





This article introduces a few of the coolest features in RavenDB 2.5, but before I get to the stuff that will make you drool, there is a slight possibility that you aren't familiar with RavenDB. The next section fixes that, and then I will go into what is new and cool.
RavenDB Introduction
RavenDB is a document database. Unlike relational databases, which you have been over-exposed to, RavenDB does not maintain the data in tables. Instead, it stores the information as documents.
Figure 1 illustrates the Northwind Schema. You have probably seen this database countless times, which is why I am going to use if for the rest of this article. Figure 2 shows how the same data is represented in RavenDB.
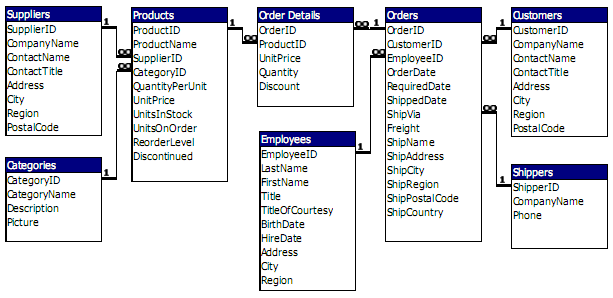
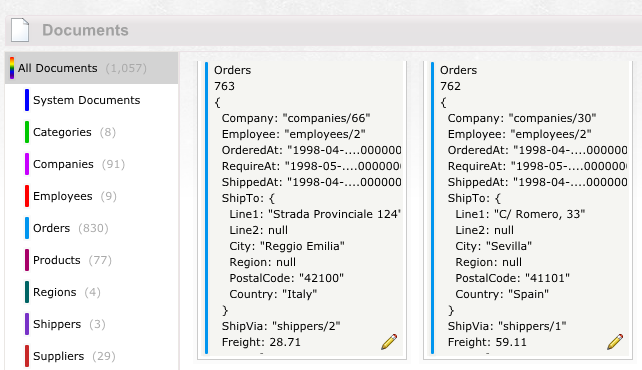
There are a few things to note here. For instance, the information is not tabular. Even in the brief look you get in Figure 2, you can see that the data is stored as JSON (Java Script Object Notation), and that you can store arbitrarily complex information in there.
Figure 3 shows a sample of just one such document.
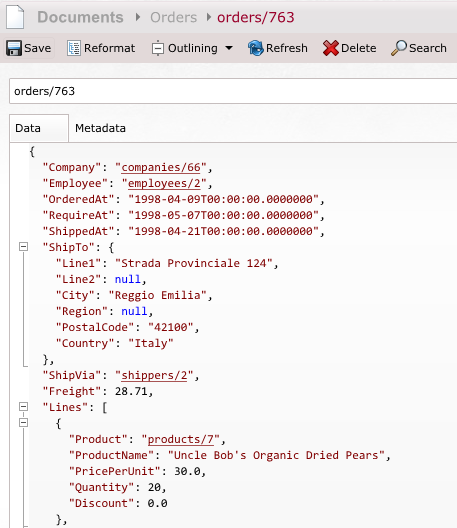
Unlike a relational database, you store all of the relevant information about a document inside the document itself. That means that if you want to display an order to the user, all you need to do is execute a single call to the server to load a document by ID. As you can imagine, loading a document by ID is about the most efficient way to go about getting data from RavenDB.
But speed and performance take a secondary role here. With RavenDB, you model data using Domain Driven Design (DDD) principles. You model documents as aggregates, and you talk about aggregate references and value objects. For example, as you saw in Figure 2, you have the order lines embedded inside the order document. That means that when you load the order document, you already have all of the order lines, with no extra trips or joins required. So far, this is all good for reads, but what about writes?
Well, let's think about it. Documents, like aggregates in DDD, serve as the consistency boundary. When you want to add a new order line, you load the order document, add a new line item, and save. The code for doing just that is shown in the following snippet.
using(var sesion = documentStore.OpenSession()) {
var order = session.Load<Order>("orders/786");
order.Lines.Add( new OrderLine {
Product = product.Id,
ProductName = product.Name,
PricePerUnit = product.PricePerUnit,
Quantity = 4
}); session.SaveChanges();}
As you probably already figured out from the code snippet, RavenDB implements a Unit of Work and Change Tracking. All you need to do is call SaveChanges, and the changes made to the order will be persisted to the database.
That has been just the barest of introduction, I know. My article from Code Magazine, April 2012, “Getting Started with RavenDB,” is available here: http://www.code-magazine.com/Article.aspx?quickid=1203041, and I recommend reading it if you aren't already familiar with RavenDB.
Getting to the Good Stuff
The RavenDB project started in 2008 (has it been that long?), and saw its first release in May 2010. The 2.0 release was in January 2013. The 2.5 release is “nearly 3.0”, and contains quite a bit of new functionality. Mostly, the new stuff is divided into several broad categories:
- New capabilities (unbounded streams, dynamic reporting, SQL Replication, and lots more)
- Improvements (better performance, easier management)
- Operations (better support for ops teams and production)
Probably the shiniest stuff is with the new capabilities, so let's look at that first.
Result Transformers
RavenDB stores information as JSON. That means that when you save something into RavenDB, you save a JSON document, like the one shown in Figure 3. When you load the data from RavenDB, it is the same document that you put in there.
But RavenDB isn't limited to just storing and retrieving your data (if that was the only thing it did, the file system would serve just as well). RavenDB understands your data, and can actually do a lot of interesting things with it. Obviously, it can index that, so you can have speedy searches, but that is something that I will discuss later.
RavenDB can transform results on the server side, allowing you to project the data easily and efficiently. Let me show you.
Let's say that you want to show a list of the customer names. You probably just want to show the user a combo box, so there is no need to load whole documents from RavenDB. Instead, you are going to write a results transformer that gives you just the data you want.
The code for that is shown in the following snippet:
public class IdAndNamesOnly : AbstractTransformerCreationTask<Customer
{
public IdAndNamesOnly()
{
TransformResults = customers =>
from customer in customers
select new { customer.Id, customer.Name }
}
}
You create the result transformer on the server the same way you create indexes: by calling IndexCreation.CreateIndexes(). And now that you have it, let's see how you actually make use of it:
var customers = session.Query<Customer>()
.TransformWith<IdAndNamesOnly, IdAndName>()
.ToList();
Now, I think you'll agree that this is a lot of effort just to pull a couple of properties from a document, right? Well, you can do it more easily if you just wrote:
var customers = session.Query<Customer>()
.Select(c => new IdAndName{ Name = c.Name, Id = c.Id })
.ToList();
This will have the exact same effect as the previous code. Only the name and ID are sent over the wire, and the project is executed on the server side.
So this new feature is a multistep, more complex method to do something that you already could do easily and naturally? Not quite. The good thing about result transformers is that they aren't limited to trivial cases; in fact, as you saw, there is really no need to make use of them for the trivial stuff.
Let's look at a more interesting example. Take a look again at Figure 3; did you notice that you don't have the company and employee names embedded in the document? If you want to get those names, you have to load those values.
In previous versions of RavenDB, you could use Include() to get those documents in your query as well. You didn't have to make multiple roundtrips to the server, but you had to send the entire document over the wire. Take a look at the following snippet, and you'll see a really elegant way to solve this.
public class OrderHeaderTransfomer : AbstractTransformerCreationTask<Order>
{
public OrderHeaderTransfomer()
{
TransformResults = orders => from order in orders select new {
OrderId = order.Id,
order.OrderedAt,
CustomerName = LoadDocument<Company>(order.Company),
EmployeeName = LoadDocument<Employee>(order.Employee)
}
}
}
As you can see, result transformers aren't limited to the document you operate on: they can touch additional documents, and project any and all that information from the server and into your hands.
Result Transformers allow you to transform documents on the server side, including merging data from multiple documents in a single request.
I should point out that this isn't a join, and it isn't going to suffer from any of the standard join's ills. This is fast, regardless of the amount of data in the database; you don't have to worry about issues like Cartesian products or how to deal with paging.
So now that you learned about how to get partial data from RavenDB, let's talk about how you can put partial data into RavenDB.
Scripted Patching
RavenDB had patching support for a while. You could go into the server and ask it to increment this property value, or to rename a property, etc. But a new and a welcome feature is the ability to write scripts that can operate on the data. Because the data format for RavenDB is JSON, it is natural that the scripting language is JavaScript.
Figure 4 shows such a script, and a bit of what it can do. The script records the total amount of all the purchases made in this order and places it in the Total Property.
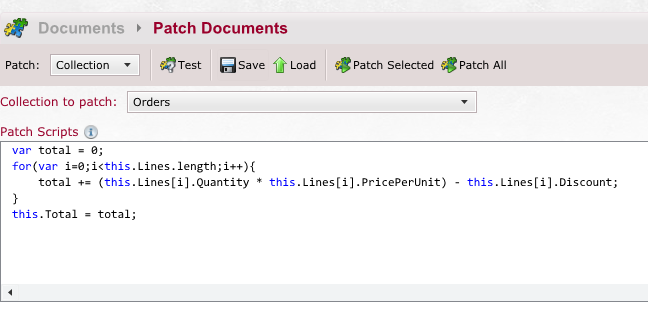
This is very useful for things like migrations, obviously, but it can also be used from your code to make targeted modifications to specific documents. For example, the following snippet shows how you can add a new order line to an order without loading it first.
documentStore.DatabaseCommands.Patch("orders/786", new ScriptedPatchRequest
{
Script = "this.Lines.push(line);",
Values =
{
{
"line", new OrderLine
{
Product = product.Id,
ProductName = product.Name,
PricePerUnit = product.PricePerUnit,
Quantity = 4
}
}
}
});
The Patch API also allows you to load additional documents, so you can pull data from them. For example, you might load the associated company document and store the company name inside the order document in such a script.
I should emphasize that you should really use the patching API for special cases, such as if you need to concurrently update a document, or have a big document that you need to update just one part of. For the most part, loading the document, modifying it in place and changing it are going to be faster and easier to work with.
This is a tool with a specific purpose, not something that you should use on general principal.
SQL Replication
I started building RavenDB because I wanted to give developers a better tool to store their data for OLTP applications. Because I had quite a lot of experience in building those, and a wealth of experience in all the different ways that relational databases made building OLTP applications hard, my path was quite obvious.
But although I honestly believe that RavenDB should be the first choice for any OTLP application, those aren't the only ones around, and even if you have the luxury of green field development, you probably have to deal with at least a few RDBMS that you need to integrate to some level.
Recognizing that fact, RavenDB comes with SQL Replication option. You can set up RavenDB so that whenever you make a change to a document, it also takes those changes and writes them to a relational database.
How does this work? RavenDB documents are arbitrarily complex objects; you can't just copy them to a relational database. The information that you have in the Order document, for example, reside on several tables in the Northwind database. The answer to the problem, again, is that you can use scripts to tell RavenDB how to properly replicate that information.
You can see a sample script like that in Figure 5.
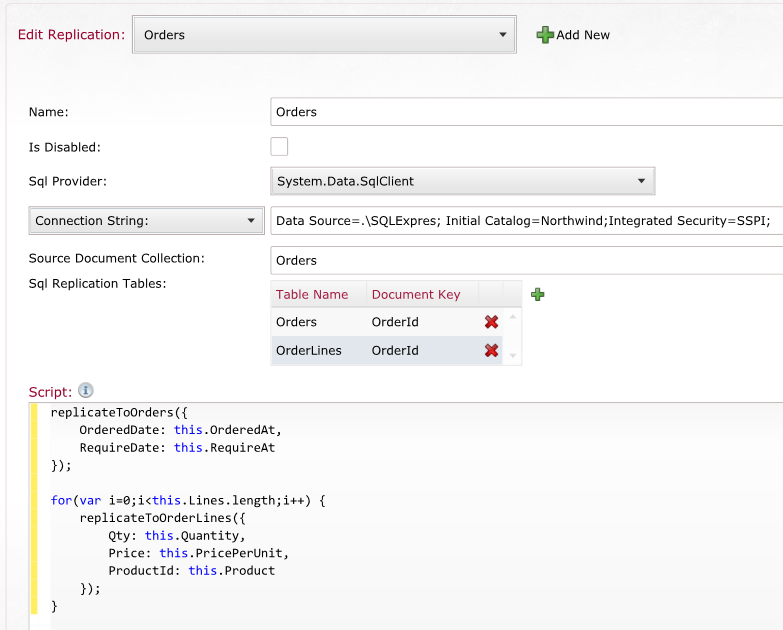
The replication script takes a document and lets RavenDB know what data goes where. After that, RavenDB takes charge of it and whenever your document is updated, the relevant information is updated on the RDMBS side, without you having to lift a finger.
This opens up some really interesting possibilities. Most of you aren't working on brand new projects, and it is hard, if not impossible, to make a change as fundamental as replacing a database midstream. What this feature means is that you don't have to.
You can switch only parts of your application to use RavenDB, usually the most heavily used pages, where the performance boost would really be useful. Those pages read and write to RavenDB, which writes to your existing relational database. The rest of the application still finds all the data in the familiar place.
This type of change is called Write Behind Caching, and is a great way to introduce RavenDB into your projects. Using RavenDB this way, you don't have to deal with fears about having to replace your entire stack. Instead of looking like a loon, you are suggesting a concrete fix to a problem by simply adding a cache. You'll get all the benefits of using RavenDB, but without the need to be a corporate politics ninja.
Unbounded Streams
In the previous section, I mentioned that one of the reasons that RavenDB got started was that I were oh so tired from having to face the exact same issues in every application that use relational databases.
One of those common issues was that of unbounded result sets. I have seen altogether too many applications loading a hundred thousand rows into memory, only to throw 99,975 of them away and show just the first 25 rows.
For example, they would do something like this:
// load 100,000 records to memory, but grid only show first 25!
Grid.DataContext = session.Query<Customer>().ToList();
With that in mind, all requests in RavenDB came with a limit. If you didn't specify a limit, RavenDB limits the result set, by default, to 128 results. Of course, that immediately led developers to write the following code:
Grid.DataContext = session.Query<Customer>()
.Take(int.MaxValue) // fix RavenDB bug
.ToList();
So we also have an upper limit: by default, this configurable limit meant that you could only get 1,024 results out of RavenDB in a single request.
In general, I am very happy with this policy, and it has saved some developers quite a lot of painful surprises in production. However, there are cases when you want to get all of the data from the database. Those cases almost always boil down to some sort of an export. Maybe you need to generate a big report, or need to move the data to a different system, or something of that sort.
RavenDB 2.5 provides support for such unbounded result sets. It's done in a way that maintains safety. The following snippet shows the code to read all of the active companies in the database.
using (var session = store.OpenSession())
{
var query = session.Query<Company>()
.Where(x => x.Active);
var enumerator = session.Advanced.Stream(query);
while (enumerator.MoveNext())
{
Company c = enumerator.Current.Document;
// do something interesting with this company
}
}
As you can see, there is a separate API for unbounded reads. But why provide such an API, and why use IEnumerator instead of IEnumerable?
Because Streams can be of any size, you may be reading ten million documents, and that is something that you want to do concurrently with the server sending the data to you. The way Streams work, the server starts sending the data, and the client starts processing it at about the same time. Because RavenDB uses a streaming approach, you don't need to have a big buffer of data in memory, or have to wait for the entire dataset to get to the client to start doing something with it.
Streams are quite powerful, but they are a tool for a specific purpose.
Dynamic Reporting
Reporting is something that you don't usually do on OTLP systems. In general, the recommendation has always been to have two systems, one for transaction processing and one for reporting (OLAP). That's what RavenDB recommends, use RavenDB as the OLTP database and use something like SQL Replication to send the data to a reporting database.
While that works quite nicely, there are still times when you want to do a little bit of reporting on top of your OLTP database. Up until RavenDB 2.5, you handled such scenarios by defining Map/Reduce indexes and querying on them. And that works quite nicely, but it limited your queries to predefined paths. Figure 6 shows such an index.
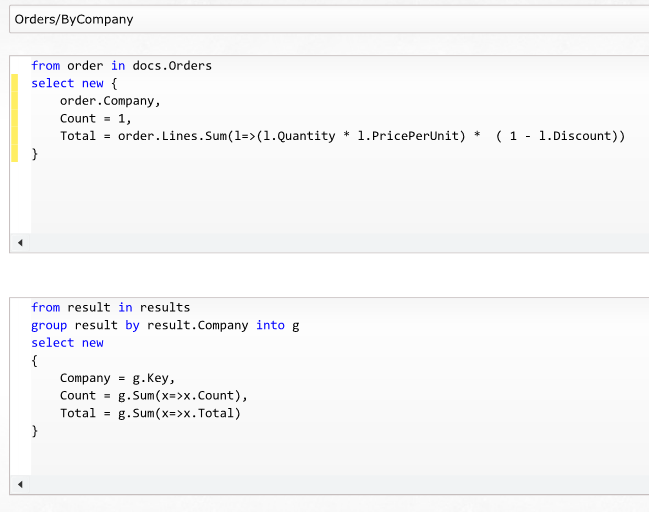
Using such an index is actually a really efficient way to aggregate information. RavenDB maintains the index for you, and pre-computes all of the results. When you query this index, you aren't actually performing any computation, just getting pre-computed. As you can imagine, this is very efficient.
The problem with this approach is that it works as long as what you want is fairly static. If you want to report sales by employee per company, you cannot use this index. In fact, you need to create a completely new index. This makes dynamic reporting cumbersome.
Dynamic teporting allows you to run aggregation on query results in an efficient manner. It is the one feature in RavenDB that allows computation during query.
With RavenDB 2.5, there is a nice story of doing dynamic reporting. Start from the index shown in Figure 7.
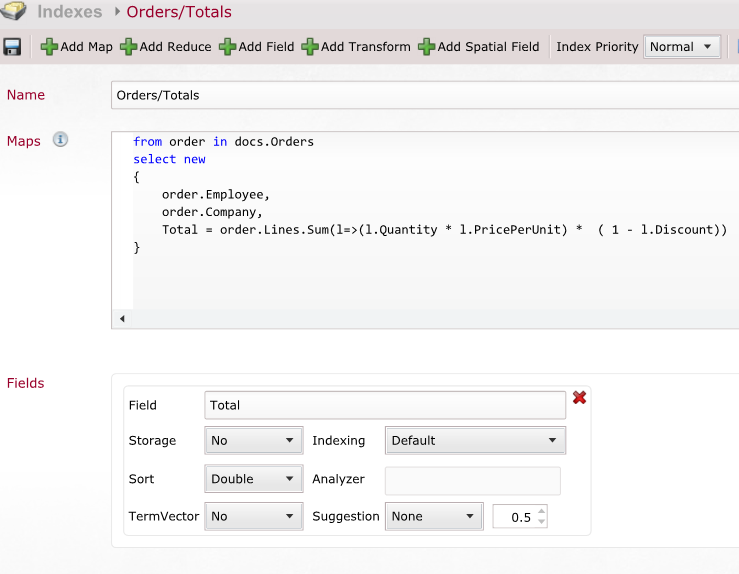
Note that you sum up the order's total, and you tell RavenDB that you should sort that value as double. This is important, because the dynamic reporting feature needs to know how to treat this value.
With this index, you can now issue a variety of reporting queries. For example, let's say that you wanted to know the total sales for each employee, the following snippet shows how to do just that.
var result = session.Query<OrderTotalResult>("Orders/Totals")
.Where(x => x.Company == company)
.AggregateBy(x => x.Employee, "Sales By Employee")
.SumOn(x => x.Total)
.ToList();
foreach (var facetResult in result.Results)
{
Console.WriteLine(facetResult.Key);
foreach (var singleResult in facetResult.Value.Values)
{
Console.WriteLine("\t{0}: {1}", singleResult.Range, singleResult.Sum);
}
}
The output of this snippet is:
Sales By Employee
employees/1: 845.8
employees/3: 933.5
employees/4: 878
employees/6: 814.5a
Note that those are the results for a specific company. You can also get results for all companies (or globally), or any query that comes to mind.
The downside of dynamic reporting is… well, they are dynamic. What this means is that unlike Map/Reduce indexes, the usual way to do reporting, they do require computation. And that makes them somewhat more expensive than the alternative.
That doesn't mean that you shouldn't be using them. In fact, you'll likely not notice a difference unless you are dealing with very large result sets. Even then, like all queries in RavenDB, dynamic reporting reports come from the HTTP cache, so you'll only need to pay the cost of actual aggregation when the data changes or you issue a completely new query.
Concurrent Writes and the Disposal of the Write Lock
Before RavenDB 2.5, Raven DB had an internal write lock that serialized all writes to a specific database on the server side. RavenDB needed this for internal housekeeping reasons
This limitation is removed in RavenDB 2.5, and now you have completely concurrent writes at the database.
The implication, of course, is that you are going to have better performance for writes, but need to be aware of concurrency exceptions if you have two threads updating the same document. That has always been an option, of course, but making writes completely concurrent make it more likely to happen.
Standard modeling techniques in RavenDB already dealt with that, so that isn't likely to affect you.
Indexing Optimizations
RavenDB indexes do quite a bit more than you might expect. Instead of just speeding up searches, you can use indexes for all queries. In fact, whenever you query, you must do so on an index. Indexes provide ways to do full text searches, spatial queries, map/reduce; and a lot more.
As you can imagine, indexes are pretty important for us. And in RavenDB 2.5, there some significant upgrades to the way indexes work. Like in the previous section, you mostly won't see those changes, just feel their impact.
For example, indexes now index directly to memory, and only flush to disk when they are finished working. This has the nice side effect of significantly improving the time it takes to index documents.
Another important change is that the query optimizer in RavenDB is now much smarter and a lot more active. It can merge indexes if they are overlapping, to reduce the load on the system. It detects and deprioritizes inactive indexes and, in general, is more active in its role of ensuring that your RavenDB applications will be tuned to your specific needs.
Summary
In this article, I listed seven of the more visible changes made to RavenDB in the 2.5 version.
- Result Transformers
- Scripted Patching
- SQL Replication
- Unbounded Streams
- Dynamic Reporting
- Concurrent Writes (no write lock)
- Indexing Optimizations
But RavenDB 2.5 has been in development for close to six months, and there are literally dozens of new features and improvements that went into it; quite a bit more than I could squeeze into a single article.
For example, the RavenDB Studio is considerably upgraded, providing better tools to administer and work with data. Other improvements include better spatial support, Excel integration, more performance work and more.
If you aren't already using RavenDB, give it a try. In this article I have focused primarily on the new things, and skipped a lot of the reasons why you might want to use RavenDB. I have found, time and again, that the major reason to do switch to RavenDB isn't a specific feature, it is the different mindset that it encourages and the fact that it was designed, from the ground up, to be a Zero Friction tool in your tool box.
There is a reason why RavenDB's motto is, “It Just Works.”
