


If you've been following the industry in the last few years, you know that it's moving steadily toward the cloud, steadily toward services, and steadily toward containers. It's all very exciting and it all makes sense economically and in terms of development and deployment speeds. The movement is reducing maintenance headaches and allowing new apps to be created faster by reusing existing services and adding smaller, new ones. But what's the story for data?
If you're writing services (containerized or not), chances are that you're the one working with the data. In the past, especially if you work on a lot of line-of-business applications like I do, working with data often meant connecting to SQL Server or perhaps some other relational database. But not all data is a good fit for a relational database and many modern applications, even line-of-business applications, are taking advantage of other ways to store data that are more appropriate for their needs. In addition, not every team that built a company's existing services used the same data storage. It's not at all uncommon to find two, three, four or more separate data stores at work. Some connect data between them and some don't.
This article follows a project through a series of development teams, updates, new modules, and choices about how and where to store its data. It's instructive as a story of typical modern system development where a small, simple app scaled and grew into a large, 24 x 7 x 52 system.
The GolfTracker App
Unfortunately, none of my clients are keen on me publishing the details of the applications that are crucial to their business, so a while back, a small team created an app that isn't proprietary. Over time, it evolved and grew. Because many of us at CODE play golf, the app was called GolfTracker and we used it mainly for demonstrations and training. The project started as an Angular Web application calling Web API services (in this case, written in .NET Core and running in Linux Docker containers) against a NoSQL back-end that was written in a few days. From there it grew. And grew. Here's a brief description of GolfTracker.
The “Portal” section of the app shown in Figure 1 allows administrators to manage golf clubs (the kind you belong to, not the kind you swing) and golfers, shown in Figure 2. Golf clubs can have one or more golf courses and each course can have multiple sets of tee boxes to play from (tees). Each set of tees has a different yardage, slope, and rating so that playing the same hole from a different tee is almost like playing a completely different hole. That means that there's a three-level-deep hierarchy where golf clubs have golf courses which have tees. A golfer is just a name, a handicap, and an ID that's registered with the system.
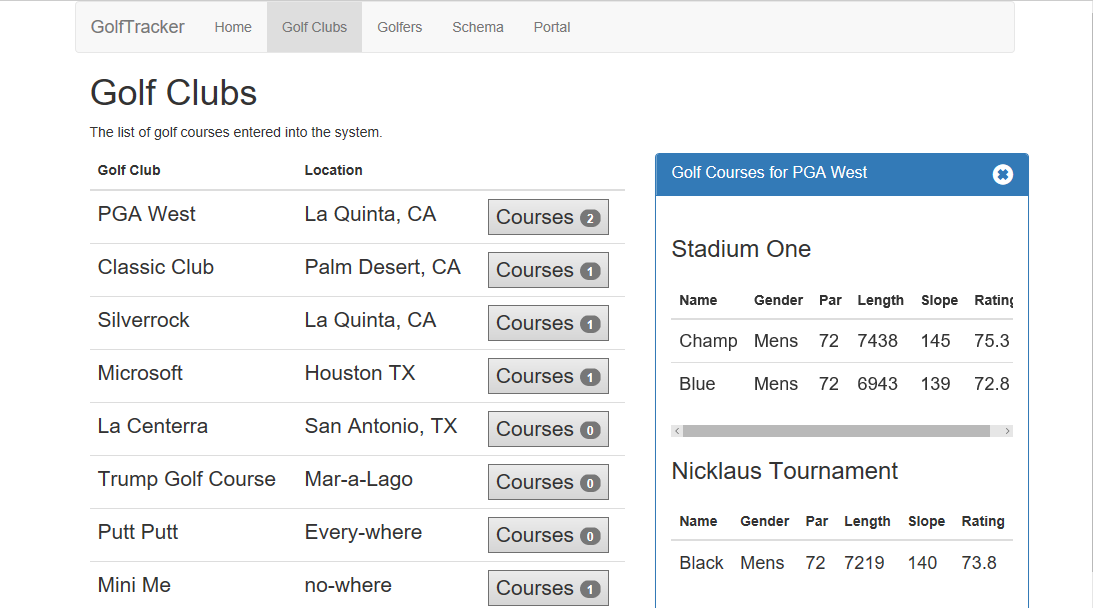
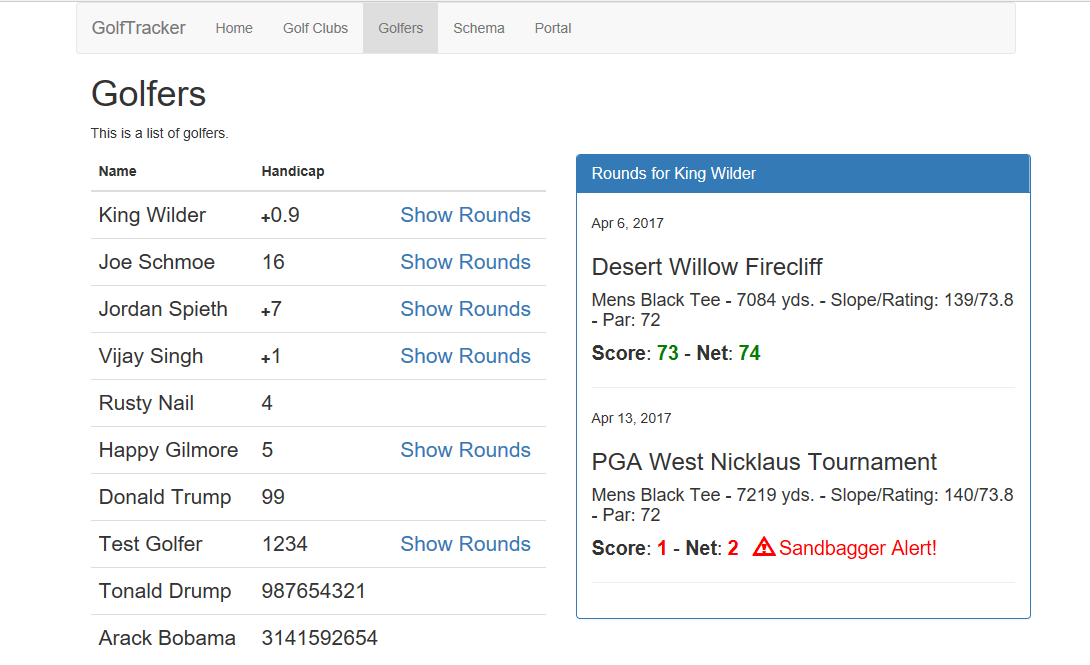
When a golfer plays a round, he specifies which club, course, and tee he played and what he shot for the round. The system uses the metrics for the tee along with the golfer's handicap to calculate a net score that's stored along with the raw score for the round. All of the information used to calculate the net score is stored with the round because golf courses often change as holes are modified, re-measured, and re-rated. This means that for a round, there's a five-level-deep hierarchy where golfers have rounds at golf clubs, at particular golf courses, and on tees. In the app, the data is flattened to a four-level-deep hierarchy where the golf course contains information about the golf club that it's part of, as shown in Figure 3.
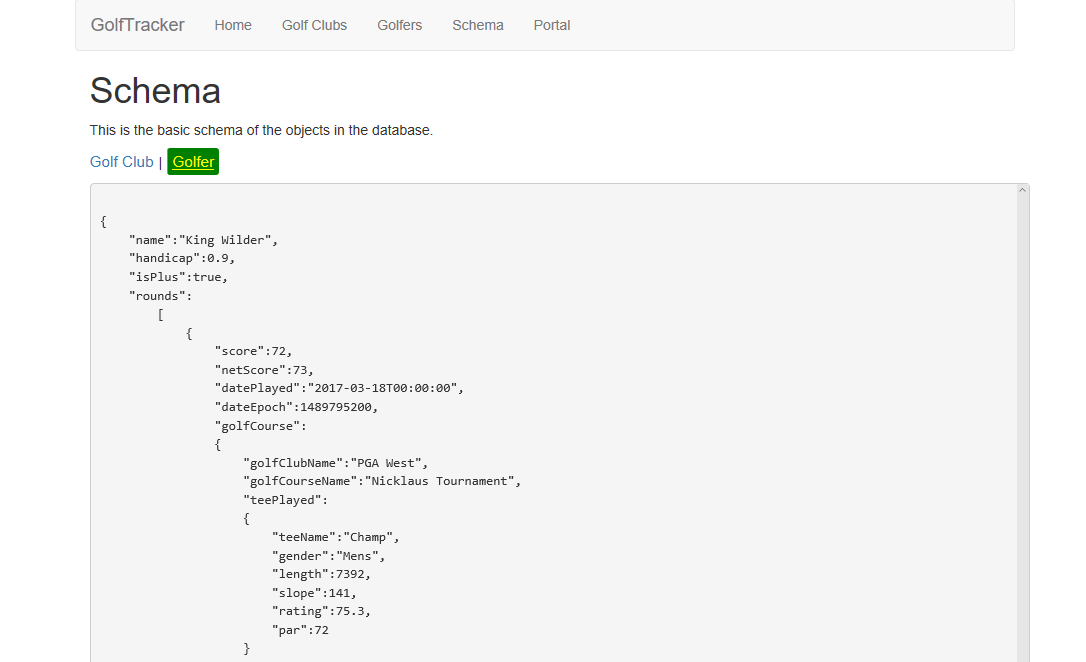
Document Data
As you can see, this is not a simple sample application that does basic Create, Read, Update, and Delete (CRUD) operations. Because of the requirement that all data pertinent to a round of golf be frozen in time when the round is entered, a NoSQL database was chosen over a relational database. The original application was written against MongoDB, which, if you're not familiar with it, is a popular, free, open source, NoSQL, Document Database, which means that it stores JSON files and indexes their contents. MongoDB databases can be scaled to massive size because they can be spread out across fault-tolerant clusters of computers, each maintaining its own part of the database, called a partition. Because all related data is stored as a single document, there isn't a need for transactions that span multiple actions, although the database can support transactions. Because all of the data for the round had to be copied and stored as a set, this was a perfect choice and no matter how popular the system gets, it will never outgrow the database.
Because the rounds were going to be stored in MongoDB, the team decided to store the rest of the information there as well. Because club, course, and tee information isn't entered or updated all that often and doesn't contain all that much data, a simple JSON document for each club including all its courses and tees was a simple and effective way to store the data. On the plus side, it only required one simple service call to retrieve all of the data for a club and another simple call to save. On the minus side, just adding a single new tee to an existing course means that all of the data for the entire club is sent back to the database to do a save. If more than one save is going on at a time, the last save wipes out all of the changes from the previous save. For example, if a co-worker just added a new golf course to the club, my saving a new tee could make his new golf course disappear. All things considered, this wasn't a bad choice for a small app, but if the app ever needs to support lots of concurrent users maintaining lots of clubs, courses, and tees, a team would either have to come up with a mechanism for keeping users from stepping on one-another's toes or move that data into a traditional relational database like Azure SQL Database where they can retrieve and update clubs, courses and tees individually instead of as an entire set.
Relational Data
Once the initial development was done, the Web app, data, and services were deployed to a test site in the cloud. It was there the team noticed that MongoDB can be expensive in the cloud, especially in Azure where, at that time it required them to either spin up and maintain their own virtual machines (there are plenty of ready-made images that already have the latest MongoDB installed and configured for a new VM) or rent a MongoDB installation from a third party in the Azure Marketplace. It's not that MongoDB is particularly expensive so much that it wasn't offered as a Platform As A Service (PAAS) offering in Azure. VMs are one of the most expensive things you can run in any cloud, both in terms of monthly cost and the time and effort required to configure and maintain them. It was going to cost a couple hundred dollars a month to run a VM solely to run the database. That's not a big deal for a large commercial site, but it was a lot of money for a sample application that doesn't generate any income.
The team knew that they could create a new set of services for the application that used Azure SQL Database (essentially SQL Server in the cloud) for as little as $5/month and scale it up as necessary if and when the site became popular. Azure SQL was not the best choice for storing rounds as it added complexity by requiring four related tables just to store rounds and the retrieve-and-save operations required extra code to roll up and unroll the hierarchy each time. On the other hand, it made the maintenance of clubs, courses, and tees more robust, as discussed earlier. The only change the team made was the introduction of primary keys for child tables so they could link child records to their parents. The keys weren't required in the Document Database as the child data was part of the JSON document. The new IDs didn't cause any problems with the MongoDB implementation because having a primary key for each child record automatically added one more property to the child record representation in the JSON document, which MongoDB automatically stored and otherwise ignored. Because GolfTracker is a training aid, it was also nice to have two back-ends to choose from and see the implementations of.
Multiple Data Stores
Next, the team was tasked with porting rounds data to Document DB. Document DB is an Azure PAAS offering of a Document Database, similar to MongoDB. Because it's a platform offering instead of requiring VMs, it was substantially cheaper than a VM, costing only about $35/month when turned down to its lowest performance level. The team re-wrote the services for rounds one more time for Document DB. It wasn't difficult because, like MongoDB, it required fewer and simpler calls than SQL Server. Although you might be thinking that the team should have used a data repository layer to save coding time and re-use the service code, you have to remember that the team was tasked with building micro services, which means services that are independently developed and deployed without dependencies across projects. In fact, it took the team less time to develop and deploy each set of services from scratch than they estimated to build a repository layer with multiple configuration and deployment pipelines for each service, plus the code is simpler, and there aren't any dependencies among the services.
At this point, the app was using Azure SQL Database services to store and maintain the club, course, and tee information with robust support for concurrent users and Document DB services for storing and maintaining rounds. The app now had the best of both worlds for a reasonable monthly cost and, in this case, the change had zero impact on the Web application.
Data Store Options
Not long after the implementation of Document DB, Microsoft rolled out a new feature of Document DB that provided API compatibility with MongoDB; which is a complicated way of saying that you can create a Document DB database in Azure that looks to all the world like it's a MongoDB database. Although you must choose this option up front when creating a new database and can't switch back and forth, you can now choose between Document DB and MongoDB when you need a PAAS Document Database in Azure. A new team was tasked with creating a new Document DB configured to use the MongoDB API and test the original MongoDB services against it. The whole process took a couple of hours and GolfTracker could now run against either DocumentDB or MongoDB to hold the round data.
Adding the Mobile App
The next step toward world domination for GolfTracker was to add a mobile application that golfers can use to record their rounds as they play. Not just the number of strokes, but details about each stroke they take (as many advanced golfers do). Then later, they can go back and see whether they hit short or long, left or right, which clubs they used, etc. When starting a new round, the user selects the golf club, golf course, and tee, then records each stroke after they take it, noting the distance to the pin (calculated automatically by Location services on the device), club used, and where the ball landed in relation to their target. They can even add notes and take pictures if they want. We assume that pictures will be used mainly for putts, but there will also be a lot of other memorable lies someone may want a picture of. At the end of a round, the mobile app writes the new round information into the existing system so that it shows up on the Web application. The plan was for the existing Web app to stay just as it was, until the mobile app launched. Then it would be updated so that golfers could select a round and see the individual strokes that were recorded.
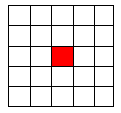
Once the golfer has played a few rounds, the mobile app begins guessing at the club to be used on the upcoming stroke based on the golfer's past performance. The golfer can always change the club, but this frees him up from having to select one most of the time. All the golfer has to do after hitting a shot is indicate how he did in comparison to the target by clicking on an on-screen grid like the one in Figure 4.
Flat Data
Using Azure SQL Database for the golf club, course, and tee information as well as the golfers was the best choice for that part of the app. Using Document DB (or MongoDB) for storing the rounds was the best choice for that part of the app (The app just copies the data retrieved from Azure SQL into the JSON document for the round and saves it in Document DB, never to change). Using Azure Table Storage was the right choice for storing strokes.
BLOB Data
What about the pictures though? Although the team could have chosen to store pictures in a database, there are better places to put them. The team chose Azure BLOB Storage (ABS). With ABS, they put the pictures into an unlimited amount of extremely cheap BLOB storage, giving each picture a unique name to retrieve it by. The services write that name (or names) into the stroke information to link the picture(s) to the stroke. When retrieving data, the UI mobile app developers could choose to delay the download of the images until after the screen comes up or not download them at all if the connection is slow or the user doesn't want to see them. The Web app can simply download the pictures like any other image on the Web. When the mobile or Web app wants a picture, it doesn't have to be sent through a service; the caller can get a custom URL to download from that expires after a few minutes so that the pictures are kept private and don't have permanent, public links. The service can return the image directly or via a URL, depending on what the calling app prefers.
Summary
In this article, I've taken a look at a real modern Web application that was deployed to the cloud. As the app evolved, the team swapped out a NoSQL database for a relational database with minimal impact on the Web application. They split the data across a NoSQL and a relational database, each suited to a different type of data, in a single app. Another team built a new mobile application that used some of the same data used by the Web app and some new data stored in a simple, flat database. A team updated the Web app to take advantage of some of the data now available from the mobile app. The various teams decided on a variety of inexpensive, high performance, highly scalable PAAS offerings from Azure to store various parts of the data: Azure SQL Database for the relational data, Document DB for the document data, Azure Table Storage for large quantities of flat data, and Azure BLOB Storage for pictures. Each change was relatively easy to design, build, and deploy as the apps, services, and data stores were independent of one another. It's not unusual for modern applications to change and develop extremely quickly or to have multiple data stores. I hope this example has helped you understand some of the options you have for storing data in the cloud and, as application development continues to evolve, how data fits into the modern landscape.
