


As I continue to work on my next major article on Data Warehousing, I want to take a break and do a little post-mortem on a database programming challenge I recently faced. It was a quiet Saturday afternoon, and I honestly thought it would take no longer than an hour to write a SQL query to aggregate some data for specific ranges of time. Unfortunately, I was a little too confident, and it wound up taking me the better part of a day (with interruptions). I finally came up with a solution, then reviewed a pattern I hadn't considered, and finally wound up simplifying my solution. So, what started as a seemingly mundane task became an unexpected learning experience.
This is a Humbling Industry
I started in this industry in 1987. Along the way, I've had significant flashpoints, both positive and negative. I've also heard some profound quotes. In 2003, I overheard a debate between Developer A and Developer B. Developer B felt that Developer A was excessively over-confident about a situation, and Developer B said something I'll never forget: “This is a humbling industry. You really need to be careful, that's all I'm saying.” As it turns out, Developer B was right, as Developer A indeed experienced a crisis for which the term “hubris” aptly applied.
I have 30 years of experience and have worked in four decades. I'm fortunate that I've worked on many systems and have had many successes (and failures to learn from). When you approach a certain level of experience, it's a never-ending “Catch-22.” Clients often seek those with meaningful experience, but experience has a way of backfiring if you become too cocky. Most of us have seen developers whose arrogance wound up backfiring, but even honest and sincere veterans can fall victim to it, even in isolated situations. That happened to me a few weekends ago, and it reinforced that no matter how much I might want to pride myself on being able to solve database programming puzzles, there will always be humbling experiences and always someone who knows more!
Step 1: Defining the Problem and the Desired Outcome
How many times have you heard this: “What is it you're trying to accomplish?” At the risk of stating the obvious, defining the problem or goal in the simplest terms possible is essential to building a solution.
At the risk of stating the obvious, defining the problem or goal in the simplest terms possible is essential to building a solution.
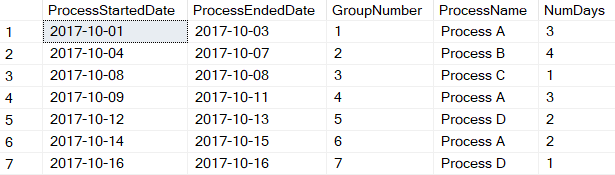
The siuation I faced is too intricate to cover in its entirety in an article, so I'll strip it down to the bare essentials. I can best simplfiy the challenge I faced in an image. Suppose you have an order that goes through the processes shown in in Figure 1.

Here's the goal: Produce the result set shown in Figure 2 that reflects each stage:
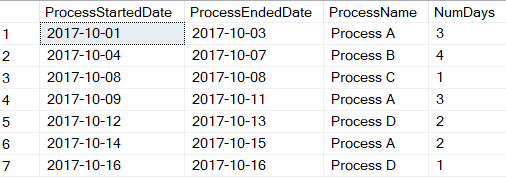
Initially, I thought this would be incredibly easy. Well, once in a while, our prior experiences can haunt us, if we mistakenly conclude that the new challenge follows the pattern of past successes. After my first query failed miserably (so miserably that I won't humiliate myself here), I stepped back and realized that I'd need more than just a simple MIN/MAX/GROUP BY.
Moving On, My Next Step: Grab for a Branch, Any Branch!
I realized that I needed to break this down into a few steps. I started with something simple. When you feel like you're falling from a tree, you grab the first branch that you can!
I needed to detect, for any given day, the process for the following day. That seemed to be the only way to establish the “breaks” in process that would ultimately lead to the final result. So, I did what you can see in the next code snippet, and directed the results to a table (TempResult1_GetNextDay). Note that I used the LEAD function, which Microsoft added in SQL Server 2012. (For those using older versions of SQL Server, or another database, you could perform a SELF-OUTER-JOIN to the same table, varying the date by one day, to get the Process for the next day.)
SELECT *, LEAD(ProcessName, 1) OVER
(ORDER BY ProcessDate) AS ProcessNextDay
INTO TempResult1_GetNextDay
FROM ProcessRows
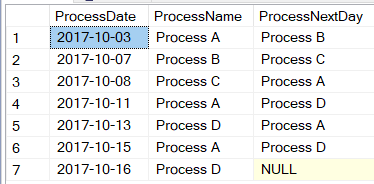
If you're not familiar with the LEAD function, let's go back to the data in Figure 1. For the row with the ProcessDate of 2017-10-03, I also want to store a value for the process on the next day (Process B). Alternatively, for the row with the ProcessDate of 2017-10-04, I could store a value for the process on the prior day (Process A.) Either way, having that value for the next/prior day allows me to easily see when the process changes by day. The LEAD function allows me to “skip forward” one row, based on the order of Process Date, to grab the Process Name for the next row:
LEAD(ProcessName, 1) OVER
(ORDER BY ProcessDate) AS ProcessNextDay
That produces the results in Figure 3. Now that I've identified the “breaks,” take a look at 2017-10-03, which is the last day of Process A, because the following day it changed to Process B. Yes, I could have used the LAG function instead to create “ProcessPreviousDay” and identified the breaks that way. Either way, there are seven instances where the ProcessName differs from ProcessNextDay, and that's the key to creating the seven groups for the final result set.
I could have used the LAG function to create “ProcessPreviousDay” and identified the breaks that way.

Now You Can Identify the Groups
From Figure 3, where I see the days where the process is about to change, I can query the rows from TempResult1_GetNextDay, but only for those rows where the ProcessName and ProcessNextDay are different (or the ProcessNextDay is null).
Now You See an Opportunity to Line the Data Up!
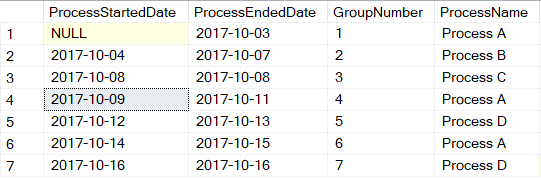
I can read from Temp1Result_GetNextDay and manipulate the dates to produce a result set that I truly covet right now in Figure 5: lining up the start/end date for each process phase. I can use the LAG function to skip “back” one row for a new phase, to get the process start date for that phase.
Here's the code for Figure 5.
SELECT DATEADD(d,1,LAG(ProcessDate,1)
OVER (ORDER BY ProcessDate))
as ProcessStartedDate ,
ProcessDate AS ProcessEndedDate ,
RANK() OVER (ORDER BY ProcessDate)
as GroupNumber , ProcessName
INTO TempResult2_GetGroups
FROM TempResult1_GetNextDay
WHERE ProcessName <> ProcessNextDay OR
ProcessNextDay IS NULL
Note that I used the RANK function to produce a GroupNumber column. This isn't required for the final result set: It was merely for reference purposes while testing. Now I have a second intermediate result set: TempResult2_GetGroups. Now that I have the start/end dates lined up, I can calculate the elapsed days for each phase. Almost!
Note that back in Figure 5, there's a NULL value for the Process Started date for the first phase. That's because I used the LAG function to go backward before the first row. You can generate another intermediate result set (TempResult3_GetGroups) and grab the first process date from the original table for that process using a correlated subquery. That gives the results in Figure 6.
select ISNULL(ProcessStartedDate,
(SELECT MIN(ProcessDate) FROM ProcessRows Inside
WHERE Inside.ProcessName = Outside.ProcessName))
AS ProcessStartedDate, ProcessEndedDate, GroupNumber, ProcessName
INTO TempResult3_GetGroups
FROM TempResult2_GetGroups Outside
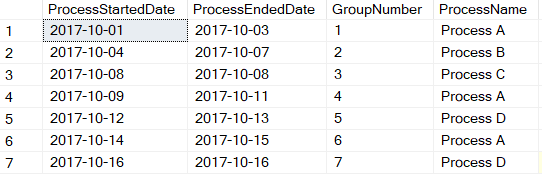
Finally, the end of the journey! I can use the DATEDIFF function to get the elapsed days for each phase, which gives the final result shown in Figure 7.
SELECT *,
DateDiff(d,ProcessStartedDate,
ProcessEndedDate) + 1 as NumDays
FROM TempResult3_GetGroups
Listing 1 contains the full query, without the use of the temporary result sets.
Listing 1: My first attempt
;with TempGroupingsCTE as
(SELECT DATEADD(d,1,LAG(ProcessDate,1) OVER
(ORDER BY ProcessDate)) as ProcessStartedDate ,
ProcessDate AS ProcessEndedDate , ProcessName, ProcessNextDay
FROM (SELECT *, LEAD(ProcessName, 1) OVER
(ORDER BY ProcessDate) AS ProcessNextDay FROM ProcessRows ) Temp
WHERE ProcessName <> ProcessNextDay OR ProcessNextDay IS NULL),
IntermediateResultCTE AS
(SELECT ISNULL(ProcessStartedDate, (SELECT MIN(ProcessDate)
FROM ProcessRows Inside
WHERE Inside.ProcessName = Outside.ProcessName))
AS ProcessStartedDate, ProcessEndedDate, ProcessName FROM TempGroupingsCTE Outside )
SELECT ProcessStartedDate, ProcessEndedDate, ProcessName,
DateDiff(d,ProcessStartedDate, ProcessEndedDate) + 1 as NumDays
FROM IntermediateResultCTE
At that point, I thought I was done. I gave myself an “A” for effort but a “D” for not correctly recognizing the actual pattern of data at the beginning. The more you can recognize, define, and apply patterns, the more effective you'll be.
The more you can recognize, define, and apply patterns, the more effective you'll be.
Another Approach:
After I came up with a solution, someone alerted me to a pattern that I freely admit I completely overlooked: a pattern known as “gaps and islands.” The great SQL author Itzik Ben-Gan (http://tsql.solidq.com/) has covered this pattern in his books. If you search his name and the keywords “gaps and islands,” you can find many online references where he (and others) have covered this pattern. Here is one such link: http://www.itprotoday.com/microsoft-sql-server/solving-gaps-and-islands-enhanced-window-functions.
The “gaps and islands” pattern covers real-life business process scenarios with a range of sequence values, breaks in sequences, and gaps/missing values. Islands are essentially unbroken sequences, delimited by gaps. My example is one that falls under the gaps and islands pattern, where a traditional MIN/MAX/COUNT/GROUP BY won't suffice. The pattern uses different combinations of the LAG/LEAD and ROW_NUMBER functions across different groups/partitions. Sometimes it can be difficult to truly absorb the application of the pattern, until you face an actual example with your company's data.
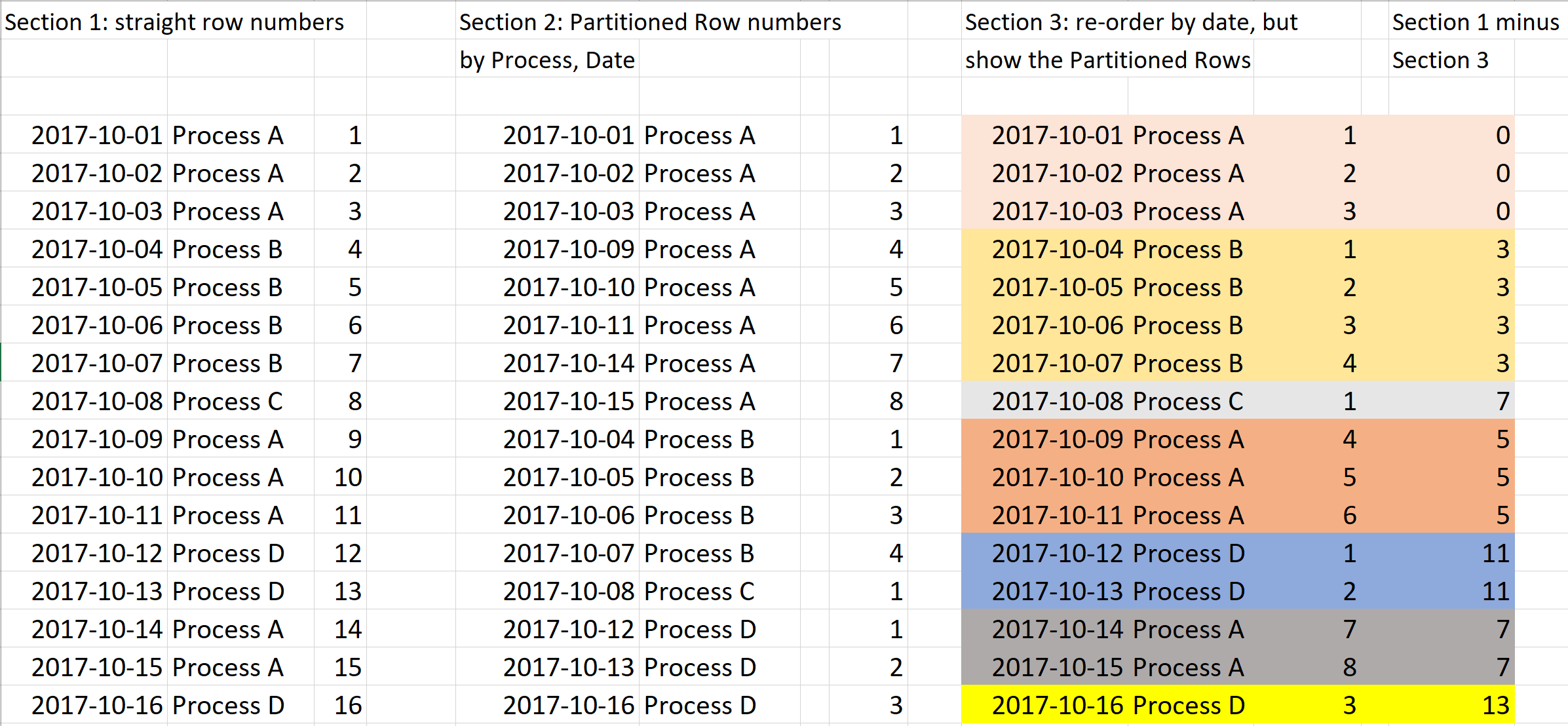
Let's go back to the original result set, which I show again in Figure 8. In Section 1, I show each day and process and the SQL Server ROW_NUMBER function to generate a unique row number by day. Then in Section 2, I re-rank each row by Process and Day, so I've temporarily ordered and ranked the rows to show days one through eight for Process A, even though one set occurred from 2017-10-01 to 2017-10-03, another set occurred from 2017-10-09 to 2017-10-11, and then a third set from 2017-10-14 to 2017-10-15. Each Process and Day now has a second ranking value.
In Section 3, I list the rows back in the original order of day, but then I subtract each row's value from Section 2 from each row's value in Section 1. The resulting number itself is meaningless, but it represents a value that I can use to determine each consecutive set of days on which a specific process occurred. If you remember from my first solution, this is the key to solving the problem. In this case, NOW I can grab the minimum and maximum values for each group, and count the number of days in the group!
Listing 2 shows an adaptation of the pattern.
Listing 2: An adaptation of the “Gaps and Islands” pattern
;with TempCTE as
(SELECT *, ROW_NUMBER() OVER (ORDER BY ProcessDate) ?
ROW_NUMBER() OVER (PARTITION BY ProcessName ORDER BY ProcessDate)
as GroupNumber
FROM ProcessRows)
SELECT MIN(ProcessDate) as StartDate,
MAX(ProcessDate) as EndDate,
COUNT(*) as NumRows, ProcessName
FROM TempCTE
Group by ProcessName, GroupNumber
order by StartDate;
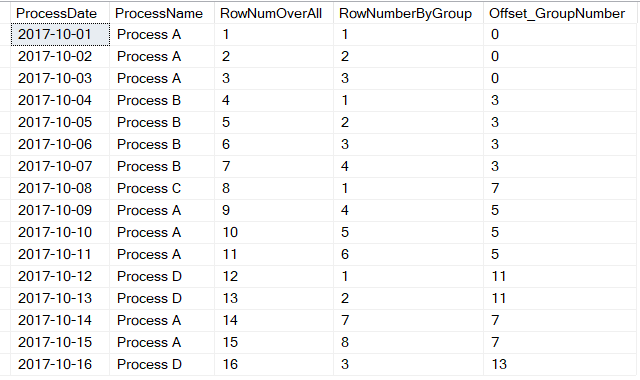
As you saw from my first solution, one of the keys was identifying the groups/breaks. The gaps/islands approach identifies groups differently, by using the ROW_NUMBER function first for the overall set of rows, and then within a specific process (Figure 8):
;with TempCTE as
SELECT *,
ROW_NUMBER() OVER (ORDER BY ProcessDate) as RowNumOverAll ,
ROW_NUMBER() OVER (PARTITION BY ProcessName
ORDER BY ProcessDate) as RowNumberByGroup,
ROW_NUMBER() OVER (ORDER BY ProcessDate) ?
ROW_NUMBER() OVER (PARTITION BY ProcessName ORDER BY ProcessDate)
as Offset_GroupNumber
FROM ProcessRows
Once I've built a temporary result set, THEN I can grab the MIN/MAX values and group by each Process Name and Group Number. Note that the math of the group number isn't relevant: The value of 5 or 11, in itself, has no meaning. It's just that EVERY ROW in that sequence has an overall row number and a group row number whose difference is the same. That's the key to this particular pattern!
SELECT MIN(ProcessDate) as StartDate,
MAX(ProcessDate) as EndDate,
COUNT(*) as NumRows, ProcessName
FROM TempCTE
Group by ProcessName, GroupNumber
order by StartDate;
Which Approach is Better/Faster?
After I saw the gaps and islands pattern, I was a little embarrassed that my solution, although functional and reliable in this situation, was more verbose and arguably less elegant than the gaps and islands approach with the rownumber offset calculation. But is it faster?
As it turns out, not necessarily. The SQL Server ranking functions come at a bit of a cost, as the cost of the second solution is higher than the first, and a review of the time and IO statistics show that the second solution is a few milliseconds faster. However, the elegance and shorter code of solution 2 might still be worth it.
A Final Word: The “Row-by-Row” Approach
Database veterans will tell you (and rightly so) that set-based approaches are the best, and that row-by-row approaches usually won't scale. There's a classic argument in SQL Server about the use of cursors. As a general rule, the practice of using cursors is discouraged, for good reason: They can be very resource-intensive, slow, and can generate resource errors if you abuse them. It can be very tempting to revert to a cursor and handle the logic here “row-by-row.” Given that my situation dealt with a huge number of rows, cursors were never a viable approach. There's usually going to be a set-based pattern to apply to your situation; the more you use them and research them, the more you can leverage them in the future.
Final Thoughts:
I hope I've provided some information to help you in building SSRS reports. In future articles, I'll continue to show different SSRS power tips. As a SQL Server/Business Intelligence contractor/consultant, I've always found that working near the report layer helps me to understand the breadth and depth of the client's business application. Users always want functionality that the product doesn't provide out of the box, so the value of SSRS depends on whether the tool provides enough hooks or open architecture for developers to extend it. Overall, SSRS does a very good job here.
