


Take advantage of the best relational databases and object-oriented design have to offer without compromising either.
Using an object/relational mapping framework like NHibernate, you can significantly reduce the amount of code you write (and therefore potential bugs) for performing standard operations against your database and save the heavy ADO.NET coding for the complicated scenarios.
In my work, I have observed that data access is one of the more complex and error-prone elements of many business computer systems. Developers always seemed to fight with the persistence mechanism and the related problems it caused for deployment, upgrades/changes, integration, reporting, and other important aspects of a complete enterprise line-of-business application.
When I moved to .NET and started leveraging its OO capabilities, it seemed data access became even more complex. I found that I frequently had to compromise either OO principles or data access principles and it never seemed to work out as well as I had hoped. As I started trying to solve more complicated challenges like reporting, integration with other systems, schema migration from one version to the next, and other enterprise concerns, it only got worse and more complex.
As time went on, I spent some more time researching the problem and became aware of a new type of solution. The theory is that, in object-oriented systems, there is a fundamental mismatch between the inherent capabilities, strengths, and weaknesses of object-oriented design and the inherent capabilities, strengths, and weaknesses of a relational data structure design. Many of the problems and resultant defects commonly observed in the persistence layer of an application, the theory suggests, trace back to this inherent mismatch. The theory calls this mismatch the “impedance mismatch.” Keeping this in mind, an application architect who operates under this theory should aim to reduce the complexity by avoiding this mismatch.
Primary Source of Complexity: The Problem Domain
All applications exist to solve one or more problems. The “problem domain” (or “domain” for short) is these problems that the application attempts to solve. The domain is where the primary complexity lay and will involve the most attention from programmers, designers, and architects. Statements such as “Inactive employees should not be scheduled for work items” usually express these domain problems. Since I like to use object-oriented systems such as .NET, I would likely start out trying to model this problem using an “Employee” object and a “Work Item” object. I might have an “Active” Boolean property on Employee as well as a method called “ScheduleWorkItem” that would attempt to schedule a work item for that Employee and report problems if any exist. This is a contrived example, of course, but you will hopefully get the general idea. I have found that object-oriented design gives me the right balance of rigidity and flexibility necessary to address most of the complexity I run into in most line-of-business problem domains.
I like to call objects like “Employee” and “Work Item” entities. Entity is one of those terribly overloaded words with conflicting definitions depending on the context. To me, in the context of domain modeling, entity has a specific definition: A single, uniquely identified unit which represents a set of related data and behavior that is different from other single, uniquely identified units of data and behavior. Entities are very important in my systems. Their identifier never changes, but their data and behavior may, according to the rules of the problem domain.
Finally, I find that languages like C#, VB, and others as well as the capabilities of the .NET Framework afford me better options for making decisions to solve domain problems and to craft and design my entities within that domain.
Secondary Source of Complexity: Persistence
Another source of complexity in my applications is the persistence and retrieval of entity data. Today, there are many options for the underlying data persistence store from object-oriented database (OODB), file-based stores, cloud stores, and, of course, the most prevalent: the relational database management system (RDBMS). Currently, I still prefer using RDBMSs such as Microsoft SQL Server as the underlying persistence store. RDBMSs are, as the ‘R’ implies, relational data stores. This means that the theory of impedance mismatch is in play and is a problem I must address.
When architecting a system, I have several principles I use to guide me when choosing which solution to use to mitigate the impedance mismatch problem. They are not absolute rules, though and I sometimes do violate them if I have very good justification. Principles are, after all, to guide, not to dictate. My principles of persistence are:
-
persistence ignorance: Since the domain is usually complex enough, I do not need to add the extra complexity of allowing persistence-related concerns bleeding into my domain entity logic. I keep persistence concerns, to the maximum extent possible, in the persistence layer. It never works out 100%, but what few compromises I must make are tolerable. -
domain concerns are the concern of the domain: It’s hard enough keeping the domain consistent and defect-free without allowing domain concerns, business logic, and other such concepts escaping from the domain and appearing in others areas of the application such as the presentation layer, the database (SQL stored procedures), ad-hoc queries with inherent logic embedded in WHERE clauses, etc. Decisions that are the concern of the domain should flow from the domain out into other parts of the system and those parts should respect the domain’s authority to determine how those decisions are determined. -
reporting, data integration, and schema versioning, are separate problem domains: This is perhaps one of the easiest principles to fail on proper adherence. It’s easy to allow complex query specifications (that is, reports) to creep into the domain. When I use the word “report”, I don’t just mean things like “ad-hoc reports” (think Crystal Reports, SQL Server Reporting Services, and similar products). I mean anything that involves submitting a query for data using more than a few simple criteria-possibly criteria specified by the user. In many cases, I will consider handling these types of queries/reports in a view, stored procedure, or some other facility of the database designed for the given type of situation. I take great care, though, putting anything that will likely see frequent change into the database as it is usually more difficult to handle change management, versioning, and other such concerns. I realize that I have to balance the needs of the application with the needs of the business demands of frequent change and rapid deployment while maintaining high quality. These aspects can be at odds and require a high degree of discipline and consideration.
For most situations, database persistence and querying is a repetitive, consistent, and well known problem space. However, in many projects today, developers are writing data access code from scratch or re-writing it from a previous attempt on a previous project. In the .NET space, there are many tools that aid in the problems involved with ADO.NET data access. From my experience, these are mostly-solved problems and it is, frankly, wasteful to write simple CRUD data access directly against ADO.NET today when these tools make it easier, safer, and better performing than the average developer could accomplish in a reasonable period of time writing their own persistence framework.
One genre of these tools stands out especially: object/relational mapping frameworks. In the next section, I will explain object/relational mapping (O/RM) and how O/RM tools can greatly accelerate your product development and reduce defects and complexity from your domain and applications.
Object/Relational Mapping
The several currently available object/relational mapping frameworks (heretofore O/RMs) for .NET take several different forms and have different strengths and weaknesses because of this. I won’t go into a full analysis and comparison because it is out of the scope of this article. There are a few features that I find particularly compelling or even mandatory in an O/RM offering I might consider. Among these are: persistence ignorance, POCO support, transparent lazy loading, and mapping separate from the model.
Persistence Ignorance and POCO Support
I’ve already mentioned persistence ignorance earlier in this article so I’ll jump right to POCO (Plain old C#/CLR Object). POCO is important because I want to be able to use my domain entity objects without having to attach to a database. Many persistence frameworks (non-O/RM and some O/RM) in use today require objects be connected to a database to even call their constructor. To me, this is an unacceptable requirement as it hampers my ability to use the objects outside of a database persistence context. Unit testing the behavior in my entities would be extremely complicated if not impossible.
POCO also represents the fulfillment of persistence ignorance in that my entities are not required to do or implement much of anything besides some baseline .NET requirements.
Transparent Lazy Loading
Most O/RMs support some form of lazy loading. Lazy loading is the concept where certain properties or related entities for a given entity are not directly loaded when the entity is loaded. Instead, they can be loaded on-demand later (triggering another database call).
Lazy loading simplifies matters on the “O” side of O/RM in that objects are easily available without having to do a lot of back-and-forth with the persistence framework to retrieve the objects needed when they’re needed. Lazy loading comes in two forms: direct and transparent. Direct means that the programmer must initiate the lazy loading directly (by calling the method “LazyLoad()” on the “Orders” property of the “Customer” entity, for example). Transparent means that the programmer can simply start enumerating over the “Orders” collection and the lazy loading will happen automatically without any separate or additional method calls on the object.
Each of these approaches has its plusses and minuses. I have found that, ultimately, transparent lazy loading works best and fits best with my other goal of persistence ignorance. If I have to call things like “LazyLoad()” on my entities, I have allowed persistence concerns to seep into my domain model. With transparent lazy loading, I can use my entities the same way in code whether they’re being serviced from the database or some other data source.
Of course, this doesn’t mean I get to be lazy about lazy loading and ignore the extra performance cost of a potentially unnecessary extra round trip to the database. I balance this against the need for rapid development. When I know that I will need the extra data no matter what, I can signal this to the persistence framework when I’m querying to go ahead and eager-fetch the data that would otherwise be lazy loaded.
Mapping Separate from the Model
Another aspect of a successful O/RM, for me, is that I am able to map between the object model and the relational model separately from either. That is, the relational model should not need to know nor care about the object model and vice versa. This means no attributes on my .NET classes, and no .NET type names in the database, for example.
Thus mapping is, in and of itself, a first-class citizen. It will require maintenance along with the code and the database schema. Without the mapping, neither the objects nor the relational model work very well or accomplish much of anything. Tooling for the mapping is important for me also. The mapping must be easy to create, edit, maintain, etc.
Introduction to NHibernate
One O/RM that particularly stands out and meets every single criterion I mentioned above to one extent or another is the NHibernate framework. NHibernate is a .NET project based heavily upon the Java-based Hibernate framework. Hibernate 1.0 was released in 2002. The 1.0 release of NHibernate occurred in 2005. It had been enjoying decent circulation and usage as a point-release for some time before then, however. NHibernate is about four years old at the time of this writing. That reminds me of another aspect of a good O/RM I look for: maturity. Building a good O/RM is non-trivial and so maturity and staying power is a preferable feature of an O/RM. NHibernate is one of the oldest and most active O/RM frameworks for .NET.
NHibernate leverages ADO.NET under the covers to achieve its data access. This means that it is compatible with various ADO.NET drivers and features. NHibernate composes parameterized statements when interacting with the underlying database connection. NHibernate has a concept of “dialects” and “drivers” for handling the differences and idiosyncrasies of various flavors of SQL (T-SQL, and PL-SQL, for example) and database engines (SQL Server, Oracle, MySQL, and Firebird, to name a few). NHibernate supports an extensive list of database engine platforms, versions, and SQL dialects. One benefit of this is that applications written using NHibernate for their data access can, with relative ease, support multiple database platforms with far fewer changes and reduced testing complexities. In most cases, the difference between supporting Microsoft SQL Server 2005 and Oracle 9i is a single line configuration file change.
NHibernate uses a simple XML configuration file to specify the dialect, driver, connection string, and various other operational options. You can also configure it programmatically using your own configuration mechanism if you prefer not to use XML or you have some other requirement for how you configure your applications.
Typically, you specify the object/relational mappings through XML though there are several other options. Called Hibernate Mapping XML files or “HBM XML” for short, these XML files can be loaded from disk, embedded as a resource in an assembly, or loaded via some other means and passed as an XmlDocument to NHibernate’s configuration API directly.
Finally, after you’ve configured NHibernate at startup, you create a “SessionFactory” (once per application) and use this factory to create “sessions” through which all the important and interesting data access stuff happens. The SessionFactory is thread-safe so you can call it from multiple threads or ASP.NET requests safely.
The NHibernate ISession object is perhaps the most visible part of NHibernate and the piece of the framework with which you will likely be having the most interaction. Logically speaking, the ISession represents an active connection and transaction to the database (though do not directly equate those things as the ISession may manage connections and transactions differently under the covers depending on various factors). A given ISession instance also will have a first-level cache of objects it has recently retrieved from or saved to the database to prevent doing extra duty or having duplicate objects floating around for a particular session. The ISession instance is also the gateway to performing CRUD operations, among other things. We’ll get more into the specifics later in this article.
Getting Started with NHibernate
At the time of this writing, NHibernate’s current released version is 2.0.1. NHibernate 2.1 is under active development and has some exciting new features. For now, though, I’ll concentrate on 2.0.1 which has more than enough features to fill this article and then some.
Downloading NHibernate 2.0.1
NHibernate is an open source project managed along with the Hibernate project (among others). You can get the installation package as well as documentation and links to receive support and guidance via the Hibernate.org Web site:
http://www.hibernate.org/343.html
Before I proceed, I should also mention the growing NHibernate community and suite of contributory/add-on projects. You can learn more about NHibernate, view documentation, and browse related projects at NHForge:
Click on the link to download which should take you to the SorceForge download page. Continue clicking the download links until finally you have a choice between a “bin” and a “src” variant of the NHibernate ZIP file. Download the “bin” variant and unzip it to a folder on your hard drive.
Also inside the ZIP file are two XSD (XML Schema Definition) files. These files enable Visual Studio to help give you IntelliSense and validation as you author NHibernate XML configuration and entity mapping documents in Visual Studio. Copy these files to your Visual Studio installation’s XML schema directory. For Visual Studio 2008, this is usually “C:\Program Files\Microsoft Visual Studio 9.0\Xml\Schemas.” If you have a 64-bit version of Windows, it will be in “Program Files (x86).” Once you copy the XSD files to this folder, Visual Studio will now detect when you start authoring NHibernate XML documents and provide assistance.
Setting Up a Project to Use NHibernate
Once you have obtained all the binaries, create a new solution in Visual Studio and add two new projects: A class library project and a console application project. Add a reference from the console project to the class library project. Add a reference to the console application project to NHibernate.dll from the folder in which you unzipped the NHibernate binaries.
I chose a console application because it is the easiest path to get started and involves the least amount of code. Unfortunately it’s not that useful, so it won’t help you in your real work. However, I think it will get the concepts across faster by not having to mess with other concerns such as Windows Forms or Web requirements.
The next step to getting started with NHibernate is to begin mapping your objects to the database schema. This step is necessary to fulfill the “mapping separate from the model” feature I talked about earlier. NHibernate allows for mapping of many sophisticated situations both from the object and database schema perspectives. Before I proceed, however, I think it is important to stop and talk a little about the domain and then I’ll resume with how to create the domain mappings and finally how to bootstrap NHibernate and begin using it.
The Domain: AdventureWorks LT
The diagram in Figure 1 illustrates the portion of the AdventureWorks LT relational model that I’ll map in this article. The center of the model is the Customer table. Customers have Addresses and Sales Orders. Each Sales Order has a Header with multiple Detail records. You should note that I italicized and capitalized certain words in that last sentence. This is because those words are important to the domain as they represent the key entities as well as describe the relationship between.
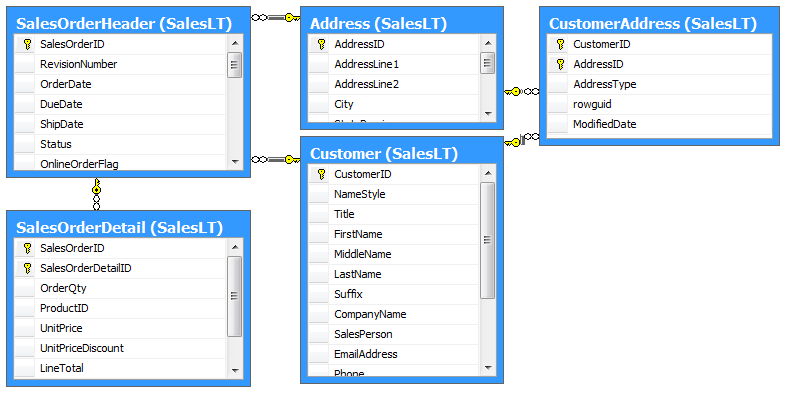
In this article, I’ll show how to map these entities and their relationships with NHibernate as well as how to use NHibernate to persist and retrieve them.
Basic Entity Mapping
NHibernate has the ability to map an object to multiple tables, to a view, and many other combinations. Perhaps the most common type of mapping is simply mapping one object to one table. This is called a “class per table” mapping. The “Address” table in the AdventureWorksLT database is a good place to start as you can map it using the class per table style.
Creating the Entity Object
Let’s start by creating an “Address” class in the .NET project. Create a folder in your project called “Domain” and then add a new class to that folder called “Address.” NHibernate can map properties to columns even when their names are different. In this case, however, the Address table has .NET-friendly column names to keep things simple. Create properties in your Address class that match the names and types of the columns in the Address table. Mark each property with the “virtual” keyword (or “Overridable” if you’re using VB). This may seem odd. I’ll explain why I want to use virtual/Overridable later in this article. When you’re done, your Address class should look something like:
public class Address
{
public virtual int AddressID {get; set;}
public virtual string AddressLine1 {get; set;}
public virtual string AddressLine2 {get; set;}
public virtual string City {get; set;}
public virtual string StateProvince {get; set;}
public virtual string CountryRegion {get; set;}
public virtual string PostalCode {get; set;}
public virtual DateTime ModifiedDate {get; set;}
}
You should note that I did not include a property for the rowguid column in the Address table. This is because rowguid is a special column for SQL Server and should, generally speaking, not be tampered-with by client applications. SQL Server uses it for replication and other internal processes. SQL Server manages this column itself, so you don’t need to map it or otherwise be concerned about it.
Creating the NHibernate HBM XML Mapping File
NHibernate’s primary mechanism for mapping objects to relational structures is XML. I usually refer to these XML mapping documents as “HBM” or “HBM XML” files. HBM stands for “HiBernate Mapping.”
NHibernate’s configuration can take XML mapping documents in a number of different forms (a direct XmlDocument object passed in through its configuration API, a reference to a file on the disk, an assembly-embedded resource, etc.). The most common way to pass mappings to NHibernate, however, is to have your XML documents embedded as resources in an assembly. I usually embed the XML documents into the same assembly as the one where my entity objects are located, but that is certainly not a requirement.
For now, let’s keep things simple. Make a folder in your project called “Mappings.” Create a new XML document file in that folder called “Address.hbm.xml.” The name is not necessarily important, but NHibernate will automatically find all *.hbm.xml embedded resources. If you name your mapping documents differently, you will have to write some extra code to help NHibernate find them. For now, let’s stick with the default convention: *.hbm.xml. It’s also worth mentioning that I prefer the style of having one HBM XML file for each entity. This is not required, however. You can have one big XML file with all your entity mappings in it or you can break it up by whichever grouping you prefer.
After you’ve added the XML file to the project, you need to mark it as an “embedded resource” so the compiler will embed the XML file into the compiled assembly. Select the XML file in Solution Explorer and press F4 to bring up the properties window. Change the “Build Action” property from “Content” to “Embedded Resource.” This is an important step and one that is often forgotten. If you make this common mistake, NHibernate will throw errors and complain that it can’t seem to find any mapping for the entity mapping that is missing.
Once you have the first XML file set up correctly, I recommend adding new XML documents by copying and pasting the original XML document. Visual Studio will also copy properties like “Build Action.” In this way, you will ensure that you never accidentally forget to change the “Build Action” and save yourself a lot of headaches.
Every HBM XML document starts with the “hibernate-mapping” element. To map a class to a table you use the “class” element. Both the hibernate-mapping and class elements take a number of attributes/options-some of which I’ll get to later-but for now I’ll stick to the basics to get going faster.
If your database engine supports the concept of multiple schemas in a single catalog (for example, SQL Server 2005’s “schema” concept), then you will need to configure your mapping to tell NHibernate this. In the LT example, the Address table is in the “SalesLT” schema. Add the “schema” attribute, with value “SalesLT”, to the <hibernate-mapping> element.
The basic shell of your mapping between the Address class and table should now look something like this:
<?xml version="1.0" encoding="utf-8" ?>
<hibernate-mapping
xmlns="urn:nhibernate-mapping-2.2"
assembly="NHibArticle.Core"
namespace="NHibArticle.Core.Domain"
schema="SalesLT">
<class name="Address">
</class>
</hibernate-mapping>
Mapping the ID of the Entity
Remember how I previously wrote that every entity has a unique identifier? In the AdventureWorks LT database, the convention is to use SQL Server identity auto-number columns as the unique identifier/primary key. NHibernate needs to know this important piece of information as the ID of an entity is special compared with other data columns. To map the ID column of a table, use the <id> element. NHibernate needs to know you plan on generating IDs in your system. NHibernate can generate them for you (in the case of GUIDs) or NHibernate can defer to the database system to generate them (in the case of auto-number, sequences, and so on). So every <id> element needs a <generator> child element. To map the AddressID property to the AddressID column using the native database identity generator, you should use the following XML:
<id name="AddressID">
<generator class="native" />
</id>
As a side note, most RDBMS have a “native” or preferred form of generating IDs. For Microsoft SQL Server, this is the identity auto-numbering system. For Oracle, sequences are generally used. Instead of specifically stating “identity” for the <generator> element (which explicitly ties your system to SQL Server), you can use the “native” generator which will instruct NHibernate to automatically use the preferred ID generation system for the underlying database platform. This is important if you ever plan on supporting more than one backend database platform. I have also found that, even if I only have plans to support one database platform, I may still use a different database for testing purposes. For example, if I want to test some particular aspect of my system that involves some database access, I may use an in-memory database like SQLite or Firebird, which is easier to set up and host for quick testing scenarios than SQL Server or Oracle.
Mapping the Properties
Next, I’ll show you how to map the rest of the properties to the rest of the columns on the Address table. You’ll map properties using the <property> XML element. For simple scenarios where the .NET property name matches the column name in the database, you can simply use the “name” attribute on the <property> element and NHibernate will match up correctly. Add a <property> element for each property in the Address class. When you’re done, it should look something like:
<property name="AddressLine1"/>
<property name="AddressLine2"/>
<property name="City"/>
<property name="StateProvince"/>
<property name="CountryRegion"/>
<property name="PostalCode"/>
<property name="ModifiedDate"/>
Now you have one entity and its associated mapping. You’re ready to begin using NHibernate to perform database operations with this entity. The full contents of the Address.hbm.xml file should now look like the contents of Listing 1. In the next section, I’ll show you how to bootstrap NHibernate and begin performing tasks.
Bootstrapping NHibernate
Now let’s switch back to the console application project. I’ll add the NHibernate XML configuration file and then I’ll write some code to bootstrap NHibernate to the point where I actually connect to a database and begin performing operations.
NHibernate Configuration File
In the console application project, add a new XML file called “hibernate.cfg.xml.” Again, this is the default name NHibernate will look for. It isn’t required as there are several ways of configuring NHibernate. This is the easiest and involves the least amount of code, so it’s perhaps the best to start with. Select this new file in Solution Explorer and press F4 to open the properties window for this file. Change the “Copy to Output Directory” property to “Copy Always.” Every time you compile, Visual Studio will copy this XML file to the output folder alongside the EXE file. Next, add a reference to your other project-the one used in the previous section to add the Address entity and its associated mapping HBM file.
NHibernate requires a minimum of four settings to operate:
- The connection provider to use.
- The SQL dialect of the database engine.
- The driver to use for interacting with the database.
- The connection string to use for connecting to the database.
The connection provider (property name “connection.provider”) is always “NHibernate.Connection.DriverConnectionProvider.” This is an extensibility point for NHibernate which is why it’s a setting and not hard coded. Extending NHibernate is a very advanced topic and beyond the scope of this article. For now, I’ll use the value mentioned above.
The SQL dialect translates NHibernate’s intentions into actual SQL statements, accounting for the various peculiarities and non-standard SQL quirks of the database engine and version. Specify this property using the “dialect” key. For SQL Server 2005, the dialect is “NHibernate.Dialect.MsSql2005Dialect.”
The driver manages the underlying Connection object (i.e., System.Data.SqlClient.SqlConnection), command objects, data readers, etc. This property’s key is “connection.driver_class” and, for SQL Server, the default is “NHibernate.Driver.SqlClientDriver.”
The connection string should be familiar to anyone who’s done any ADO.NET programming. This is the connection string which NHibernate passes to the Connection object to initiate the connection to the database server. It uses the standard ADO.NET connection string format. NHibernate does not tamper with this at all. It will pass it directly to the SqlConnection object (for example). The “connection.connection_string” key identifies this property.
- Now that you have a good idea about what the four required configuration parameters for NHibernate are, you can create the XML configuration document. It should look something like Listing 2.
Building the Configuration and SessionFactory
Everything is in place now to start using NHibernate. Just to recap, you should have the following things:
- Two projects in a Solution, one being a console application project.
- An entity class (Address).
- An XML mapping (address.hbm.xml).
- A configuration file (hibernate.cfg.xml).
In your Main() method in your console application project, instantiate a new Configuration() object, instruct it to use the hibernate.cfg.xml file for its configuration, point it to your HBM document, and then build a session factory in preparation for creating a new session. Listing 3 shows the start of the sample console application I used to write this article.
In this example, I have some basic error handling and some handling for when the application ends (so that the console window doesn’t disappear when it’s finished). The main meat is in the middle-where the configuration is loaded, mappings added, and the session factory created.
You only need to perform these tasks once per application at startup. Once you have acquired a session factory, maintain a reference to it for the duration of the application lifetime. The session factory is thread-safe so you can call it from multiple threads or web requests in the context of a web application. You should note that individual sessions created by the factory are not thread-safe. Be careful to ensure that you only access a given session from a single thread and/or web request at a time.
Creating a Session and Connecting to the Database
From the session factory you just created in the previous section, call the “OpenSession” method to acquire a new session. At this point, the session is essentially a live connection to the database and you should treat it as such for the purposes of connection pooling, memory leaks, performance, and other such concerns.
When you open a session, for various reasons, it may not actually connect to the database at first. Instead it may wait until the first time it needs to actually connect. As I said before, treat it as though it is connected by making sure you wrap it with the using() block in C# or a Try/Finally block in VB.
Also, you should always perform database operations with NHibernate through a transaction. Any time you open a session, you should be concerned about transaction management. You can use one transaction / session or multiple transactions per session, but you should always be performing operations within the context of a transaction.
Consider the following code example of opening a session and starting a new transaction while preventing connection leaks by using the using() block:
using (var session = factory.OpenSession())
using (var xaction = session.BeginTransaction())
{
//TODO: work with session and transaction here
}
Basic Create, Retrieve, Update, and Delete
Now that you have an open session and an active transaction, you can begin performing interesting operations such as saving an entity, retrieving it, deleting it, etc. Let’s start by saving a new address.
Saving an Address
Saving an entity is simple with NHibernate once you have a session open. Simply call the “Save” method on the session and pass in the entity to be saved.
var address = createNewAddress();
session.Save(address);
xaction.Commit();
var lastAddressID = address.AddressID;
NHibernate will not actually insert the row into the database table at this point. It will batch up commands. The session will automatically “flush” a batch to the database when it needs to, if you explicitly call Flush() on the session, or whenever you commit a transaction. I’ll cover how the semantics of batching and flush work later in this article. For now, simply commit the transaction to actually flush an address to the database. At the end of the using() block, the session and transaction will close, releasing the connection to the database back to the ADO.NET connection pool.
If you look at the contents of the Address table in the database, you should now see a new row representing the Address you just saved. Congratulations, you’ve successfully saved your first record using NHibernate!
After having saved an entity, NHibernate automatically works with the database to retrieve the ID that the database assigned to that entity and assigns it to the entity’s <id>-mapped property. As an experiment, print out the AddressID of the address entity before and after you save and commit it and you’ll notice it changes from 0 to whatever the next identity number is.
Retrieving an Address by Its ID
Retrieving an entity by its ID is also simple. The Load() method on the session will retrieve an entity by its ID and throw an exception if it does not exist in the database. The Get<T>() (Get(Of T)() for VB) method will retrieve the entity or return null if none was found. I prefer to use the Get method since I prefer not to have throw or trap exceptions for conditions that can otherwise be detected by an “if” statement (seeing as how throwing and catching exceptions is an expensive operation).
For the sake of this example, imagine that this is a separate web request and the user has clicked on a link to load the Address she just saved in the previous request. First, look at the row in the database and copy its AddressID value. Next, in the code, open a new session from the SessionFactory. Next, call the Get<Address>(id) method and pass in the AddressID you just looked up in the database. Assign the return value of the Get call to a variable. Finally, print the AddressLine1 value to the console to verify it all worked.
After you’re done, your code should look something like this:
using (var session = factory.OpenSession())
using (var xaction = session.BeginTransaction())
{
var address =
session.Get<Address>(lastAddressID);
//TODO: Do something with the address here
xaction.Commit();
}
If you got a NullReferenceException, you probably had the wrong AddressID or there was some other problem. Otherwise, you should see the value you originally entered for AddressLine1 when you saved that address.
Updating an Address
Next, let’s take the address you just retrieved from the database, change a property, and update it. Simply modify the AddressLine1 property (or any property except AddressID), and then call the Update() method on the session.
Consider this example:
address.AddressLine1 = "334 Smith Street";
session.Update(address);
xaction.Commit();
Now check the values in the database and you should see that they have changed.
Deleting an Address
Hopefully by now you’re getting the hang of the basics. Deleting an entity is just as easy as the rest of the CRUD operations. Simply call the Delete() method and pass in the Address to delete.
session.Delete(address);
xaction.Commit();
A Little More About the Session First-level Object Cache
Before I proceed on to more complex scenarios and operations, I want to cover a few more important aspects of the Session object.
The session maintains a cache, called the First Level Cache, of all the objects it has saved or retrieved. This cache lasts the duration of the session. You can “evict” an individual object from the cache or clear everything from it. Evicting and clearing the cache is not something you have to worry about for most regular applications and only comes into play for specific scenarios.
The reason the session caches objects is because you may retrieve the same object again or it may be related to another object you’re retrieving and so the session recognizes objects and IDs it already has loaded and prevents excessive and unnecessary database calls. Most of time, this is a benefit and you won’t have to think or worry about it.
Addressing Some Questions
This is usually the point where, when I’m introducing someone to NHibernate, a million questions pop up. I’m guessing that a million questions are swirling around in your mind about all this right now. What about max length on varchar fields? What about custom/user types? What about aggregate functions? What about complex queries? What if I want to delete an entity by its ID without having to load it first? What about projection queries (selecting a subset of fields from one or more tables instead of a single entity from one table)? What about transaction management? What about database X feature Y? What about default values for columns (like the ModifiedDate on the Address table)? What about user-defined types?
NHibernate doesn’t address every situation you’ll run into when interacting with the database, but it does handle most-including the questions above. Unfortunately, I won’t get to all of them in this article. I hope, however, that this article will get you up to speed on the basics and enable you to be able find more specific information about NHibernate as you evaluate it for your project.
More than Just CRUD
So far, I’ve only shown basic CRUD operations with NHibernate. NHibernate can do much more than CRUD, though. Some of NHibernate’s greatest features come into play when managing the relationships between multiple entities. One of the more common types of relationships is the many-to-one relationship. A good example of this in the AdventureWorksLT database is the SalesOrderHeader table foreign key relationship to Customer. You can relate many sales orders to one customer-thus a many-to-one relationship.
From now on, I’ll call many-to-one relationships “MTO” for brevity. The converse of this relationship is a one-to-many (OTM)-one customer can have many sales orders. For now, I’ll start with the MTO side since it’s easier to map with NHibernate and show examples. After that, I talk about the OTM side.
Many-to-One Relationships
Let’s start by creating the Customer object the same way you did the Address object. Remember: leave out the rowguid column to keep things easier. When you’re finished, it should look something like this:
public class Customer
{
public virtual int CustomerID {get; set;}
public virtual int NameStyle {get; set;}
public virtual string Title {get; set;}
public virtual string FirstName {get; set;}
public virtual string MiddleName {get; set;}
public virtual string LastName {get; set;}
public virtual string Suffix {get; set;}
//... and so forth
}
Next, create the SalesOrderHeader object in a similar fashion. The SalesOrderHeader table has a few interesting features on it that, for now, you should just ignore because they are not relevant to this topic. For now, ignore the ShipToAddressID, BillToAddressID, SalesOrderNumber, TotalDue, and rowguid columns.
Remember the basic goal of this exercise is to avoid having to, in the main business code, worry about persistence concerns. Imagine if you were building your app and didn’t have to worry about a database behind it. How would you structure SalesOrderHeader differently? For starters, you probably wouldn’t have a “CustomerID” property, you’d probably have a “Customer” property and its type wouldn’t be Int32, it would simply be “Customer.” You’ll tell NHibernate in the HBM XML how to map the CustomerID column to the Customer property later. Here’s what your SalesOrderHeader class should look like:
public class SalesOrderHeader
{
//... other value properties
public virtual Customer Customer { get; set; }
}
Mapping Customer and SalesOrderHeader
Mapping the Customer object is straightforward and should look like the Address mapping, only with different names and properties. Mapping SalesOrderHeader is similarly straightforward except for a few fields. First, SalesOrderNumber and TotalDue are computed columns in SQL Server and either should not be mapped or should be mapped as read only. For now, to keep things simple, just leave these fields out of your mapping and your class.
The “Customer” property is a little different than the normal fields in the table. As I mentioned earlier, the relationship between SalesOrderHeader and Customer is an MTO, so you need to use a new tag (instead of <property>): <many-to-one>. The <many-to-one> tag needs the property name, the column name of the foreign key in the table (only if it is different from the property name which, in our case, it is).
Add the <many-to-one> tag to your mapping. It should look something like this:
<class name="SalesOrderHeader">
<id name="SalesOrderID">
<generator class="native" />
</id>
<!-- <property> tags here ... -->
<many-to-one
name="Customer" column="CustomerID"/>
</class>
Saving and Updating MTO Relationships
Once you have Customer and SalesOrderHeader created and mapped, you should be able to perform the standard Save/Get/Update/Delete operations just like you did with Address earlier. At this point, in order to create a new Customer and SalesOrderHeader, relate them both, and have them both saved, you’ll have to call Save() on both object instances. NHibernate can do some more intelligent things and cascade-save related entities if you tell it to. I’ll get to the more advanced functionality in a little bit. For now, to relate two objects, you would write code like this:
var customer = createNewCustomer();
session.Save(customer);
var order = createNewOrder();
order.Customer = customer;
session.Save(order);
xaction.Commit();
Retrieving the Related Object
When you retrieve the SalesOrderHeader you just saved, NHibernate will, by default, not get the Customer. Instead, it will use a “proxy” object or a ghost of the Customer. The Customer property on SalesOrderHeader will not be null, but no data is actually loaded yet.
As soon as you access any properties on the related Customer proxy, NHibernate will, at that moment, execute a SELECT statement to retrieve the Customer. This all happens transparently and the code accessing the SalesOrderHeader and/or Customer objects never needs to know that this is happening. This is what I referred to earlier as transparent lazy loading and is an important feature of NHibernate and actually a key differentiator between other O/RM frameworks-many of which do not support transparent lazy loading.
Note that I said, this all happens by default. Certain relations may call for no lazy loading (for example, always load the Customer whenever you load the SalesOrderHeader). You can, in specific situations, tell NHibernate to get a related object or related objects when getting another object. For example, you might want to load a collection of objects for one specific query with lazy-loading disabled.
This concludes part 1 of this article about using HNibernate. You have learned why you want to use NHibernate, techniques for configuring NHibernate, how to map your objects to your data entities, and how to load basic objects. In part 2 you'll learn more advanced NHibernate concepts including configuring more advanced object relationships, managing lazy loading, and concepts for sorting and filtering data using NHibernate.
Listing 1: Address.hbm.xml
<?xml version="1.0" encoding="utf-8" ?>
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2"
assembly="NHibArticle.Core"
namespace="NHibArticle.Core.Domain"
schema="SalesLT">
<class name="Address">
<id name="AddressID">
<generator class="native" />
</id>
<property name="AddressLine1"/>
<property name="AddressLine2"/>
<property name="City"/>
<property name="StateProvince"/>
<property name="CountryRegion"/>
<property name="PostalCode"/>
<property name="ModifiedDate"/>
</class>
</hibernate-mapping>
Listing 2: An hibernate.cfg.xml file
<?xml version="1.0" encoding="utf-8" ?>
<hibernate-configuration xmlns="urn:nhibernate-configuration-2.2">
<session-factory>
<property name="connection.provider">
NHibernate.Connection.DriverConnectionProvider
</property>
<property name="dialect">
NHibernate.Dialect.MsSql2005Dialect</property>
<property name="connection.driver_class">
NHibernate.Driver.SqlClientDriver</property>
<property name="connection.connection_string">
server=.;
database=AdventureWorksLT;
trusted_connection=True;
</property>
</session-factory>
</hibernate-configuration>
Listing 3: Sample application Program/Main
using System;
using NHibArticle.Core.Domain;
using NHibernate;
using NHibernate.Cfg;
namespace NHibArticle.ConsoleApp
{
public class Program
{
static void Main(string[] args)
{
try
{
var config = new Configuration();
config.Configure();
config.AddAssembly(typeof(Address).Assembly);
var factory = config.BuildSessionFactory();
//TODO: NHibernate access code here
}
catch (Exception ex)
{
Console.WriteLine(ex);
}
Console.WriteLine(
"Program finished. Press RETURN to finish.");
Console.ReadLine();
}
}
}
