


The Entity Framework team at Microsoft has been making several improvements since the launch of v4 with Visual Studio. The biggest of these is the capability to use a Code First or Code Only development model. Previously, if you wanted to work with the Entity Framework, you had to use either a Database First or Model First development model.
With Database First, you work with an existing database and make all of your changes at the database level. You then update the model with those changes. In Entity Framework version 1, this was the only option (unless you wanted to hack a bunch of XML). Entity Framework version 4 introduced Model First, where you could start with a blank model, and then create a database from that model. If changes were made to the model, you could recreate the database from the new model. This was my preferred method of building new applications since it allowed me to focus on my model and the classes I wanted to work with and not have to focus as much on the persistence itself. More and more developers are starting to use this concept, where the classes or model drive the design.
However, if you are working in a highly changing, iterative process, making changes to your database may not make sense. In fact, sometimes, you may not even worry about the actual persistence, especially during early development. This is where Code First really shines. Because Code First uses POCOs (Plain Old CLR Objects), you can now work with the Entity Framework in a TDD environment much more easily. This allows you to have a data layer that is ignorant of how it is persisted, thus allowing you to write unit tests for your business logic that use POCO classes without necessarily having a database in the picture. Technically, you can do this with Model First, but there are more steps involved. Additionally, with Code First, there is no .emdx file (the Entity Framework file that traditionally contains the model). Code First operates with an implied model at run time, so no real model file exists.
Because Code First uses POCOs (Plain Old CLR Objects), you can now work with the Entity Framework in a TDD environment much more easily.
Code First will be released with Entity Framework 4.1, which will likely be out shortly after this article is in print, and new features will come out of band. This means you will be able to get your hands on new features without having to wait for a new version of Visual Studio. I am very excited about this as this release model works very well in the open-source area and Microsoft has been successful doing this with ASP.NET MVC as well. This release model allows the team to respond to change faster and will make the feedback process for Entity Framework faster and more efficient.
A New Context
Along with Code First, there is a new context class, the DbContext. DbContext is a smaller, lightweight wrapper for the ObjectContext. The ObjectContext is still the default for Model First and Database First development; although there are T4 templates to generate the DbContext-based code.
To get started with Code First, you will need to create a context class that inherits from DbContext. I am going to work with the same movie model concept as I did in my last article, so I will create a MovieModel class:
public class MovieModel : DbContext
{
public MovieModel()
{
}
public MovieModel(string dbName)
: base (dbName)
{
}
public DbSet<Movie> Movies { get; set; }
public DbSet<Actor> Actors { get; set; }
public DbSet<Director> Directors { get; set; }
}
You must have a parameter-less constructor, but I also add one that takes in the database name. I do this for a few reasons, most of which involve testing. I will touch on my workflow when using Code First a bit later so you will see why it is important.
The connection strings have also changed with Code First. Since you do not have an .edmx file, the necessary information to connect to your database is much simpler and is more like the standard ADO.NET connection strings you are used to. The real key is that your connection string name must match the context class name. If it does not match, Entity Framework will not use the connection string. Here is a sample from an App.Config or Web.Config file:
<connectionStrings>
<add
name="MovieModel"
providerName="System.Data.SqlClient"
connectionString="Server=.\SQLEXPRESS;
Database=EFCodeFirstCodeMag;
Trusted_Connection=true;"/>
</connectionStrings>
The providerName needs to be set to the ADO.NET class for the database provider and the connectionString property is a normal ADO.NET connection string. Since there is no .edmx file, you do not need to specify model information like you have had to when working with Entity Framework in either Database First or Model First modes.
If you do not specify a connection string, the Entity Framework will look for a local SQL Server Express database with the name of the fully qualified context class name. In this case, my database name would be EFCodeFirstCodeMag.Data.MovieModel.
If you do not specify a connection string, the Entity Framework will look for a local SQL Server Express database with the name of the fully qualified context class name.
Once you have your new context created, you will now need to create your entity classes. Listing 1, Listing 2, Listing 3, and Listing 4 show the complete entity and model classes I will be using. I have three entities to represent a movie, its actors, and its director. Each movie will have multiple actors and a single director and both actors and directors can belong to multiple movies. Thus the relationships represented are a many-to-many relationship between movie and actor and a one-to-many relationship between movie and director. It is true that a movie may have more than one director in real life, but for the sake of the model representation, this model will only have a single director.
Since these are POCO classes, you don’t have to inherit from any Entity Framework base class and you can inherit from any of your own classes or interfaces as you wish. By default, all properties on your class will have corresponding database columns created when you generate your database.
Each entity must have a key and the Entity Framework will use a convention to figure this out from your class. It looks for a property on your class called Id or {EntityName}Id. For the movie entity I use MovieId. I generally prefer to use more descriptive names when working in .NET and SQL Server, but you can use just Id if you want. I have seen debate over this convention, but you can use whatever you like best. If you use one of these two options, you do not need to specifically tell the Entity Framework that this is your key, it will just use it.
If you want to call your key something outside of the convention, you can do that by applying a [Key] attribute to the property. This will override the convention and use the property name you have marked. For example, say you have a book entity and you want your key to be the ISBN number. You could set up your key like this:
[Key]
public int ISBN { get; set; }
If you are using an int for the key type, the key will automatically generate in the database as an identity to get auto-incrementing properties. If your key is another type, you will have to do some work to make sure it is properly generated.
The additional properties on your classes will be generated in the database based on their types. By default a string type will create an nvarchar column in your SQL Server database. You can use the fluent API or you can tag your properties with attributes. I am personally more a fan of the attributes over the fluent API, but you can use either option. More on that in a moment.
Once you have your entity class created, you must let the model know about it. This is done by creating a DbSet<T> property in your model. For the MovieModel, I added three:
public DbSet<Movie> Movies { get; set; }
public DbSet<Actor> Actors { get; set; }
public DbSet<Director> Directors { get; set; }
DbSet is a generic type so you specify the type of entity with DbSet and, generally, you will want to name the property with a pluralized version of the entity.
Not only do the classes need to be included using properties in the model, but also the relationships between entities must be included within each entity if you want to access them from each other. These properties are known as Navigation Properties and are what would get generated for you when using a non-Code First option. In my Movie entity, I need a property to access the actors as well as the director. I can create simple properties as follows:
public virtual ICollection<Actor> Actors { get; set; }
public int DirectorId { get; set; }
public virtual Director Director { get; set; }
I want to point out a few things here. First off, the properties for Actors and Director are virtual. This is to allow the Entity Framework to create proxies that can be used with features like lazy loading. I am using the ICollection type to allow for maximum flexibility and it is the recommended type to use. You can use other collection types, but you may run into some limitations depending on how you are using the classes. The convention the Entity Framework uses will recognize these properties by their names. If you want to name the properties something different, you can use the fluent API to wire them up.
I also have a property for the DirectorId so that I can access it directly if I want. The other reason I tend to specify the foreign key property is that it will follow a convention as it does with primary keys. If I don’t specify the DirectorId, the column will get generated as Director_DirectorId, a concatenation of the entity name and primary key. The convention will recognize that DirectorId is the primary key of the Director entity and use that when creating the foreign key field in the database.
In my Actor Entity I need to create a reference back to my Movie by using a property here as well:
public virtual ICollection<Movie>
Movies { get; set; }
Since I have a many-to-many relationship between Movie and Actor, I have collections on both sides. When the database gets generated, there will be a join table that will contain both the actor ids and movie ids.
For the director, there is a one-to-many relationship so I will use the same property for the director as I used for the actor. The difference being that Movie does not use a collection for the director. If I wanted to allow a movie to have multiple directors, I could use a collection as I did with actors and a similar join table would be created.
This will leave my Movie class looking like this:
public class Movie
{
public int MovieId { get; set; }
public string Name { get; set; }
public string Rating { get; set; }
public DateTime ReleaseDate { get; set; }
public virtual ICollection<Actor>
Actors { get; set; }
public int DirectorId { get; set; }
public virtual Director Director { get; set; }
}
As it stands now, the only property that is required on this entity is the MovieId. If this class were generated as shown above, each additional property would be created as nullable. To make properties generate as non-nullable, you have two options: attributes or the fluent API.
To make the Name property required or generated non-nullable, I can simply put a required attribute on the property:
[Required]
public string Name { get; set; }
To use the fluent API, you will need to override the OnModelCreating() method in your model:
protected override void OnModelCreating
(DbModelBuilder modelBuilder)
{
base.OnModelCreating(modelBuilder);
}
Then you can invoke the fluent API using the modelBuilder parameter inside the OnModelCreating() method:
modelBuilder.Entity<Movie>()
.HasRequired(p => p.Name);
You will need to create a new entry in this method for each operation you want to use with the fluent API. I personally like the attribute method more due to the amount of code that could end up in the OnModelCreating() method. The attributes also serve as validation that can even be used by ASP.NET MVC to create client-side validation for models.
Along with making the Name property required, I need to limit the size. By default, the Name property would get generated in the database as a nvarchar(MAX). (This was changed in the Entity Framework 4.1 RTW release. The RC release generated with a default length of 128.) That is a bit excessive and it is doubtful that I would ever need that much space in the database. I want to limit it to 50 characters and you can do that with a simple attribute as well:
[MaxLength(50)]
[Required]
public string Name { get; set; }
Now the Name field will get generated as a nvarchar(50) non-null field in the database. Attributes exist for most options in database creation, but what if I wanted this to not be Unicode and generate as a varchar instead of an nvarchar? There is not an attribute to do this. In CTP5, there was an option to do pluggable conventions so that you could create your own conventions (and subsequent attributes), but this was removed in the RC release. It should get added back in a future release, but it is not known when it will be added back or it if will be the same as what was in CTP5.
For now, if you want to make a field not generate as Unicode, you have to use the fluent API:
modelBuilder.Entity<Movie>()
.Property(p => p.Name).IsUnicode(false);
Between data annotation attributes and the fluent API, you can control how your database gets generated. As mentioned, I much prefer the data annotation route, as I believe it is easier to read and also has the additional coolness of giving you model validation and other benefits in ASP.NET MVC.
I Have My Entity and Model Classes, Now What?
Once you have your entity and model classes defined, it’s time to generate your database. This will be done for you at run time if the database doesn’t exist, or you can create it yourself with some API calls.
Having the database get auto-created at run time is pretty cool, but I personally find that I want to control it more. This is especially true when testing. One of the areas that I think Entity Framework Code First really excels is giving you the ability to test and work in a TDD/BDD style. While you can technically do this using Database First or Model First, creating POCO classes by hand can make this process much easier. I can create entity classes to be used within my business layer and mock them out in tests without ever actually creating the database at all.
To create your database manually, you can use the DbContext.Database.Create() method. In my integration tests, I use the following in my test setup:
private MovieModel _model;
[SetUp]
public void Setup()
{
_model = new MovieModel();
if (_model.Database.Exists())
{
_model.Database.Delete();
}
_model.Database.Create();
}
This will create the database and also delete it first if it already exists. If it already exists and you don’t delete it first, the Create() method will throw an exception. Figure 1 shows the database once it is created. By using the DbContext.Database.Create() method, I can be sure that each test has a clean database to work with. I also make sure there is a separate database for these tests, usually suffixed by “_Test”. Since I have a model that takes the database name as parameter I can change my test to use new MovieModel(“EFCodeFirstCodeMag _Test”).
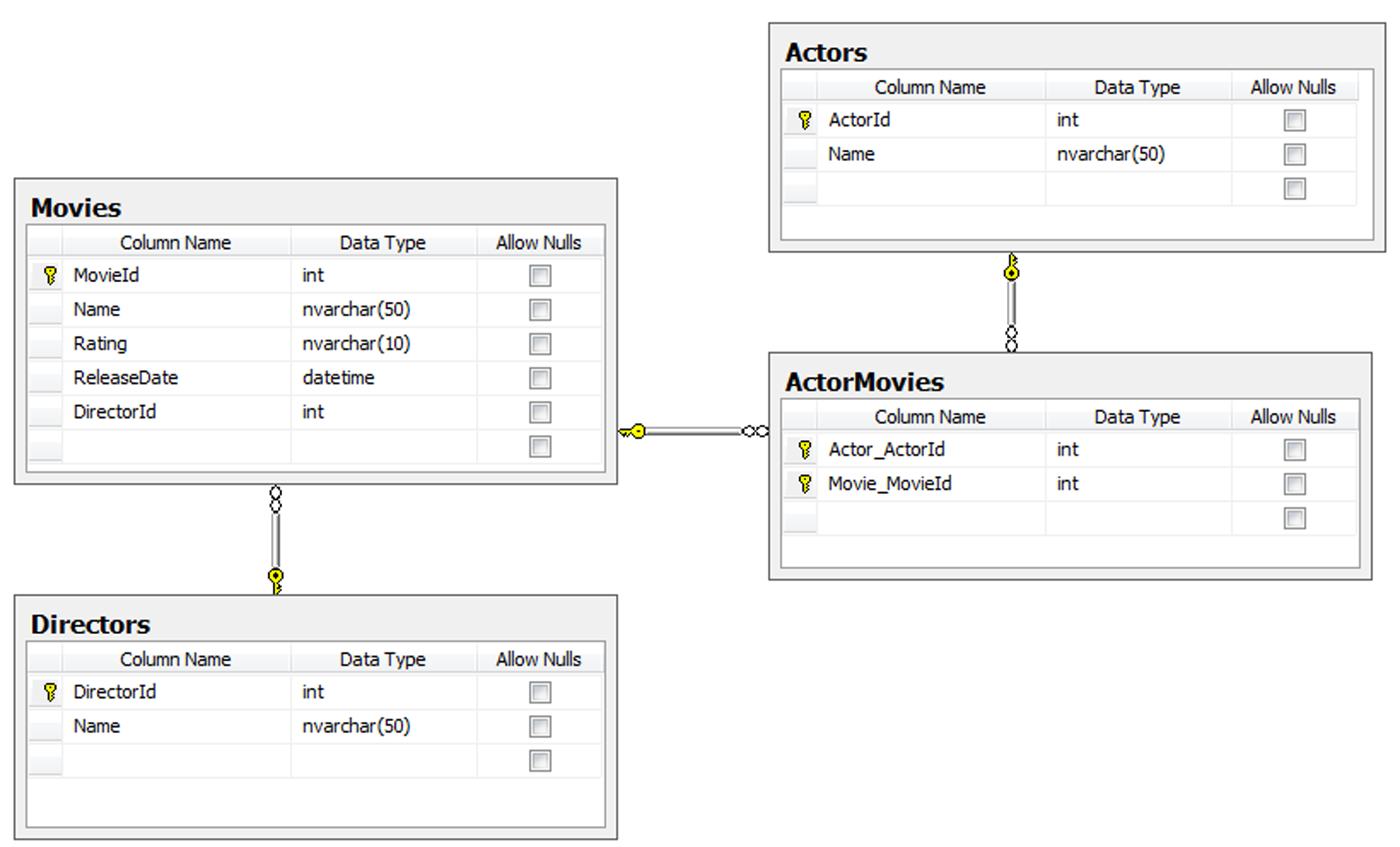
I normally use the connection string in the configuration file to set this, but depending on the testing framework and runner that you use, you may need to set it through the constructor for tests.
When doing my normal work, I will have three databases on my local machine: the main database (just EFCodeFirstCodeMag), the test database, and a compare database. Since the Entity Framework doesn’t have a migration facility at this time (this is coming in a future release), I don’t really want to drop and recreate the database I am developing against every time as I may have data in it I want to preserve. My options here are to either seed the database each time it gets regenerated or use a compare database. I normally use the latter option.
I generally have a PowerShell script that calls the Database.Create() method by passing in the name of the database in the constructor. This will create the EFCodeFirstCodeMag_Compare database, which is used to hold the schema and nothing else. I then use a database compare tool to sync the schema with the development database I am using. This allows me to preserve my data while at the same time keeping up with schema changes.
I like this option because it mimics more of what I would do to create a migration for the production database when it is time to launch my changes.
Time for Some CRUD
From here it is mostly business as usual. CRUD (Create Read Update Delete) operations work exactly as they have in previous versions of the Entity Framework. Listing 5 has a test class with some basic CRUD tests to show usage.
I normally keep some tests like this in my test suite so that I can verify that I have my class configuration correct when it comes to CRUD operations and make sure that my database is generated in the manner I am expecting. It is especially important if you are using a key type other than int, like a GUID, to make sure that your keys are being generated properly.
Note: One thing that has changed is that you must instantiate your collections now. If I want to add something to a Movie.Actors property I must new that property up first. Previously, Entity Framework did this for you behind the scenes. I prefer it working this way as it behaves like a normal class does; however, if you are used to not having to do that, or are migrating existing classes over to Code First, it may come as a surprise.
Summary
The Entity Framework has come a long way since the vote of no confidence and it is good to see the team listening and making changes based on user input. Code First is certainly a product of that.
I am most excited about it since it makes doing TDD/BDD a great deal easier. I expect any new .NET project I start will be using Code First over the other methods. Keep an eye on the ADO.NET team blog for the most up-to-date information and more tutorials at http://blogs.msdn.com/adonet.
The code for this article is posted on Github at https://github.com/danemorgridge/EFCodeFirstCodeMag.
Listing 1: MovieModel.cs
public class MovieModel : DbContext
{
public MovieModel()
{
}
public MovieModel(string dbName)
: base (dbName)
{
}
public DbSet<Movie> Movies { get; set; }
public DbSet<Actor> Actors { get; set; }
public DbSet<Director> Directors { get; set; }
}
Listing 2: Movie.cs
public class Movie
{
public int MovieId { get; set; }
[MaxLength(50)]
[Required]
public string Name { get; set; }
[MaxLength(10)]
[Required]
public string Rating { get; set; }
[Required]
public DateTime ReleaseDate { get; set; }
public virtual ICollection<Actor> Actors { get; set; }
[Required]
public int DirectorId { get; set; }
public virtual Director Director { get; set; }
}
Listing 3: Actor.cs
public class Actor
{
public int ActorId { get; set; }
[MaxLength(50)]
[Required]
public string Name { get; set; }
public virtual ICollection<Movie> Movies { get; set; }
}
Listing 4: Director.cs
public class Director
{
public int DirectorId { get; set; }
[MaxLength(50)]
[Required]
public string Name { get; set; }
public virtual ICollection<Movie> Movies { get; set; }
}
Listing 5: MovieTests.cs
[TestFixture]
public class MovieTests
{
private MovieModel _model;
[SetUp]
public void Setup()
{
_model = new MovieModel();
if (_model.Database.Exists())
{
_model.Database.Delete();
}
_model.Database.Create();
}
[Test]
public void Create_Then_Read_Test()
{
CreateMovieData();
Movie movie = _model.Movies.Where(m => m.Name ==
"The Matrix").First();
Assert.NotNull(movie);
Assert.IsTrue(3 == movie.Actors.Count);
Assert.NotNull(movie.Director);
}
[Test]
public void Add_Actor_To_Movie_Test()
{
CreateMovieData();
AddActor();
Movie movie = _model.Movies.Where(m => m.Name ==
"The Matrix").First();
Assert.IsTrue(4 == movie.Actors.Count);
}
[Test]
public void Remove_Actor_From_Movie_Test()
{
CreateMovieData();
AddActor();
Movie movie_before_remove = _model.Movies.Where(m => m.Name ==
"The Matrix").First();
Assert.IsTrue(4 == movie_before_remove.Actors.Count);
RemoveActor();
Movie movie_after_remove = _model.Movies.Where(m => m.Name ==
"The Matrix").First();
Assert.IsTrue(3 == movie_after_remove.Actors.Count);
}
private void CreateMovieData()
{
Movie movie = new Movie();
movie.Name = "The Matrix";
movie.ReleaseDate = new DateTime(1999, 3, 31);
movie.Rating = "R";
Director director = new Director();
director.Name = "Wachowski Bros.";
movie.Director = director;
Actor neo = new Actor();
neo.Name = "Keanu Reeves";
Actor morpheus = new Actor();
morpheus.Name = "Laurence Fishburne";
Actor trinity = new Actor();
trinity.Name = "Carrie-Anne Moss";
movie.Actors = new List<Actor>();
movie.Actors.Add(neo);
movie.Actors.Add(morpheus);
movie.Actors.Add(trinity);
_model.Movies.Add(movie);
_model.SaveChanges();
}
private void AddActor()
{
Movie movie = _model.Movies.Where(m => m.Name ==
"The Matrix").First();
Actor agentSmith = new Actor();
agentSmith.Name = "Hugo Weaving";
movie.Actors.Add(agentSmith);
_model.SaveChanges();
}
private void RemoveActor()
{
Movie movie = _model.Movies.Where(m => m.Name ==
"The Matrix").First();
Actor agentSmith = new Actor();
agentSmith.Name = "Hugo Weaving";
movie.Actors.Remove(movie.Actors.Where(a => a.Name ==
agentSmith.Name).First());
_model.SaveChanges();
}
}
