have machines with such a large feature set providing value to so many different users, they should look for ways to separate the interface into each feature so that the user is not led down the wrong path, or led down the right path at the wrong time.
Splitting Up the Email Sender API
After the discussion about your email sender’s API being rolled up into a single class, and the realization that not everyone needs to read from a database or a file, you decide to separate out the objects as shown in Figure 12. When you dive into the code again, you realize that you don’t have to make many changes to your system. The database reader service and the file reader service are both objects on their own, already. The real change that you need to make is to not call them directly from the email sender.
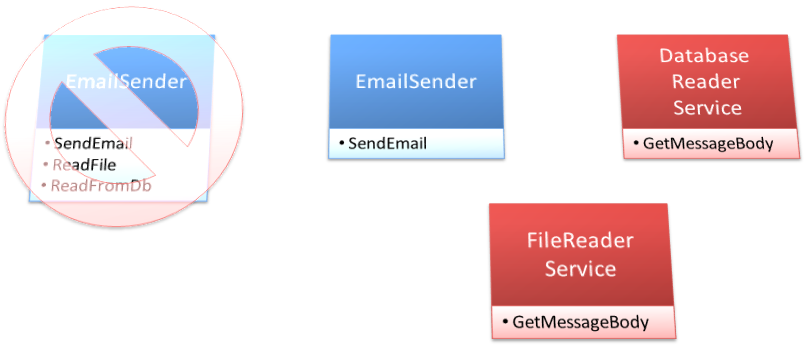
The resulting EmailSender class is significantly smaller. Additionally, you were able to make the message body a parameter of the SendEmail method. This allows for any client of the email sender to provide any message body they need, regardless of the source.
public class EmailSender
{
public void SendEmail(string messageBody)
{
SmtpClient client = // new ...
client.Credentials = // new ...
MailAddress from = // new ...
MailAddress to = // new ...
MailMessage msg = // new ...
msg.Body = messageBody;
msg.Subject = // ...
client.Send(msg);
}
}
The file reader service and database reader service classes needed no changes this time around. You simply moved their calls into the code behind of the form for your application (Listing 7). However, the other departments that are using the API need to know that they are responsible for calling the database reader and file reader, directly.
After some discussion with the other departments, there was a little bit of grumbling about how they thought the new API set was more difficult to use. They agreed that a small set of documentation on how to use the API would be sufficient for their needs, though. And honestly, you feel a little more secure knowing that you will have some documentation for the growing API.
Trying to Settle in for a Marathon
After delivering this version of the system, including the new documentation that you wrote for the API set, you decide to step back for a minute and take stock of your system. What you see is rather surprising at this point. You have a growing number of classes and a lot of functionality compared to the original starting point of reading a flat text file and emailing it. Given the attention that you’ve received for this work and the amount of functionality that you have built in, you decide to ask your manager for some official project support. Rather than working this code base on the side of your other responsibilities, you would like to have a dedicated project for this system. This would help provide long-term support for what is now a mission critical part of the company.
Your manager, having received nothing but praise for your hard work and dedication from everyone-including the CTO-happily says yes. He then asks for a timeline to complete the next version. You let him know that you’ll need to think about that for a bit, but off-hand, you expect the code to change when new features are needed, primarily.
On your way back to your desk, another coworker stops you and wants to discuss this project. He’s heard a lot about what you have been doing and likes the direction that you have been taking the code. After a few minutes of discussion, your coworker lets you know that he wants to use this project, but isn’t interested in the current format readers or email sender. He’s mostly interested in the general process and wants to know if he can reuse various parts of the system without having to bring all of your specific implementations along. The current objects and interfaces provide most of what your coworker wants. However, you realize that the big picture of the process is still hard coded and tightly coupled in the current application. Your coworker mentions an idea that revolves around a higher-level process providing an abstraction that lower-level details can implement. This piques your interest and you sit down at your desk, ready to tackle this next challenge.
The Dependency Inversion Principle
The Dependency Inversion Principle has two parts:
Think back to the last time you wanted to turn on a lamp to help light an area of a room. Did you have to cut a hole in the wall, dig around for electrical wires, strip them bare, and solder the lamp directly into the wiring of the house?
Think back to the last time you wanted to turn on a lamp to help light an area of a room. Did you have to cut a hole in the wall, dig around for electrical wires, strip them bare, and solder the lamp directly into the wiring of the house? Of course not (at least, I hope not!) The electrical outlet provides a standard interface for such an occasion. No one, in most of the industrialized world, would expect to solder a lamp directly into the electrical wiring of the building. Additionally, no one expects to only be able to plug in a lamp, to an outlet. We expect to plug in lamps, computers, televisions, vacuums and other devices. The standard, 120 volt, 60 hertz power outlet has become a ubiquitous part of society in the United States.
The same principle also applies in software development. Rather than working with a set of classes that are hard wired (tightly coupled) to each other, you want to work with a standard interface. Furthermore, you want to ensure that you can replace the implementation without violating the expectations of that interface, according to LSP. So, if you’re working with an interface and you want to be able to replace it, then you need to ensure that you are only working with the interface and never with a concrete implementation. That is, the code that relies on the interface should only ever know about the interface. It should not know about any of the specific classes that implement the interface.
Policy, Detail, and Abstraction Ownership
Another way to think about DIP is to say that policy (high level) should not depend on detail (implementation), but detail should depend on policy. The higher-level policy should define an abstraction that it will call out to, where some detail implementation executes the requested action. This perspective can help to illustrate why this is the dependency inversion principle and not just a dependency abstraction principle.
As an example of why detail depending on policy is an inversion of the dependency, look at the code you wrote into the FormatReaderService. The format reader service is the policy. It defines what the IFileFormatReader interface should do-the expected behavior of those methods. This allows you to be concerned with the policy itself, by defining how the format reader service works without regard for the implementation detail of the individual format readers. The format readers, then, are dependent on the abstraction provided by the reader service. Both the service and individual format readers, in the end, are dependent on the abstraction of the format reader interface.
Correcting Coupling by Inverting Dependencies
You know that it’s not reasonable for a class to have zero dependencies-to have zero coupling. You would not have a usable set of classes if you had zero coupling. However, you also know that you want to reduce direct coupling whenever possible. You want to decouple your system so that you can change individual pieces without having to change anything more than the individual piece. The Dependency Inversion Principle is the key to this goal. By depending only on an abstraction such as an interface or base class, you can correct the coupling of the various parts of the system. This allows you to re-compose the system with different implementations.
You would not have a usable set of classes if you had zero coupling.
Consider a set of classes that need to be instantiated into the correct hierarchy so that you can get the functionality needed. It’s easy to have the highest level class-the one that you want to call-instantiate the class at the next level down, and have that class instantiate its next level down, and so-on. Figure 14 represents a standard object graph where the higher-level object-the policy-is dependent on and coupled directly to the lower-level object-the detail.
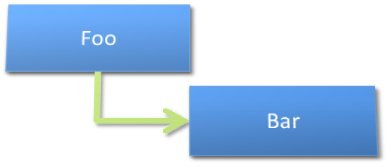
This creates the necessary hierarchy but couples the classes together, directly. You would not be able to use Foo without bringing Bar along with it.
If you want to decouple these classes, you can easily introduce an interface for Foo to depend on and Bar to implement. Figure 15 illustrates a simple IBar interface that you can create from the public API of the Bar class.
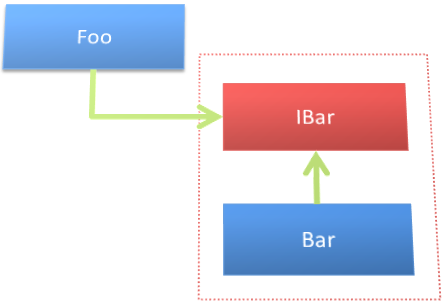
In this scenario, you can decouple the implementation of Bar from the use of it in Foo by introducing the interface. However, you’ve only decoupled the implementation by separating the interface from it. You haven’t inverted the dependency structure yet and you haven’t corrected all of the coupling problems in this setup.
What happens when you want to change Bar in this scenario? Depending on the change you want to make, you could have a rippling effect that causes you to change the IBar interface. Foo depends on the IBar interface, so you must change the implementation of Foo as well. You may have decoupled the implementation of Bar, but you have left Foo dependent on changes to Bar. That is, the Policy is still dependent on the Detail.
If you want to invert the dependency structure and have the Detail become dependent on the Policy, then you must first change your perspective. The developer working with this system must understand that you should not merely abstract the implementation away from the interface. Yes, this separation is necessary, but it is not sufficient. You must understand who owns the abstraction-the Policy, or the Detail.
The Dependency Inversion Principle says that Detail should be dependent on Policy. This means that you should have the Policy define and own the abstraction that the detail implements. In the Foo->IBar->Bar scenario, you need to treat IBar as part of Foo and not just a wrapper around Bar. Nothing may have changed structurally, but the perspective of ownership has shifted, as illustrated by Figure 16.
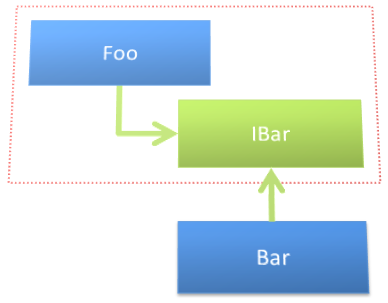
If Foo owns the IBar abstraction, you can place these two constructs in a package that is independent of Bar. You can put them into their own namespace, their own assembly, etc. This can greatly increase the illustration of what class or module is dependent on the other. If you see that AssemblyA contains Foo and IBar, and AssemblyB provides the implementation of IBar, it is easier to see that the detail of Bar is dependent on the policy defined by Foo.
When you have the dependency structure inverted correctly, the ripple effect of changing the policy and/or detail is now correct as well. When you change the implementation of Bar, you are no longer seeing an upward ripple of changes. This is due to Bar being required to conform to the abstraction provided by Foo-the detail is no longer dictating changes to the policy. Then, when you change the needs of Foo, causing a change in the IBar interface, you now have changes that ripple down the structure. Bar-the detail-will be forced to change based on the policy changing.
Decoupling and Inverting the Email Sending System Dependencies
Looking through your codebase you see that the IFileFormatReader is already an instance of Dependency Inversion. The FormatReaderService class owns the definition of the format reader interface. If the needs of the format reader service changes, you will likely see ripples of change down into the individual format readers. However, if an individual file format reader changes, you will not likely see changes ripple up into the format reader service. This makes you wonder where else you can invert the system’s dependencies.
The first thing you want to do is decouple the logic of getting the log message, and sending it as an email, from the form. You don’t mind the references to the two reader services and the email sender, but having the explicit knowledge of what to call when is a little questionable in your mind. You recognize that the process is actually duplicated in the form: once for sending from a file, and once for sending from a database. And then you remember all the other departments that are using this as well, and start to wonder just how much duplication of the process really exists. Additionally, some of your friends have been talking about “unit testing” recently. They say that you should ensure the real process logic that you are testing is encapsulated into objects that don’t have references to external systems.
With all of this in mind, you decide to create an object called ProcessingService. After a few minutes of moving code around to try and consolidate the process, you realize that you don’t want the processing service to be coupled directly to the database reader or file reader services. With an additional moment of thinking, you recognize a pattern between the two: the “GetMessageBody” method. Using this method as the basis, you create a new interfaced called IMessageInfoRetriever and have both the database reader and file reader services implement that.
public interface IMessageInfoRetriever
{ string GetMessageBody(); }
public class FileReaderService :
IMessageInfoRetriever
{
public string GetMessageBody() {/* ... */}
}
public class DatabaseReaderService :
IMessageInfoRetriever
{
public string GetMessageBody() {/* ... */}
}
This interface allows you to provide any implementation you need to the processing service. You then set your eyes on the email service, which is currently directly coupled to the processing service. A simple IEmailService interface solves that, though. Figure 17 shows the resulting structure.
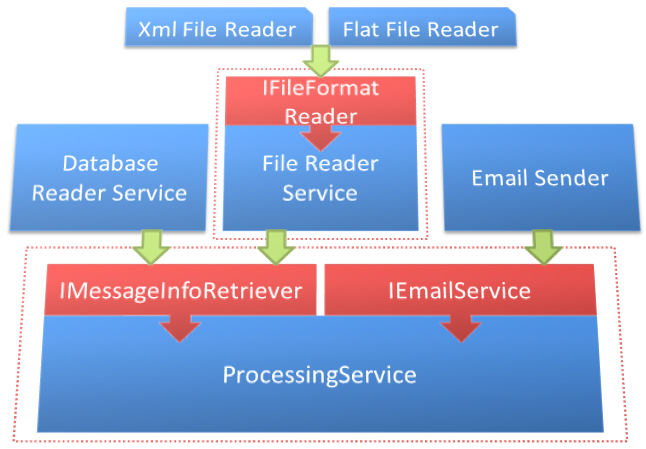
Passing the message info retriever and email service interfaces into the processing service ensures that you have an instance of whatever class implements those interfaces, without having to know about the specific instance types. You can see the end result of this endeavor in Listing 8.
Another Day, Another Delivery
You coworker meets the delivery of this version with great enthusiasm. He’s excited about the possibilities of using the processing service and providing his own email service implementation, format readers, etc. It seems that you have made yet another successful delivery of this ever-evolving solution and you gladly accept your coworker’s thanks.
Heading back to your desk, you realize how high your confidence in this code base, and your ability to continue improving it, actually is. This leads you to wonder what the next change request will be and what new principles and practices you can assimilate into your skill set. It is of little concern, though. Whatever the task, for whoever makes the request, you are certain of your ability to meet their needs.
Summary of Your SOLID Race
When you first set out on the quest to satisfy your CTO, you had no idea that the resulting race would change so many times or so rapidly. You started at a pace to win a 50-meter dash. Soon after, you slowed the pace down for a 400-meter race. You then continued to change the pace as you continued to add features and functionality, realizing the need to restructure the application for long-term maintenance and enhancements. The journey, now at the point where you are settled in for the marathon of a long-term project, has brought you from a system represented by Figure 18, to a system represented by Figure 19.
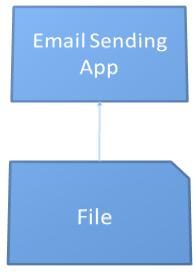
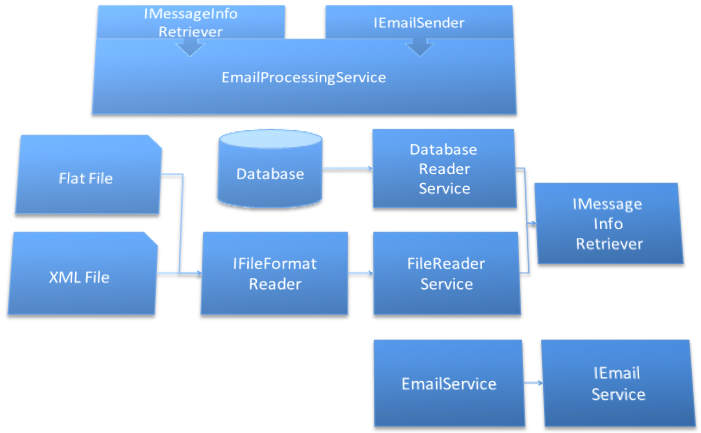
The difference between these two structures is staggering and looking at them side by side for a moment, you wonder what you’ve actually gained with this sprawl of objects and interfaces. You quickly dismiss the sense of uncertainty, though, as you remember the numerous advantages.
Benefits of the New System Structure
With a set of classes that are small and each providing a valuable function, you are able to construct a larger system that has more value than just the individual parts. It’s like working with a box of LEGO building blocks. Each individual block may be valuable, but they can create something much more valuable when stacked together correctly.
This system is also easily dissectible, and the various parts are easily replaceable. You can change out the specific implementations of the email service, the message info retrieval, and other parts of the system. You can accomplish all of these changes without worrying about adversely affecting the parts of the system that you are not touching.
The ability to segment the system, by both horizontal layers and vertical slices, gives you the ability to focus in to a single point in the system.
The ability to segment the system, by both horizontal layers and vertical slices, gives you the ability to focus in to a single point in the system. This allows you to assign various parts of the system to different team members, with more confidence of the system not falling apart like a game of Jenga.
Achieving Low Coupling
By abstracting many of the implementation needs into various interfaces and introducing the concepts of OCP and DIP, you can create a system that has very low coupling. You can take many of these individual pieces out of this system with little to no spaghetti mess trailing after them. Separating the various concerns into the various object implementations also helps to ensure that you can change the system’s behavior as needed, with very little modification to the overall system-just update the one piece that contains the behavior in question.
Achieving High Cohesion
You can get higher cohesion with a combination of low coupling and SRP-you can stack a lot of small pieces together like building blocks to create something larger and more complex. Any of these individual pieces may not represent much functionality or behavior, but then, an individual puzzle piece isn’t much fun to use without the other pieces. Once separated, DIP allows you to tie the various blocks back together by depending on an abstraction and allowing that abstraction to be fulfilled with different implementations. This creates a system that is much greater than the mere sum of its parts.
Achieving Strong Encapsulation
LSP, DIP, and SRP all work hand in hand to create encapsulation. You can encapsulate the behavioral implementations in many individual objects, preventing them from leaking into each other. You can ensure that the dependencies on those behaviors are encapsulated behind an appropriate interface. At the same time, you do the necessary due-diligence to ensure that you aren’t violating any of the individual abstraction’s semantics or purpose, according to LSP. This helps ensure that you can properly replace the implementation as needed.
A New Utility Belt
In the end, the stepping stones of the SOLID principles offer new insight into object-oriented software development. The principles that you once thought were for the academics are now a set of tools that you can readily grasp.
Listing 1: Method to send email from file contents
private void Send_Click(object sender, EventArgs e)
{
try
{
Output.Text = string.Empty;
FileInfo file = new FileInfo(_file);
StreamReader rdr = file.OpenText();
string messageBody = rdr.ReadToEnd();
rdr.Dispose();
SmtpClient client = new SmtpClient("<a href="http://some.mail.server.com">some.mail.server.com</a>");
client.Credentials = new NetworkCredential(
"someuser", "somepassword");
MailAddress from = new MailAddress("<a href="mailto://me@myserver.com">me@myserver.com</a>");
MailAddress to = new MailAddress("<a href="mailto://your.cto@yourcompany.com">your.cto@yourcompany.com</a>");
MailMessage msg = new MailMessage(from, to);
msg.Body = messageBody;
msg.Subject = "Test message";
client.Send(msg);
Output.Text = "Sent email with body: " +
Environment.NewLine + messageBody;
}
catch (Exception ex)
{
Output.Text = ex.ToString();
}
}
Listing 2: The EmailSender object
public class EmailSender
{
public string MessageBody { get; set; }
public string FileName { get; set; }
public void ReadFile()
{
FileInfo file = new FileInfo(FileName);
StreamReader rdr = file.OpenText();
string fileContents = rdr.ReadToEnd();
rdr.Dispose();
FormatReader formatReader = new FormatReader();
MessageBody =
formatReader.GetMessageBody(fileContents);
}
public void SendEmail()
{
SmtpClient client = new SmtpClient("<a href="http://some.mail.server.com">some.mail.server.com</a>");
client.Credentials = new NetworkCredential(
"someuser", "somepassword");
MailAddress from = new MailAddress("<a href="mailto://me@myserver.com">me@myserver.com</a>");
MailAddress to = new MailAddress("<a href="mailto://error.logs@yourcompany.com">error.logs@yourcompany.com</a>");
MailMessage msg = new MailMessage(from, to);
msg.Body = messageBody;
msg.Subject = "Test message";
client.Send(msg);
}
}
Listing 3: The new XMLFileFormatReader object
public class XmlFileFormatReader: IFileFormatReader
{
XmlDocument _xmlDoc;
public bool CanHandle(string fileContents)
{
bool canHandle;
try
{
_xmlDoc = new XmlDocument();
_xmlDoc.LoadXml(fileContents);
canHandle = true;
}
catch (Exception)
{
canHandle = false;
}
return canHandle;
}
public string GetMessageBody(string fileContents)
{
string messageBody = _xmlDoc.SelectSingleNode("//email/body")
.InnerText;
return messageBody;
}
}
Listing 4: GetMessageBody with default file format reader
private IFileFormatReader _defaultFormatReader;
public void RegisterDefaultFormatReader(
IFileFormatReader defaultFormatReader)
{
_defaultFormatReader = defaultFormatReader;
}
public string GetMessageBody(string fileContents)
{
string messageBody = string.Empty;
bool wasHandled = false;
foreach(IFileFormatReader formatReader in _formatReaders)
{
if (formatReader.CanHandle(fileContents))
{
messageBody = formatReader.GetMessageBody(fileContents);
wasHandled = true;
}
}
if (!wasHandled)
{
messageBody = _defaultFormatReader
.GetMessageBody(fileContents);
}
return messageBody;
}
Listing 5: A correct abstraction for a square and rectangle
public interface Shape
{
int Area();
}
public class Rectangle : Shape
{
public virtual int Height { get; set; }
public virtual int Width { get; set; }
public int Area() { return Height * Width; }
}
public class Square : Shape
{
public int LengthOfSides { get; set; }
public int Area() { return LengthOfSides ^ 2; }
}
public class DoStuff
{
public void DoTheRectangleStuff()
{
Rectangle rectangle = new Rectangle();
rectangle.Height = 4;
rectangle.Width = 5;
AssertTheArea(rectangle, 20);
}
public void DoTheSquareStuff()
{
Square square = new Square();
square.LengthOfSides = 4;
AssertTheArea(square, 16);
}
private void AssertTheArea(Shape shape, int expectedArea)
{
int actualArea = shape.Area();
Debug.Assert(expectedArea == actualArea);
}
}
Listing 6: Violating LSP with specific type checks
public class DatabaseConnectionReader : IFileFormatReader
{
public bool CanHandle(string fileContents)
{
bool canHandle = false;
if (fileContents.StartsWith("server="))
canHandle = true;
return canHandle;
}
public string GetMessageBody(string fileContents)
{
throw new NotImplementedException("Need to read from the
database! Not from this interface!");
}
}
public class FileReaderService
{
// ...
public string GetMessageBody(string fileContents)
{
// ...
foreach(IFileFormatReader formatReader in _formatReaders)
{
// ...
if (formatReader.GetType()
.Equals(typeof(DatabaseConnectionReader)))
{
messageBody = // GET THE LOG INFO FROM A DATABASE, HERE.
}
else
{
messageBody = formatReader.GetMessageBody(fileContents);
}
// ...
}
// ...
}
// ...
}
Listing 7: Using The new API set in your application
private void SendFromFile_Click(object sender, EventArgs e)
{
try
{
Output.Text = string.Empty;
FileReaderService fileReaderService =
new FileReaderService();
fileReaderService.RegisterFormatReader(
new XmlFormatReader());
fileReaderService.RegisterDefaultFormatReader(
new FlatFileFormatReader());
string messageBody = fileReaderService
.GetMessageBodyFromFile(_fileName);
EmailSender emailSender = new EmailSender();
emailSender.SendEmail(messageBody);
Output.Text = "Sent email with body: " +
Environment.NewLine + messageBody;
}
catch (Exception ex)
{
Output.Text = ex.ToString();
}
}
private void SendFromDatabase_Click(object sender, EventArgs e)
{
try
{
Output.Text = string.Empty;
DatabaseReaderService databaseReaderService =
new DatabaseReaderService();
string messageBody = databaseReaderService.GetMessageBody();
EmailSender emailSender = new EmailSender();
emailSender.SendEmail(messageBody);
Output.Text = "Sent email with body: " +
Environment.NewLine + messageBody;
}
catch (Exception ex)
{
Output.Text = ex.ToString();
}
}
Listing 8: The ProcessingService class
public class ProcessingService
{
private readonly IEmailSender _emailSender;
private readonly IMessageInfoRetriever _messageInfoRetriever;
public ProcessingService(IEmailSender emailSender,
IMessageInfoRetriever messageInfoRetriever)
{
_emailSender = emailSender;
_messageInfoRetriever = messageInfoRetriever;
}
public string SendMessage()
{
string messageBody = _messageInfoRetriever.GetMessageBody();
_emailSender.SendEmail(messageBody);
return "Send Email With Body: " + messageBody;
}
}
