


In all but the simplest applications, data is stored in a central location and accessed over a network.
However, in many scenarios, distributed applications can not assume a certain kind of network connection, both in terms of performance and reliability. In scenarios where users access their applications on mobile PCs, network connections may not be available at all. This introduces relatively complex data access scenarios with which modern applications need to cope.
The .NET Framework provides many great data access components, including the ADO.NET (System.Data) and SqlClient (System.Data.SqlClient) technologies. Many of the data features in .NET have been architected specifically with distributed applications in mind.
The DataSet object is a good example. Unlike its predecessor the RecordSet object in COM-based ADO, ADO.NET DataSets operate while inherently disconnected. A connection to a database is opened, data is retrieved and put into memory, and from that point on, the connection is no longer needed and can be dropped. Only when data needs to be refreshed or stored back into the database is the connection needed again. At that point, an existing connection may be reused, or a completely new connection may be created.
The point is that ADO.NET does not have a dependency on the connection staying alive. You can query data into the memory of a laptop computer, completely disconnect the computer from the network, later reconnect it and re-establish a connection to the database, and the DataSet will be able to save changes to the database as if the connection was never severed. In fact, ADO.NET doesn’t try to keep a DataSet connected, and therefore never sees the difference between a partially and fully connected scenario.
ADO.NET is not the only component that is of importance to distributed systems. Often, it is also required that applications can take advantage of network connections other than LANs (Local Area Networks), in particular, the Internet. This enables users to run their applications while in the office as well as on business trips (hotel rooms), or geographically separated offices. There are a number of ways the .NET Framework helps in these scenarios as well. ADO.NET Web services can be used to call objects across the Internet. The same is true for technologies such as .NET Remoting, or the upcoming Windows Communication Foundation (WCF, formerly known as Indigo).
This means that fundamentally, the .NET Framework provides everything a developer needs to support partially connected scenarios. This statement applies at a relatively low level. Developers have the ability to connect to a database locally (meaning “on the local network”) and take the data “on the road” without requiring a permanent connection. This also provides fundamentals for offline data storage. Other technologies allow the developer to invoke objects (including data access infrastructure) over the Internet.
However, this does not mean that anything happens automatically. Whenever a direct connection is opened to SQL Server, that connection only works on the LAN and there is no automatic mechanism mapping that operation to a distributed call over the Internet. Similarly, there won’t be an offline cache available in scenarios where no network connection is available at all. All the fundamentals needed to implement those scenarios are provided, but some extra planning and implementation work is required on the developer’s part to make all of this happen. Luckily, the amount of effort required is relatively small, assuming proper architecture.
The Requirements
So how can you architect the application infrastructure in a way that supports features such as data access over the Internet, offline data, or perhaps even access to different types of databases? And furthermore, is it even all that smart to access data remotely, rather than just accessing business objects remotely? As is so often the case, the answer is: it depends.
Practically all modern applications are built in tiers, where individual layers of the application are responsible for different tasks. Often, applications have at least three tiers: the database tier, the business object tier, and the user interface tier. Another valid although older pattern is the client/server approach, which in essence is a two-tier application: one tier handles all database-related tasks, and the second tier handles both the application logic and the user interface. Some applications may even have more than three distinct tiers. All these approaches are valid and have advantages and disadvantages (an exploration of which is beyond the scope of this article).
Most experts agree that tiers are the accepted way of architecting business applications these days. However, not everyone agrees on where those tiers should physically reside. Over the past 10 years, many applications have been architected with two tiers (database and business objects, a.k.a. middle tier) being located on a server or server farms with computers in close proximity to each other, or at the very least on the same LAN. ASP.NET Web applications are a good example of such a set up. In fact, you could argue that in HTML-based Web applications, the UI tier (the third tier) lives on the server as well, since almost all UI tasks are processed and handled on the server and only HTML output and very limited client-side functionality (scripts) are sent to the browser.
A similar set up can be used for Smart Client applications. Data access and business logic can reside on the server and only a small client application is deployed to individual workstations. The client applications only handle UI tasks and all processing is handled on the server, possibly using concepts from Service Oriented Architecture.
Set ups similar to these are in extensive use and development today, and they are perfectly valid. However, there are other alternatives, the need for which can arise out of some of the shortcomings of the scenarios described above. Probably the biggest issue with these scenarios is that although they are relatively straightforward to create and maintain for developers and administrators, they are not necessarily great for users in all instances. It is certainly great to have Web applications that a user can use from an airport terminal if need be, but at the same time, users may want to use their applications while completely disconnected from the network. Imagine a salesman who just visited a customer and managed to secure a large sale. On his plane trip back to the home office, the salesman wants to set up the customer’s account and enter the new order. These tasks probably require business logic as well as data access, storage, and manipulation, but with an application that requires connectivity, this would not be possible.
You can accommodate this scenario by deploying the business tier to the workstation, in addition to the user interface. The scenario also requires data to be available locally, so you need to at least create the illusion of a local data store (offline data).
All the scenarios listed above are equally valid and important, and in fact, I could have come up with additional scenarios, such as Pocket PC support and others. Clearly, the goal for data access infrastructure needs to be to work in all these scenarios. Also, I do not consider it sufficient for data access to just work. Instead, I expect data access to work as efficiently as possible in all scenarios. For instance, you want to support data access over the Internet for Smart Client applications, yet at the same time, you would not want to sacrifice performance for LAN or Web Server set ups.
I expect data access infrastructure to be flexible and maintainable and be serviceable well into the future without any dependencies on code that might possibly be outdated by then. Also, I expect the system to be easy to use, ideally even easier than using ADO.NET (or any other data access technology for that matter) by itself.
The Overall Idea
Because the .NET Framework does not fulfill all these requirements out of the box, you need to create your own data access architecture. Of course, you do not want to reinvent the wheel, so use all the data access components the .NET Framework provides and simply wrap your functionality around it.
Fundamentally, what you need is a single place through which all our data access will pass. No developer will ever be allowed to create a connection or send a command to the database that does not pass through the infrastructure. Sometimes people say “…but I have so many different data access scenarios and needs, how could I possibly build infrastructure that allows for all of those?”
The answer is simple. The implementation needs to be flexible and pass all kinds of different commands through without applying any special restrictions. Can something like that be implemented? Of course! It can be done without too much trouble. In fact, the .NET Framework itself applies this very concept by routing all data access through a few simple objects in ADO.NET. This approach builds on that and does not limit the feature-set provided.
Figure 1 shows how data access works in this setup. Any client code that needs to execute a database command uses a data service object (often also referred to as a data portal object) to do so. The client can specify the desired database operation using a standard SqlCommand object (or in more generic scenarios, an IDbCommand object, as you will see later). Once the command is passed to the data service, it is completely up to the service to figure out how to execute the command, achieve the desired operation, and return the requested result set. One possible implementation can have the data service open a standard connection to SQL Server and execute the command, but there are many other options, as you will see later in this article.
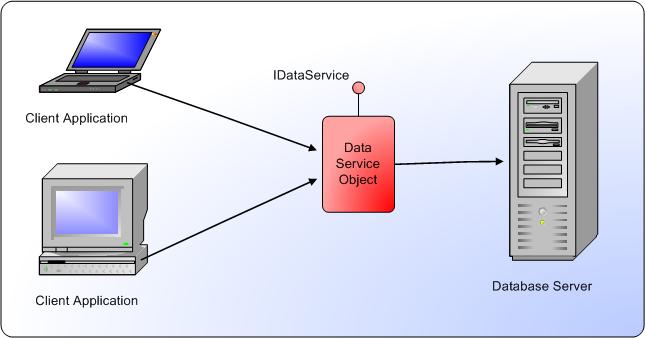
The data service object features a number of methods that can be used to interact with the data. The exact list of methods varies with your exact needs, but at a bare minimum, there will be methods such as ExecuteQuery(), or ExecuteScalar(), and the like. To make our scenario as generic as possible, first create an interface that defines the methods you want. For now, keep things simple. Here is a first version of that interface (create a new project such as a C# Windows application to put this code into):
using System.Data;
public interface IDataService
{
DataSet ExecuteQuery(IDbCommand command,
string resultName);
void ExecuteNonQuery(IDbCommand command);
object ExecuteScalar(IDbCommand command);
bool IsValid();
}
This interface serves as the contract to which every data service class needs to adhere. It is simpler than a real-life version would be, but it will suffice for the first example.
The interface exposes three methods that are specific to data operations: ExecuteQuery() executes a query and returns a result set; ExecuteNonQuery() executes a database command that does not query data (such as INSERT); and ExecuteScalar() is similar to ExecuteQuery(), except that it returns a single value instead of a set of rows.
The IsValid() method is somewhat different. It tells you whether the data service is valid and can be used in its current state. For instance, a standard SQL Server data service would be valid on a LAN, but not over the Internet, where it could not connect to the database. In essence, this method tells you whether or not the service managed to connect to the database.
Now that you have defined a simple interface, you can create the first class that implements those ideas. Listing 1 shows a simple data service that connects to SQL Server on a local area network. It takes care of all the details of talking to the database, such as creating a connection based on configuration settings defined for the application. To use this class, you need to add an application configuration file to your project that contains the following information:
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<appSettings>
<add key="UserId" value="devuser"/>
<add key="Password" value="devuser"/>
<add key="Server" value="(local)"/>
<add key="Database" value="Northwind"/>
</appSettings>
</configuration>
It should be pointed out here that this is not a particularly good way to store configuration information for database access. In a production implementation, information such as user names and passwords should be stored in a more secure way. It could also be discussed whether Windows or SQL authentication is the better way to go. These issues are not the focus of this article.
Now that you have a data service class as well as appropriate configuration settings, you can use the service to query data:
IDataService svc = new SqlServerDataService();
if (svc.IsValid())
{
IDbCommand cmd =
new SqlCommand("SELECT * FROM Customers");
DataSet dsCustomers =
svc.ExecuteQuery(cmd,"Customers");
}
This is the code you would expect the developers using the data service infrastructure to write. It is already pretty nice, because it is much easier to use the data service object to execute queries than it is to create connections and adapters and all the other things that are now abstracted into the service class. However, there are a number of improvements you can make to make it even easier to use these classes. Also, you have not quite achieved the goals defined above.
Adding Some Punch
The data service you created above will only work on a local network. You need to use a different data service if you want to access data over the Internet. You also need to use a different data service if you want to access offline data. However, it is relatively easy to create such data services and use them instead of the SQL Server data service, as all these services will adhere to the interface you created before. Therefore, these data services are completely interchangeable.
There are also a few little oddities about the code sample above. For instance, you created a variable of type IDataService and then assigned it a new instance of a SqlServerDataService object. The burden to decide which data service object is to be used is up to the developer. That may not be a good situation if you wanted to switch between various data services on the fly. What you need instead is a way to automatically instantiate a data service based on configuration settings and system state.
You can take care of this problem by introducing a special object that does nothing but instantiate data services. Call this object your data service factory. Figure 2 shows how various objects interact. Listing 2 shows the implementation of the data service factory.
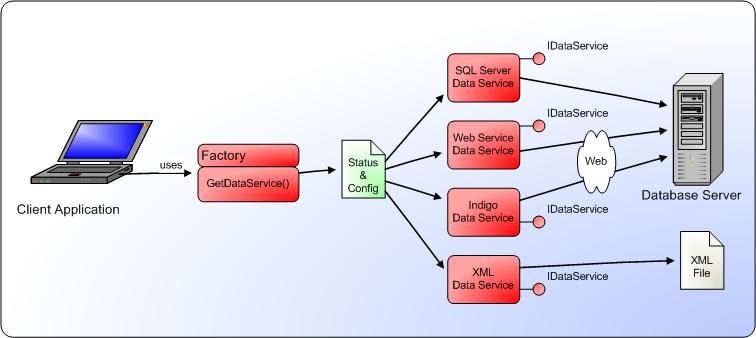
The factory features a single method that is of importance to us: GetDataService(). This method is static (shared, in Visual Basic terms), so it can be called without having to create an instance of the DataServiceFactory object first. The implementation is straightforward: The method retrieves a configuration setting and then instantiates the service object based on that setting. Note that it supports more than one setting separated by commas. It will try them one after the other until it finds a valid one. This allows you to define that you want to use the SqlServerDataService if possible, but if that fails, you want to use a different service (which you will create below).
All that is left to make the factory work is to modify the configuration file to the following:
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<appSettings>
<add key="UserId" value="devuser"/>
<add key="Password" value="devuser"/>
<add key="Server" value="(local)"/>
<add key="Database" value="Northwind"/>
<add key="dataservice"
value="sqlserver,webservice"/>
</appSettings>
</configuration>
In the data query example above, you also create a variable of type IDbCommand, but then assigned it a new instance of an SqlCommand object. This may not be intuitive to developers. Also, the SqlCommand object really has to match the SqlServiceDataService object. If your data service factory created an Oracle data service, the SqlCommand object won’t work. However, you can assume that each individual data service knows what type of command object it expects. This is a task you can offload to the data service as well.
Often, when dealing with command objects, you may want to add command parameters. Each IDbCommand has a collection of parameters. Unfortunately, this collection does not feature an Add() method that would make it easy to add new command parameters as the SqlCommand object does. This makes it unnecessarily difficult to add parameters, and you can ease that pain by adding another method to the interface that also takes care of that task. Here is version 2 of the interface:
public interface IDataService
{
DataSet ExecuteQuery(IDbCommand command,
string resultName);
void ExecuteNonQuery(IDbCommand command);
object ExecuteScalar(IDbCommand command);
bool IsValid();
IDbCommand GetCommandObject();
void AddCommandParameter(IDbCommand command,
string name, object value);
}
As you may have noticed, Listing 1 already implements this version of the interface.
With the changes you have now made, you can modify the data query example to the following:
IDataService svc =
DataServiceFactory.GetDataService();
IDbCommand cmd =
svc.GetCommandObject(
"SELECT * FROM Customers");
DataSet dsCustomers =
svc.ExecuteQuery(cmd,"Customers");
You can also add command parameters as shown in this example:
IDbCommand cmd =
svc.GetCommandObject(
"SELECT * FROM Customers WHERE Name = @Name");
svc.AddCommandParameter(cmd,"@Name","Egger");
At this point, you have infrastructure that is reasonably easy to use (although I will investigate ways to make things even easier). This is especially true considering how powerful the infrastructure already is. The code sample above can be executed against any database on the LAN, over the Internet, or offline, assuming you write appropriate data services and register them with the factory. The system also has the capability to fail over to other data services, such as using an Internet-enabled data service when the LAN service turns out not to be valid.
Adding Internet Functionality
Above, I have already referred to a data service based on a Web service, so let’s go ahead and implement it. There are a few ways to implement such a service. The simplest is to take whatever command is sent to the data service, extract the command text, and send it off to a Web service that re-creates a real command object from the transmitted command text, fires it against the database, and sends the result back to the client.
The trickiest part is that command objects are not serializable. In other words, they can not be sent as Web service parameters. This is a stumbling block, because although you can extract the command text from the command object, you are likely to need more information to support all scenarios. You can work around this problem by extracting all the information you need from the command object and send it in some other way. For instance, you can put the required information into an XML string, send that to the Web service, and use it to re-create a real command object on the server.
Listing 3 shows the implementation of a Web service class that is called by the client stub shown in Listing 4. As you can see, the code on the Web server simply uses a standard SQL Server Web service to connect to the database and to execute the desired commands. The only part worth mentioning is the GetCommandFromXml() method, which turns command object information into a real SqlCommand object that is used for the actual execution of the command.
The client code shown in Listing 4 is also pretty simple. For the most part, it simply routes calls to the Web service implemented in Listing 3 (referred to as WebDataService in this implementation). Once again, there only is one other noteworthy part: the GetSerializedCommand() method, which turns all the parts of the command object you care about into XML, so it can be passed to the Web service.
As you can see, the service is very simple overall. This fact must be attributed to the simplicity of creating Web services in ASP.NET. Many difficult aspects, such as transferring query results over the Internet, are handled automatically.
At this point, the Web service-based data service is complete. With the current system configuration, this service will be used automatically whenever the “normal” SQL Server data service is not valid. If you want to see the new service in action right away (it can be difficult to simulate failover on a single computer), simply change the configuration to the following:
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<appSettings>
<add key="UserId" value="devuser"/>
<add key="Password" value="devuser"/>
<add key="Server" value="(local)"/>
<add key="Database" value="Northwind"/>
<add key="dataservice" value="webservice"/>
</appSettings>
</configuration>
Re-run the data access example from further above without any changes to see the new service in action. Note that there is no need for the developer to even know that the data now travels over the Web.
At this point, you probably need to ask yourself whether you have chosen the best way of accessing data over the Internet. The approach clearly works, and I have seen it used in very similar form in production applications. However, I must point out a few shortcomings and characteristics of the current implementation.
For one, there is a performance penalty that comes along with the Web service approach. Using the failover approach you have implemented, applications based on this infrastructure will perform very well on LANs, as the direct access data service will be used. However, whenever the Web service approach is used, performance will not be as stellar. It often surprises me how well Web services perform, but there definitely is a difference. There are a number of ways to improve performance. One of the biggest areas of inefficiency lies in the way .NET serializes ADO.NET DataSets for transport over Web services. You could battle this problem by creating a custom serializer, similar to the approach you took with the command object.
You could also achieve significantly better performance with alternate Internet technologies, such as .NET Remoting or the upcoming Windows Communication Foundation (WCF, formerly known as Idigo). These approaches allow for binary communication, which performs much better than XML-based communication utilized by Web services.
Another issue is security. It is conceivable and somewhat probable that someone would call your data service Web service outside of your application, and thus gain full access to your database. This is a great risk that must be addressed in production implementations. Luckily, there are a number of ways to enhance security.
First, you need to make sure that only people who have any business in your database can access the Web service. This can be handled through standard authentication mechanisms. You also need to make sure that data is securely encrypted while it travels over the wire, so it can not be intercepted and viewed. This can be handled through Web service security. There are several ways of encrypting data in transit, and you can pick whichever you are comfortable with. However, do not implement your own encryption mechanism. No matter how confident you are in your algorithm, and no matter how hard it may seem to crack to you, it is almost certainly going to be significantly weaker than even simple standard encryption mechanisms available to .NET Web service developers.
Another security problem you need to address is tampering. Encryption tends to counter this problem, but if you want to really be certain that nobody messes with your data while it travels over the Internet, you can digitally sign it. At this point, you have a system that only authorized people and applications can use, and data is not usable and not modifiable.
You are still not as secure as I would like us to be. Another scenario you may want to protect ourselves against is “replay attacks.” Someone might be able to intercept your message, and although it could not be read or altered, it could be sent to your server again at a later point in time. This allows a potential hacker to retrieve whatever data happened to be requested by that message, store it locally, and try to hack it in the comfort and privacy of his or her own office, with no time limitations, all of which greatly increases the hacker’s chance of success. You can prevent replay attacks by adding a timing mechanism to the service, such as a time stamp or a ticket. Each ticket is only valid for a short period of time (perhaps a matter of minutes), reducing the chance of replay attacks greatly. (Of course you need to make sure that your ticket information is also encrypted and/or signed, so it can not be altered.)
At this point, you are getting closer to a reasonably secure system. I am sure you can even come up with further security measures on your own. However, there is one more thing I strongly recommend: Let’s say all of this wasn’t enough and a hacker has managed to get into your system after all. Remember: they have all day to hack systems while developers have many other things to worry about, which gives them a great advantage and the ability to hack into systems you would consider quite secure. I still want to put up another wall of defense.
Instead of allowing full access to the database, it would be much better to only allow access to stored procedures. This can be done easily by setting access permissions so the account the Web service uses to log in only has access to certain stored procedures. This allows you to judge very clearly what sort of damage hackers will be able to do to your systems in a worst-case scenario, as they can not do anything that is not supported by the exposed set of stored procedures. Of course, this may still be bad enough, but normally not nearly as bad as what they could do with low-level database access.
If you implement all these things, you have put up a number of walls that will deter hackers for a while. You probably would have to have extremely valuable data in your database for hackers to still make it worthwhile to break into your system. Of course there are scenarios where this level of security is not sufficient. In that case, you should probably consult with a company specializing in security, or question whether your application is suitable for distributed and mobile use.
Adding Offline Capabilities
With the architecture you have created so far, you can also implement the core of an offline storage system. Many times, Microsoft Outlook is used as the poster child for offline functionality. Whenever the user has access to her Exchange server, either directly or over HTTP (in a fashion similar to the scenarios above), live data is being accessed, but when the connection is unavailable, data from a local offline data store is being used. This version of the data is not necessarily as up to date as the data on the Exchange server, but it is generally up to date enough to allow the user to work productively. Basically, the user sees the data as it was the last time it was accessed online.
The core concept is pretty simple. Take the data that is served up by the data services you created so far, and store it locally for later use. Then, create another data service that can access that offline data when everything else fails.
The following code snippet shows a relatively naïve approach to modify the SqlServerDataService to store all data that is queried through the ExecuteQuery() method locally:
public DataSet ExecuteQuery(IDbCommand Command,
string ResultName)
{
DataSet ds = new DataSet();
SqlCommand objCommand = (SqlCommand)Command;
SqlDataAdapter adAdapter =
new SqlDataAdapter(objCommand);
adAdapter.SelectCommand.Connection =
this.Connection;
adAdapter.Fill(ds,ResultName);
adAdapter.SelectCommand.Connection = null;
this.conDirect.Close();
ds.WriteXml("Offline.xml");
return ds;
}
I am calling this a naïve approach, because the offline XML file gets overridden every time. So if you queried all customers whose last name starts with A, and then query all whose last name starts with B, the offline file would only contain the B customers. If you were to subsequently query invoice information, the file would contain a completely different set of data altogether. And to make matters worse, there is no easy way to tell what type of data is contained in the latest version.
This approach points us in the right direction in terms of what is fundamentally required: All the data that travels through one of the three data access methods (in all your live data services) needs to be intercepted and stored away for later use. XML files are only adequate for the simplest of uses. In most scenarios, you need a sophisticated local data store such as MSDE/SQL Express or a similarly capable database.
Once data is stored locally, creating a data service that operates on the local data source is mostly a variation of the SQL Server data service. The only part that deserves special mention is data modification. When the user updates data in the local data store, or adds new data altogether, those changes need to be applied locally, but you also need to keep track of all the records that have been modified and when, so you can later sync those changes back to the online version of the data store.
The implementation of this can happen in a number of ways. I like a variation that has the data access methods raise events whenever data is queried (ideally, those events are static/shared, so it is relatively easy to hook up to them on a global basis). This allows for the creation of a single object that subscribes to the data access events of all kinds of data services. This object ideally queues a copy of the data away so it can be stored for offline use, possibly on a low priority background thread.
So the fundamental ideas behind building an offline data store similar to Outlook’s offline data store are pretty straightforward and can be implemented in a completely generic fashion. However, there really is a bit more to it, and compared to many business applications, Outlook faces a much less complex problem. This is due to two facts: Outlook has relatively simple business rules and Outlook stores data in a fashion that is not comparable to most business applications. In Outlook, each user has an individual set of data. E-mail messages belong to one user and one user only. The same is true for contacts. Even potentially shared data such as calendar information is kept separated. If two users share the same appointment, they both get a unique copy.
Most business applications work differently. Often, complex business rules are needed, and offline scenarios may need special handling. For instance, an order for 1000 widgets entered offline may appear perfectly valid to the local business logic that relies on the last known snapshot of data. However, once the system is taken back online, it may discover that another sales person has sold the remaining stock of that widget, making the data entered offline invalid. In many such scenarios, there are no good generic answers as to how to handle them. Developers will have to implement scenario-specific conflict resolution logic so the system can be brought back into valid state.
The problem of shared data is a completely different problem. Outlook conveniently sidesteps this one completely, but you are not likely to get off the hook this easily. Fundamentally, you need to implement a concurrency management system. The appropriate approach depends on your scenario. Do you want to simply store the last version of a record? Do you want to approach the problem on a field by field basis? Do you want to use a data dictionary to define groups of fields that have to be updated together? (It is probably okay to save one user’s version of an e-mail address and another user’s version of the same record’s phone number, but it is probably not okay to save one user’s version of a city field and another user’s ZIP code update of the same record.). Perhaps you may even want to ask the user to help resolve the problem in difficult cases. The choice of appropriate implementation is up to the developer and beyond the scope of this architectural article.
One other area of concern that should be mentioned at least briefly is that of security. It is highly recommended that whatever technology you choose to use for your client-side data store supports strong security. Security is of a particular concern for offline data because the probability of data theft is orders of magnitude greater than for desktop computers, as it is much easier to steel a laptop bag out of a car, than it is to carry a PC out of an office. Having the device stolen may set you back a couple of thousand dollars, but if your data is not secure and is therefore accessible to the thief, the potential damage is much greater. I am sure you wouldn’t want to explain to a few hundred of your best clients why their credit card numbers got stolen out of your database.
The Hidden Value of Stored Procedures
For my next architectural trick: stored procedures. Stored procedures have a lot of advantages, from security to performance. I do not want to engage in a discussion about the general advantages and disadvantages of stored procedures, as such a discussion really has nothing to do with the subject of this article. However, there is one aspect of stored procedures that is often overlooked, yet is of incredible importance to the data access infrastructure: stored procedures are the ultimate abstraction of data access. Using stored procedures, you can easily port your application to use any type of database as the back end.
Some readers may wonder how that would work. After all, many databases and data sources do not support stored procedures at all. Nevertheless, I stick to my statement. Here’s why. Developers often think of stored procedures as snippets of code that live inside the database. However, at a more abstract level, stored procedures are simply little programs with a certain signature (procedure name and parameter names and types) that sit between the client application and the database. From an architectural point of view, the fact that stored procedures live inside SQL Server is irrelevant. And if you happen to be talking to a data source that does not support stored procedures, you can always reproduce the same concept yourself using standard .NET code.
Consider a simple example: Let’s say you want to query all customers from a database whose name starts with A. Without stored procedures, you could use the infrastructure like so:
IDataService svc =
DataServiceFactory.GetDataService();
IDbCommand cmd =
svc.GetCommandObject(
"SELECT * FROM Customers WHERE Name = @Name");
svc.AddCommandParameter(cmd,"@Name","Egger");
DataSet ds = svc.ExecuteQuery(ds,"Customers");
In this case, the select statement is sent to the database server as specified. Using stored procedures, the procedure has a name and receives a single parameter. The procedure then executes the SQL statement internally and returns the result set. You can call such as procedure in the following fashion:
IDataService svc =
DataServiceFactory.GetDataService();
IDbCommand cmd =
svc.GetCommandObject("GetNames");
cmd.CommandType = CommandType.StoredProcedure;
svc.AddCommandParameter(cmd,"@Name","Egger");
DataSet ds = svc.ExecuteQuery(ds,"Customers");
Both approaches work fine as long as the data service served up by the service factory links you to SQL Server. If you were to switch to a completely different data storage system (let’s use XML files as an example), you would have problems in either case. In the first case, you would have to map the SELECT command to something you can execute on an XML file. Although not impossible, this task would be extremely difficult. You would have to create an engine that can parse T-SQL syntax and then find a way to apply the operations to XML, which is difficult because XML follows a completely different paradigm. I do not think that it is feasible to implement such a solution.
The stored procedure approach also will not work out of the box, because XML certainly does not support the concept of stored procedures. However, you can create a solution relatively easily. All you have to do is create a piece of code named GetNames with a single parameter, and then call that code from an XML data service. That little snippet simply needs to load the XML file, apply an XPath query (or any other sort of XML processing), and return the result in a fashion compatible to the SQL Server stored procedure. With ADO.NET and System.XML, this task is surprisingly easy.
The approach I want to demonstrate accomplishes this task very elegantly (in my opinion). Rather than adding all such methods to an XML data service manually, I like to use an object I call a stored procedure façade. This is an object that can act very similar to a system that supports stored procedures natively. The idea is to create a simple .NET object with methods that can be treated like stored
procedures, even though they are just standard methods. The goal is to provide a simple way to execute those methods without having to hard code them into the data service. This task is accomplished by a method called ExecuteFakeQuery(), which is defined on an abstract StoredProcFacade class. Developers can derive from that class, add their own methods, and then execute them by passing a standard IDbCommand object (like the one you created in the second example above) to the ExecuteFakeQuery() method.
The key to implementing such a façade object lies in .NET Reflection. Reflection allows you to inspect objects and find out what methods and properties they have. Reflection also allows you to execute these methods dynamically. Using these capabilities, you can inspect the command object passed to the ExecuteFakeQuery() method, match it up with a method on the façade object, execute that method dynamically, and return the result as if it came from a stored procedure in SQL Server. Listing 5 shows the implementation of the base façade class.
Now that you have the tricky part wrapped up in a reusable class, you can subclass it and add the GetNames() method that the query is expecting to use. Listing 6 shows an implementation of that method that is purposely kept rather wild to demonstrate how different the method can be from normal data access. (This method assumes an XML file as it would have been created by the naïve offline approach shown above.)
Now all that’s missing is the ExecuteQuery() method in a new XML data service. The implementation of that method is so simple it only requires a few lines of code:
public DataSet ExecuteQuery(IDbCommand cmd,
string resultName)
{
if (cmd.CommandType !=
CommandType.StoredProcedure)
{
throw new Exception("Not a stored proc!");
}
StoredProcFacade f =
new CustomerStoredProcedures();
return f.ExecuteFakeQuery((SqlCommand)cmd);
}
Of course, this code could be easily enhanced by allowing for an external configuration option specifying which stored procedure façade to use.
Voila! You have now ported the application to work with XML as a database through the use of stored procedures. Note that in many scenarios, the fake stored procedures can be mapped to highly performing database access, resulting in implementations far superior to the XML example. Also, the implementation of these stored procedures (fake or real) is pretty straightforward, especially as many of them can usually be code generated. This is especially true for CRUD (insert, update, delete) stored procedures that deal with insert, update, and delete operations.
Note that another benefit you get from this approach is that the stored procedure (fake or real) can map data from a structurally incompatible data source to the expected result format.
Adding Polish
At this point, you have a system with a lot of depth in its features. However, you still have a very narrow scope, since all the data services only support three methods. You could argue that these three methods support a very wide range of data operations, but I would expect these services to be more feature-rich. Here are some ideas of what you might add to your data services:
- Add transaction support to the IDataService interface (and all implementations thereof) through methods such as BeginTransaction() and CommitTransaction().
- Add code that attempts to detect SQL injection attacks by looking for comparison operators in the command text and see if they all use the parameters collection, rather than parameter values stored in the command string. The current architecture already provides some protection against SQL injection by supporting parameters, but this feature forces people to take the safe route.
- Add security features such as application role support.
- Add support for data readers. Data readers allow very fast and resource-friendly reading of data. The difficulty in the above scenario is that readers do not support the distributed scenarios as well as DataSets do. However, it can still be done with specialized reader handling in distributed environments. Performance will suffer a lot in those cases, but on the LAN, readers provide great performance, and over the Internet, users should not expect the same performance anyway, right?
- Add methods that can load data asynchronously in a thread-safe fashion.
- Add concurrency checking to the data service and raise events whenever concurrency problems occur, so developers can write interfaces that react to those events.
These are very technical features, but you may also be interested in adding more task-oriented features. Here are some ideas for those:
- Create methods that can create command objects that perform CRUD operations (insert, update, delete) for updated rows in data tables. The command builder object can perform this task too, but you can provide more sophisticated or more specialized functionality.
- Create methods that can create command objects for standard operations, such as retrieving a row based on the key value, retrieving a list of records based on foreign key values or the value of any given single field.
If you can abstract many of the standard data access operations in this fashion and put the burden on each data service object rather than your business logic, you can write very generic data access code that works in an optimized fashion on any given data source. Depending on your application, these methods can handle a very large percentage of data access operations, making it much easier to build applications that support various database technologies.
There is also more polish that can be added on the business object level. Currently, any code using this infrastructure needs to instantiate a data service. In a business object, you can add one more layer of abstraction by adding a protected ExecuteQuery() method to your base business object class, which is then available on all concrete business objects. This method is a direct map to the data service’s ExecuteQuery() method, except that it also takes care of instantiating the data service, taking that burden off developers. The same can be done with all other methods exposed by the data service.
As you can see, the architecture and implementations you have created are really just the beginning. They form a base on which you can build your own architecture. As you can imagine, production implementations are likely to be much more sophisticated than the examples shown here, but the core concepts remain identical.
I expect powerful data access infrastructure to handle very complex scenarios, yet be easier to use than plain ADO.NET.
We need to build a data access infrastructure that routes all data operations through a single class. This does not limit us in any way, as the .NET Framework already takes a similar approach.
This architecture allows you to dynamically switch between various ways of accessing data without the rest of the application ever noticing.
Stored Procedures are the ultimate abstraction of data access.
The architecture you created in this article is really just the beginning…
